





Milvus中的向量查询是通过基于布尔表达式的标量过滤检索向量的过程。通过标量过滤,用户可以使用应用于数据属性的特定条件来限制其查询结果。例如,如果用户查询1990-2010年期间发布的电影,并且分数高于8.5,则只有属性(发布年份和分数)满足条件的电影。
本文旨在研究如何在Milvus 2.0中完成查询,从查询表达式的输入到查询计划的生成和查询执行。
查询表达式
Milvus中带有属性过滤的查询表达式采用EBNF(扩展的巴科斯-诺尔形式)语法。下图是Milvus中的表达式规则。
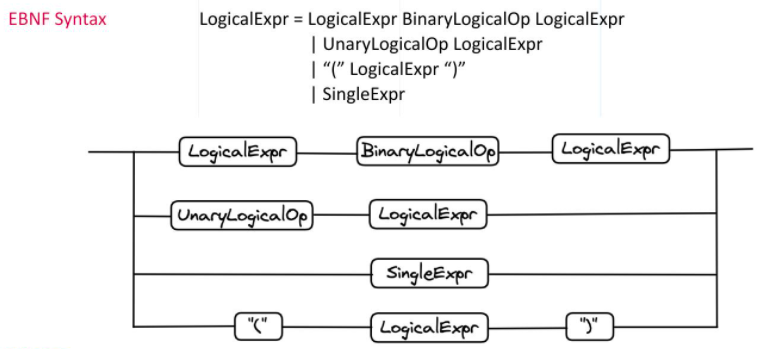
可以使用二进制逻辑运算符、一元逻辑运算符、逻辑表达式和单个表达式的组合来创建逻辑表达式。由于EBNF语法本身是递归的,因此逻辑表达式可以是更大逻辑表达式的组合或部分结果。一个逻辑表达式可以包含多个子逻辑表达式。同样的规则也适用于Milvus。假设用户需要在许多条件下过滤结果的属性。在这种情况下,用户可以通过组合不同的逻辑运算符和表达式来创建自己的过滤条件集。
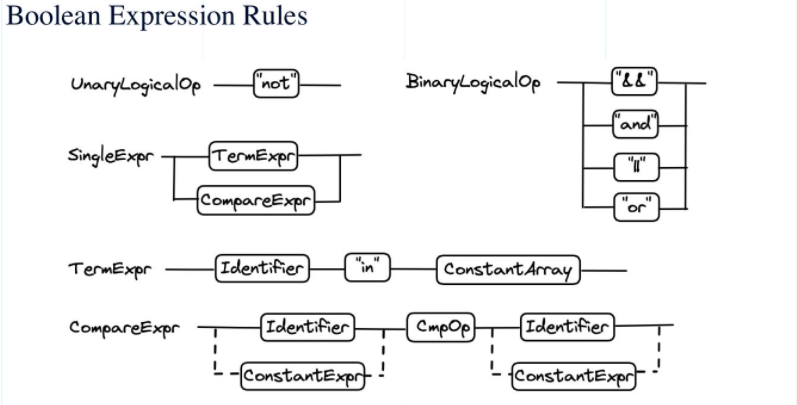
上图显示了Milvus中的部分布尔表达式规则。一元逻辑运算符可以添加到表达式中。目前,Milvus仅支持一元逻辑运算符“not”,这表明系统需要获取标量场值不满足计算结果的向量。二进制逻辑运算符包括“and”和“or”单个表达式包括术语表达式和比较表达式。
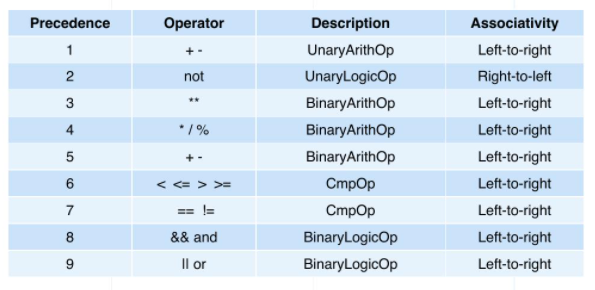
在Milvus中进行查询时,还支持基本的算术计算,如加法、减法、乘法和除法。下图显示了操作的优先级。运算符按降序顺序从上到下列出。
在Milvus中如何处理某些胶片上的查询表达式?
假设Milvus中存储了大量的胶片数据,用户希望查询某些胶片。例如,存储在Milvus中的每个电影数据都有以下五个字段:电影ID、发行年份、电影类型、分数和海报。在本例中,电影ID和发行年份的数据类型是int64,而电影分数是浮点数据。此外,电影海报以浮点向量的格式存储,电影类型以字符串数据格式存储。值得注意的是,支持字符串数据类型是Milvus 2.1中的一项新功能。
例如,如果用户想要查询分数高于8.5的电影。电影也应该在2000年之前的十年到2000年之后的十年发行,或者它们的类型应该是喜剧或动作电影;用户需要输入以下谓词表达式:分数>8.5&(2000-10<release_year<2000+10 |键入[喜剧,动作])。
收到查询表达式后,系统将按以下优先级执行:
1.分数高于8.5的电影的查询。查询结果称为“result1”。
2.计算2000-10得到“结果2”(1990)。
3.计算2000+10得到“结果3”(2010)。
4.release_year值大于“result2”且小于“result3”的电影的查询。也就是说;该系统需要查询1990年至2010年间发行的电影。查询结果称为“result4”。
5.查询喜剧或动作片的电影。查询结果称为“result5”。
6.将“result4”和“result5”结合起来,可以获得1990年至2010年间发行的电影,或者属于喜剧或动作电影类别的电影。结果称为“结果6”。
7.取“result1”和“result6”中的公共部分,以获得满足所有条件的最终结果。

计划AST生成
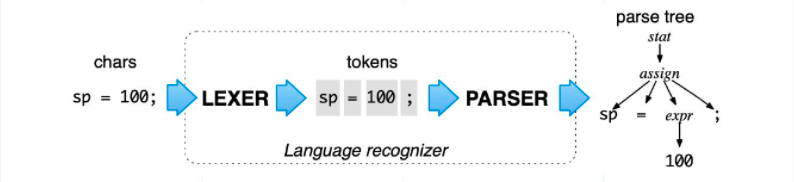
Milvus利用开源工具ANTLR(另一种语言识别工具)生成plan AST(抽象语法树)。ANTLR是一个强大的解析器生成器,用于读取、处理、执行或翻译结构化文本或二进制文件。ANTLR可以生成一个解析器,用于根据预定义的语法或规则构建和遍历解析树。下图是输入表达式为“SP=100;”的示例。LEXER是ANTLR中内置的语言识别功能,它为输入表达式生成四个令牌——“SP”、“=”、“100”和“;”。然后,该工具将进一步解析这四个令牌,以生成相应的解析树。
walker机构是ANTLR工具的关键部分。它旨在遍历所有解析树,以检查每个节点是否遵守语法规则或检测某些敏感词。下图列出了一些相关API。由于ANTLR从根节点开始,并向下通过每个子节点到底部,因此无需区分如何遍历解析树的顺序。
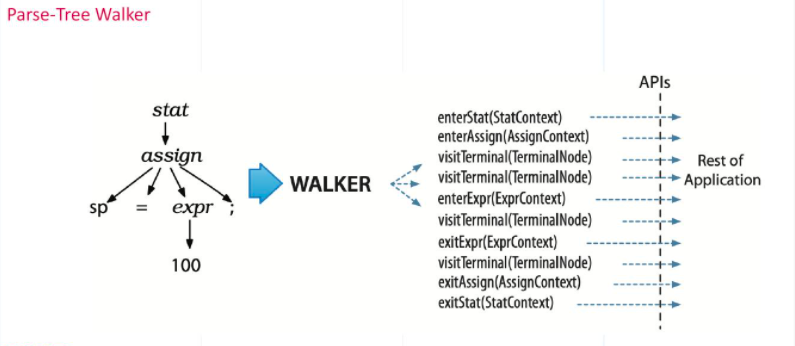
Milvus以与ANTLR类似的方式生成PlanAST for query。然而,使用ANTLR需要重新定义相当复杂的语法规则。因此,Milvus采用了最流行的规则之一——布尔表达式规则,并依赖GitHub上开源的Expr包来查询和解析查询表达式的语法。
在使用属性过滤的查询过程中,Milvus在接收到查询表达式后,将使用ant解析器(Expr提供的解析方法)生成原始的未解决计划树。我们将得到的原始计划树是一个简单的二叉树。然后,通过Expr和Milvus中的内置优化器对计划树进行微调。Milvus中的优化器与上述walker机制非常相似。由于Expr提供的计划树优化功能非常复杂,因此在很大程度上减轻了Milvus内置优化器的负担。最终,分析器以递归方式分析优化的计划树,以在协议缓冲区(protobuf)结构中生成计划AST。

查询执行
查询执行在根目录下,执行在前面步骤中生成的计划AST。
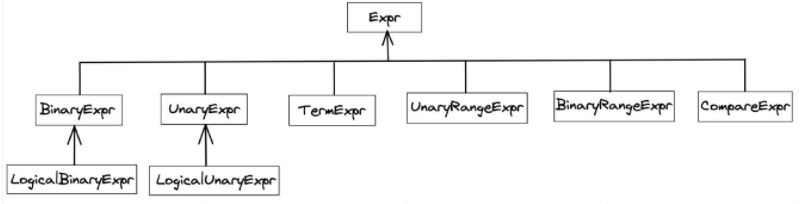
在Milvus中,计划AST在原型结构中定义。例如,下图是具有protobuf结构的消息。表达式有六种类型,其中有二进制表达式,一元表达式还可以有二进制逻辑表达式和一元逻辑表达式。
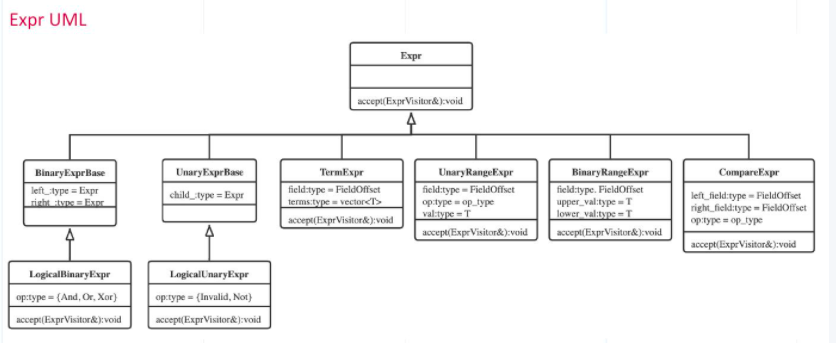
下图是查询表达式的UML图像。它演示了每个表达式的基类和导数类。此外,每个类都附带了一个接受访问者参数的方法。这是一种典型的访客设计模式。Milvus使用这种模式来执行plan AST,因为它最大的优点是用户不必对原始表达式做任何事情,但可以直接访问模式中的一个方法来修改某些查询表达式类和相关元素。
在执行计划AST时,Milvus首先接收原型计划节点。然后通过内部C++原型解析器获得segcore类型计划节点。在获得这两种类型的计划节点后,Milvus接受一系列类访问,然后修改并执行计划节点的内部结构。最后,Milvus搜索所有执行计划节点以获得过滤结果。最终结果以位掩码的格式输出。位掩码是位数字的数组(“0”和“1”)。满足过滤条件的数据在位掩码中标记为“1”,而不满足要求的数据在位掩码中标记为“0”。
在Milvus中执行计划AST的工作流。
原文标题:How Does the Database Understand and Execute Your Query?
原文作者:Angela Ni
原文链接:https://dzone.com/articles/how-does-the-database-understand-and-execute-your
