





VLDB 2021论文:Big Metadata: When Metadata is Big Data
摘要
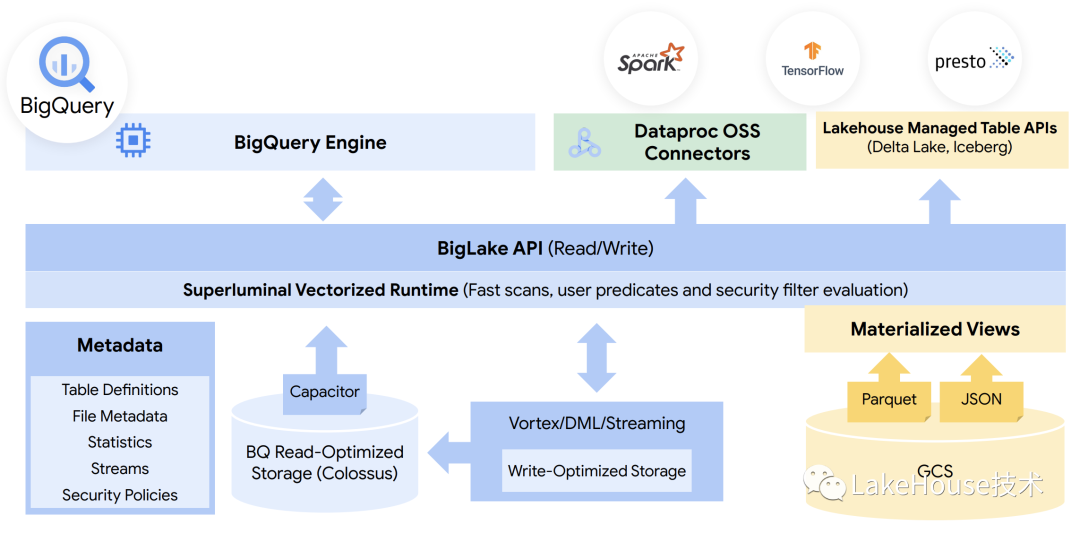
在进行本论文剖析之前,我们先看下Google在Google Data Cloud Summit 2022介绍的BigLake的架构:
从架构可以看出google有一套面向湖仓分析的存储引擎capacitor,从bigquery的论文来看这套存储引擎和deta lake&hudi的定位类似,在实际功能能力上甚至领先于delta lake&hudi;另外可以看到有一套统一的MetaData,其中会管理statistics,本论文也是介绍Google在PB级别表statistics如何通过元数据管理进行data skip从而提高分析性能。
阅读目的
去年在做hudi的时候在社区和小伙伴推动和讨论data skip metadata方案,目前在hudi最新的0.11已经落地了一个版本HUDI-1822。刚好看到google的这篇论文和当时的想法比较类似,就来看下google的data skip metadata和hudi、delta lake的方案有什么区别。
解决的核心问题(场景/技术)
问题定义
目前业界大数据在海量数据分析的元数据存储上面,一般都是为了支持扩展性,而去牺牲了性能。比如HIVE的元数据只存储了分区的信息,file及block级别的statistics在进行SQL优化的时候完全没有用上;delta lake在这块做了一定的优化,把file级别的statistics单独存储到delta log中,在scan之前通过查询delta log表去过滤出实际要scan的file,block级别的过滤还是需要在scan的时候去读取parquet的metadata来做过滤(会多一些远程的文件操作)。其实statistics是可以存储到block级别的,如果在分析之前能够做到block级别的过滤可以大幅提高查询的性能,但是对于大表block级别的statistics数据量太大,目前的方案都难以存储或者存储之后无法读取。
论文的价值
Google这篇论文正是解决block级别的statistics做到可存储、可快速读取、可应用到优化器中,从而有效的提高分析性能(包括远程文件打开的开销、无效block读取的开销等)。主要特性包括:
• 两层元数据架构:第一层元数据包含库表分区,是存储在Google的统一catalog里面;而block级别的statistics是存储在一个列存的表中
• 一致性保证:对于所有的操作支持ACID的维护
• 流和批处理统一使用这套方案
• 扩展性几乎没有限制
• 性能友好:block级别的statistics通过列存存储
业界相关工作
元数据用自己的存储在很多数据库系统也是这么做的,比如google的bigtable。不少database会把元数据的概要表存储在内存中来做加速,而bigquery的元数据需要处理大表的scale,所以放在内存是放不下的。hive元数据的痛点在于单点查询partition性能不行。
论文内幕
本文的特点是使用一个新颖的思路,在SQL引擎的中端到端的解决了大规模表的查询性能优化问题。对于Bigquery来讲,可以有效的加速器其大表小数据量过滤的性能。
基础概念
• 执行引擎:bigquery coordinator给出的是初始化的plan,在执行过程中会根据统计信息进行动态的plan的优化,动态的plan还会影响物理执行算子的选择。
• data skip表的存储模式:通过一层dataset的抽象来支持包括事物等的处理逻辑,表的数据组织结构会不断的变化来支持查询的优化。
元数据管理
• 元数据管理能力:bigquery支持万列的表,支持历史表的timetravel。一开始的元数据支持粗粒度的元数据,类似odps以及hive metastore,随着表的规模增加单点的性能问题凸显,分析性能的前提在于要读取的列的数量,这个是新元数据设计的基础。data skip表的表结构:表的字段和原表完全一致,只是字段的类型会被替换为一个结构体的类型CMETATYPE:

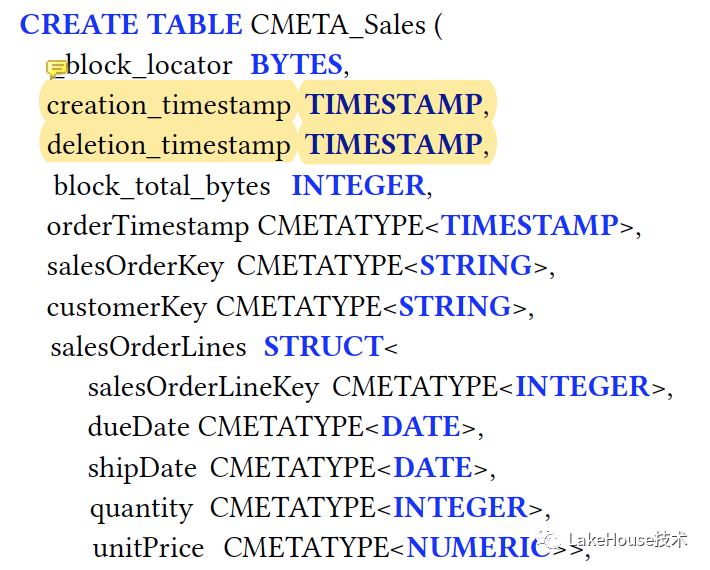

• 元数据表的增量生成:增量更新的changlog存储在一个高可用的存储系统中,一份写到类似HDFS的服务做持久化,另外一份在dump出去之前会保存在内存
查询优化
data skip表的查询和数据的查询进行统一查询优化,也就是说对data skip表的访问的会作为一个子查询生成到统一的用户的SQL的查询优化中。用户的SQL:

嵌入data skip表子查询的查询优化的SQL:


Data skip表的元数据
data skip表支持按照分区键的最大值进行clustering,同时最新版本的数据通过物化视图来处理。data skip表的元数据为了提高查询效率,直接存储在逻辑元数据的中心元数据,相当于能够提高查询效率。
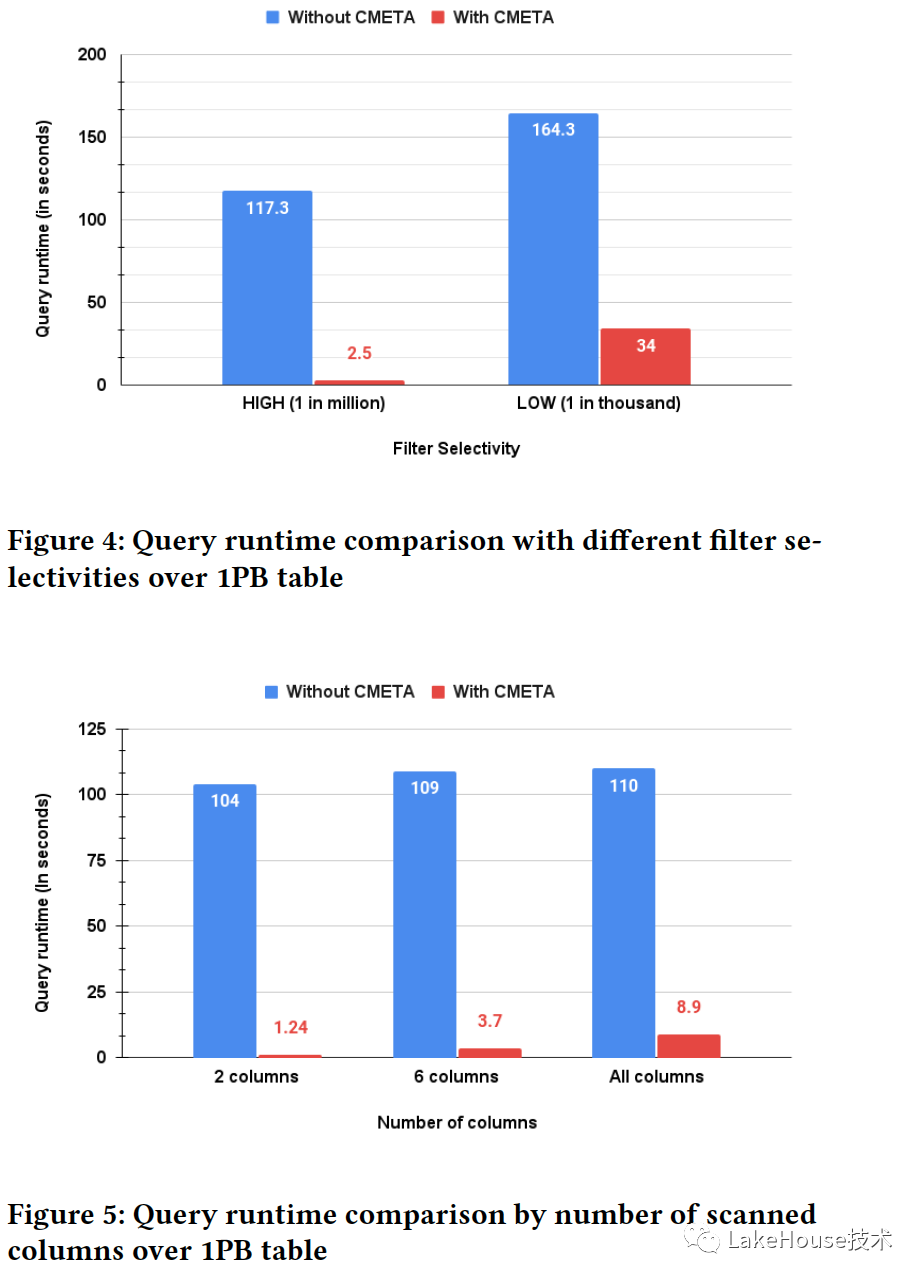
方案结果
可以看到对于大表的过滤型查询效果非常好。
学习感悟
这表论文呈现出了data skip表的完整的设计,从成熟度来看相比delta lake、Hudi要成熟更多,也说明了Google大数据相关的工作在业界是比较领先的。另外就是可以参考这篇论文快速的去Hudi里面实践落地了。
推荐阅读
Halodoc使用Apache Hudi构建Lakehouse的关键经验
印尼医疗龙头企业Halodoc的数据平台转型之Lakehouse架构
基于 Flink + Hudi 的实时数仓在 Shopee 的实践
