





许多从事微服务开发的朋友一直对CQRS是什么感到困扰。他们将CQRS视为一种架构;很遗憾的告诉大家,它不是。CQRS是一种非常简单的模式,它为原本设计很困难的架构提供了许多机会。
CQRS不是最终一致性,它不是事件、消息传递、没有分离的读写模型,也没有使用事件溯源。那么CQRS到底是什么呢?
在这里我将通过两篇文章系统讨论CQRS与DDD以及事件溯源之间的联系
1
CQRS是什么?
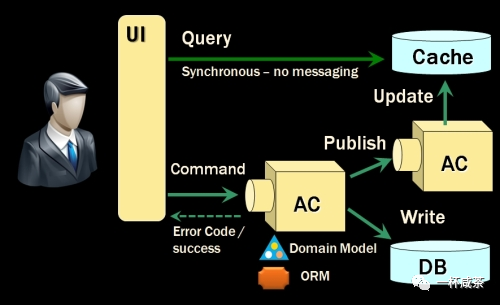
CQRS,Command Query Responsibility Segregation(命令查询责任分离),是Greg Young于2010年引入的一种设计模式。Grep本人基于Bertrand Meyer提出的这一想法,当被问及他认为CQRS是一种方法还是一种模式,如果是一种模式,它具体解决了什么问题?
“如果我们按照多年前对CQRS设定的定义,这将是一个非常简单的低层次模式。作为一种模式,它甚至没有那么有趣; 它更多的只是一些概念上的东西; ,你只需要分开。更有意思的是它能赋能什么。有趣的是这是模式所赋能的。每个人都被系统束缚住了,他们说CQRS很复杂是结合服务总线以及他们正在做的所有其他事情,实际上,这是没有必要的。如果你用最简单的定义,那么它就是一种模式。但更重要的是,一旦你采用了这种模式,你就会得到更多的机会。”
CQRS的其核心概念是,您可以使用不同的模型来更新信息,而不是使用用于读取信息的模型。在某些情况下,这种责任分离很有价值,但需警惕的一点是CQRS会增加系统风险的复杂性 。
CQRS只是创建了两个对象,而以前只有一个。分离的依据是命令还是方法(与Meyer对CQRS定义一样,命令是任何改变状态的方法,查询是任何返回值的方法)
当大多数人讨论CQRS时,他们实际上是在讨论将CQRS模式应用于表示应用程序服务边界的对象。对下面的伪代码进行分析:
CustomerServicevoid MakeCustomerPreferred(CustomerId)Customer GetCustomer(CustomerId)CustomerSet GetCustomersWithName(Name)CustomerSet GetPreferredCustomers()void ChangeCustomerLocale(CustomerId, NewLocale)void CreateCustomer(Customer)void EditCustomerDetails(CustomerDetails)
应用CQRS后产生两个服务
CustomerWriteServicevoid MakeCustomerPreferred(CustomerId)void ChangeCustomerLocale(CustomerId, NewLocale)void CreateCustomer(Customer)
void EditCustomerDetails(CustomerDetails)
CustomerReadServiceCustomer GetCustomer(CustomerId)CustomerSet GetCustomersWithName(Name)CustomerSet GetPreferredCustomers()
这就是整个CQRS模式。当我们这样解释它时候,他似乎没有多有意思,多牛逼,对吧。然而,这种分离的方式使我们能够在架构上做许多有趣的事情,最大的一点是它打破了研发人员智力模型思考惯性:因为二者使用相同的数据,所以他们也应该使用相同的数据模型
2
为什么选择CQRS?
通常情况下,用户与信息系统交互的主流方法是可以看作是对数据的CRUD,也就是对数据进行增删改查(Create/Read/Update/Delete)。简单点,可以把这些交互看作是对于数据的存储和检索两种操作。
随着业务需求变得越加复杂,我们需要摆脱这种交互方式。希望以不同的方式检索那些已存储的数据,譬如将多个数据合并为一个,或者通过组合不同来源的信息来形成虚构的数据;在更新操作时,我们可能会发现只被允许存储对数据组合的验证规则,或者可能存储推测的数据而非我们所提供的。
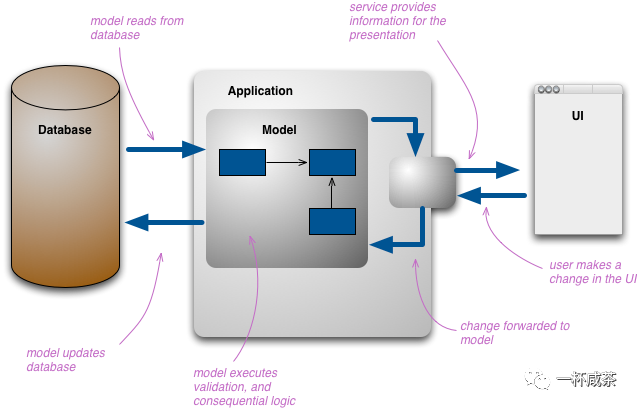
当用户与信息交互时,会有对应的前端数据表现形式,每一种表现形式可能都不同。开发人员会根据这些数据表现形式构筑自己的概念模型并操纵自己脑海中模型的核心元素。如果使用领域模型,那么这个概念模型就称为领域,同时开发人员会持久化数据,持久化的数据应该尽可能接近数据模型,以避免更多的中间过程修改。
对于水平切片的多层架构来说,其数据模型的结构可能会相当复杂。但是也可以将其视作一个概念整体,例如下图中的model,充当所有单个概念模型的概念集成点。
在解释为什么使用CQRS之前,我们需要了解其背后的两个主要驱动力:协作性(collaboration)和陈旧性(staleness)。
协作性:指多个参与者将使用/修改同一组数据的情况--无论参与者的实际意图是否是相互协作。通常有一些规则来表示某个用户可以执行某些修改,而在一些情况下这种修改可以被接受但在另一情况下就不行。其中参与者可能是人也可能是软件。
陈旧性:指在协作环境中,一旦向用户显示数据,相同的数据可能已经被另一个参与者修改--它是陈旧的。几乎所有使用缓存的系统都在提供老的数据--通常是出于性能的考虑。这意味着我们不能完全相信用户的决定,因为他们可能是根据过时的信息做出的反应。
对于常见的集中式架构(分层架构)并没有明确解决这两问题中的任何一个。虽然将所有内容放在同一个数据库可能是朝着处理协作的方向做出的努力,但在这种架构中,由于使用缓存作为提高性能的事后考虑,数据陈旧性通常反而更严重。
知道了传统开发方式(CRUD)所表征的概念模型,业务需求变动所带来多样化数据查询的诉求,以及CQRS核心解决的两个问题;我们来从以下几个角度来分析,为什么引入CQRS:
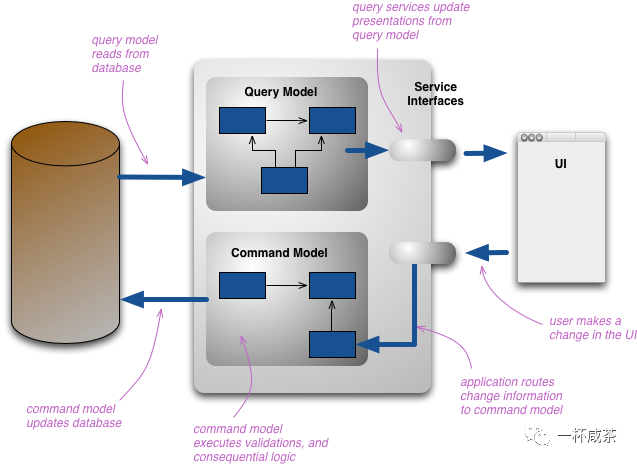
引述1:简化查询诉求
如果我们要向用户展示的数据无论如何都会是老的数据,真的有必要去从主数据库中拿数据吗?如果我们只想要数据而不是任何规则或者保存行为,为什么要将这些第3范式结构转换为领域对象?为什么要将这些领域对象再转换为DTO,并通过特定的“线路”传输他们,谁又能保证“线路”一定是准确无误的?为什么又要将这些DTO转换为用户可查看的模型对象?
简而言之,看起来我们做了很多没有必要的工作,假设重用已经编写的代码比解决手头上的问题更容易。让我们尝试另外一种方法:
我们如何创建一个额外的数据存储器,其数据可能与主数据库有些许不同步--言外之意就是向用户展示的数据是过时的,所以为啥不反映在数据存储器本身呢。稍后我们将提出一种方法来使这个数据存储多多少少要保持同步。
那么现在,这个数据存储器应该是什么样子的呢?就像视图模型一样如何?每个视图一个表,然后我们的客户端可以简单地SELECT * FROM viewTable(或者加一个Where子句来传入一个ID),最后将结果绑定到前端屏幕,那这样就再简单不过了。如果你觉得有必要,可以用一个很薄的外观来包装数据存储器,或者使用存储过程,或者使用AutoMapper,或者EFCore,它可以很简单地从数据读取器映射到你的视图模型类。问题是视图模型结构已经是足够友好的,因此不需要将它们转换为其他任何东西。
你甚至可以考虑获取数据存储并将其放入您的Web层。它与Web层中的内存缓存一样安全。只授予网络服务器对这些表的查询权限,应该是可以的。
引述2:多种数据存储器的诉求
注:数据存储器:对文件,文档或其他形式内容以数字方式记录并保存在存储系统中以供后续查询使用。
虽然可以使用常规数据库作为查询数据存储器,但它不是唯一的选择。考虑到查询数据的本质上要与视图模型相同。由于各种视图模型类之间没有任何关系,因此不需要查询数据存储器中的表之间的任何关系。
所以这个时候问自己一个问题,真的需要关系型数据库吗?
答案是否定的,但是处于所有实际目的并且由于组织的开发团队的惯性,这个选择仍然是最佳选择。
可拓展性(缩放查询和预先计算)
假设现在的查询是在与主数据库不同的另一数据存储器中执行的,并且其中数据也没要求是100%最新的,因此可以轻松添加这些存储器的更多实例,而不必担心数据的一致性。更新一个实例的机制可以用于多个实例。
这为查询提供了廉价的水平缩放。此外,代码也没有进行太多的转换,因此每个查询的延迟也会降下来。简单的代码就是快速的代码
同时,当我们希望在短时间内且O(1)复杂度下获取数据实体时,但一般情况下数据总是和其他实体有很多关联关系,我们同时又希望避免更多爆炸量数据库表的Jion。解决办法就是:
在数据更改时,在请求之前预先把结果算出来。这样可以避免请求时使用更少的资源,将减少响应延迟并使其是可被稳定预测的。这个时候通常会引入Redis避免数据库过载(常见的三大问题:缓存击穿,缓存穿透,)
并发(数据更改)
由于用户是根据陈旧的数据做出的决定,因此我们需要对这些决定进行辨别并确认用户的更改。
假设目前有这么一个场景:有一个销售代表正在和客户打电话。客户正在查看自己的个人信息,并期望把他作为“首选”客户,同时修改他们的地址,更改他的性别,姓氏以及婚姻状态。用户不知道的是,打开屏幕之后,财务部收到一个消息,表明该客户拖欠支付账单。此时,销售代表同意并提交了对客户信息的更改。
那么问题来了,我们允许这个更改吗?
好吧,我们应该接受其他客户个人信息的更改,而不应该把客户作为“首选”客户。由于客户的诚信原因,他不应看作优质客户。按以往的经验,编写这些检查会是一个头疼的事儿。需要对数据进行比较,推断更改的含义,那些是相互关联的(名称及性别),那些是独立的,确定要检查有没有数据冲突--不仅仅与用户检索到的数据进行比较,还要与数据库中当前状态数据状态进行比较,然后再做出决定:拒绝还是接受更改。
不幸的是,对于用户来说,如果其中任何一个环节出了问题,我们往往会拒绝整个事情。那时,用户必须刷新他们的屏幕以获取最新数据,并重新输入所有以前的更改;只能希望这次用户不会因为乐观的并发问题而情绪崩溃而骂娘。
随着系统组织的数据模型越大包含的字段越多,当更多的用户对这种数据模型进行操作时,同时更改某些属性的可能性越大,从而增大了并发冲突的可能性和数量。
这个时候我们如果将这些数据模型拆分为“写入模型”和“读取模型”,是不是有助于我们分离对单一数据模型操作的复杂性(谁需要啥?谁负责啥?)并增加我们解决问题的灵活性,因而可以适应越来越复杂模型和业务变化的诉求。
这个时候我们更多考虑的是责任:谁改了啥?用例是啥?客户提交的数据合乎规则吗?是否要进行中断?这是不是另一个应用程序的责任吗?那些用户只需读数据?这些数据应该是强一致性的吗?等等这些问题会接踵而来。由于这种思维方式,CQRS通常和DDD联系在一起,来划定领域问题域。
从技术角度来讲,CQRS还可以简化对并发和事务数据库锁的管理。当使用异步CQRS模式时,经常讨论的是:“数据最终一致性”、“数据生命周期”,“数据所有权”、“业务需求”,以及其他建模的内容(实体事务边界和一定不变量)。这些讨论的点,同样在利用DDD确定数据聚合时经常提及的,这也就是CQRS是面向DDD的原因。
CQRS设计意图
核心设计思想:重新思考用户界面的设计,以期使我们能快速捕捉用户的意图。这样,找出客户首要关注点,而不是一次次的去确认客户是不是搬家了还是结婚了,这些屁话。如上述所属,使用类似Excel表格的界面,进行数据更改时候并不能准确捕捉用户意图。
有了CQRS的拆分,我们甚至可以考虑在服务器发送已收到前一个命令的确认消息之前,允许用户提交一个新的命令。然后在网页左侧展示用户所有待执行的命令,服务器收到这些之后可以异步检查并消费处理这些命令,假设失败了,也可以更改这个命令的执行状态,然后用户再点击失败命令查看失败详情。
注意:这里的命令的发送,应区别于事件发布。事件发布是在传递已经发生的事实表述:发生了啥,发布方时不需care接收方是咋处理的。而命令不同,命令是准备要执行的操作描述,用户是关注操作的结果的成功与否。
首先我们需要明确一点:对于异步CQRS,用户针对陈旧数据进行相应的操作,并将这些操作(命令)提交(发送)后,立马刷新当前页面,这个时候用户并不能立马看到更改后的结果。对于这种情况,前端可以通过“乐观并发”来展示“正确”的结果:预先缓存这些旧数据数据并假设对其更改是实际生效的,在重新获取新数据前,以这种Fake期望值展示出去给客户。如果执行结果出现差异,则再返回正确数据时进行调整。
当是同步CQRS时,那么会有这样的语义环境:在同一个事务中将两个模型写入不同的表中。它总是同步的。
但是,CQRS很少是同步的,因为如上我们希望使用不同资源、不同数据库(数据存储器)类型、使用RabbitMQ这种消息传递基础设施进行开发和业务拓展
综上所述CQRS旨在:为多用户协作的应用程序,提供适当的架构实现方式。它明确考虑数据陈旧和数据波动等因素,利用这些特征去创建更简易和更具拓展性的结构;将处理命令的责任与处理无副作用查询(读取访问)的责任严格分开。
3
CQRS什么时候使用?
何时使用
与很多设计模式一样,都有它适用的场景。许多系统确实适合老式的CRUD心智模型,对于传统集中式架构的开发人员来讲,CQRS是一个重大的精神跨域,需要抛弃经验主义,从逻辑上区分出两个模型。除非CQRS的引入益处很大,否则不应该引入。
那么适用CQRS的场景大体上有那些呢,请看:
开发的系统后续可能会有很多业务上的变动;
企业尚不清楚具体业务发展方向,存在可拓展的业务和技术诉求;
需要与其他业务领域的团队合作(有其他限界上下文);
当前开发的服务和其他已存在的服务有一定耦合关系;
当前服务是面向写入的,不读自身的数据;
业务领域非常复杂;
系统对性能有极高的要求;
与其他架构模式的结合
与基于任务的UI(响应式界面)结合
与EDA(事件驱动架构)的结合,常常会伴随着时间溯源和流处理讨论;
与一致性和可用性权衡后选择最终一致性的分布式结合;
与需预先执行大量逻辑和计算后才做更新操作的模型结合;
当需对用户行为进行监控查询分析时(所有更新会产生对应事件并存入库中),与CQRS结合会避免单一模型导致大量数据库的交互;
与领域驱动设计结合;
缺点和注意事项
尽管CQRS有这么多便利,在引入时候应该非常谨慎和小心。对于很多信息系统来讲,数据更新和读取方式相同,引入CQRS会徒增复杂性,会严重拖垮生产力,给项目增加不必要的风险。
对于命令端和查询端有较大的重叠时,共享数据模型更容易构建。
对于独立简单的API或明确定义范围的API,复杂性和资源消耗反倒很大。
对于不匹配的领域模型上使用CQRS会徒增复杂性降低生产力而增加系统性的风险.
对于上一条不匹配的领域内,但是它的查询要求极高,使用CQRS仍会带来复杂性或性能消耗。
引入CQRS会给团队(开发人员和业务)带来“变化”的恐惧,改变开发方式。
需对团队带来“变化”,作一些必要的解释:
当我们以读模型+写模型方式去组织业务逻辑或代码时,总会在系统某一时刻存在重复(复制)数据;团队当中存在一些人(譬如我)如此害怕重复数据,觉得这是一种反模式。他们认为:数据就应该只有一个Owener,这个主人是唯一可以控制谁可以访问的人,没有人可以复制这个数据到自己数据库或消息传递的基础服务中。如果想要这个数据,必须调我的API接口!!!
虽说这种观念有一定道理:重复性数据会导致复杂性、更多依赖性、糟糕的性能、服务中断、SLA减少.
维基百科:SLA -- Service Level Argeement 服务等级协议、服务水平协议,分布式服务提供商与客户之间定义的正式承诺。服务提供商与受服务用户(双方或多方关系)之间具体达成了承诺的指标(质量、可用性、责任)
拓展文章:"一文了解字节跳动如何解决 SLA 治理难题".

X轴(低级技术):服务和数据的水平复制、再造缓存、负载均衡数据
Y轴(组织):划割功能为独立(微)服务来处理不同问题域,来处理自身数据--
Z轴(高级分片):沿客户边界的服务和数据分区;应将相似的东西(每个资源ID、地理位置),每个用例分割为自身的基础架构.
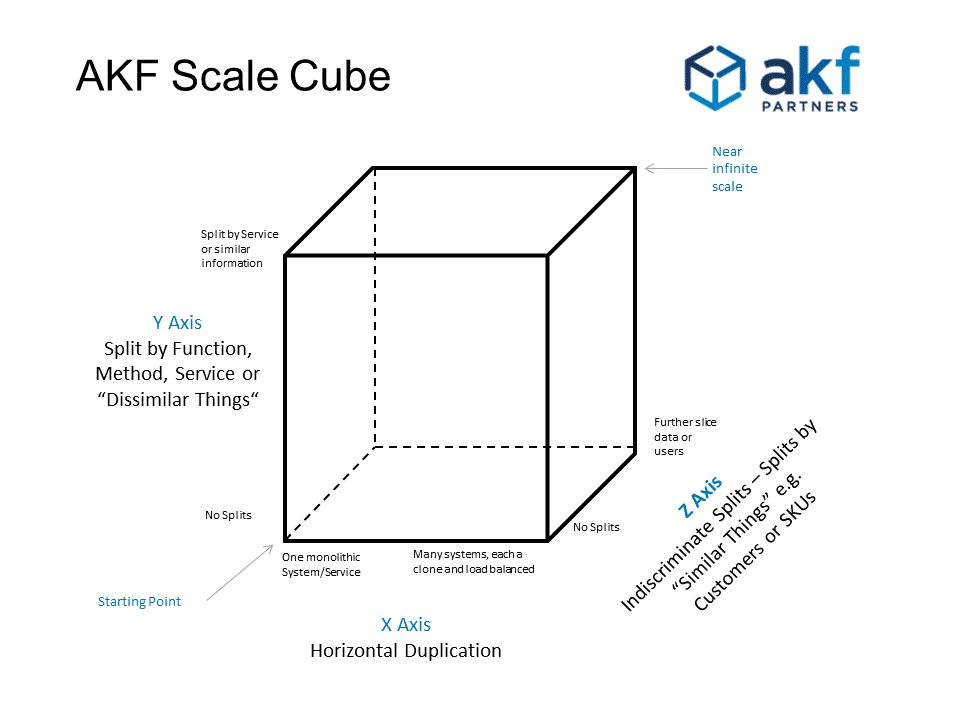
关于这个方法论的具体描述请看原文
4
如何科学实现CQRS?
实现Command
Command;对写入模型进行写入操作的方法;是一个我们经常用来设计的通用术语: 改变系统状态的东西(任何类型的更新);
具有以下特点:
命令可以是简单的API调用;
命令可以同步或异步处理;
命令可以通过消息总线发送也可以不不通;
命令可以是一个做OOP(面向对象)也可以不做的超类;
命令可以是简单的函数调用;
所有上述的特点你在任何一个命令身上都能找到影子,我们期许命令以某种方式改变某些状态。命令表示了我们的意图(而不是事实),并且会产生对应的副作用(对资源)。它被用于指向特定目的,并在Consumer Domain--消费域(the Codomain--到达域).
命令通常被定义为‘动词+其它’,例如CreateOrder,Update-UserInfo.之类。
命令通常是以行为为中心,而不是以数据为中心。它是关于改变某些东西的意图,不映射资源的格式,也不是某些中间数据状态的表征,譬如API的DTO.它包含有助于处理意图的数据,仅此而已。
要强调的一点是:如何处理命令,也就是说如何处理写入模型,才是实现CQRS的关键
那么现在我们就来揭示CQRS的关键,处理命令的方式总是大同小异:
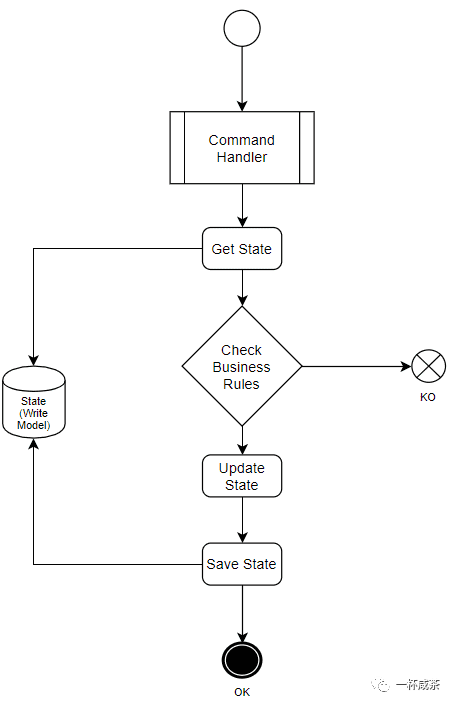
如果是异步的,将其保存到消息传递的基础设施中,并将ok返回给调用者;
无论同步异步,都根据它的形式(API,消息,函数调用)来调用正确CommandHandler(一个函数)来处理它;
CommandHandler必须来判定它是否可以处理它:
CommandHandler在处理前必须从数据库或者通过事件回溯,获取到当前状态;同时使用预先定;义好的业务规则来确定是否可以确认或拒绝此刻状态下的命令
如果上面判定允许该命令可执行,CommandHandler会将命令应用于当前状态后,可以产生对应的事件也可以不产生;
保存新的状态;
如果为同步,CommandHandler会返回Ok给调用者,或者返回极少的信息,譬如ID,但不会返回整个状态(当前写入模型);
如果是异步,则将消息提交到消息传递基础设施中。
在这里我们需要注意的几点是:命令应该遵循一个叫做“即发即忘”的原则;不应期望获取命令执行的任何除“成功”和“失败”之外的其他结果。命令仅仅只是一个请求,处理可是同步也可以是异步的;不要心想立马给老子返回结果,因为这个结果稍后会在读取模型中反映出来。
命令处理程序必须包含业务逻辑,以便能够立即拒绝或接受命令。
public class CreateOrderCommand{public class Command : ICommand<Result>{public decimal Price { get; set; }public Guid ProductId { get; set; }public int Count { get; set; }public Guid UserId { get; set; }}public class Result{public Guid Id { get; set; }}public class Validator : AbstractValidator<Command>{public Validator(){//The business rules.RuleFor(cmd => cmd.TotalPrice).GreaterThanOrEqualTo(30);RuleFor(cmd => cmd.ProductId).NotEmpty();RuleFor(cmd => cmd.UserId).NotEmpty();RuleFor(cmd => cmd.Count).GreaterThanOrEqualTo(1);}}public class Handler : ICommandHandler<Command, Result>{private readonly IRepository<OrderAggregate> _repository;public Handler(IRepository<OrderAggregate> repository){_repository = repository;}public async Task<Result> Handle(Command command, CancellationToken cancellationToken){var order = OrderAggregate.CreateMovie(command.Price, command.ProductId, command.Count, command.UserId);await _repository.Add(order);var result = new Result{Id = order.Id};return result;}}}
关于Command还有很多注意事项,就不在这里具体展开讲了,大家可以自行去了解;就在这里简单再提几点内容:
Command的处理应该是幂等的
Command无法使用读取端读取数据
Command应只处于技术原因重试命令,而不应出于业务原因重试命令,结果可能会不同(例如重试时,此时获取价格调整)
Command可以被保存在Command Bus中以至后续处理
实现Query;
处理完CQRS的核心,我们来逐步梳理读取模型所带来的变化和常见的实现方式:让我们回顾一下最早期之前未拆分的读取一体模型,如果目前有各式不同的读取数据诉求时,我们会依据这种一体模型构建不同的读取模型。
当需要查询数据以响应不同的用例时,我们习惯于在某种单一形式的数据库(MySql,MongoDB,Postgre-SQL,SQL),对其中含有的原始数据事实进行操作/更新后获取期望的数据。但同时这个时候又希望使用专门的数据库以不同的方式解释数据,例如:
缓存数据
快速的文本搜索
图形语言查询
带有连贯时间属性的时序数据
对多维数组进行预先计算
使用实时数据库向客户端发送实时更新。
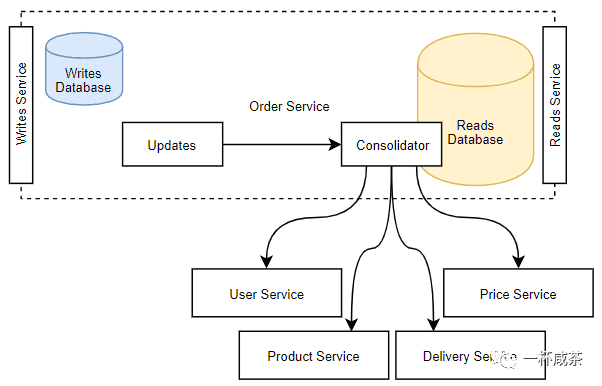
问题1:新老系统或服务兼容
在开发新系统时,往往是希望将新服务或系统集成在现有的老旧系统中。传统的老旧系统无法或者不想适应新系统的思维模式和沟通形式。那么新系统只需要一个API来重用旧系统所能理解的格式来获取数据。所以可能新系统需要一组不同的服务来构建老旧系统的视图和业务规则所反映的模型。
因为老的遗留模型往往采取的是集中式单体架构,其具有着跨领域的更多数据,而且可能还继承了更古老的系统条件约束。重新推倒重做是不可能的,所以只能保证服务的连续和重叠性。
问题2:多数据库下读写责任分离的约束
当使用多种数据库之后,引入了一个隐式约束:读取服务必须只处理读取,而不是写入。由于数据最新最真实的来源不是从读取来的。
读取数据库与写入数据库之间没有同步。读取数据库不能对写入数据库产生任何副作用。由于非常规的操作,甚至都无法读取到最原始记录。同样的,当我们查询一个API时,也不希望改变数据。
最终一致性
从第二段描述我们可知,使用读取服务的人是在对陈旧数据做处理。
当发送一个Command要处理的数据时,处理是异步完成的(没有结果,即发即忘),所以对读取数据库的更新也将是异步的。(除非是同一个数据库,但这种开发方式很少见)
举个栗子,目前有订单服务,产品服务,邮件服务:
T0:发送关于A1101号订单的AddProductToOrderCommand命令(v1)
T1:写服务更新A1101号订单包含的产品信息(v2)
T2:通知读服务并根据订单新产品查询产品服务,以更新视图上产品的名称和描述(处理中)
T3:此时邮件服务也收到了写服务的通知,需要读服务来获取订单最新的详细信息,此时邮件服务内的数据还尚未更新(最早的数据版本),因为读取服务还在处理T2的其他关联请求(v1)
T4:产品服务返回响应到读取服务,该服务最终可以更新其读取数据库(v2)
在T3时,虽然之前更新发生在T2(绝对时间)之前,但读取服务依然发送了旧版本的订单给邮件服务(v1),因为此时读取服务获取到的数据还不是最新的。我们无法知道系统重新聚合最新实体需要多长时间。这也就是CQRS的隐含语义:“Read your own writes",以及我们与其它系统对话时,必须要考虑最终一致性的问题。
其中版本在这样的系统中是强制必须的。它代表了一种逻辑时刻,一个单调的计数器,以协调帮助我们理解系统流程如何运行并进行逻辑决策的。版本并不是唯一选择,也可以用向量时钟和CRDT结构处理事件排序的因果关系。通常是外部系统不需要知道的事,这是内部服务或系统的混乱,需要这么一个标志来消除噪音。
但是有人非想要保证写入和读取数据库之间的强一致性,那么就需要自动更新(但是目前大多数系统都是以异构系统组织业务的,这种情况很少发生)。哪怕这样做了,也将失去依赖不同系统提供的可用性(CAP定理)。
通过明确分离的两个系统,读取服务独立于写入服务工作:不同生命周期、不同的部署、不同的约束、不同的SLA。
读取服务具备的功能;
读取服务可以提供比写入服务更多的功能。双方的参与者与用例都不怎么一样。读取服务可以拥有的功能大致有:
验证
缓存
加密
限流,对读取速率约束
有限保留
弹性缩放
主从复制和负载均衡
数据分片
用于实时更新的SSE(Server-sent events)或Websockts(推送)
如何实现Query服务;
假设目前是没有事件传递机制的情况下,此时我们需要一个数据库同步程序来同步写入数据库和读取数据库之间的差异。此时构建读取服务需要的技术列表:
双写
在代码中,当我们使用ORM写入数据库A时,我们可以引入其他数据库B进行写入。必须引入事务或适当的其他方式来确保它们之间的原子性或一致性
数据库同步
每隔几分钟复制和转换一次数据的批处理;或者一个“几乎实时”的后台服务,每几分钟轮询一次
变更数据捕获(CDC)
将数据库更改派生为事件流;
依赖复制日志充当数据库发出的事件;然后对这些事件进行一些流处理;
Kafka Connect和Debezium组合进行的数据流处理的一大市场
事件
订阅现有事件(在原始状态被更改时发布)并从它们构建我们读取状态(从过去重放)到任何数据库
隐藏 Lambda 架构
与批处理视图合并的实时视图
综上,最好的方式还是依靠带有Pub/Sub基础服务的事件。从本质上讲,CQRS已经将发布者和消费者分离了。这也就是为什么CQRS会和事件紧密关联的原因之一。
5
总结
通过近一万多字的了解之后,其实CQRS本身就是一个很简单且微不足道的模式。他的有趣地方不在于自身,而围绕着CQRS做出的架构决策,后续系列文章会详细展开来讲。
当下很多企业都想将应用程序迁移到云或为云开发应用程序,CQRS并不是非必须的。但是,许多使用云的驱动因素,例如对可扩展性、弹性和敏捷性的要求,也是采用 CQRS 模式的驱动因素。此外,通常作为平台即服务 (PaaS) 云计算平台的一部分提供的许多服务非常适合为 CQRS 实施构建基础架构:例如,高度可扩展的数据存储、消息传递服务和缓存服务。
END




排版 | Ethan
文章 | Ethan
图文 | 部分内容和图片摘至网络

