




介绍启动容器时候,默认情况下Docker是怎么组织网络的,保证容器可以连通
tips: 默认观者已具备并熟悉Docker各种命令行和概念,能创建,运行,查看容器
问题 1:二层网络和三层网络的区别和作用 ?
答:
首先二层、三层并不是指ISO七层网络模型中的数据链路层和网络层,而是指核心层、汇聚层和接入层,是按照逻辑拓扑结构上进行分类的
核心层
核心层是整个网络的支撑脊梁和数据传输通道,重要性不言而喻。
因此在整个三层网络结构中,核心层对设备要求是最高的,必须配备高性能的数据冗余转接设备和防止负载过剩的均衡负载的设备,以降低各核心层交换机所承载的数据量
汇聚层
汇聚层是连接网络的核心层和各个接入层的应用层,在两层之间承担“媒介传输”的作用。
汇聚层应具备以下功能:
实施安全功能(划分VLAN和配置ACL【Access Control List】访问控制列表
工作组整体接入功能
虚拟网络过滤功能
因此汇聚层设备应采用三层交换机
接入层
接入层的面向对象是终端用户,为终端用户提供接入功能;
二层网络
二层网络只有核心层与接入层,这样的网络结构模式运行简便,交换机根据MAC地址表进行数据包的转发
如果存在MAC地址进行转发,不存在MAC地址进行泛洪,也就是说数据包广播发送到所有端口,如果目的终端收到给出回应,那么交换机就可以将该MAC地址添加到地址表中,这是交换机对MAC地址进行建立的过程
但是这样频繁地对未知的MAC目标的数据包进行广播,在大规模的网络架中形成的网络风暴是非常庞大的,这也很大程度上限制了二层网络规模的扩大,因此二层网络的组网能力非常有限,所以一般知识用来搭建小局域网
三层网络
二层网络仅仅通过MAC寻址即可实现通讯,但仅仅是同一个冲突域内;三层网络则需要通过IP路由实现跨网段的通讯,可以跨多个冲突域
三层交换机在一定程度上可以替代路由器,但是应该清醒地认识到三层交换机出现最重要的目的是加快大型局域网内部的数据交换
它所具备的路由功能也多是围绕这一目的而展开的,所以它的路由功能没有同一档次的专业路由器强,在安全、协议支持等方面还有很多欠缺,并不能完全取代路由器工作
在实际应用过程中,典型的做法就是:处于同一局域网中的各个子网的互联以及局域网中VLAN间的路由,用三层交换机来代替路由,而只有局域网与公网互联之间要实际跨地域的网络访问时,才通过专业路由器
问题 2:Linux中 IP命令如何使用 ?
答:
Linux的IP命令和ifconfig类似,但IP命令功能更强大,并旨在取代后者。使用IP命令,只需一个命令,你就能很轻松地执行一些网络管理任务。ifconfig是net-tools中已被废弃使用的一个命令,许多年前就没有在维护。Linux系统提供iproute2工具替代了一些常用的net-tools命令,iproute2套件里提供了很多增强功能的命令,ip命令即是其中之一
1.格式:
ip [options] object [command[arguments]]
2.主要参数:
OPTIONS是修改ip行为或改变器输出的选项。所有选项都是以-字符开头,分长、短两种形式。如link,addr,route、rule、tunnel
object是要管理者获取信息的对象。如网络接口类型eth0
command设置针对指定对象执行的操作、它和对象的类型有关。一般情况下,ip支持对象的增加(add)、删除(delete)和展示(show或list)。有些对象不支持这些操作,或者有其他的一些命令。对于所有的对象,用户可以使用help命令获的帮助。这个命令会列出这个对象的支持的命令和参数的语法。如果没有指定对象的操作命令,ip会使用默认的命令。一般情况下,默认命令是list,如果对象不能列出,就会执行help命令
arguments是命令的一些参数,他们依赖于对象和命令。ip支持两种类型的参数,flag和parameter。flag由一个关键词组成;parameter由一个关键词加一个数值组成。为了方便,每个命令都一个可以忽略的默认参数。例如,参数dev是ip link 命令的默认参数,因此,ip link ls eth0 等于 ip link Is dev eth0 命令的默认参数将使用default标出
IP地址管理
设置和删除IP地址
请注意ip地址要有一个后缀,比如/24.这种用法用于在无类域内路由选择(CIDR)中来显示所用的子网掩码。在这个例子中,子网掩码是255.255.255.0
设置一个IP地址,使用以下命令
需要查看是否已经生效
删除IP地址
ip addr del 192.168.0.193/24 dev wlan0ip addr show wlan0ip addr add 192.168.0.193/24 dev wlan0
路由管理
列出路由表条目
添加默认路由
ip route add default via 192.168.202.254添加网络路由
ip route add 192.168.4.0/24 via 192.168.4.1修改网络路由
ip route change 192.168.4.0/24 dev eth1设置NAT由$
查看某个路由表信息
擦除路由表
ip route show

假设现在有个ip地址,你需要指导路由包从哪里来,可以使用下面的路由选项(列出了路由所使用的接口等)
ip route get 119.75.216.20$

ip命令的路由对象的参数还可以帮助你查看网络中的路由数据,并设置你的路由表。第一个条是默认的路由条目,你可以随意更改它
ip route add nat 192.168.1.100 via 192.168.1.1
$ ip route show table main$ ip route show table local$ ip route show table all
ip route fluship route flush cache
网络统计
显示网络统计数据
ip -s -s link ls docker0ip -s link或 ip -s link ls docker0
使用ip命令还可以显示不同网络接口的统计数据;当需要获取一个特定网络接口的信息时,在网络接口名字后面添加选项ls即可。使用多个选项-s会给你特定接口更详细的信息。特别是在排除网络连接故障时,这会非常有用
ARP管理
查看ARP信息
地址解析协议(ARP)用于将一个ip地址转换成它的对应物理地址,也就是通常所说的MAC地址。使用ip命令的neigh或者neighbour选项,你可以查看接入你所在的局域网的设备的MAC地址 $
ip neighbour
网络监测
监控netlink消息
可以使用ip命令查看netlink消息。monitor选项允许你查看网络设备的状态。比如,所在局域网的一台电脑根据它的状态可以被分类成REACHABLE或者STALE。使用下面的命令:
$ ip monitor all
$
网络接口设置
激活和停止网络接口
你可以使用ip命令的up和down选项来激活某个特定的接口,就像ifconfig的用法一样
停止网络接
$ ip link set eth0 down启动网络接口eth0
$ ip link set eth0 up修改设置传输队列的长度
$ ip link set dev eth0 txqueuelen 100$或$ ip link set dev eth0 txqlen 100修改网络设置MTU(最大传输单元)的值
ip link set dev eth0 mtu 1500修改网卡的MAC地址
ip link set dev eth0 address 00:01:4f:00:15:f1
$
路由策略设置$
ip rule 命令中包含add、delete、show(或者list)等子命令。
注意:策略路由(policy routing)不等于路由策略(routing policy)。
在某些情况下,我们不只是需要通过数据包的目的地址决定路由,可能还需要通过其他一些域:源地址、ip协议、传输层端口甚至数据包的负载。这就叫做策略路由(policy routing)
插入新的规则
ip rule add删除规则
ip rule delete显示路由表信息
ip rule list
$
$子命令可以用如下缩写:
add:a;
delete:del/d
双网卡数据路由策略选择,让来自192.168.3.0/24的数据包走11.0.0.254这个网关,来自192.168.4.0/24的数据包走12.0.0.254这个网关
定义表
$ ech0 10 clinet_cnc >>/etc/iproute2/rt_tables$$ ech0 20 clinet_tel >>/etc/iproute2/rt_tables
$
把规则放入表中
$ ip rule add from 192.168.3.0/24 table clinet_cnc$$ ip rule add from 192.168.4.0/24 table clinet_tel
$
添加策略路由
$ ip route add default via 11.0.0.254 table clinet_cnc$$ ip route add default via 12.0.0.254 table clinet_tel
$
刷新路由表
$ ip route flush cache
$
问题 3:Linux Network Namespace的概念 ?
答:
Network Namespece是实现网络虚拟化的重要功能,他能创建多个隔离的网络空间,它能创建多个隔离的网络空间,它们由独自的网络栈信息。不管是虚拟机还是容器,运行的时候仿佛自己就在独立的网络中。以下操作通过ip命令来完成各种操作。ip命令来自于iproute2安装包,一般系统会默认安装
那么什么是network namespace?
一般来说,Linux的安装共享一组网络接口和路由表条目。您可以使用策略路由来修改路由表条目,但这并没有从根本上改变网络接口和路由表集的事实/条目在整个操作系统中共享。Network Namespace改变了这一基本假设。使用Network Namespace,可以拥有彼此独立运行的不同且独立的网络接口和路由表实例。
提示: ip命令因为需要修改系统的网络配置,默认需要sudo权限。请不要在生产环境或者重要的系统中用root直接执行,以防产生错误
ip命令管理的功能很多,和network namespace 有关的操作都是在子命令$ ip netns$ 进行的,可以通过ip netns help 查看所有操作的帮助信息
默认情况下,使用ip netns 是没有网络namespaces 的,所以ip netns ls命令看不到任何输出
[root@localhost ~]# ip netns helpUsage: ip netns listip netns add NAMEip netns delete NAMEip netns identify PIDip netns pids NAMEip netns exec NAME cmd ...ip netns monitor[root@localhost ~]# ip netns ls
创建Network Namespace也非常简单,直接使用ip netns add 后面跟着要创建的namespace名称。如果相同名字的namespace已经存在,则命令会报 Cannot create namespace的错误
[root@localhost ~]# ip netns add net1[root@localhost ~]# ip netns lsnet1
$ ip netns $ 命令创建的network namespace 会出现在 $ /var/run/netns/$ 目录下,如果需要管理其他不是 $ ip netns$ 创建的network namespace,只要在这个目录下创建一个指向对应network namespace文件的连接就行
有了自己创建的Network Namespace,我们还需要看它里面有那些东西。对于每个network namespace来说,它会有自己独立的网卡、路由表、ARP表、iptables等和网络相关的资源。ip命令提供了ip netns exec 子命令可以在对应的network namespace 中执行命令,比如我们要看一下这个network namespace 中有哪些网卡。更棒的是,要执行的可以是任何命令,不只是和网络相关的(当然,和网络无关命令执行的结果和在外部执行没有区别)。
比如下面的例子中,执行bash命令之后,后面所有的命令都是在这个network namesapce 中执行的,好处是不用每次执行命令都要把 $ ip netns exec NAME$ 补全,缺点是你无法清除知道自己当前所在的shell,容易混淆。
[root@localhost ~]# ip netns exec net1 ip addr1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWNlink/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00[root@localhost ~]# ip netns exec net1 bash[root@localhost ~]# ip addr1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWNlink/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00[root@localhost ~]# exitexit
更新:通过修改bash的前缀信息可以区分不同shell,操作如下:
$ ip netns exec ns1 bin/bash --rcfile <(echo "PS1=\"namespace ns1> \"")namespace ns1> ping www.google.comPING www.google.com (178.60.128.38) 56(84) bytes of data.64 bytes from cache.google.com (178.60.128.38): icmp_seq=1 ttl=58 time=17.6 ms
ip netns exec 后面跟着namespace的名字,比如这里的net1,然后是要执行的命令,只要是合法的shell命令都能运行,比如上面 ip addr或者bash
每个namespace在创建的时候会自动创建一个lo的interface,它的作用和linux系统中默认看到的lo一样,都是为了实现loopback通信。如果希望lo能工作,不要忘记启用它:
[root@localhost ~]# ip netns exec net1 ip link set lo up
默认情况下,network namespace是不能和主机网络,或者其他network namespace通信的
$ 问题 4:不同 Network Namespace是如何通信的 ?
答:
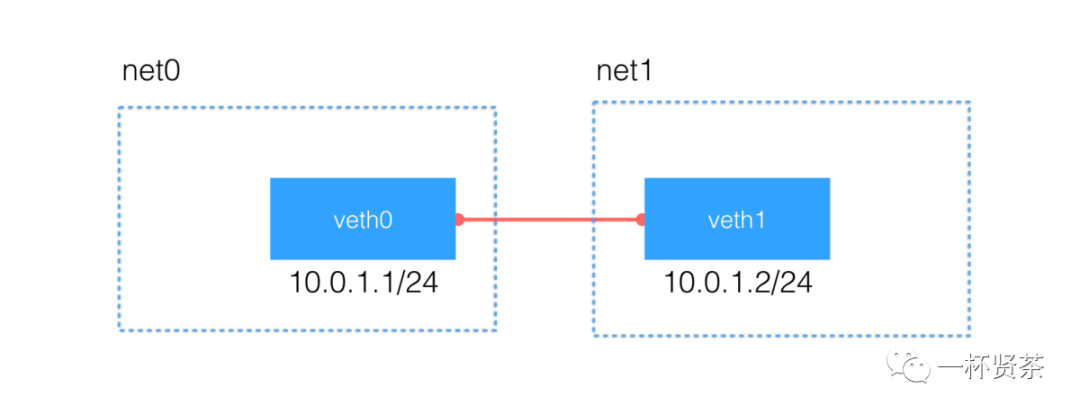
有了不同network namespace之后,也就有了网络的隔离,但是如果他们之间没有办法通信,也没有实际的用处。要把两个网络连接起来,linux提供了$ veth pair$ 。可以把 $ veth pair$ 当作是双向的pipe(管道),从一个方向发送的网络数据,可以直接被另一端接收到;或者也可以想象成两个namespace直接通过一个特殊的虚拟网卡连接起来,可以直接通信。
使用上面提到的方法,我们再创建另外一个Network Namespace,这里我们使用net0和net1两个名字
我们可以使用ip link add type veth来创建一对veth pair出来,需要记住的是veth pair无法单独存在,删除其中一个,另外一个也会自动消失
[root@localhost ~]# ip link add type veth[root@localhost ~]# ip link4: veth0: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT qlen 1000link/ether 36:88:73:83:c9:64 brd ff:ff:ff:ff:ff:ff5: veth1: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT qlen 1000link/ether fe:7e:75:4d:79:2e brd ff:ff:ff:ff:ff:ff
创建 veth pair的时候可以自己指定他们的名字,比如:
$ ip link add vethfoo type veth peer name vethbar
$
创建出来的两个名字就是vethfoo 和 vethbar。因为这里我们对名字没有特殊要求,所以直接使用系统自动生成的名字。
如果pair的一段接口处于DOWN 状态,另一端能自动检测到这个信息,并把自己的状态设置为 $ NO-CARRIER$ 创建结束之后,我们能看到名字为veth0和veth1两个网络接口,名字后面的数字是系统自动生成的。接下来要做的就是把这对 veth pair 分别放到已知的两个namespace里面,这个可以使用
$ ip link set DEV netns NAME$ 来实现
[root@localhost ~]# ip link set veth0 netns net0[root@localhost ~]# ip link set veth1 netns net1[root@localhost ~]# ip netns exec net0 ip addr1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWNlink/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:004: veth0: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN qlen 1000link/ether 36:88:73:83:c9:64 brd ff:ff:ff:ff:ff:ff[root@localhost ~]# ip netns exec net1 ip addr1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWNlink/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:005: veth1: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN qlen 1000link/ether fe:7e:75:4d:79:2e brd ff:ff:ff:ff:ff:ff
最后,给这对veth pair配置上ip地址,并启用他们
[root@localhost ~]# ip netns exec net0 ip link set veth0 up[root@localhost ~]# ip netns exec net0 ip addr add 10.0.1.1/24 dev veth[root@localhost ~]# ip netns exec net0 ip route10.0.1.0/24 dev veth0 proto kernel scope link src 10.0.1.1[root@localhost ~]# ip netns exec net1 ip link set veth1 up[root@localhost ~]# ip netns exec net1 ip addr add 10.0.1.2/24 dev veth1
可以看到,在每个namespace中,在配置完ip之后,还自动生成了对应的路由表信息,网络 10.0.1.1/24数据报文都会通过veth pair 进行传输。使用ping命令可以验证它们的连通性:
[root@localhost ~]# ip netns exec net0 ping -c 3 10.0.1.2PING 10.0.1.2 (10.0.1.2) 56(84) bytes of data.64 bytes from 10.0.1.2: icmp_seq=1 ttl=64 time=0.039 ms64 bytes from 10.0.1.2: icmp_seq=2 ttl=64 time=0.039 ms64 bytes from 10.0.1.2: icmp_seq=3 ttl=64 time=0.139 ms--- 10.0.1.2 ping statistics ---3 packets transmitted, 3 received, 0% packet loss, time 2004msrtt min/avg/max/mdev = 0.039/0.072/0.139/0.047 ms
完成以上操作,我们创建的网络拓扑结构如下:
问题 5:如何使用 bridge 连接不同的 namespace?
答:
虽然veth pair 可以实现两个network namespace之间的通信,但是当多个namespace需要通信时候,就无能为力了。
讲到多个网络设备通信时,我们首先应首先想到交换机和路由器,因为这里要考虑的只是同个网络,所以只能用到交换机的功能。Linux当然也提供了虚拟交换机的功能。但是我们还是用ip命令来完成所有的操作。
提示:和bridge有关的操作也可以使用命令brctl,这个命令来自bride-utils这个包,读者可以根据自己的发行版进行安装,使用方法请查阅man页面或者相关文档。
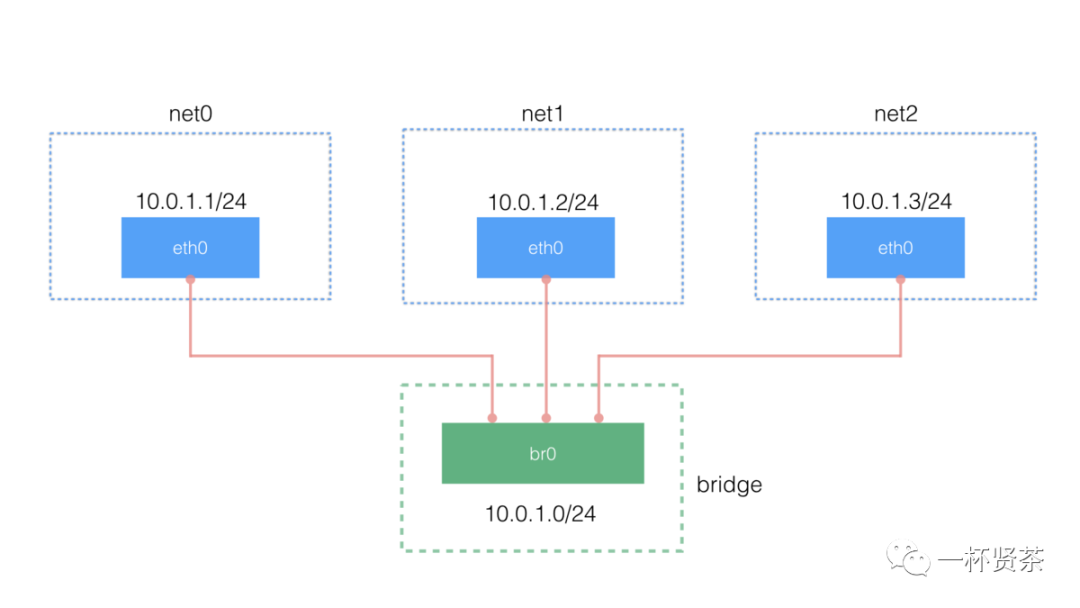
首先我们来创建需要的bridge,为简单起见,名字就叫做br0
[root@localhost ~]# ip link add br0 type bridge[root@localhost ~]# ip link set dev br0 up
下面只演示了一个namespace的操作,其他namespace要做的事情和这个类似。创建 veth pair:
[root@localhost ~]# ip link add type veth
把其中一个veth(veth1)放到net0里面,设置它的ip地址并启用它
[root@localhost ~]# ip link set dev veth1 netns net0[root@localhost ~]# ip netns exec net0 ip link set dev veth1 name eth0[root@localhost ~]# ip netns exec net0 ip addr add 10.0.1.1/24 dev eth0[root@localhost ~]# ip netns exec net0 ip link set dev eth0 up
最后,把另一个veth(veth0)连接到创建的bridge上,并启用它:
[root@localhost ~]# ip link set dev veth0 master br0[root@localhost ~]# ip link set dev veth0 up
可以通过bridge命令(也是iproute2包自带的命令)来查看bridge管理的link信息:
[root@localhost ~]# bridge link17: veth0 state UP : <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 master br0 state forwarding priority 32 cost 2
最后通过ping命令来测试网络的连通性:
[root@localhost ~]# ip netns exec net0 ping -c 3 10.0.1.3PING 10.0.1.3 (10.0.1.3) 56(84) bytes of data.64 bytes from 10.0.1.3: icmp_seq=1 ttl=64 time=0.251 ms64 bytes from 10.0.1.3: icmp_seq=2 ttl=64 time=0.047 ms64 bytes from 10.0.1.3: icmp_seq=3 ttl=64 time=0.046 ms--- 10.0.1.3 ping statistics ---3 packets transmitted, 3 received, 0% packet loss, time 2008ms
下面是这部分网络的拓扑结构,如果对docker网络熟悉的话,其实这和docker默认的bridge网络模型十分相似。当然要实现每个namespace对外网的访问还需要额外的配置(设置默认网关,开启ip_forward,为网络添加NAT规则等)。
问题 6:如何通俗的解释网桥 (Virtual Bridge)的概念 ?
答 :
弄清楚以下几个概念就自然明白了网桥:
集线器(hub)
一个口接收到的信号,原封不动的发送给所有其他的口,由其他的口上的设备自己决定是否接收信号。有点类似广播,但是比广播更纯粹。由于hub只是简单的转发,所以hub工作在物理层(L1)
网桥(bridge)
工作在数据链路层(L2).以太网中,数据链路层地址就是MAC地址,网桥与集线器的区别在于,网桥会过滤MAC,只有目标的MAC地址匹配的数据才会发送到出口。一个bridge指的是一个输入到一个输出的桥接。
交换机(switch)
早期的switch,其实可以看成多个bridge的集成设备,因此也工作在数据链路层。一个交换机口的输入到另一个交换机的输出,可以认为是一个bridging.交换机中的MAC table,实际上为了bridge能工作而存在。一个N口交换机堪称是N*(N-1) 也就是A²n个网桥集合
但是事情也不是绝对的,随着技术的发展,也常听到L3 switch,也就是说switch也可以包含routing功能
路由器(router)
工作在网络层(L3),基于ip地址做转发
通俗的说,网桥就是一个二层桥接设备,桥接(bridging)就是把桥的两端连接起来,但不是所有的流量都放行,只有目的的MAC地址(二层)匹配的才放行
其中容易混淆的是网桥和交换机的概念,现在普遍认为的交换机可以同时具有bridging和routing两种功能。其中bridging与网桥相关。交换机更像是一个兼顾二层,三层的设备
问题 7:什么是 Veth Pair ?其功能又是什么 ?
答:
Veth是虚拟以太网卡(VirtualEthernet)的缩写。Veth设备总是成对的,因此我们称之为vethpair。Vethpair一段发送的数据会再另一端接收,非常类似Linux的双向管道。根据这一特性,vethpair常被用于跨networknamespace之间的通信,即分别将vethpair的两端放在不同的namespace里
图1
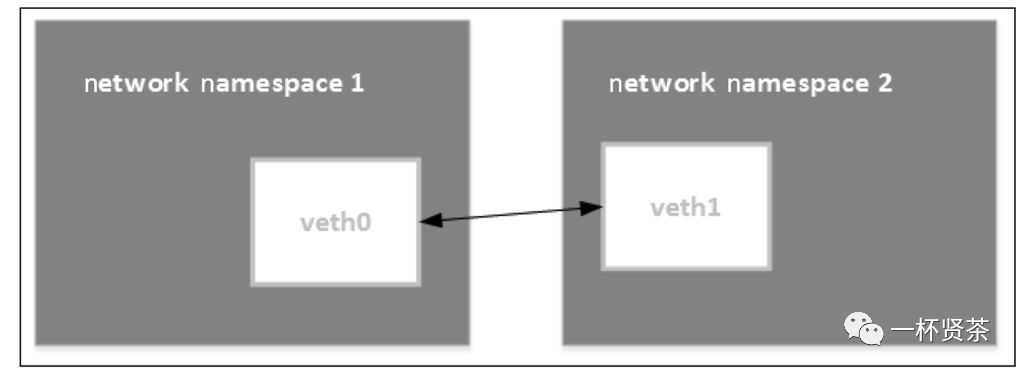
仅有veth pair 设备,容器仍是无法访问外部网络的。因为从容器内发出的数据包,实际上是直接进了veth pair设备的协议栈。如果容器需要访问网络,则需要使用网桥等技术将veth pair设备接收的数据包通过某种方式转发出去。
顾名思义,veth pair 就是一对的虚拟网络设备接口,一端连接着网络协议栈,另外一端彼此相连。如下图所示:
图2
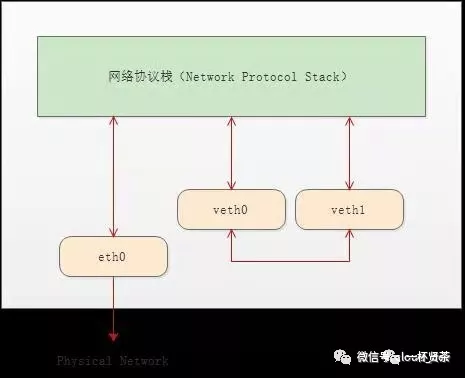
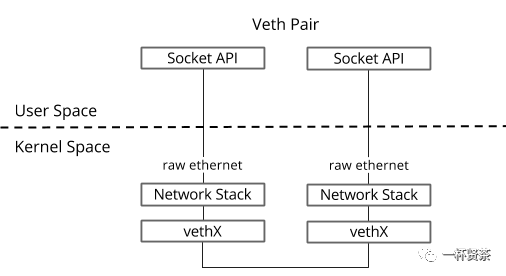
正因有此特性,它常常充当一个桥梁,连接着各种虚拟网络设备,典型的例子像上述图1所示,“两个namespace之间的链接”,“Bridge、OVS之间的链接”,抑或是“Docker容器之间的链接”等等,以此构建出非常复杂的虚拟网络结构,比如OpenStack Neutron
问题 8:veth-pair连通性 ?
答:
对于图1中veth0和veth1分别配上ip:10.1.1.2和10.1.1.3,然后从veth0 ping 一下veth1.理论上它们处于同一网段下,是能ping通的,但结果却是ping不通。
通过抓包 $ tcpdump -nnt -i veth0
$
输出:
$ root@ubuntu:~# tcpdump -nnt -i veth0 $$ tcpdump: verbose output suppressed, use -v or -vv for full protocol decode$$ listening on veth0, link-type EN10MB (Ethernet), capture size 262144 bytes $$ ARP, Request who-has 10.1.1.3 tell 10.1.1.2, length 28 $$ ARP, Request who-has 10.1.1.3 tell 10.1.1.2, length 28
$
可以看到,由于veth0和veth1处于同一个网段,且是第一次连接,所以会事先发送ARP包,但veth1并没有响应ARP包。
经查,由于Ubuntu系统内核中一些ARP相关的默认配置限制所导致,需修改以下配置项:
$ echo 1 > /proc/sys/net/ipv4/conf/veth1/accept_local$$ echo 1 > /proc/sys/net/ipv4/conf/veth0/accept_local$$ echo 0 > /proc/sys/net/ipv4/conf/all/rp_filter$$ echo 0 > /proc/sys/net/ipv4/conf/veth0/rp_filter$$ echo 0 > /proc/sys/net/ipv4/conf/veth1/rp_filter
$
再次ping之后就可行了
$
root@ubuntu:~# ping -I veth0 10.1.1.3 -c 2PING 10.1.1.3 (10.1.1.3) from 10.1.1.2 veth0: 56(84) bytes of data.64 bytes from 10.1.1.3: icmp_seq=1 ttl=64 time=0.047 ms64 bytes from 10.1.1.3: icmp_seq=2 ttl=64 time=0.064 ms--- 10.1.1.3 ping statistics ---2 packets transmitted, 2 received, 0% packet loss, time 3008msrtt min/avg/max/mdev = 0.047/0.072/0.113/0.025 ms
问题 9:Veth-Pair通信过程是怎样的呢 ?
答 :
上面连通性的解释,我们通过对两个虚拟网口设备进行抓包进行以下分析:
对于veth0口:
root@ubuntu:~# tcpdump -nnt -i veth0tcpdump: verbose output suppressed, use -v or -vv for full protocol decodelistening on veth0, link-type EN10MB (Ethernet), capture size 262144 bytesARP, Request who-has 10.1.1.3 tell 10.1.1.2, length 28ARP, Reply 10.1.1.3 is-at 5a:07:76:8e:fb:cd, length 28IP 10.1.1.2 > 10.1.1.3: ICMP echo request, id 2189, seq 1, length 64IP 10.1.1.2 > 10.1.1.3: ICMP echo request, id 2189, seq 2, length 64IP 10.1.1.2 > 10.1.1.3: ICMP echo request, id 2189, seq 3, length 64IP 10.1.1.2 > 10.1.1.3: ICMP echo request, id 2244, seq 1, length 64
对于veth1口:
root@ubuntu:~# tcpdump -nnt -i veth1tcpdump: verbose output suppressed, use -v or -vv for full protocol decodelistening on veth1, link-type EN10MB (Ethernet), capture size 262144 bytesARP, Request who-has 10.1.1.3 tell 10.1.1.2, length 28ARP, Reply 10.1.1.3 is-at 5a:07:76:8e:fb:cd, length 28IP 10.1.1.2 > 10.1.1.3: ICMP echo request, id 2189, seq 1, length 64IP 10.1.1.2 > 10.1.1.3: ICMP echo request, id 2189, seq 2, length 64IP 10.1.1.2 > 10.1.1.3: ICMP echo request, id 2189, seq 3, length 64IP 10.1.1.2 > 10.1.1.3: ICMP echo request, id 2244, seq 1, length 64
从上述抓包结果可以发现,并没有看到ICMP的echo reply包,那么它是怎么ping通的呢?
其实这里echo reply走的是localback口,我们来抓localback口的来验证猜想
root@ubuntu:~# tcpdump -nnt -i lotcpdump: verbose output suppressed, use -v or -vv for full protocol decodelistening on lo, link-type EN10MB (Ethernet), capture size 262144 bytesIP 10.1.1.3 > 10.1.1.2: ICMP echo reply, id 2244, seq 1, length 64IP 10.1.1.3 > 10.1.1.2: ICMP echo reply, id 2244, seq 2, length 64IP 10.1.1.3 > 10.1.1.2: ICMP echo reply, id 2244, seq 3, length 64IP 10.1.1.3 > 10.1.1.2: ICMP echo reply, id 2244, seq 4, length 64
那么为什么会走localback口呢?
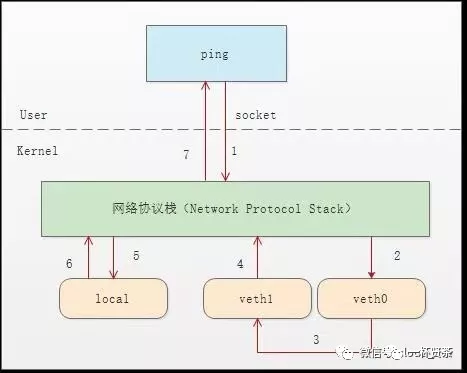
通过分析整个通信流程,可以一窥其中奥秘:
首先ping程序构造ICMP $ echo request$ ,通过socket发给协议栈
由于ping指定了走veth0口,如果是第一次,则需要发送ARP请求,否则协议栈直接将数据包交给veth0。
由于veth0连着veth1,所以ICMP request直接发给veth1。
veth1收到请求后,交给另一端的协议栈
协议栈看本地10.1.1.3这个ip,于是构造了ICMP reply包,查看路由表,发现会给10.1.1.0网段的数据包应该走localback口,于是将reply包交给lo口(会优先查看路由表的0号表,ip route show table 0查看)
lo收到协议栈的reply包后,啥也不干,转手又返回给协议栈
协议栈收到reply包之后,发现有socket再等待包,于是将包给socket。
等待在用户态的ping程序发现socket返回,于是就收到 ICMP的reply包
整个通信过程如下图所示:
问题 10:两个Namespace之间的连通性及其连接方式?
答:
namespace是自Linux 2.6X内核版本之后支持的特性,主要用于资源的隔离。有了namespace,Linux系统就可以抽象出多个网络子系统,各个子系统间都有自己的网络设备,协议等等,彼此之间不受影响。
如果各个namespace之间需要通信,需要veth-pair来做桥梁。
根据链接方式和规模,分为“直接相连”,“通过Bridge相连”和“通过OVS相连”
直接相连
直接相连是最简单的方式,如下图,一对veth-pair直接将两个namespace连接在一起
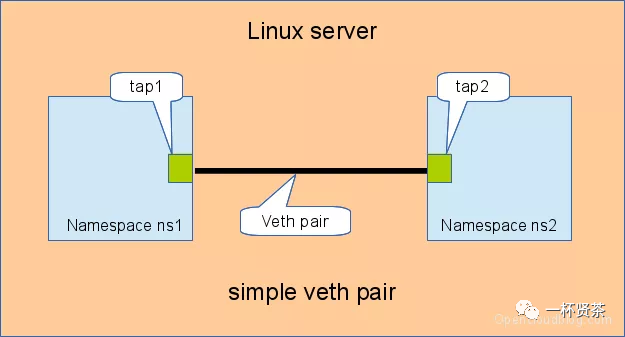
给veth-pair配置IP,测试连通性
创建 namespace
ip netns a ns1ip netns a ns2
创建一对 veth-pair veth0 veth1
ip l a veth0 type veth peer name veth1
将 veth0 veth1 分别加入两个 ns
ip l s veth0 netns ns1ip l s veth1 netns ns2
给两个 veth0 veth1 配上 IP 并启用
ip netns exec ns1 ip a a 10.1.1.2/24 dev veth0ip netns exec ns1 ip l s veth0 upip netns exec ns2 ip a a 10.1.1.3/24 dev veth1ip netns exec ns2 ip l s veth1 up
从 veth0 ping veth1
[root@localhost ~]# ip netns exec ns1 ping 10.1.1.3PING 10.1.1.3 (10.1.1.3) 56(84) bytes of data.64 bytes from 10.1.1.3: icmp_seq=1 ttl=64 time=0.073 ms64 bytes from 10.1.1.3: icmp_seq=2 ttl=64 time=0.068 ms--- 10.1.1.3 ping statistics ---15 packets transmitted, 15 received, 0% packet loss, time 14000msrtt min/avg/max/mdev = 0.068/0.084/0.201/0.032 ms
通过Bridge相连
Linux Bridge相当于一台交换机,可以中转两个namespace的流量,我们看看veth-pair在其中扮演的什么角色
如下图,两对儿veth-pair分别将两个namespace链接到Bridge上
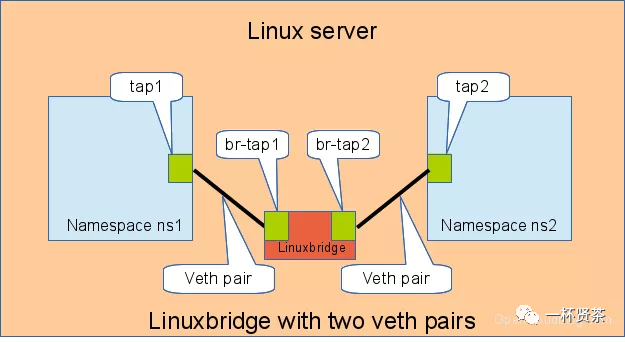
同样通过veth-pair配置IP,实验测试连通性
首先创建 bridge br0
ip l a br0 type bridgeip l s br0 up
然后创建两对 veth-pair
ip l a veth0 type veth peer name br-veth0ip l a veth1 type veth peer name br-veth1
分别将两对 veth-pair 加入两个 ns 和 br0
ip l s veth0 netns ns1ip l s br-veth0 master br0ip l s br-veth0 upip l s veth1 netns ns2ip l s br-veth1 master br0ip l s br-veth1 up
给两个 ns 中的 veth 配置 IP 并启用
ip netns exec ns1 ip a a 10.1.1.2/24 dev veth0ip netns exec ns1 ip l s veth0 upip netns exec ns2 ip a a 10.1.1.3/24 dev veth1ip netns exec ns2 ip l s veth1 up
veth0 ping veth1
[root@localhost ~]# ip netns exec ns1 ping 10.1.1.3PING 10.1.1.3 (10.1.1.3) 56(84) bytes of data.64 bytes from 10.1.1.3: icmp_seq=1 ttl=64 time=0.060 ms64 bytes from 10.1.1.3: icmp_seq=2 ttl=64 time=0.105 ms--- 10.1.1.3 ping statistics ---2 packets transmitted, 2 received, 0% packet loss, time 999msrtt min/avg/max/mdev = 0.060/0.082/0.105/0.024 ms
通过OVS相连
OVS是第三方开源的Bridge,功能比Linux Bridge要强大,对于同样的实验,我们用OVS查看效果

测试两个namespace之间的连通性:
用 ovs 提供的命令创建一个 ovs bridge
ovs-vsctl add-br ovs-br
创建两对 veth-pair
ip l a veth0 type veth peer name ovs-veth0ip l a veth1 type veth peer name ovs-veth1
将 veth-pair 两端分别加入到 ns 和 ovs bridge 中
ip l s veth0 netns ns1ovs-vsctl add-port ovs-br ovs-veth0ip l s ovs-veth0 upip l s veth1 netns ns2ovs-vsctl add-port ovs-br ovs-veth1ip l s ovs-veth1 up
给 ns 中的 veth 配置 IP 并启用
ip netns exec ns1 ip a a 10.1.1.2/24 dev veth0ip netns exec ns1 ip l s veth0 upip netns exec ns2 ip a a 10.1.1.3/24 dev veth1ip netns exec ns2 ip l s veth1 up
veth0 ping veth1
[root@localhost ~]# ip netns exec ns1 ping 10.1.1.3PING 10.1.1.3 (10.1.1.3) 56(84) bytes of data.64 bytes from 10.1.1.3: icmp_seq=1 ttl=64 time=0.311 ms64 bytes from 10.1.1.3: icmp_seq=2 ttl=64 time=0.087 ms--- 10.1.1.3 ping statistics ---2 packets transmitted, 2 received, 0% packet loss, time 999msrtt min/avg/max/mdev = 0.087/0.199/0.311/0.112 ms
经过上述三个经典实验,我们可以看到;veth-pair在虚拟网络中充当着桥梁的角色、链接多种网络设备构成复杂的网络
虚拟机
虚拟机通过tun/tap或者其他类似的虚拟网络设备,将虚拟机内的网卡同br0连接起来,这样就达到和真实交换机一样的效果,虚拟机发出去的数据包先到达br0,然后由br0交给eth0发送出去,数据包都不需要经过host机器的协议栈,效率高。如果有多个虚拟机,那么这些虚拟机通过tun/tap设备连接到网桥。
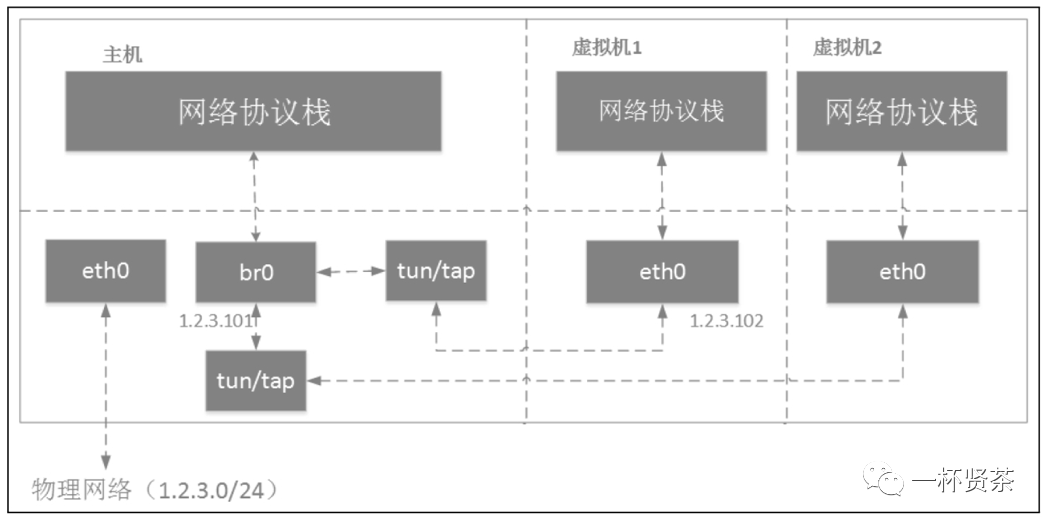
容器
容器运行在自己单独的network namespace里,因此都有自己单独的协议栈。Linux bridge在容器场景的组网和上面的虚拟机场景差不多,但也存在一些区别。例如,容器使用的veth pair设备,而虚拟机使用的是tun/tap设备。在虚拟机场景下, 我们给主机物理网卡eth0分配了ip地址;而在容器场景下,一般不会对宿主机eth0进行配置。在虚拟机场景下,虚拟机一般会和主机在同一网段;而在容器场景下,容器和物理网络不在同一网段内。Linux bridge在容器中的应用如下图:
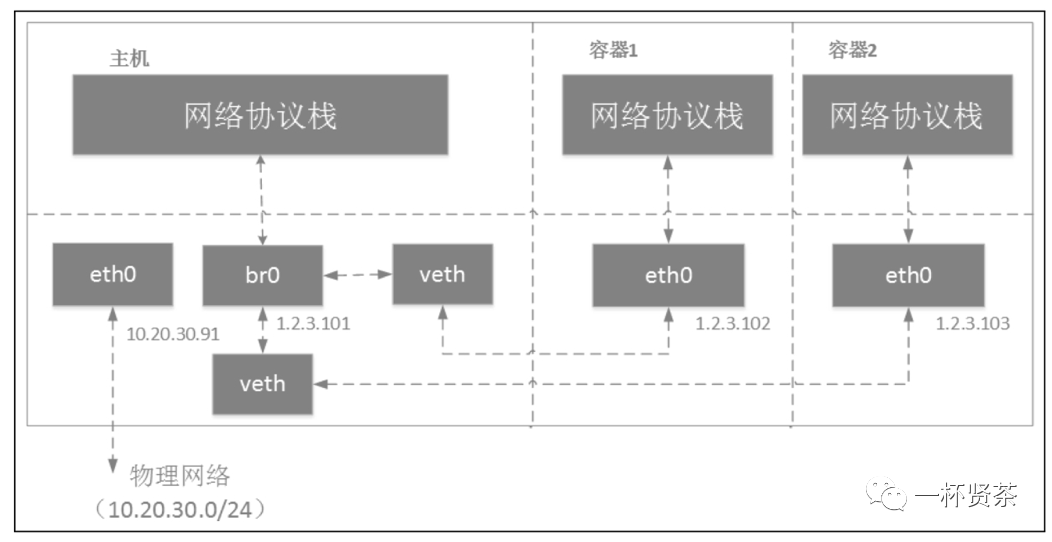
在容器中配置其网关地址为br0,在上图中即1.2.3.101(容器网络网段1.2.3.0/24)。因此,从容器发出去的数据包先到达br0,然后交给host机器协议栈。由于目的ip是外网ip,且host机器开启了IPforwar功能,数据包会通过eth0发送出去。因为容器所分配的网段一般都不在物理网络网段内(在上述例子中,物理网段是10.20.30.0/24),所以一般发出去之前先会做NAT转换(NAT转换需要自己配置,可以使用iptables)
网络接口的混杂模式
混杂模式(Promiscuousmode),简称Promiscmode,俗称“监听模式”。混杂模式通常被网络管理员用来诊断网络问题,但也会被无认证的、想偷听网络通信的人利用。根据维基百科的定义,混杂模式是指一个网卡把它所接受的所有网络流量都交给CPU,而不是只把它想转交的部分交给CPU。在IEEE802定义的网络规范中,每个网络帧都有一个目的MAC地址。在非混杂模式下,网卡只会接收目的MAC地址是它自己的单播帧,以及多播及广播帧;在混杂模式下,网卡会接收经过他的所有帧。
使用$ ifconfig$ 或者$ netstat -i$ 命令查看一个网卡是否开启了混杂模式。
$ ifconfig eth0$ ,查看eth0的配置,包括混杂模式。当输出包含PROMISC时,表明该网络接口处于混杂模式。
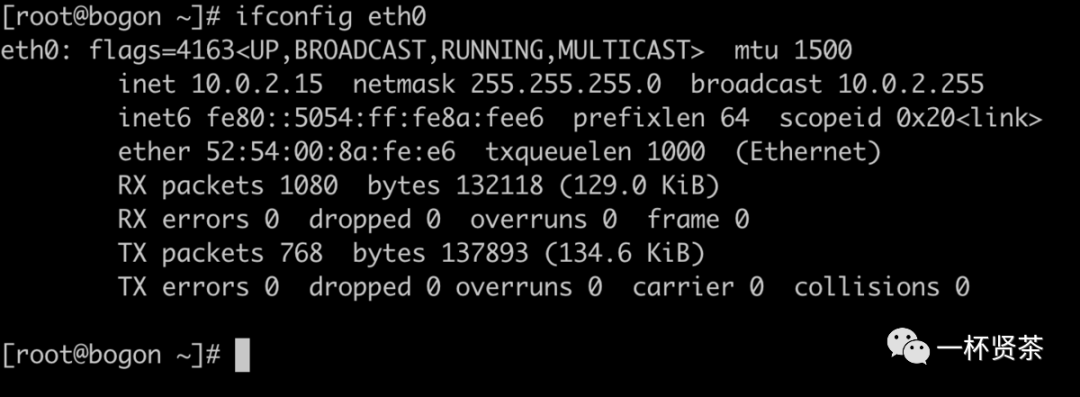
启用网卡的混杂模式,可以使用下面命令:
$ ifconfig eth0 promisc
$

使网卡推出混杂模式,可以使用下面如下命令
$ ifconfig eth0 -promisc
$

veth设备加入Linux bridge后,可以通过查看内核日志看到veth0自动进入混杂模式,而且无法退出,直到将veth0从Linux bridge中移除。
Iptables
iptables在Docker和Kubernetes网络中应用甚广。例如,Docker容器和宿主机的端口映射、Kubernetes
Service的默认模式、CNI的port map插件、Kubernetes网络策略等都是通过iptables实现的
Netfilter
iptables的底层实现是netfilter。netfilter是Linux内核2.4版引入的一个子系统。它作为一个通用的、抽象的框架,提供一整套hook函数的管理机制,使得数据包过滤、包处理(设置标志位、修改TTL等)、地址伪装、网络地址转换、透明代理、访问控制、基于协议类型的链接跟踪,甚至带宽限速等功能成为可能。netfiliter的架构就是在整个网络流程的若干位置放置一些钩子,并在每个钩子上挂在一些处理函数进行处理。
IP层的5个钩子点的位置,对应iptables就是5条内置链,分别是PREROUTING、POSTROUTING、INPUT、OUTPUT和FORWARD
如下图:
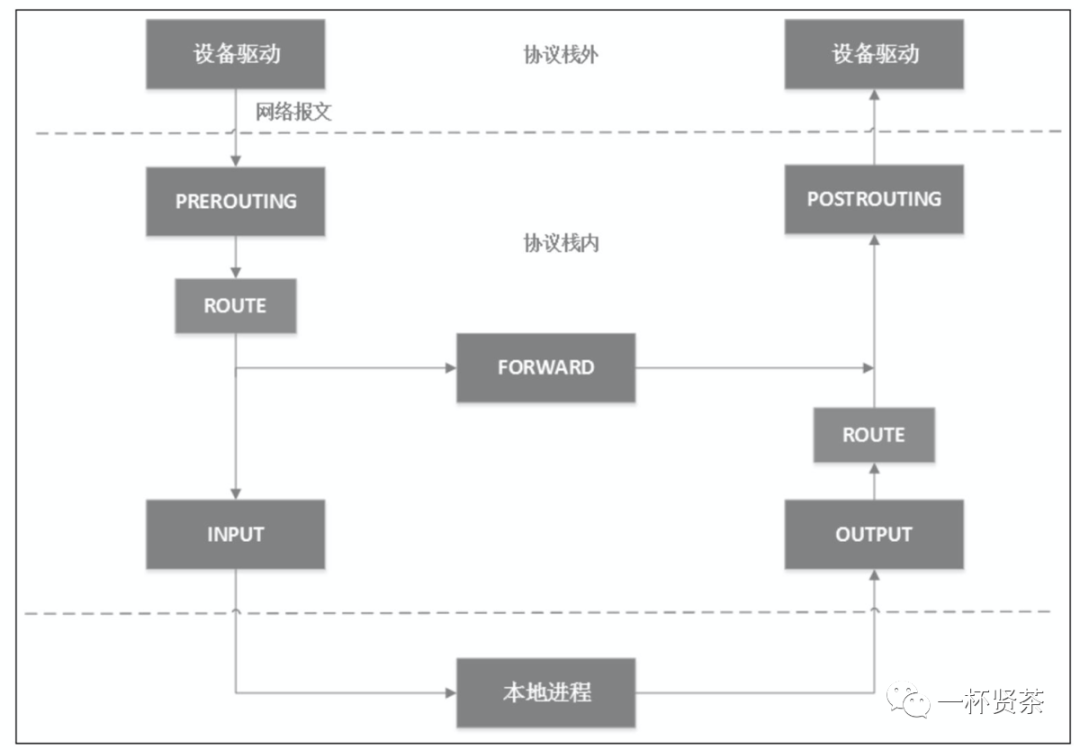
当网卡上收到一个包送达协议栈时,最先经过netfilter钩子是PREROUTING,如果确实有用户埋了这个钩子函数,那么内核将在这里对数据包进行目的地址的转换(DNAT)。不管PREROUTING有没有做过DNAT,内核都会通过查本地路由表决定这个数据包是发送给本地进程还是发送给其他机器。如果是发送给其他机器(或其他network namespace),就相当于把本地当作路由器,就会经过netfilter的forward钩子,用户可以在此设置包过滤钩子函数,例如iptables的reject函数。所有马上要发到协议栈的包都会经过POSTROUTING钩子,用户可以在这里埋下源地址转换(SNAT)或源地址伪装(Masquerade,简称Masq)的钩子函数。
如果经过上面的路由决策,内核决定把包发给本地进程,就会经过INPUT钩子。本地进程收到数据包后,回程报文会先经过OUTPUT钩子,然后经过一次路由决策(例如,决定从机器的那块网卡出去,下一跳地址是多少等),最后出协议栈的网络包同样会经过POSTROUTING钩子。
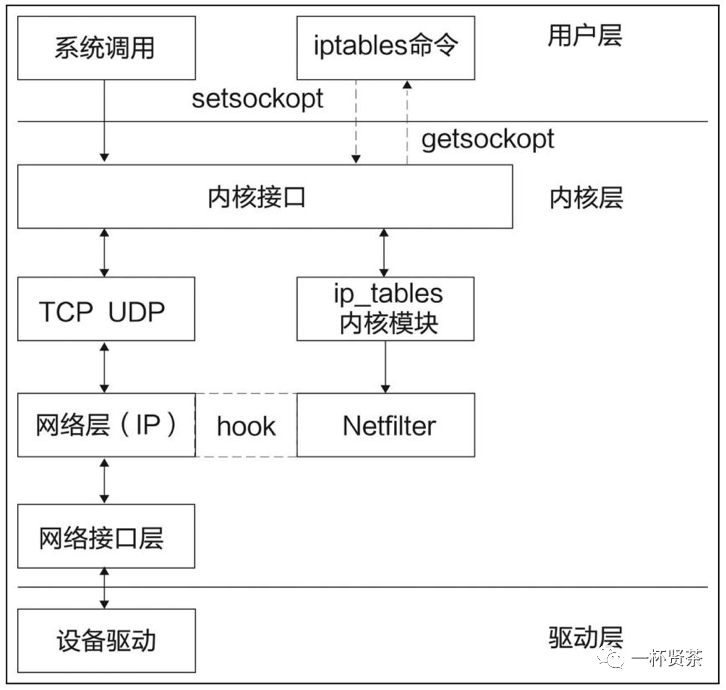
iptables
iptables是用户空间的一个程序,通过netlink和内核netfilter框架打交道,负责往钩子上配置回调函数。一般情况下用于构建Linux内核防火墙,特殊情况下也做服务负载均衡(这是Kubernetes特色操作)。
我们常说的iptables5X5,即5张表(table)和5条链(chain)。5条链即iptables的5条内置链,对应上文介绍的netfilter的5个钩子。这5条链分别是:
INPUT链:一般用于处理输入本地进程的数据包;
OUTPUT链: 一般用于处理本地进程的输出数据包;
FORWARD链:一般用于处理转发到其他机器/networknamespace的数据包;
PREROUTING链:可以在此处进行DNAT;
POSTROUTING链:可以在此处进行SNAT;
除了系统预定义的5条iptables链,用户还可以在表中定义自己的链
5张表如下所示:
filter表:用于控制到达某条链上的数据包是继续放行,直接丢弃(drop)或拒绝(reject);
nat表:用于修改数据包的源和目的地址;
mangle表:用于修改数据包的IP头信息;
raw表:iptables是有状态的,即iptables对数据包有链接追踪(connectiontracking)机制,而raw是用来去除这种追踪机制的;
security表:最不常用的表(通常,我们说iptables只有4张表,security表是新加入的特性),用于在数据包应用SELinux。
这5张表的优先级从高到低是:raw、mangle、nat、filter、security。需要注意的是,iptables不支持用户自定义表。
不是每个链上都能挂表,iptables表与链的对应关系如下图所示:
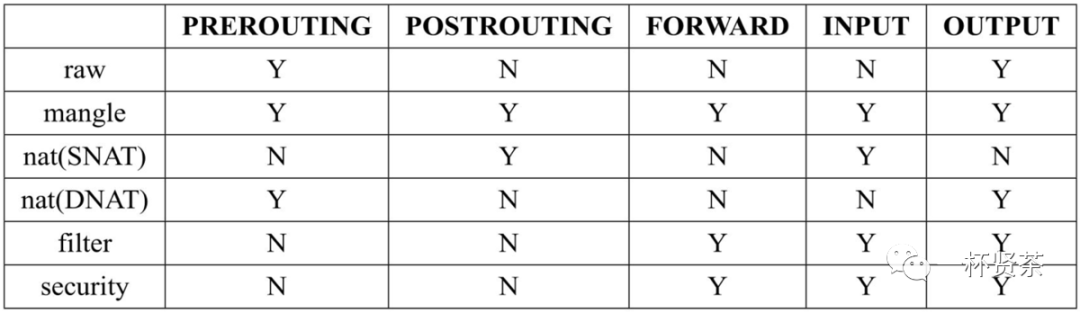
iptables的表是来分类管理iptables规则(rule)的 ,系统所有的iptables规则都被划分到不同的表集合中。
iptables的规则就是挂在netfilter钩子上的函数,用来修改数据包的内容或过滤数据包,iptables的表就是所有规则的5个逻辑集合。
一条iptables规则包含两部分信息:匹配条件和动作。匹配条件很好理解,即匹配数据包这条iptables规则“捕获”的条件,例如协议类型、源IP、目的IP、源端口、目的端口、连接状态等。每条iptables规则允许多个匹配条件任意组合,从而实现多条件的匹配,多条件之间是逻辑与(&&)关系。
数据包匹配后,常见的动作有下面几个:
DROP:直接将数据包丢弃,不再进行后续的处理。应用场景是不让某个数据意识到你的系统存在,可以用来模拟宕机。
REJECT:给客户端返回一个connectionrefused或destinationunreachable报文。应用场景是不让某个数据源访问你的系统,善意的告诉他:这里没有你要的服务内容
QUEUE:将数据包放入用户空间的队列,供用户空间的程序处理;
RETURN:跳出当前链,该链里后续的规则不再执行
ACCEPT:同意数据包通过,继续执行后续的规则;
JUMP:跳转到其他用户自定义的链继续执行
用户自定义链中的规则和系统预定义的5条链里的规则没有区别。由于自定义的链没有与netfilter里的钩子进行绑定,所以它不会自动触发,只能从其他链的规则中跳转过来,这也就是JUMP动作存在的意义
NAT
NAT的全称是Network Address Translation,即网络地址转换。TCP/IP的网络数据包不是由IP地址吗?IP地址不是由来源与目的地吗?iptables命令就能修改IP数据报到报文头数据,目标或来源IP地址和port都能修改。
假如有数据包需要通过Linux主机传送出去,步骤如下:
先经过NAT table的PREROUTING链接;
经由路由判断确定这个数据包是否要进入本机,若不进入,则下一步;
再经过Filter table的FORWARD链;
通过NAT table的POSTROUTING链,最后传送出去;
NAT服务器的重点在于上面的1、4步,也就是NAT table的两条重要的链:PREROUTING与POSTROUTING。
两条链不同的作用:
PREROUTING:修改的是目标IP(Destination NAT, DNAT)
POSTROUTING:修改的是来源IP(Source NAT, SNAT)
Linux网络虚拟设备
Linux虚拟网络的背后是由一个个的虚拟设备构成的。虚拟化技术没出现之前,计算机网络系统都只包含物理的网卡设备,通过网卡适配器,线缆介质,连接外部网络,构成庞大的Internet。
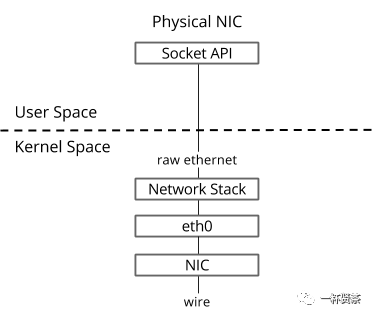
然而,随着虚拟化技术的出现,网络也随之被虚拟化,相较于单一的物理网络,虚拟网络变得非常复杂,在一个主机系统里面,需要实现诸如交换、路由、隧道、隔离、聚合等多种网络功能;
而实现这些功能的基本元素就是虚拟的网络设备,比如tap、tun和veth-pair
tap/tun
tap/tun提供了一台主机内用户空间的数据传输机制。它虚拟了一套网络接口,这套接口和物理的接口无任何差别,可以配置IP,可以路由流量,不同的是,它的流量只在主机内流通
tap/tun有些许的不同,tun只操作三层的IP包,而tap擦欧总二层的以太网帧

veth-pair
veth-pair是成对出现的一种虚拟网络设备,一端连接着协议栈,一端连接着彼此,数据从一端出,从另一端进。
它的这个特性常常用来连接不同的虚拟组件,构建大规模的虚拟网络拓扑,比如连接Linux Bridge、
OVS、LXC容器等
一个很常见的案例就是它被用于OpenStack Neutron,构建非常复杂的网络形态
常见的网络设备:eth0、tap、tun、veth-pair这些都构成了如今云网路必不可少的元素

