




从计算机视觉到新药发现,许多流行的人工智能(AI)应用都由向量数据库提供支持。索引是一种组织数据的过程,它极大地加速了大数据搜索,使我们能够高效地查询数百万、十亿甚至万亿规模的向量数据集。
本文是对上一篇博客“使用向量索引加速大数据上的相似性搜索”的补充,涵盖了索引在使向量相似性搜索高效和不同索引(包括FLAT、IVF_FLAT、IVF_SQ8和IVF_SQ8H)中所起的作用。本文还提供了四个指标的性能测试结果。我们建议先阅读这个博客。
本文概述了四种主要类型的指标,并继续介绍四种不同的指标:IVF_PQ、HNSW、HARRE和E2LSH。
近似最近邻搜索是索引中的一个基本概念。为了更好地理解这个概念及其相对于KNN(K近邻)的优势,请阅读玛丽·史蒂芬·利奥(Marie Stephen Leo)撰写的博客文章。
常见索引有哪些不同类型?
为高维向量相似性搜索设计了许多索引,每种索引都在性能、准确性和存储需求方面进行权衡。常见的索引类型有基于量化、基于图、基于哈希和基于树。此外,基于磁盘的人工神经网络是近似近邻搜索(ANN)最新进展的产物。后续文章将介绍这种索引类型。(请继续关注!)
基于量化的索引
基于量化的索引通过将大量点划分为所需数量的簇来工作,并确保点与其质心之间的距离之和最小。通过取聚类中所有点的算术平均值来计算质心。
基于图的索引
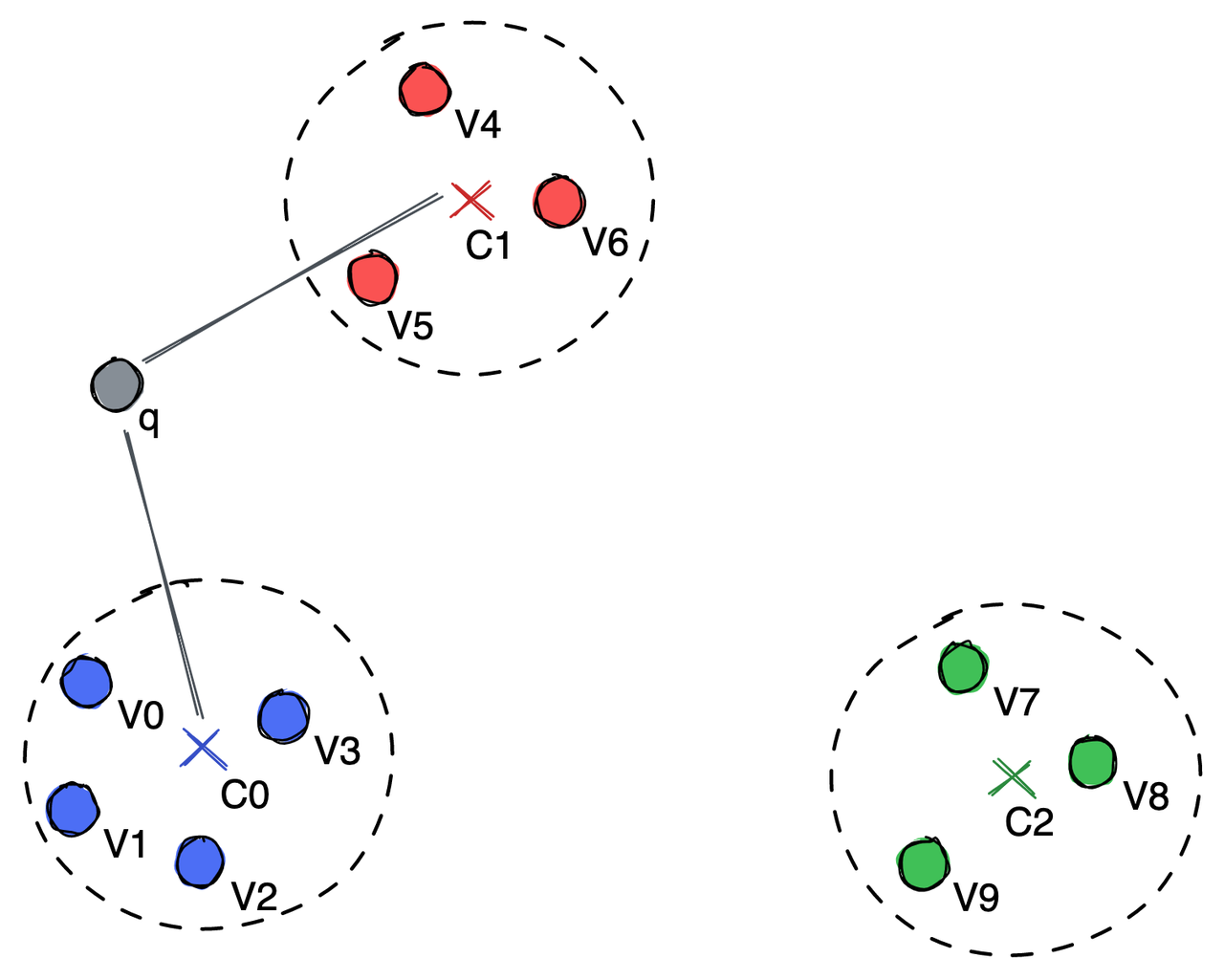
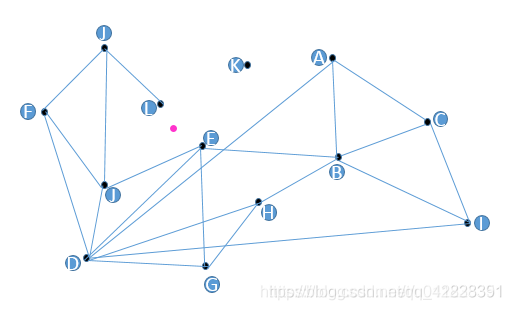
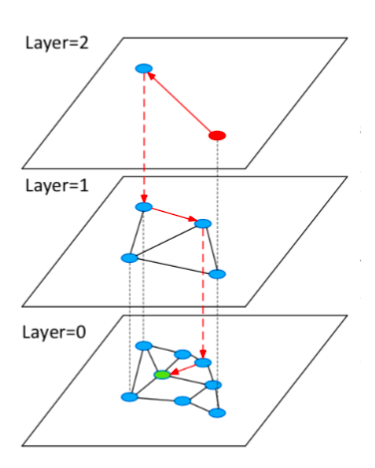
图本身包含最近邻信息。以下图为例;粉红点是我们的查询向量。我们需要找到它最近的顶点。入口点是随机选择的。有时,入口点可能是插入数据库的第一个向量。例如,我们随机选择A作为入口点。B、 C和D是A的邻域,其中D最接近粉红点。因此,我们继续从D开始,在它的邻居E、F和J中,离粉红点最近的是E。然而,与粉红点相比,E的所有邻居都更远。因此,我们可以说E是最接近粉红点的。
然而,上述方法存在一些问题:
-
首先,不查询像K这样的顶点。
-
顶点E和L彼此接近,但不相连。因此,在人工神经网络中,L不被视为E的邻居,这大大阻碍了查询效率。
-
要查询的相邻顶点数越多,存储消耗越大。然而,连接线不足导致查询效率降低。这些问题很容易解决,只要:
-
在构建图时,所有顶点都需要有一个相邻顶点。在这种情况下,可以查询顶点K。
-
必须连接所有相邻顶点。(有关连接策略的更详细说明,请阅读基于邻近图的近似近邻搜索。)
-
可以通过配置指定要查询的相邻顶点数。
随着问题的解决,查询效率仍然没有得到提高。因此,我们需要在这里引入“高速公路”机制。
高速公路机制
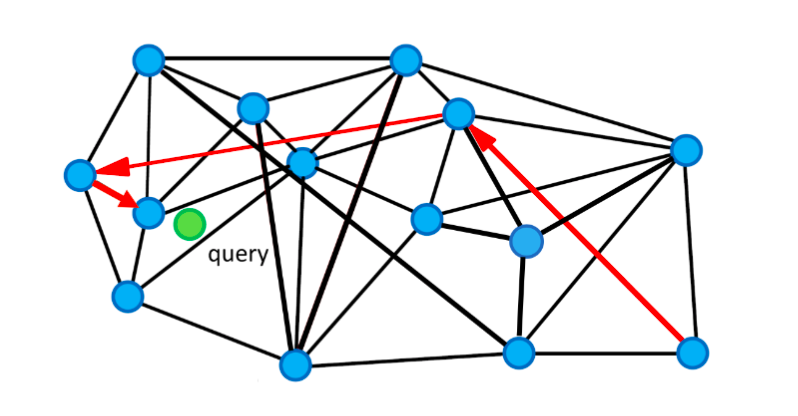
由于我们可能从远离目标查询向量的入口点开始查询,因此我们可能需要走很长的路,穿过许多顶点才能找到最近的邻居。通过引入快速机制,我们可以跳过一些相邻顶点以加快搜索速度。如下图所示,我们可以按照红色箭头(高速公路)查找绿色查询点的最近邻居。它只通过3个顶点。
基于哈希的索引
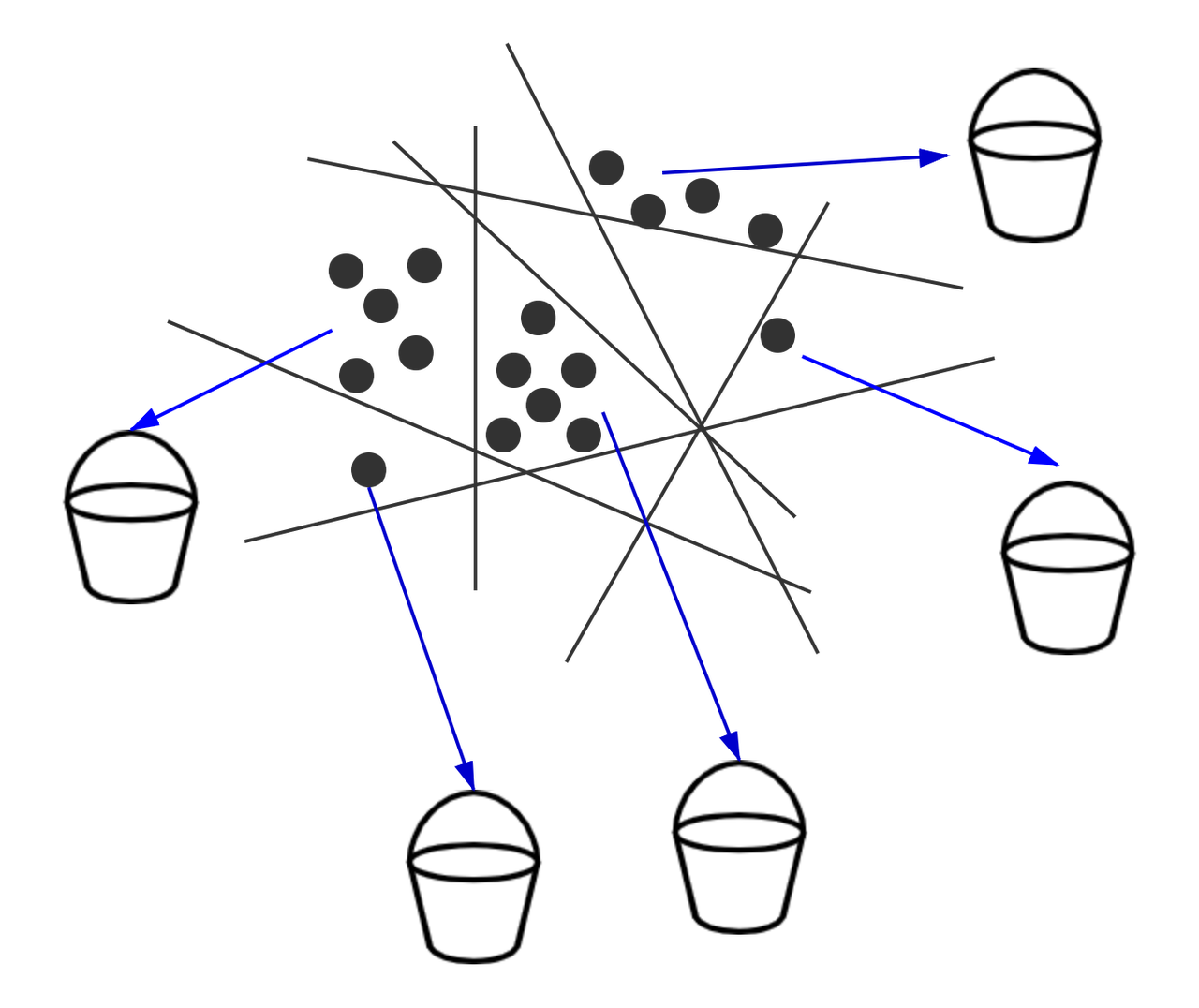
基于哈希的索引使用一系列哈希函数。多个哈希函数之间发生冲突的概率表示向量的相似性。因此,数据库中的每个向量都被放入多个桶中。在最近邻搜索过程中,搜索半径不断增加,以获得足够的桶。然后进一步计算查询向量和桶中向量之间的距离。
基于树的索引
大多数基于树的索引使用特定的规则从上到下划分整个高维空间。例如,KD树选择方差最大的维度,并根据该维度的中值将空间中的向量划分为两个子空间。同时,通过随机投影生成一个超平面,并使用该超平面将向量空间一分为二。
索引最适合哪些场景?
下表概述了几个索引及其分类。
前文“使用向量索引加速大数据上的相似性搜索”介绍了前四种索引及其性能测试结果这篇文章主要关注IVF_PQ、HNSW、HARRE和E2LSH。
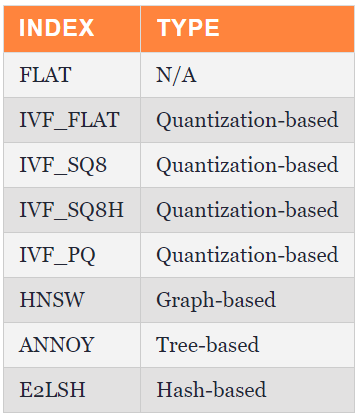
注:虽然在这篇文章中,我们将体外受精指数归类为基于量化的指数,但这在学术界仍有争议,因为一些研究人员认为体外受精指数不应被视为基于量化的。
IVF_PQ:最快的IVF指数类型,召回率显著降低
乘积量化将原始高维向量空间均匀分解为m个低维向量空间的笛卡尔乘积,然后对分解后的低维向量空间进行量化。IVF_PQ不是计算目标向量和数据库向量之间的距离,而是使用乘积量化器(向量与其对应的粗质心向量之间的差)对残差向量进行编码。因此,数据库中的向量由其质心和量化的残差向量表示。
在计算目标查询向量和选定存储桶中的向量之间的距离时,IVF\U PQ使用查找表快速解码剩余向量的距离。
IVF_PQ在量化向量乘积之前执行IVF索引聚类。其索引文件甚至比IVF_SQ8更小,但在搜索向量时也会导致准确性损失。
HNSW:一种高速、高召回指数
HNSW(分层可导航小世界图)是一种基于图的索引算法,该算法增量构建一个多层结构,该结构由存储元素嵌套子集的一组分层近似图(层)组成。上层以指数衰减的概率分布从下层随机选择。搜索从最上层开始,在该层中找到距离目标最近的节点,然后向下到下一层开始另一次搜索。经过多次迭代,它可以快速接近目标。
HNSW限制图的每一层上节点的最大次数以提高性能。此外,在建立索引时可以使用efConstruction指定搜索范围,在搜索目标时可以使用ef指定搜索范围。
HARRE:一种基于低维向量的树索引
HARRE(近似最近邻哦,是的)是一种索引,它使用超平面将高维空间划分为多个子空间,然后将它们存储在树结构中。
HARRET是n_树(n_树表示森林中的树数)不同的二叉树,树上的每个节点都是数据库的超平面子空间。在树的每个中间节点上选择一个随机超平面,将空间划分为两个子空间。叶是向量小于_K的超平面子空间。
如下图所示,Have将空间切割为几个子空间。首先,将空间切割成2个子空间。

然后将这2个子空间中的每一个子空间切成两半,生成4个较小的子空间。
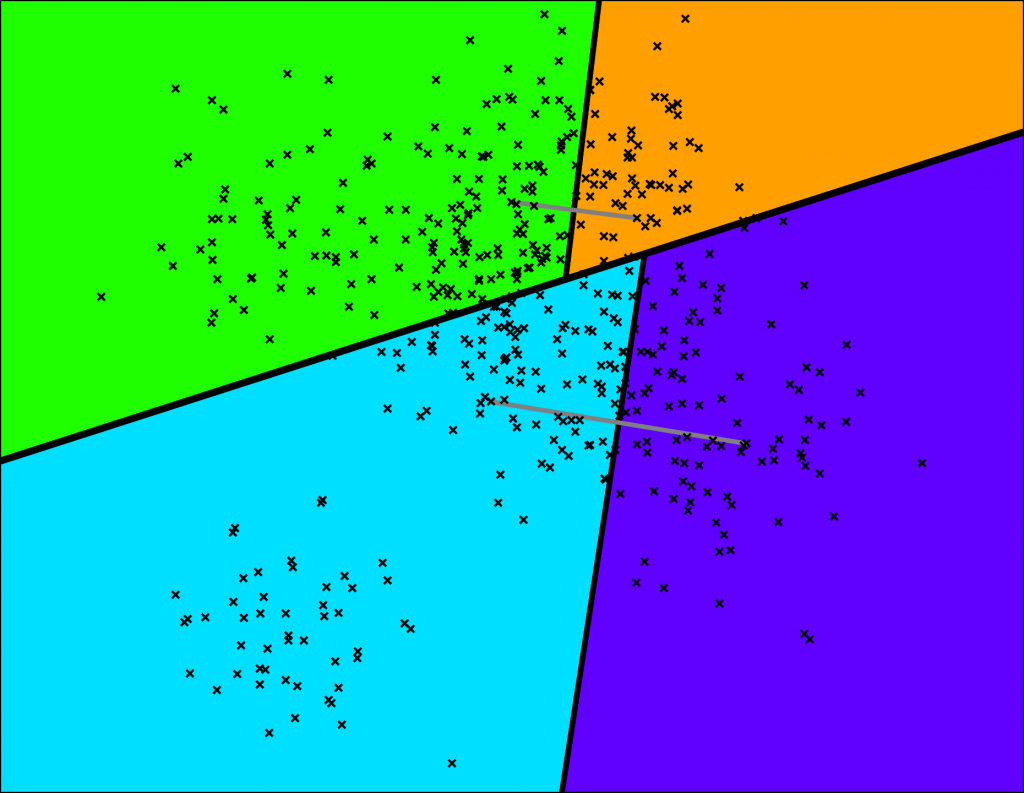
如果我们继续分割整个空间,我们最终会得到如下图所示的结果。
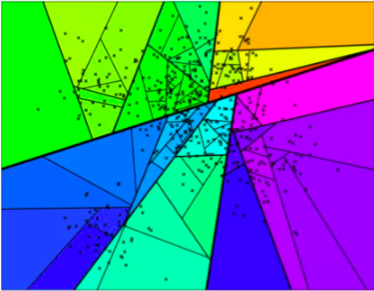
整个空间划分过程类似于一棵二叉树。

在搜索向量时,HARRE遵循树结构查找更接近目标向量的子空间,然后比较这些子空间中的所有向量以获得最终结果。HARRE最多检查搜索k个节点,默认情况下,如果未提供,其值为n\u trees*n。HARRE使用优先级队列同时搜索所有树,以确保遍历足够的节点。因此,当目标向量接近某个子空间的边缘时,需要显著增加搜索子空间的数量以获得较高的召回率。
HARRE支持多种距离度量,包括欧几里得距离、曼哈顿距离、余弦距离和汉明距离。此外,可以在多个进程之间共享HARRE索引。然而,它的缺点是只适用于低维和小数据集。此外,HARRE仅支持整数作为数据ID,这意味着如果向量ID不是整数,则需要额外维护。最后,GPU处理也不受HARRE支持。
E2LSH:用于超大数据量的高效索引
E2LSH基于p-稳定分布构造LSH函数。E2LSH使用一组LSH函数来增加相似向量的冲突概率,并减少不同向量的冲突概率。LSH函数首先沿随机线投影对象,然后使投影发生意外偏移,最后使用楼层函数定位偏移投影所在的宽度w的间隔,从而将对象划分为一个桶。
在搜索和查询过程中,E2LSH首先根据哈希函数组找到向量对象所在的bucket,然后使用哈希函数组h2定位该bucket中的位置。E2LSH的二级哈希结构不仅可以减少由于将所有向量的哈希投影值存储在数据库中而导致的高存储开销,而且可以快速定位查询向量所在的哈希桶。
E2LSH特别适用于数据集量很大的场景,因为该算法可以显著提高搜索速度。
致谢
非常感谢易、程千亚和徐伟志,他们对本文的评论给予了帮助,并提供了宝贵的建议。
原文标题: Accelerating Similarity Search on Really Big Data with Vector Indexing (Part II)
原文作者: Angela Ni
原文链接: https://dzone.com/articles/accelerating-similarity-search-on-really-big-data
