




在以前的文章中,我们讨论了查询执行阶段和统计信息。上次,我开始研究数据访问方法,即顺序扫描。今天我们将介绍索引扫描。本文需要对索引方法接口有一个基本的了解。如果像“操作符类”和“访问方法属性”这样的词不起作用,请查看我不久前关于索引的文章,以获得更新。
普通索引扫描
索引返回行版本ID(元组ID,简称TID),可以通过以下两种方式之一进行处理。第一种是索引扫描。大多数(但不是所有)索引方法都具有索引扫描属性,并支持这种方法。
该操作在带有索引扫描节点的计划中表示:
解释从预订中选择*
其中book_ref=‘9AC0C6’,total_amount=48500.00;
QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Index Scan using bookings_pkey on bookings
(cost=0.43..8.45 rows=1 width=21)
Index Cond: (book_ref = '9AC0C6'::bpchar)
Filter: (total_amount = 48500.00)
(4 rows)
这里,访问方法每次返回一个TID。索引机制接收ID,读取相关表页,提取元组,检查其可见性,如果一切正常,则返回所需字段。整个过程会重复,直到访问方法用完与查询匹配的ID为止。
计划中的索引条件行仅显示可以仅使用索引过滤的条件。只能对照表检查的其他条件列在过滤线下。
换句话说,索引和表扫描操作并没有被分为两个不同的节点,而是作为索引扫描节点的一部分执行。然而,有一个称为Tid扫描的特殊节点。它使用已知ID从表中读取元组:
解释从预订中选择*,其中ctid=’(0,1)’::tid;
QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Tid Scan on bookings (cost=0.00..4.01 rows=1 width=21)
TID Cond: (ctid = '(0,1)'::tid)
(2 rows)
成本估算
在计算索引扫描成本时,系统估计索引访问成本和表页获取成本,然后将其相加。
索引访问成本完全取决于选择的访问方法。如果使用B-树,大部分成本来自索引页的获取和处理。获取的页面和行数可以从数据总量和查询条件的选择性中推断出来。索引页访问模式本质上是随机的(因为作为逻辑邻居的页面通常也不是磁盘上的邻居),因此访问单个页面的成本估计为random\u page\u成本。这里还包括从树根下降到叶页面的成本和额外的表达式计算成本。
成本表部分的CPU组件包括每行的处理时间(CPU\u tuple\u成本)乘以行数。
成本的I/O部分取决于索引访问选择性以及磁盘上元组的顺序与访问方法返回元组ID的顺序之间的相关性。
高度相关性良好
在理想情况下,当磁盘上的元组顺序与索引中ID的逻辑顺序完全匹配时,索引扫描将按顺序从一页移动到另一页,每一页只读取一次。
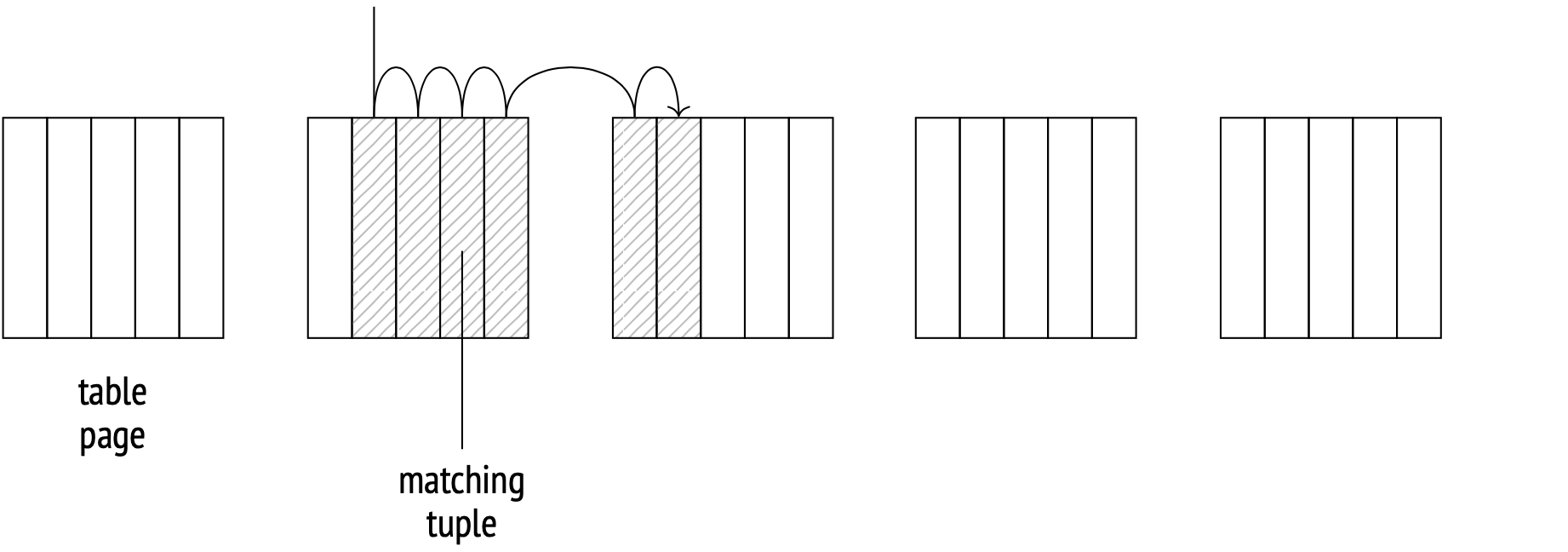
该相关性数据是收集的统计数据:
SELECT attname, correlation
FROM pg_stats WHERE tablename = 'bookings'
ORDER BY abs(correlation) DESC;
attname | correlation
−−−−−−−−−−−−−−+−−−−−−−−−−−−−−
book_ref | 1
total_amount | 0.0026738467
book_date | 8.02188e−05
(3 rows)
接近1的绝对book_ref值表示高度相关性;接近零的值表示分布更为混乱。
下面是对大量行进行索引扫描的示例:
解释从book_ref<“100000”的预订中选择*;
QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Index Scan using bookings_pkey on bookings
(cost=0.43..4638.91 rows=132999 width=21)
Index Cond: (book_ref < '100000'::bpchar)
(3 rows)
总成本约为4639。
选择性估计为:
SELECT round(132999::numeric/reltuples::numeric, 4)
FROM pg_class WHERE relname = 'bookings';
round
−−−−−−−−
0.0630
(1 row)
这大约是1/16,这是可以预期的,考虑到book_ref值的范围从000000到FFFFFF。
对于B-树,成本的索引部分只是所有所需页面的页面获取成本。与B树支持的任何过滤器匹配的索引记录总是排序并存储在逻辑连接的叶子中,因此要读取的索引页数估计为索引大小乘以选择性。然而,页面并没有按顺序存储在磁盘上,因此扫描模式是随机的。
成本估计包括处理每个索引记录的成本(在cpu_index_tuple_cost下)和每行的过滤器成本(在每个操作员的cpu_operator_cost下,在本例中我们只有一个)。
表I/O成本是所有所需页面的顺序读取成本。在完全相关时,磁盘上的元组是有序的,因此获取的页数将等于表大小乘以选择性。
然后将处理每个扫描元组的成本(cpu_tuple_cost)添加到顶部。
WITH costs(idx_cost, tbl_cost) AS (
SELECT
( SELECT round(
current_setting('random_page_cost')::real * pages +
current_setting('cpu_index_tuple_cost')::real * tuples +
current_setting('cpu_operator_cost')::real * tuples
)
FROM (
SELECT relpages * 0.0630 AS pages, reltuples * 0.0630 AS tuples
FROM pg_class WHERE relname = 'bookings_pkey'
) c
),
( SELECT round(
current_setting('seq_page_cost')::real * pages +
current_setting('cpu_tuple_cost')::real * tuples
)
FROM (
SELECT relpages * 0.0630 AS pages, reltuples * 0.0630 AS tuples
FROM pg_class WHERE relname = 'bookings'
) c
)
)
SELECT idx_cost, tbl_cost, idx_cost + tbl_cost AS total FROM costs;
idx_cost | tbl_cost | total
−−−−−−−−−−+−−−−−−−−−−+−−−−−−−
2457 | 2177 | 4634
(1 row)
该公式说明了成本计算背后的逻辑,结果与规划师的估计非常接近。如果您愿意解释几个小细节,就可能得到准确的结果,但这超出了本文的范围。
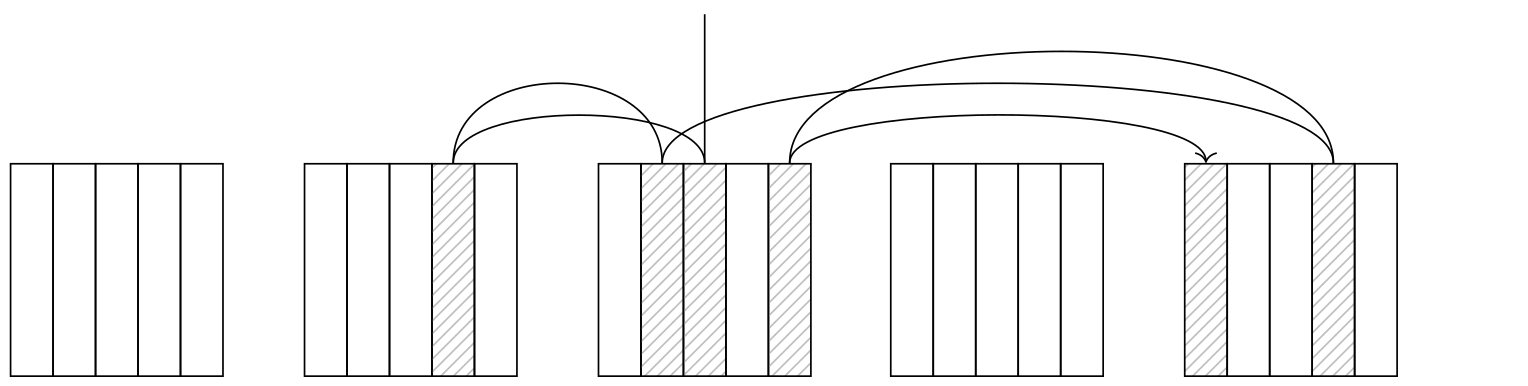
低相关性不好
当相关性较低时,整个画面会发生变化。让我们为book_date列创建一个索引,该索引与索引的相关性接近零,并运行一个查询,该查询选择的行数与上一个示例中的行数相似。索引访问非常昂贵(在好的情况下是56957对4639),因此规划人员只有在被告知明确这样做时才会选择它:
CREATE INDEX ON bookings(book_date);
SET enable_seqscan = off;
SET enable_bitmapscan = off;
EXPLAIN SELECT * FROM bookings
WHERE book_date < '2016-08-23 12:00:00+03';
QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Index Scan using bookings_book_date_idx on bookings
(cost=0.43..56957.48 rows=132403 width=21)
Index Cond: (book_date < '2016−08−23 12:00:00+03'::timestamp w...
(3 rows)
相关性较低意味着访问方法返回元组ID的顺序与元组在磁盘上的实际位置关系不大,因此下一个元组将位于不同的页面中。这使得索引扫描节点从一个页面跳到另一个页面,在最坏的情况下,页面抓取的数量将等于元组的数量。
然而,这并不意味着简单地用random_page_cost替换seq_page_cost,用reltuple替换relpages,就能得到正确的成本。事实上,这将给我们一个535787的估计,这远远高于规划师的估计。
这里的关键是缓存。频繁访问的页面存储在缓冲缓存中(也存储在操作系统缓存中),因此缓存大小越大,在其中找到请求页面并避免访问磁盘的机会就越高。具体规划的缓存大小由effective_cache_size参数(默认为4GB)定义。较低的参数值会增加要提取的预期页数。我不会在这里给出确切的公式(您可以从index_pages_fetched函数下的backend/optimizer/path/costsize.c文件中找到)。我将在这里放一个图表,说明获取的页数与表大小的关系(选择性为1/2,每页的行数为10):
然而,这并不意味着简单地用random_page_cost替换seq_page_cost,用reltuple替换relpages,就能得到正确的成本。事实上,这将给我们一个535787的估计,这远远高于规划师的估计。
这里的关键是缓存。频繁访问的页面存储在缓冲缓存中(也存储在操作系统缓存中),因此缓存大小越大,在其中找到请求页面并避免访问磁盘的机会就越高。具体规划的缓存大小由effective_cache_size参数(默认为4GB)定义。较低的参数值会增加要提取的预期页数。我不会在这里给出确切的公式(您可以从index_pages_fetched函数下的backend/optimizer/path/costsize.c文件中找到)。我将在这里放一个图表,说明获取的页数与表大小的关系(选择性为1/2,每页的行数为10):
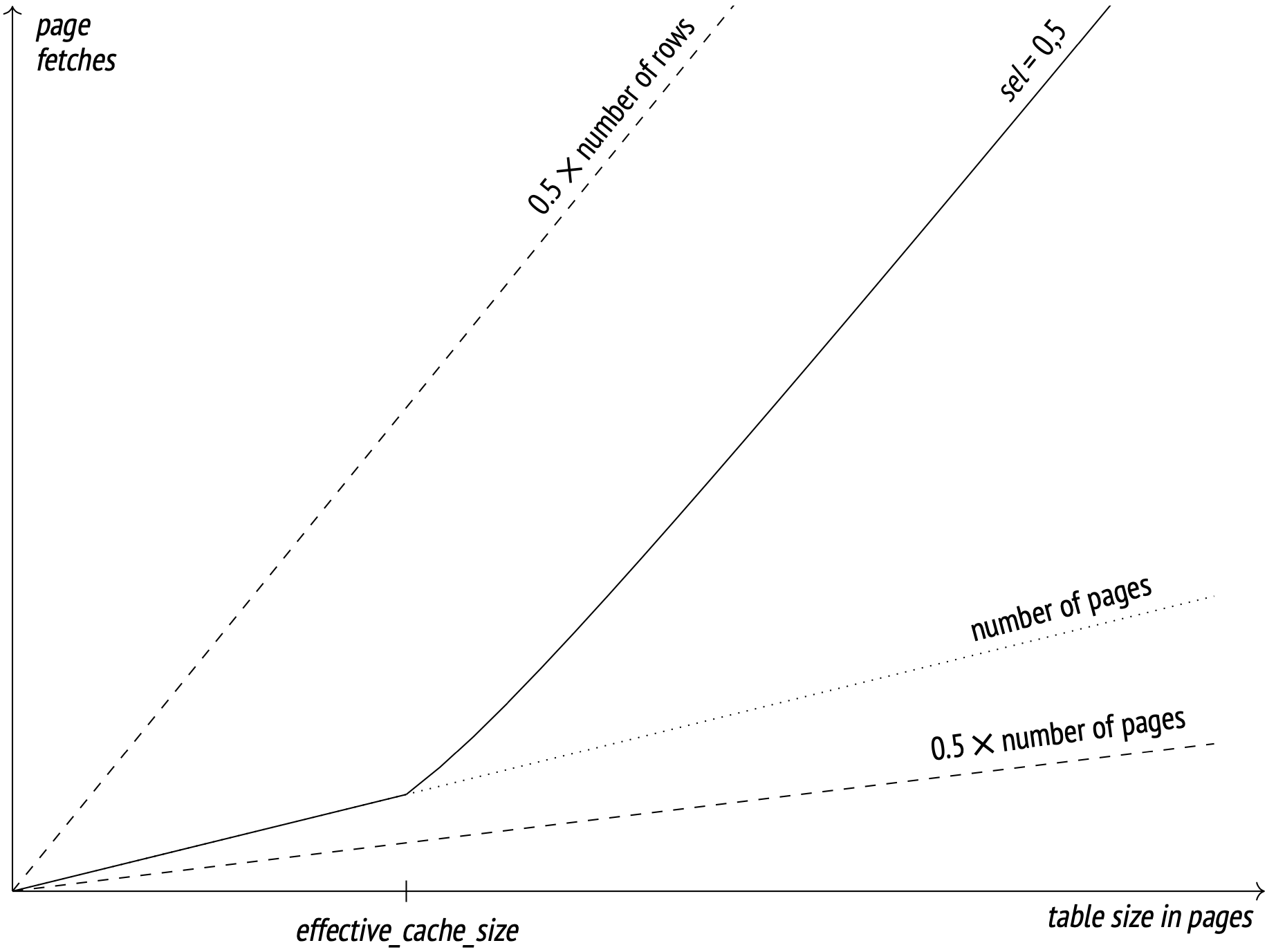
虚线表示取数等于页数的一半(完全相关时的最佳结果)和行数的一半(零相关且无缓存时的最差结果)。
从理论上讲,effective_cache_size参数应该与总可用缓存大小相匹配(包括PostgreSQL缓冲区缓存和系统缓存),但该参数仅用于成本估算,实际上并不保留任何缓存内存,因此无论实际缓存值如何,您都可以根据需要对其进行更改。
如果将参数调低到最小值,则成本估计将非常接近前面提到的无缓存最坏情况:
SET effective_cache_size = '8kB';
EXPLAIN SELECT * FROM bookings
WHERE book_date < '2016-08-23 12:00:00+03';
QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Index Scan using bookings_book_date_idx on bookings
(cost=0.43..532745.48 rows=132403 width=21)
Index Cond: (book_date < '2016−08−23 12:00:00+03'::timestamp w...
(3 rows)
RESET effective_cache_size;
RESET enable_seqscan;
RESET enable_bitmapscan;
在计算表输入/输出成本时,规划器同时考虑最坏和最佳情况成本,然后根据实际相关性选择中间值。
当您只扫描表中的一些元组时,索引扫描是有效的。表中的元组位置越与访问方法返回ID的顺序相关,则使用此访问方法可以有效检索的元组就越多。相反,低阶相关的访问方法在元组数非常少的情况下变得效率低下。
仅索引扫描
当索引包含处理查询所需的所有数据时,我们将其称为查询的覆盖索引。通过使用覆盖索引,访问方法可以直接从索引中检索数据,而无需单表扫描。这称为仅索引扫描,可以由任何具有可返回属性的访问方法使用。
该操作在计划中用一个仅索引扫描节点表示:
EXPLAIN SELECT book_ref FROM bookings WHERE book_ref < '100000';
QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Index Only Scan using bookings_pkey on bookings
(cost=0.43..3791.91 rows=132999 width=7)
Index Cond: (book_ref < '100000'::bpchar)
(3 rows)
该名称表明仅索引扫描节点从不查询表,但在某些情况下确实如此。PostgreSQL索引不存储可见性信息,因此访问方法返回与查询匹配的每一行版本的数据,而不管它们对当前事务的可见性如何。然后通过索引机制验证元组可见性。
但是,如果该方法必须扫描表以获取可见性,那么它与普通索引扫描有何不同?诀窍是一个称为可见性地图的功能。每个堆关系都有一个可见性映射,用于跟踪哪些页面只包含已知对所有活动事务可见的元组。每当索引方法返回指向可见性映射中标记的页面的行ID时,您可以确定那里的所有数据对您的事务都是可见的。
仅索引扫描成本由可见性映射中标记的表页数决定。这是一个收集的统计数据:
SELECT relpages, relallvisible
FROM pg_class WHERE relname = 'bookings';
relpages | relallvisible
−−−−−−−−−−+−−−−−−−−−−−−−−−
13447 | 13446
(1 row)
索引扫描和仅索引扫描成本估计之间的唯一区别在于,后者将前者的输入/输出成本乘以可见性映射中不存在的页面的分数。(处理成本保持不变。)
在本例中,每个页面上的每一行版本对每个事务都可见,因此输入/输出成本基本上乘以零:
WITH costs(idx_cost, tbl_cost) AS (
SELECT
( SELECT round(
current_setting('random_page_cost')::real * pages +
current_setting('cpu_index_tuple_cost')::real * tuples +
current_setting('cpu_operator_cost')::real * tuples
)
FROM (
SELECT relpages * 0.0630 AS pages, reltuples * 0.0630 AS tuples
FROM pg_class WHERE relname = 'bookings_pkey'
) c
) AS idx_cost,
( SELECT round(
(1 - frac_visible) * -- the fraction of the pages not in the visibility map
current_setting('seq_page_cost')::real * pages +
current_setting('cpu_tuple_cost')::real * tuples
)
FROM (
SELECT relpages * 0.0630 AS pages,
reltuples * 0.0630 AS tuples,
relallvisible::real/relpages::real AS frac_visible
FROM pg_class WHERE relname = 'bookings'
) c
) AS tbl_cost
)
SELECT idx_cost, tbl_cost, idx_cost + tbl_cost AS total
FROM costs;
idx_cost | tbl_cost | total
−−−−−−−−−−+−−−−−−−−−−+−−−−−−−
2457 | 1330 | 3787
(1 row)
堆中仍然存在的任何尚未清空的更改都会增加总计划成本(并使计划对优化器不那么理想)。您可以使用EXPLAIN ANALYSE命令检查所需堆取数的实际数量:
CREATE TEMP TABLE bookings_tmp WITH (autovacuum_enabled = off)
AS SELECT * FROM bookings ORDER BY book_ref;
ALTER TABLE bookings_tmp ADD PRIMARY KEY(book_ref);
ANALYZE bookings_tmp;
EXPLAIN (analyze, timing off, summary off)
SELECT book_ref FROM bookings_tmp WHERE book_ref < '100000';
QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Index Only Scan using bookings_tmp_pkey on bookings_tmp
(cost=0.43..4712.86 rows=135110 width=7) (actual rows=132109 l...
Index Cond: (book_ref < '100000'::bpchar)
Heap Fetches: 132109
(4 rows)
由于已禁用抽真空,规划器必须检查每一行的可见性(堆抓取)。然而,在抽真空后,不需要这样做:
VACUUM bookings_tmp;
EXPLAIN (analyze, timing off, summary off)
SELECT book_ref FROM bookings_tmp WHERE book_ref < '100000';
QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Index Only Scan using bookings_tmp_pkey on bookings_tmp
(cost=0.43..3848.86 rows=135110 width=7) (actual rows=132109 l...
Index Cond: (book_ref < '100000'::bpchar)
Heap Fetches: 0
(4 rows)
带有INCLUDE子句的索引
您可能希望索引包含查询经常使用的特定列(或多个列),但您的索引可能不可扩展:
-
对于唯一索引,添加额外列可能会使原始列不再唯一。
-
新的列数据类型可能缺少索引访问方法的适当运算符类。
如果是这种情况,您可以(在PostgreSQL 11和更高版本中)使用不属于搜索键的列来补充索引。虽然缺少搜索功能,但这些有效负载列可以使索引覆盖需要这些列的查询。
人们通常将这些特定类型的指数称为覆盖,这在技术上是不正确的。只要一个查询的列集合覆盖了执行该查询所需的列集合,那么任何索引都可以覆盖该查询。索引是否使用添加了INCLUDE子句的字段无关紧要。此外,同一索引可以覆盖一个查询,但不能覆盖另一个查询。
这是一个用另一个带有额外列的主键索引替换自动生成的主键索引的示例:
CREATE UNIQUE INDEX ON bookings(book_ref) INCLUDE (book_date);
BEGIN;
ALTER TABLE bookings DROP CONSTRAINT bookings_pkey CASCADE;
NOTICE: drop cascades to constraint tickets_book_ref_fkey on table
tickets
ALTER TABLE
ALTER TABLE bookings ADD CONSTRAINT bookings_pkey PRIMARY KEY
USING INDEX bookings_book_ref_book_date_idx; -- new index
NOTICE: ALTER TABLE / ADD CONSTRAINT USING INDEX will rename index
"bookings_book_ref_book_date_idx" to "bookings_pkey"
ALTER TABLE
ALTER TABLE tickets
ADD FOREIGN KEY (book_ref) REFERENCES bookings(book_ref);
COMMIT;
EXPLAIN SELECT book_ref, book_date
FROM bookings WHERE book_ref < '100000';
QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Index Only Scan using bookings_pkey on bookings (cost=0.43..437...
Index Cond: (book_ref < '100000'::bpchar)
(2 rows)
位图扫描
虽然索引扫描在高相关性下有效,但当相关性下降到扫描模式比顺序模式更随机且页面抓取数增加时,索引扫描就会不足。这里的一个解决方案是预先收集所有元组ID,按页码排序,然后使用它们扫描表。这就是位图扫描(第二种基本索引扫描方法)的工作原理。它可用于任何具有位图扫描属性的访问方法。
考虑以下计划:
位图扫描
虽然索引扫描在高相关性下有效,但当相关性下降到扫描模式比顺序模式更随机且页面抓取数增加时,索引扫描就会不足。这里的一个解决方案是预先收集所有元组ID,按页码排序,然后使用它们扫描表。这就是位图扫描(第二种基本索引扫描方法)的工作原理。它可用于任何具有位图扫描属性的访问方法。
考虑以下计划:
REATE INDEX ON bookings(total_amount);
EXPLAIN
SELECT * FROM bookings WHERE total_amount = 48500.00;
QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Bitmap Heap Scan on bookings (cost=54.63..7040.42 rows=2865 wid...
Recheck Cond: (total_amount = 48500.00)
−> Bitmap Index Scan on bookings_total_amount_idx
(cost=0.00..53.92 rows=2865 width=0)
Index Cond: (total_amount = 48500.00)
(5 rows)
位图扫描操作由两个节点表示:位图索引扫描和位图堆扫描。位图索引扫描调用访问方法,该方法生成所有元组ID的位图。
位图由多个块组成,每个块对应于表中的一个页面。由于每个元组的标题大小很大(每个标准页面最多256个元组),因此页面上的元组数量有限。由于每个页面对应一个位图块,因此创建的块足够大,可以容纳最大数量的元组(每个标准页面32个字节)。
位图堆扫描节点逐块扫描位图,转到相应页面,并获取位图中标记的所有元组。因此,页面是按升序提取的,每个页面只提取一次。
实际的扫描顺序不是连续的,因为页面可能不在磁盘上一个接一个地定位。操作系统的预取在这里是无用的,因此位图堆扫描通过异步读取页面的有效io并发性来使用其自己的预取功能(并且它是唯一这样做的节点)。此功能在很大程度上取决于您的系统是否支持posix_fadvise功能。如果需要,您可以根据硬件功能设置参数(在表空间级别)。
地图精度
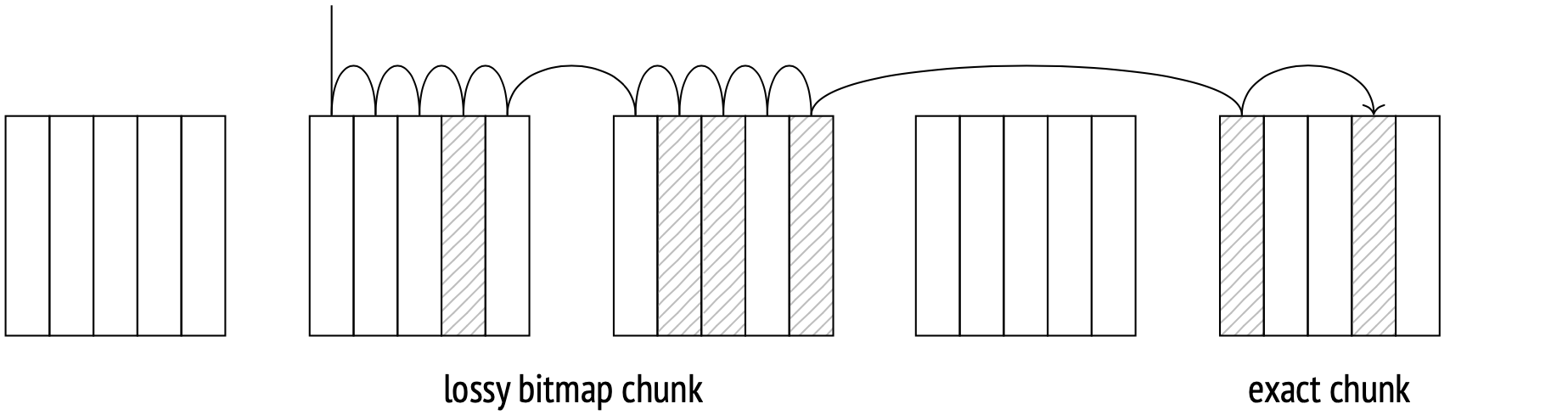
当查询从大量页面请求元组时,这些页面的位图可能会占用大量本地内存。允许的位图大小受work\u mem参数的限制。如果位图达到允许的最大大小,它的一些块开始扩大:每个扩大的块的位与一个页面而不是元组匹配,然后块覆盖一系列页面,而不仅仅是一个页面。这使位图大小易于管理,同时牺牲了一些准确性。您可以使用EXPLAIN ANALYSE命令检查位图的准确性:
EXPLAIN (analyze, costs off, timing off)
SELECT * FROM bookings WHERE total_amount > 150000.00;
QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Bitmap Heap Scan on bookings (actual rows=242691 loops=1)
Recheck Cond: (total_amount > 150000.00)
Heap Blocks: exact=13447
−> Bitmap Index Scan on bookings_total_amount_idx (actual rows...
Index Cond: (total_amount > 150000.00)
(5 rows)
在这种情况下,位图足够小,可以容纳所有元组数据,而无需放大。这就是我们所说的精确位图。如果我们降低work_mem值,一些位图块将被放大。这将使位图丢失:
SET work_mem = '512kB';
EXPLAIN (analyze, costs off, timing off)
SELECT * FROM bookings WHERE total_amount > 150000.00;
QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Bitmap Heap Scan on bookings (actual rows=242691 loops=1)
Recheck Cond: (total_amount > 150000.00)
Rows Removed by Index Recheck: 1145721
Heap Blocks: exact=5178 lossy=8269
−> Bitmap Index Scan on bookings_total_amount_idx (actual rows...
Index Cond: (total_amount > 150000.00)
(6 rows)
当使用放大的位图块获取表页时,规划器必须根据查询条件重新检查其元组。无论检查是否实际进行,该步骤始终由计划中的重新检查条件行表示。过滤出的行数显示在“索引重新检查”删除的行下。
在大型数据集上,即使每个块都被放大的位图也可能超过work\u mem的大小。如果是这种情况,只需忽略work\u mem限制,就不会进行额外的升标或缓冲。
位图操作
查询的过滤条件中可能包含多个字段。这些字段可能各有一个单独的索引。位图扫描允许我们一次利用多个索引。每个索引都得到一个为其构建的行版本位图,然后将位图进行and和OR运算。例子:
EXPLAIN (costs off)
SELECT * FROM bookings
WHERE book_date < '2016-08-28' AND total_amount > 250000;
QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Bitmap Heap Scan on bookings
Recheck Cond: ((total_amount > '250000'::numeric) AND (book_da...
−> BitmapAnd
−> Bitmap Index Scan on bookings_total_amount_idx
Index Cond: (total_amount > '250000'::numeric)
−> Bitmap Index Scan on bookings_book_date_idx
Index Cond: (book_date < '2016−08−28 00:00:00+03'::tim...
(7 rows)
在本例中,位图和节点将两个位图放在一起。
当精确位图同时进行and和OR运算时,它们保持精确(除非生成的位图超过work\u mem限制)。原始位图中任何放大的块在生成的位图中保持放大。
成本估算
考虑以下位图扫描示例:
EXPLAIN
SELECT * FROM bookings WHERE total_amount = 28000.00;
QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Bitmap Heap Scan on bookings (cost=599.48..14444.96 rows=31878 ...
Recheck Cond: (total_amount = 28000.00)
−> Bitmap Index Scan on bookings_total_amount_idx
(cost=0.00..591.51 rows=31878 width=0)
Index Cond: (total_amount = 28000.00)
(5 rows)
规划人员估计此处的选择性约为:
SELECT round(31878::numeric/reltuples::numeric, 4)
FROM pg_class WHERE relname = 'bookings';
round
−−−−−−−−
0.0151
(1 row)
总位图索引扫描成本的计算与普通索引扫描成本相同,但表扫描除外:
SELECT round(
current_setting('random_page_cost')::real * pages +
current_setting('cpu_index_tuple_cost')::real * tuples +
current_setting('cpu_operator_cost')::real * tuples
)
FROM (
SELECT relpages * 0.0151 AS pages, reltuples * 0.0151 AS tuples
FROM pg_class WHERE relname = 'bookings_total_amount_idx'
) c;
round
−−−−−−−
589
(1 row)
当位图同时进行and和OR运算时,它们的索引扫描成本加上(微小的)逻辑操作成本。
位图堆扫描输入/输出成本计算与完全相关的索引扫描成本计算有很大不同。位图扫描以升序获取表页,无需重复扫描,但匹配的元组不再整齐地彼此相邻,因此没有快速简单的顺序扫描。因此,可能要获取的页面数会增加。
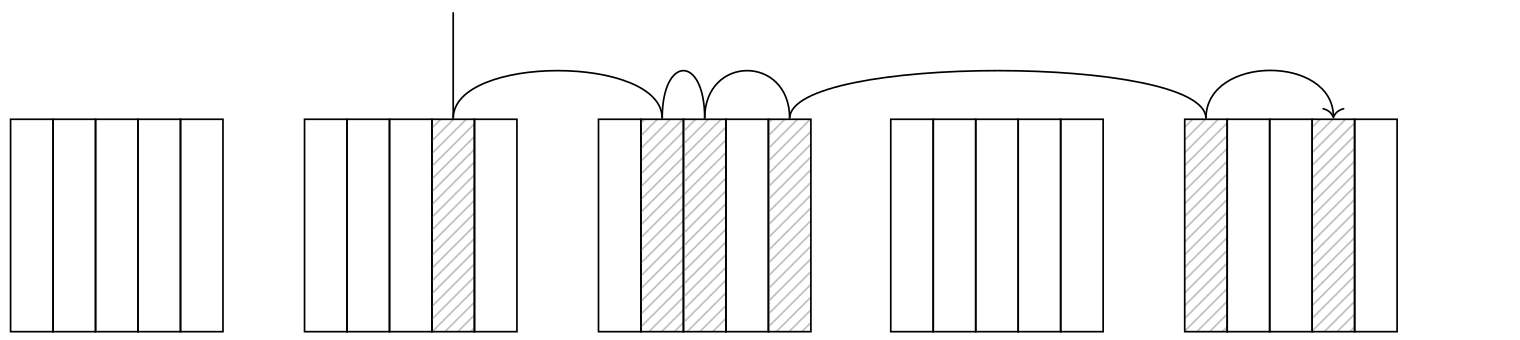
这由以下公式说明:

单个页面的获取成本估计在seq_page_cost和random_page_cost之间,具体取决于要获取的页面总数的分数。
WITH t AS (
SELECT relpages,
least(
(2 * relpages * reltuples * 0.0151) /
(2 * relpages + reltuples * 0.0151), relpages
) AS pages_fetched,
round(reltuples * 0.0151) AS tuples_fetched,
current_setting('random_page_cost')::real AS rnd_cost,
current_setting('seq_page_cost')::real AS seq_cost
FROM pg_class WHERE relname = 'bookings'
)
SELECT pages_fetched,
rnd_cost - (rnd_cost - seq_cost) *
sqrt(pages_fetched / relpages) AS cost_per_page,
tuples_fetched
FROM t;
pages_fetched | cost_per_page | tuples_fetched
−−−−−−−−−−−−−−−+−−−−−−−−−−−−−−−+−−−−−−−−−−−−−−−−
13447 | 1 | 31878
(1 row)
通常,每个扫描的元组都有一个处理成本,要添加到总输入/输出成本中。对于精确位图,获取的元组数等于表行数乘以选择性。当位图有损时,必须重新检查有损页面上的所有元组:
这就是为什么(在PostgreSQL 11及更高版本中)估计会考虑有损页面的可能部分(根据总行数和work_mem限制计算)。
估计还包括总查询条件重新检查成本(即使对于精确的位图)。位图堆扫描启动成本的计算与位图索引扫描总成本略有不同:需要考虑位图操作成本。在本例中,位图是精确的,估计值计算如下:
WITH t AS (
SELECT 1 AS cost_per_page,
13447 AS pages_fetched,
31878 AS tuples_fetched
),
costs(startup_cost, run_cost) AS (
SELECT
( SELECT round(
589 /* child node cost */ +
0.1 * current_setting('cpu_operator_cost')::real *
reltuples * 0.0151
)
FROM pg_class WHERE relname = 'bookings_total_amount_idx'
),
( SELECT round(
cost_per_page * pages_fetched +
current_setting('cpu_tuple_cost')::real * tuples_fetched +
current_setting('cpu_operator_cost')::real * tuples_fetched
)
FROM t
)
)
SELECT startup_cost, run_cost, startup_cost + run_cost AS total_cost
FROM costs;
startup_cost | run_cost | total_cost
−−−−−−−−−−−−−−+−−−−−−−−−−+−−−−−−−−−−−−
597 | 13845 | 14442
(1 row)
并行索引扫描
所有索引扫描(普通、仅索引和位图)都可以并行运行。
并行扫描成本的计算方法与顺序扫描成本的计算方法相同,但(与并行顺序扫描的情况一样)并行进程之间的处理资源分配降低了总成本。输入/输出操作在进程之间同步,并按顺序执行,因此此处没有更改。让我演示几个并行计划的示例,而不涉及成本估算。
并行索引扫描:
EXPLAIN SELECT sum(total_amount)
FROM bookings WHERE book_ref < '400000';
QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Finalize Aggregate (cost=19192.81..19192.82 rows=1 width=32)
−> Gather (cost=19192.59..19192.80 rows=2 width=32)
Workers Planned: 2
−> Partial Aggregate (cost=18192.59..18192.60 rows=1 widt...
−> Parallel Index Scan using bookings_pkey on bookings
(cost=0.43..17642.82 rows=219907 width=6)
Index Cond: (book_ref < '400000'::bpchar)
(7 rows)
仅并行索引扫描:
EXPLAIN SELECT sum(total_amount)
FROM bookings WHERE total_amount < 50000.00;
QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Finalize Aggregate (cost=23370.60..23370.61 rows=1 width=32)
−> Gather (cost=23370.38..23370.59 rows=2 width=32)
Workers Planned: 2
−> Partial Aggregate (cost=22370.38..22370.39 rows=1 widt...
−> Parallel Index Only Scan using bookings_total_amoun...
(cost=0.43..21387.27 rows=393244 width=6)
Index Cond: (total_amount < 50000.00)
(7 rows)
在位图索引扫描期间,位图索引扫描节点中位图的构建始终由单个进程执行。位图完成后,在并行位图堆扫描节点中并行执行扫描:
EXPLAIN SELECT sum(total_amount)
FROM bookings WHERE book_date < '2016-10-01';
QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Finalize Aggregate (cost=21492.21..21492.22 rows=1 width=32)
−> Gather (cost=21491.99..21492.20 rows=2 width=32)
Workers Planned: 2
−> Partial Aggregate (cost=20491.99..20492.00 rows=1 widt...
−> Parallel Bitmap Heap Scan on bookings
(cost=4891.17..20133.01 rows=143588 width=6)
Recheck Cond: (book_date < '2016−10−01 00:00:00+03...
−> Bitmap Index Scan on bookings_book_date_idx
(cost=0.00..4805.01 rows=344611 width=0)
Index Cond: (book_date < '2016−10−01 00:00:00+...
(10 rows)
访问方法的比较
该图显示了各种访问方法的成本与条件选择性之间的依赖关系:
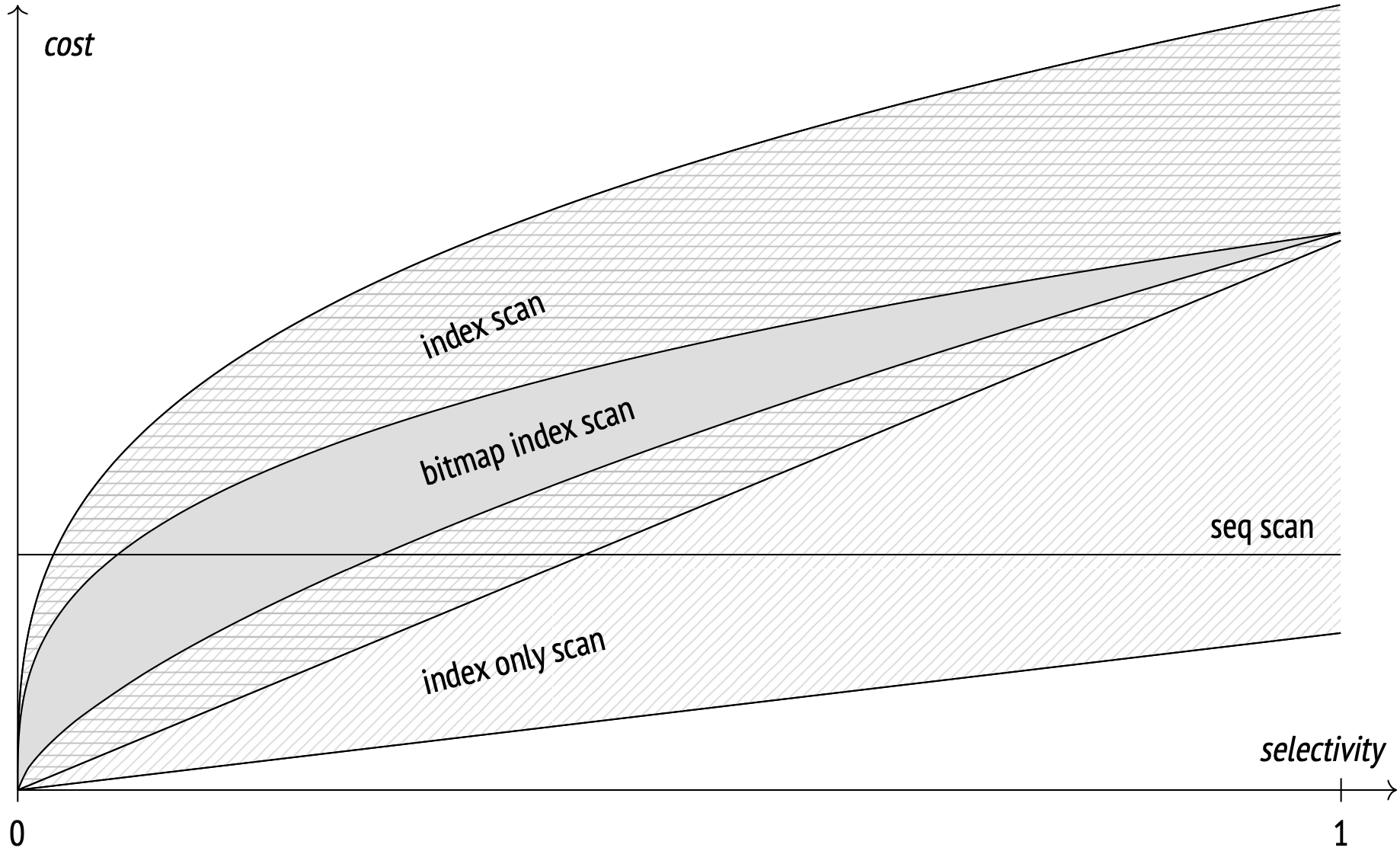
该图是定性的,确切数字显然取决于数据集和参数值。
顺序扫描是选择性不可知的,并且在一定的选择性阈值后通常优于其他扫描。
索引扫描成本在很大程度上取决于磁盘上元组的物理顺序与访问方法返回ID的顺序之间的相关性。即使在更高的选择率下,完美相关性下的索引扫描也优于其他扫描,但在低相关性(通常情况下)下,成本很高,并很快超过顺序扫描成本。总的来说,索引扫描在一个非常重要的情况下占主导地位:每当使用索引(通常是唯一索引)获取单行时。
只有索引扫描可以优于其他扫描(如果适用),甚至包括在全表扫描期间的顺序扫描。然而,其性能在很大程度上取决于可见性图,在最坏的情况下会下降到索引扫描级别。
位图扫描成本虽然取决于为位图分配的内存限制,但仍然比索引扫描成本更可靠。这种访问方法在完全相关时的性能比索引扫描差,但在相关性较低时的性能要优于索引扫描。
每种访问方法都适用于特定情况;没有人总是比其他人更差或更好。规划人员总是不遗余力地为每个具体情况选择最有效的访问方法。为了使其估计准确,最新的统计数据至关重要。
原文标题:Queries in PostgreSQL: 4. Index scan
原文作者:Egor Rogov
原文链接:https://postgrespro.com/blog/pgsql/5969493
