




数据湖中的Parquet和Postgres
静态数据不同
几周前,我在Retool上看到了一篇博客,介绍了他们迁移4TB数据库的经验。他们制定了一些好的程序并成功地进行了迁移,但整个过程因数据库的大小而变得复杂。数据库的大小是两个非常大的“日志”表的结果:一个编辑日志和一个审计日志。
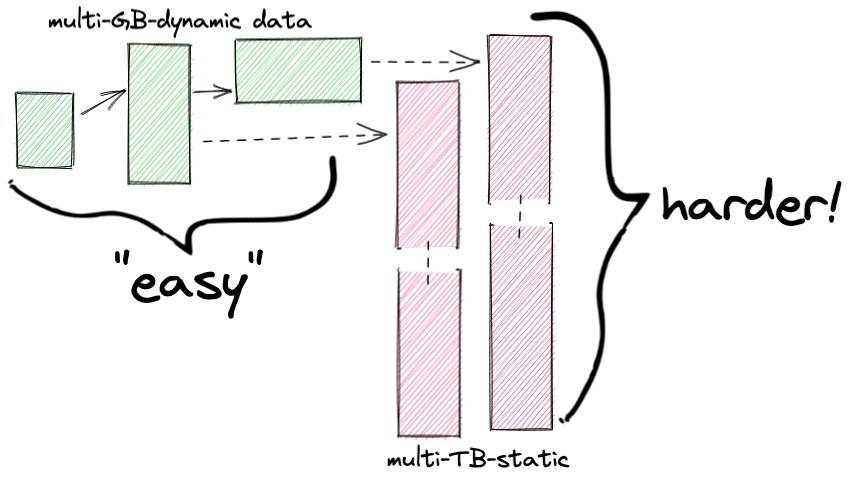
关于日志表,它们变化不大。它们只是设计的。他们也会被相当不规则地查询,并且查询通常是在时间范围内的:“告诉我当时发生了什么”或“向我展示这些日期之间的活动”。
因此,如果将日志表构造为时间范围分区,那么重新工具迁移可能会更容易。这样,分区集中只有一个“活动”表(包含最近条目的表)和一个更大的历史表集合。迁移可以将活动分区作为关键路径的一部分移动,并在以后执行所有历史分区。
即使将日志表分解为可管理的块,它们在总体上仍然相当大!关于分区的PostgreSQL文档对位于分区集合末尾的过时数据有一些苛刻的看法:
删除旧数据的最简单选择是删除不再需要的分区。
这是有道理的!所有这些旧的历史记录只是把你的基本备份弄得一团糟,也许你几乎从来没有机会去查询它。
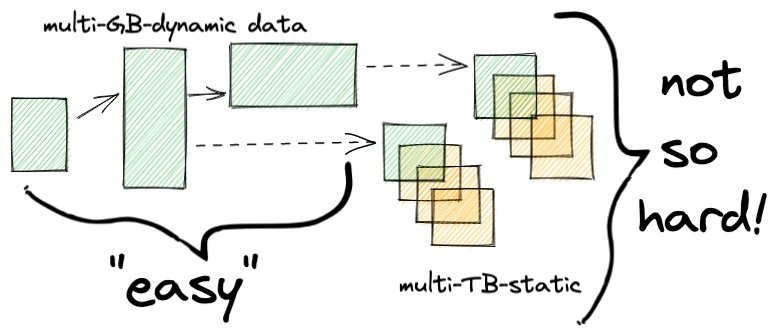
除了丢掉表,还有别的选择吗?
将数据转储到湖中
如果有一个存储选项仍然耐用,允许通过多个查询工具进行访问,并且可以透明地集成到您的操作事务数据库中,该怎么办?
即使将日志表分解为可管理的块,它们在总体上仍然相当大!关于分区的PostgreSQL文档对位于分区集合末尾的过时数据有一些苛刻的看法:
删除旧数据的最简单选择是删除不再需要的分区。
这是有道理的!所有这些旧的历史记录只是把你的基本备份弄得一团糟,也许你几乎从来没有机会去查询它。

如何以Parquet格式存储静态数据,但通过Parquet_fdw保留对数据的数据库访问?
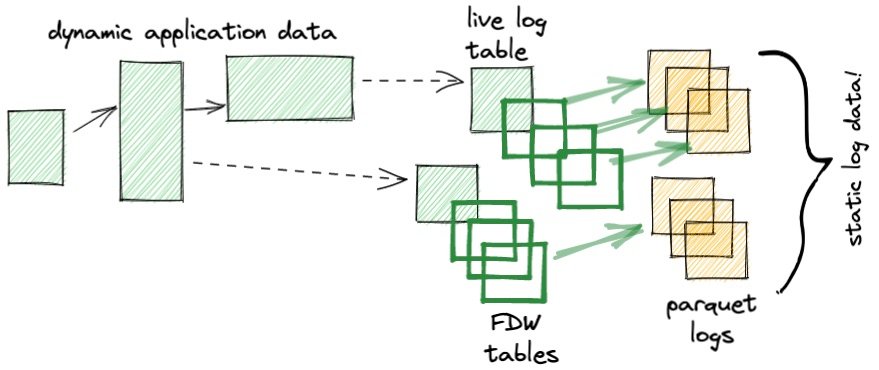
听起来有点疯狂,但是:
-
外部 parquet表可以与本地PostgreSQL表一起参与分区。
-
parquet文件也可以由R、Python、Go和许多云应用程序使用。
-
现代PostgreSQL(14+)可以并行访问外来表,因此即使是Parquet文件的集合也可以有效扫描。
-
Parquet存储压缩的数据,因此您可以将更多的原始数据存储到更少的存储中。
等等, parquet?
Parquet是一种独立于语言的存储格式,专为在线分析而设计,因此:
-
以列为导向
-
已键入
-
二进制的
-
压缩的
PostgreSQL中的标准表将在磁盘上面向行。
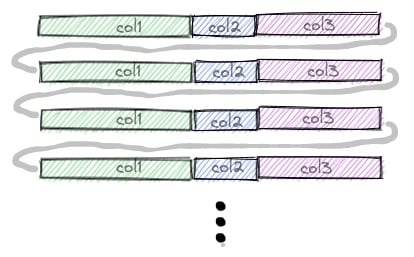
这种布局适用于PostgreSQL需要做的事情,比如一次查询、插入、更新和删除“几个”记录的数据。(根据具体操作,“少数”的值可能达到几十万或数百万。)
拼花文件将数据列存储在磁盘上,分批称为“行组”。
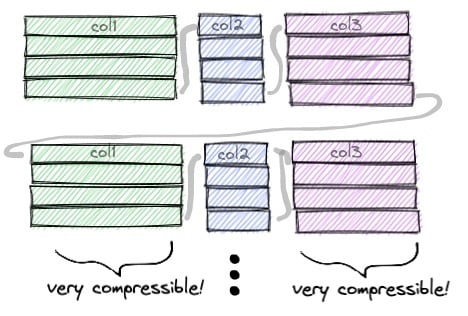
您可以看到Parquet格式的名称:数据分组为小方块,就像Parquet一样。将数据分组在一起的优点之一是,压缩例程往往在相同类型的数据上工作得更好,当数据元素具有相同的值时更是如此。
这行得通吗?
一句话“是的”,但有一些警告:Parquet已经存在了好几年,但相对而言,支撑它的生态系统仍在不断变化。底层C++库的新版本仍在定期发布,parquet_fdw只有几年的历史,等等。
然而,我能够证明我自己的满意,事情烤得足够有趣。
正在加载数据
我从费城停车违规的一个方便的数据表开始,我在之前关于空间连接的博客文章中使用了该表,并按违规日期,issue_datetime对文件进行了排序。

数据下载和排序
#
# Download Philadelphia parking infraction data
#
curl "https://phl.carto.com/api/v2/sql?filename=parking_violations&format=csv&skipfields=cartodb_id,the_geom,the_geom_webmercator&q=SELECT%20*%20FROM%20parking_violations%20WHERE%20issue_datetime%20%3E=%20%272012-01-01%27%20AND%20issue_datetime%20%3C%20%272017-12-31%27" > phl_parking_raw.csv
#
# Sort it
#
sort -k2 -t, phl_parking_raw.csv > phl_parking.csv
在面向列的Parquet设置中,按issue_datetime排序数据将使针对该列进行过滤的查询更快。
-- Create parking infractions table
CREATE TABLE phl_parking (
anon_ticket_number integer,
issue_datetime timestamptz,
state text,
anon_plate_id integer,
division text,
location text,
violation_desc text,
fine float8,
issuing_agency text,
lat float8,
lon float8,
gps boolean,
zip_code text
);
-- Read in the parking data
\copy phl_parking FROM 'phl_parking.csv' WITH (FORMAT csv, HEADER true);
好的,现在我有一个8M的记录数据表,适合于一些大容量数据实验。这张表有多大?
SELECT pg_size_pretty(pg_relation_size('phl_parking')) AS pg_table_size;
pg_table_size
----------------
1099 MB
刚刚超过1GB!
生成Parquet file
我怎么才能拿到Parquet file?
事实证明,这比我预期的要困难得多。大多数互联网建议是使用Python或Spark将CSV文件转换为Parquet。最后,我在GDAL库中使用了非常新的(目前尚未发布,将在GDAL 3.5中发布)对Parquet的支持,并使用ogr2ogr命令进行转换。
ogr2ogr -f Parquet \
/tmp/phl_parking.parquet \
PG:"dbname=phl host=localhost" \
phl_parking
对于这些测试,Parquet文件将驻留在/tmp中的本地磁盘上,但出于云计算的目的,它可能驻留在云卷上,甚至(使用正确的软件)对象存储中。
% ls -lh /tmp/phl_parking.parquet
-rw-r--r-- 1 pramsey wheel 216M 29 Apr 10:44 /tmp/phl_parking.parquet
由于数据压缩,Parquet文件的大小是数据库表的20%!
查询Parquet
在PostgreSQL中查询Parquet涉及许多部分,目前构建这些部分可能具有挑战性。
Apache libarrow,在启用Parquet支持的情况下构建。
Parquet本身。
请注意,parquet_fdw需要libarrow版本6,而不是最近发布的版本7。
但是,一旦构建了FDW和支持库,一切都会像其他FDW扩展一样工作。
CREATE EXTENSION parquet_fdw;
CREATE SERVER parquet_srv FOREIGN DATA WRAPPER parquet_fdw;
CREATE FOREIGN TABLE phl_parking_pq (
anon_ticket_number integer,
issue_datetime timestamptz,
state text,
anon_plate_id integer,
division text,
location text,
violation_desc text,
fine float8,
issuing_agency text,
lat float8,
lon float8,
gps boolean,
zip_code text
)
SERVER parquet_srv
OPTIONS (filename '/tmp/phl_parking.parquet',
sorted 'issue_datetime',
use_threads 'true');
与原始表相比,Parquet file的性能相似,通常稍慢。只需快速进行行计数(当表预缓存在内存中时)。
-- Give native table same indexing advantage
-- as the parquet file
CREATE INDEX ON phl_parking USING BRIN (issue_datetime);
SELECT Count(*) FROM phl_parking_pq;
-- Time: 1230 ms
SELECT Count(*) FROM phl_parking;
-- Time: 928 ms
类似地,PostgreSQL上的过滤器也稍微快一点。
SELECT Sum(fine), Count(1)
FROM phl_parking_pq
WHERE issue_datetime BETWEEN '2014-01-01' AND '2015-01-01';
-- Time: 692 ms
SELECT Sum(fine), Count(1)
FROM phl_parking
WHERE issue_datetime BETWEEN '2014-01-01' AND '2015-01-01';
-- Time: 571 ms
parquet_fdw实现得非常好,甚至会告诉您将在给定过滤器的文件上使用的执行计划。例如,前面的过滤器涉及打开拼Parquet文件中132行组中的约20%。
EXPLAIN SELECT Sum(fine), Count(1)
FROM phl_parking_pq
WHERE issue_datetime BETWEEN '2014-01-01' AND '2015-01-01';
Finalize Aggregate (cost=6314.77..6314.78 rows=1 width=16)
-> Gather (cost=6314.55..6314.76 rows=2 width=16)
Workers Planned: 2
-> Partial Aggregate (cost=5314.55..5314.56 rows=1 width=16)
-> Parallel Foreign Scan on phl_parking_pq (cost=0.00..5242.88 rows=14333 width=8)
Filter: ((issue_datetime >= '2014-01-01 00:00:00-08')
AND (issue_datetime <= '2015-01-01 00:00:00-08'))
Reader: Single File
Row groups: 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51,
52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63
对于遍历整个表并进行摘要,Parquet查询的速度大约与PostgreSQL查询相同。
SELECT issuing_agency, count(1)
FROM phl_parking_pq
GROUP BY issuing_agency;
-- Time: 3043 ms
SELECT issuing_agency, count(1)
FROM phl_parking
GROUP BY issuing_agency;
-- Time: 3103 ms
我对性能差异的内部模型是,虽然Parquet格式通过行块过滤和仅访问感兴趣的列在避免不必要的读取方面具有一些优势,但这些优势被将原始数据从Parquet转换为内部PostgreSQL格式的效率低下所抵消。
结论
我们已经看到:
-
Parquet是一种软件中立格式,在数据科学和数据中心中越来越常见。
-
通过Parquet_fdw扩展,可以使Parquet访问对PostgreSQL透明。
-
Parquet存储可以节省大量空间。
-
Parquet存储比本机存储慢一点,但可以从备份和其他数据所需的可靠性操作中卸载静态数据的管理。
-
静态数据的Parquet存储比仅仅将其丢弃要好得多。
更重要的是,我认为还有更多需要讨论:
-
Parquet文件可以参与分区吗?
-
Parquet可以在集合中并行访问拼花文件吗?
-
Parquet可以驻留在云对象存储中而不是文件系统存储中吗?
-
带parquet存储的PostgreSQL能否像“中端大数据引擎”一样处理parquet支持的大量静态数据集上的数字?
到目前为止,Parquet工具的生态系统一直由数据科学(R和Python)和少数云OLAP系统(Apache Spark)的需求所主导,但PostgreSQL没有理由不能开始分享这种常见的云格式优势,并开始在数据湖中畅游。
原文标题:Parquet and Postgres in the Data Lake
原文作者:Paul Ramsey
原文链接:https://www.crunchydata.com/blog/parquet-and-postgres-in-the-data-lake
