





01 前言
近年来,在金融科技的推动下,互联网金融业务蓬勃发展,金融行业数据处理呈现出新的特征,如数据量大、并发量高、处理性能高、类型繁多等。这就对海量数据的存储、并发访问及实时分析能力提出了新的要求。
另一方面来讲,“事后”分析已经不能满足快速的市场需求和业务变化,需要对海量客户行为数据的实时洞察提高营销精准度,如实时推荐等,并持续监测交易行为提高风险预警能力,如实时风控、反欺诈等。传统技术架构下的数据分析业务,其数据时效性面临着前所未有的挑战。
HTAP(混合事务/分析处理),是Gartner提出的一种新兴的应用框架,旨在打破事务处理和分析之间“壁垒”,在同一个数据库中,提供更高效的“实时业务”决策。
本次最佳实践,我们将为您展开讲解,如何利用巨杉分布式数据库SequoiaDB,实现HTAP混合事务/分析处理,实现OLTP与OLAP及资源平衡。

02 背景
2.1 业务需求变革
2.2 传统OLTP/OLAP的痛点
目前在业内,实现HTAP混合负载,主要有三种技术方案:
• 单一系统同时承载混合负载(如DB2、Oracle、MySQL等)
• 使用不同系统组合+数据同步技术(如ETL、GoldenGate、CDC等)
• 同一存储不同计算引擎(如HBase+Spark等)
这些技术实现HTAP混合负载,无论何种方案,均存在一定的缺陷和短板。
数据共享难题
传统技术使用Oracle、MySQL、DB2、Informix等数据库构建业务,分离部署,数据分散存储。要实现HTAP混合负载,需要构建多套数据库,并基于一系列的数据复制技术,或基于ETL进行数据加工、转换。这样一来,不但架构的复杂性大大增加,数据传输消耗了大量的网络带宽进行数据传输。即便如此,这种跨库实现的混合负载,数据的延迟得不到有效解决。
例如一个关联查询,往往需要在不同机构实现跨库数据查询。甚至,有些数据已经使用磁带落库的方式永久封存,数据远远没有发挥出其应有价值。如何能够打通各个业务系统,把数据盘活,解决复杂的数据复制,让数据能够给业务带来新的增长点,是现在面临比较棘手的问题。

图1 OGG+Kafka实现数据复制
性能不能兼顾
扩展性难题
开发接口单一
2.3 巨杉分布式数据库SequoiaDB的HTAP技术优势
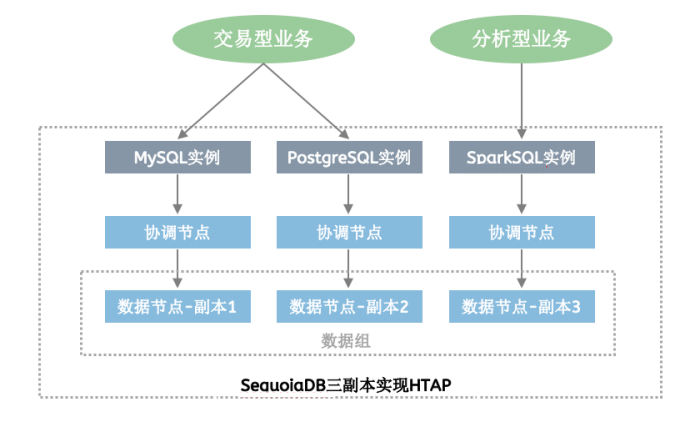
03 分布式数据库HTAP技术特性
3.1 副本
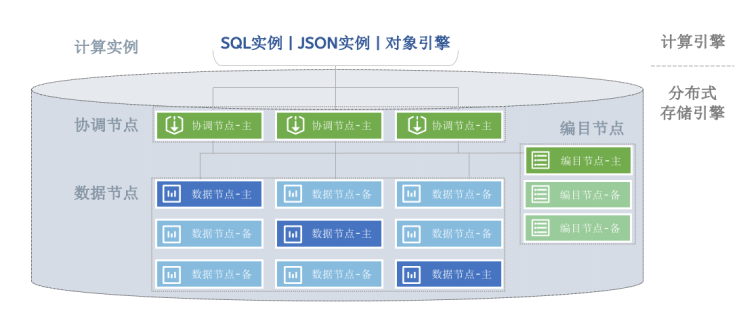
• 数据分散存储在不同的数据组中;
• 主副本提供读、写服务,备副本提供只读服务;
数据组内,有多个副本,由数据库内部的一致性算法实现数据同步。
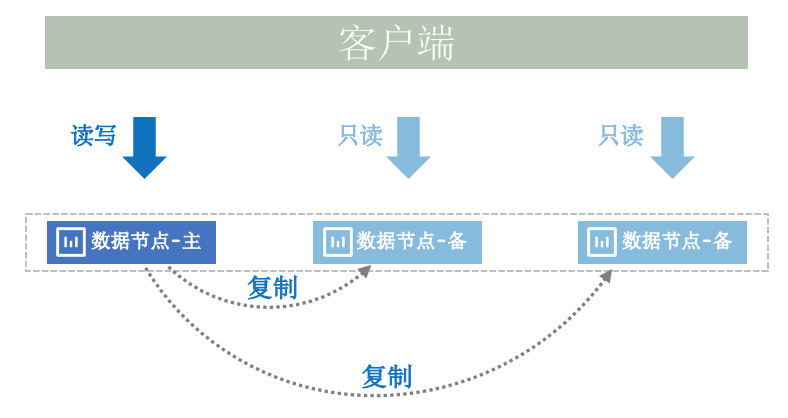
3.2 负载隔离
• 各个副本之间,没有任何负载干扰,完全实现了HTAP混合负载下的负载隔离。
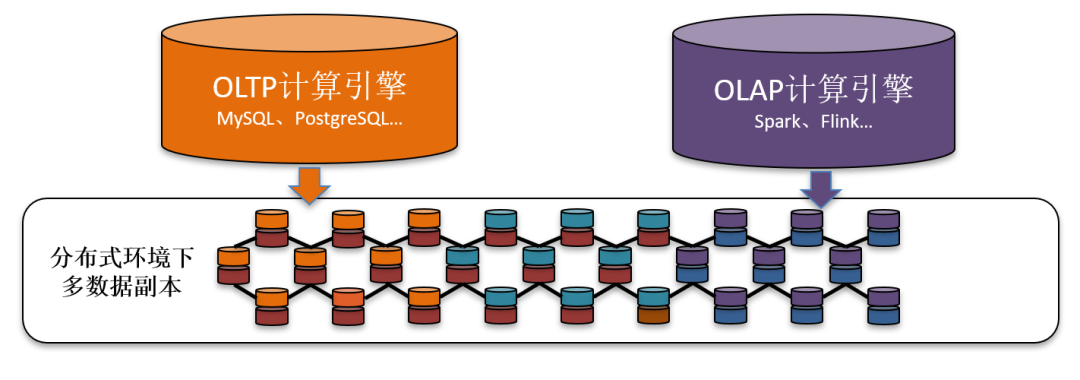 图5 HTAP负载隔离
图5 HTAP负载隔离3.3 多种SQL引擎
分布式数据库支持多种SQL引擎,常见的有:
1、MySQL引擎
2、PostgreSQL引擎
3、Spark引擎
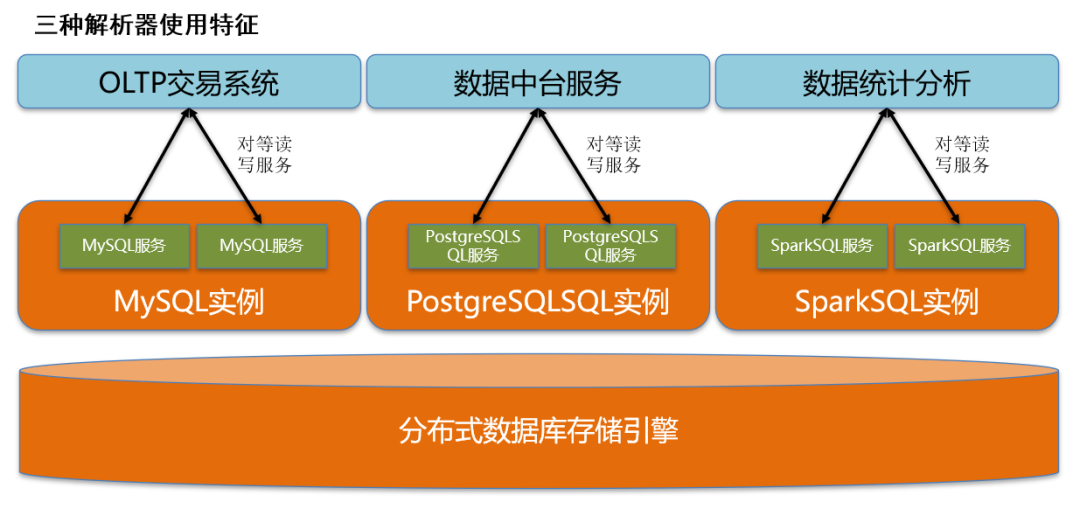
图6 三种解析器使用特征
各类引擎的特点如下:
SQL引擎 | 描述 | 适用场景 |
MySQL 引擎 | 适合精准查询、业务数据写入、柜面查询等场景 增删查改操作和普通MySQL完全一致 和MySQL语法兼容度达到100% | OLTP |
PostgreSQL 引擎 | 以复杂SQL语法和强大的SQL编程能力见长 支持增删查改等功能,和普通PostgreSQL使用完全一致 采用外部表的方式将数据存储在分布式数据库中 | OLTP OLAP |
Spark 引擎 | 可扩展的数据分析组件,集成了原生的内存计算 适合报表分析、大表关联查询等 提供友好、高性能的关联查询 支持标准SQL、支持JDBC访问、支持Python等接口 通过使用 Spark连接组件,来访问分布式数据库存储引擎 | OLAP |
04 分布式数据库HTAP最佳实践
4.1 环境描述
本文的示例中,我们选择MySQL作为OLTP引擎,SparkSQL作为OLAP分析引擎。
计算引擎可实现集群部署。MySQL和SparkSQL实例均可部署在多台服务器,对连接请求实现均衡的同时,避免了单点故障隐患;
分布式存储引擎。SequoiaDB数据库分布式存储引擎中,数据节点分布在多台服务器上,这样能够充分利用服务器的数据存储和计算能力;
网络隔离。在Spark计算引擎读写繁忙的情况下,会产生较大的网络传输从而侵占MySQL实例在线事务处理的带宽资源,因此,生产环境下建议为Spark和MySQL实例配置独立的网卡。
本次最佳实践案例的实验环境规划如下:
服务器规划:
IP地址 | 主机名 |
192.168.100.201 | sdb01 |
192.168.100.202 | sdb02 |
192.168.100.203 | sdb03 |
节点 | sdb01 | sdb02 | sdb03 |
SQL引擎 | MySQL实例 | PostgreSQL实例 | SparkSQL实例 |
协调节点 | 协调节点 | 协调节点 | 协调节点 |
编目节点 | 编目节点(主) | 编目节点 | 编目节点 |
数据节点 (副本) | 数据组1-主副本 | 数据组1-备副本 | 数据组1-备副本 |
数据组2-主副本 | 数据组2-备副本 | 数据组2-备副本 | |
数据组3-主副本 | 数据组3-备副本 | 数据组3-备副本 |
节点 | sdb01 | sdb02 | sdb03 |
SQL引擎 | MySQL实例 | PG实例 | Spark实例 |
数据节点 首选连接 | 首选主副本 | 首选主副本 | 首选备副本 |
规格 | |
服务器数量 | 3台 |
CPU | 8 核 |
内存 | 16GB |
磁盘 | 100GB * 3 |
操作系统 | Centos 7.4 |
软件 | 版本 |
SequoiaDB | 3.4 |
MySQL | 5.7.25 |
Spark | 2.3.3 |
4.2 过程演示
演示场景:
1、 MySQL、PostgreSQL、SparkSQL跨引擎数据操作及查询
在MySQL中,创建bills.orders表并插入数据,进行数据的增删改查操作;
在PostgreSQL、SparkSQL中查询,并验证数据正确性;
2、 跨引擎Join查询
在MySQL中再创建一张表bills.customers;
在SparkSQL中进行bills.orders、bills.customers的表关联查询;
查看各个数据副本的访问统计,来验证HTAP负载隔离。
4.2.1 创建测试orders表、进行HTAP配置
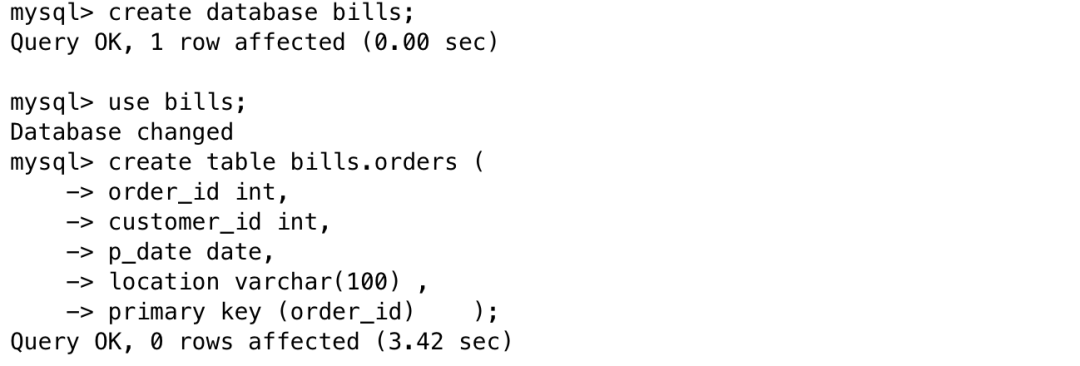
1、在MySQL实例中创建表的步骤如下:
mysql -h 127.0.0.1 -P 3306 -uroot -proot
create database bills;use bills;
create table bills.orders (order_id int,customer_id int,p_date date,location varchar(100) ,primary key (order_id) );注:在SequoiaDB数据库中, 使用MySQL引擎建表,默认即使用SequoiaDB分布式存储引擎。
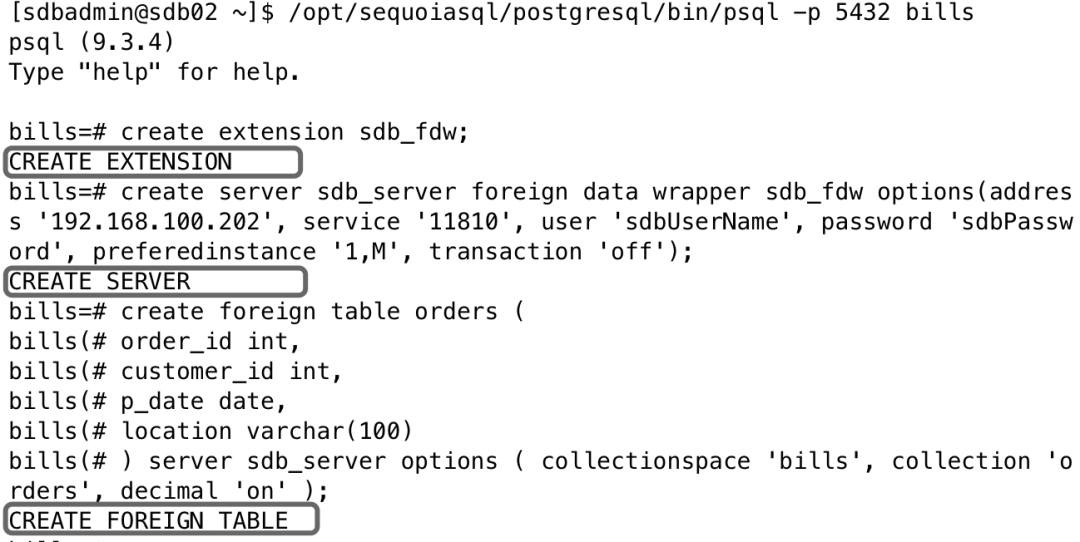
2、在PostgreSQL实例中创建表
在PostgreSQL客户端创建外部表bills.orders,并映射到数据库引擎中的orders表。
//登陆PostgreSQL客户端/opt/sequoiasql/postgresql/bin/psql -p 5432 bills//加载SequoiaDB连接驱动create extension sdb_fdw;//配置与SequoiaDB连接参数create server sdb_server foreign data wrapper sdb_fdw options(address '192.168.100.202', service '11810', user 'sdbUserName', password 'sdbPassword', preferedinstance '1,M', transaction 'off');//创建orders表create foreign table orders (order_id int,customer_id int,p_date date,location varchar(100)) server sdb_server options ( collectionspace 'bills', collection 'orders', decimal 'on' );
3.SparkSQL实例中创建表
在SparkSQL客户端创建外部表bills.orders,并映射到数据库引擎中的orders表。
$ 登陆spark beeline客户端/opt/spark-2.3.3-bin-hadoop2.7/bin/beeline -u 'jdbc:hive2://192.168.100.203:10000'//创建orders表create table bills.orders (order_id int,customer_id int,p_date date,location varchar(100) )USING com.sequoiadb.spark OPTIONS ( host '192.168.100.203:11810', collectionspace 'bills', collection 'orders',preferredinstance '2,3,S') ;select * from bills.orders;


说明Spark中orders表创建成功。
Note: 1、Preferedinstance选项:会话读操作优先选择的策略,取值列表:"M"、"S"、"A"、1-255。可以使用数组指定多个取值。"M":可读写实例(主实例) "S":只读实例(备实例) "A":任意实例 1-255:通过 instanceid 指定实例 ID 的实例。 2、Instanceid,是一个数据组内,各个副本的编号,默认是0。设置该参数后,可以SQL实例中建表时,指定其访问的首选副本。
在本文中,将SQL实例的访问策略设置为:MySQL、PostgreSQL优先连接主副本,SparkSQL优先连接备副本,从而实现HTAP负载隔离。因此,还需要对所有数据组的各个副本设置其instanceid。
//本例中将主副本的instanceid设置为1,两个备副本设置为2、3.//登陆SequoiaDB存储引擎$ sdbdb = new Sdb( "192.168.100.201", 11810 )db.updateConf( { instanceid:1 }, { GroupName:"group1", NodeName:"sdb01:11830" } );db.updateConf( { instanceid:2 }, { GroupName:"group1", NodeName:"sdb02:11830" } );db.updateConf( { instanceid:3 }, { GroupName:"group1", NodeName:"sdb03:11830" } );//以group1为例,其他数据组操作类似。
4.3.2 在MySQL中插入测试数据
登陆MySQL,向bills.orders表中插入4条测试数据:
insert into bills.orders values(10001,1,"2017-06-01","Beijing");insert into bills.orders values(10002,2,"2018-06-01","Shanghai");insert into bills.orders values(10003,3,"2019-06-01","Guangzhou");insert into bills.orders values(10004,4,"2020-06-01","Shenzhen");
查看数据:
select * from bills.orders;

4.3.3 在MySQL中操作数据
在MySQL中,更新bills.orders中一条记录,并查询:
update bills.orders set location="Nanjing" where order_id=10001;select * from bills.orders;

delete from bills.orders where order_id=10002;select * from bills.orders;

4.3.4 在PostgreSQL中查询数据
登陆PostgreSQL客户端,并查询orders表数据:
/opt/sequoiasql/postgresql/bin/psql -p 5432 bills//查询orders表数据:select * from orders;
 这说明在MySQL中的数据,在PostgreSQL中是共享的。
这说明在MySQL中的数据,在PostgreSQL中是共享的。
4.3.5 在SparkSQL中查询数据
登陆SparkSQL客户端,并查询orders表数据:
/opt/spark-2.3.3-bin-hadoop2.7/bin/beeline -u 'jdbc:hive2://192.168.100.203:10000'//查询orders表数据:select * from bills.orders;

这说明,MySQL中所操作的数据,在Spark SQL中是共享的。
从数据的增、删、改、查操作可以看出,数据在MySQL和PostgreSQL、SparkSQL中是完全共享的。
4.3.6 跨引擎JOIN查询
1. 创建第二张表bills.customers
MySQL中创建customers表结构:
create table bills.customers (customer_id int,customer_name varchar(100) ,gender char(1),birth_date date,primary key (customer_id) );
Spark中创建customers表结构
create table bills.customers (customer_id int,customer_name varchar(100) ,gender char(1),birth_date date )USING com.sequoiadb.spark OPTIONS ( host '192.168.100.203:11810', collectionspace 'bills', collection 'customers',preferredinstance '2,3,S') ;
2. 向2个表分别插入测试数据
登陆MySQL实例,向orders、customers表各插入50000条数据
//为便于插入,创建存储过程proc_insertdrop procedure if exists proc_insert;delimiter ;;create procedure proc_insert()begindeclare i bigint default 1;while i<50001doinsert into bills.orders values (i*177,i,"2018-05-09",'Beijing');insert into bills.customers values (i,'Tom','F',"2018-05-09");set i=i+1;end while ;commit;select i as "Inserted Rows of orders: ", i as " Inserted Rows customers: ";end;;//清空现有数据,调用存储过程,插入数据delete from bills.orders;call proc_insert();;

//数据查询select count(*) from bills.orders;select count(*) from bills.customers;
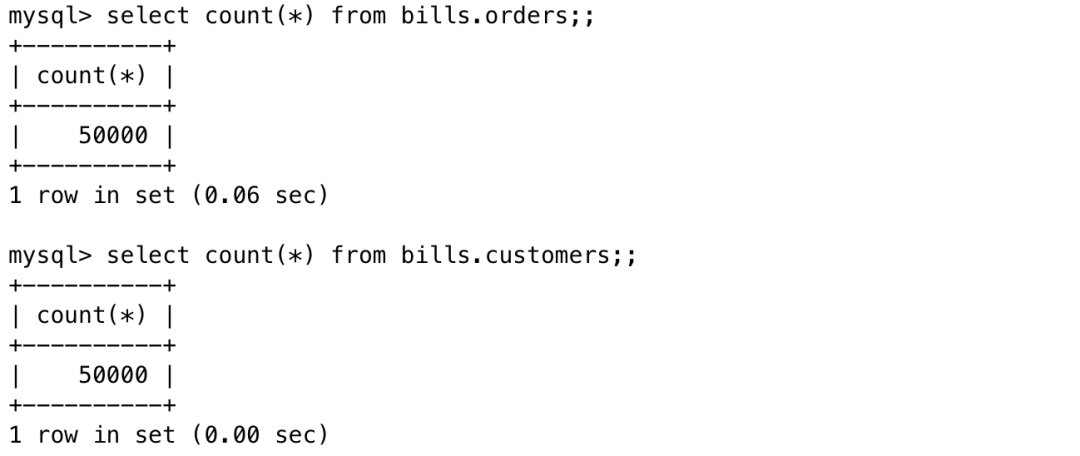
至此,数据库中已存在2张表,orders表、customer表,分别有50000条数据。
3. 在Spark中进行JOIN查询
select count(*)from bills.orders o inner join bills.customers con o.customer_id=c.customer_id ;
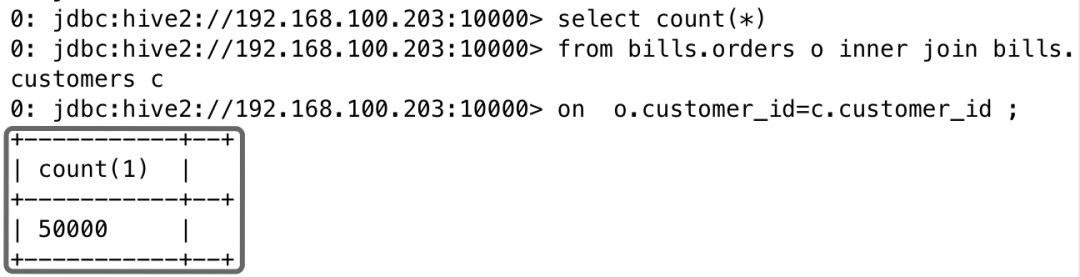
4.3.7 HTAP负载隔离验证
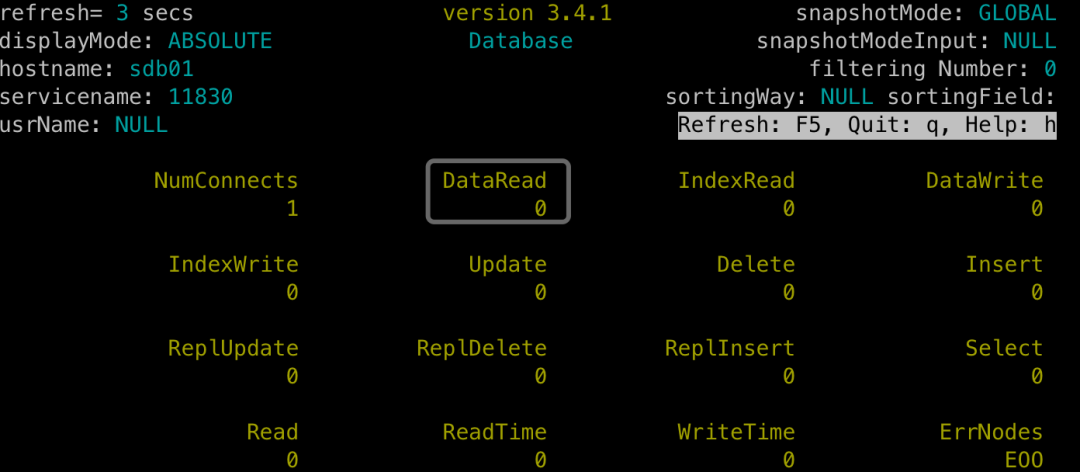
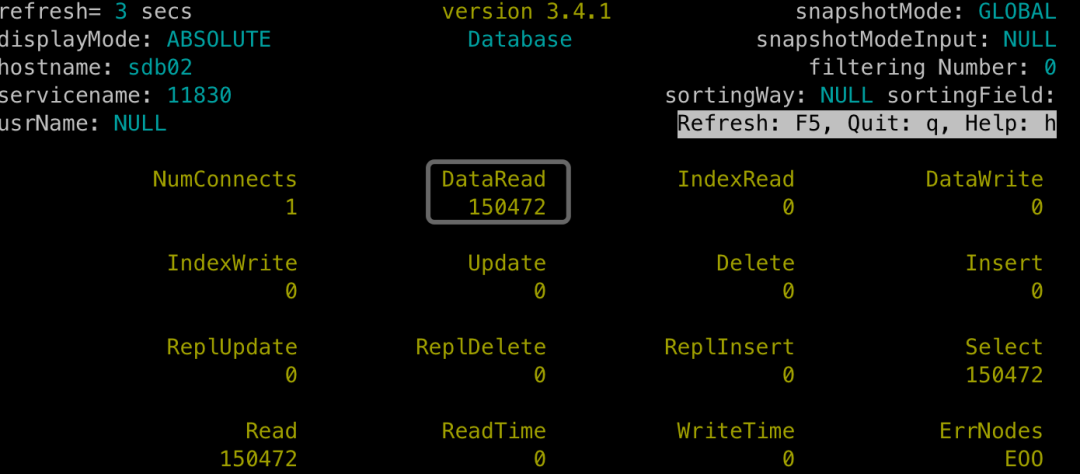
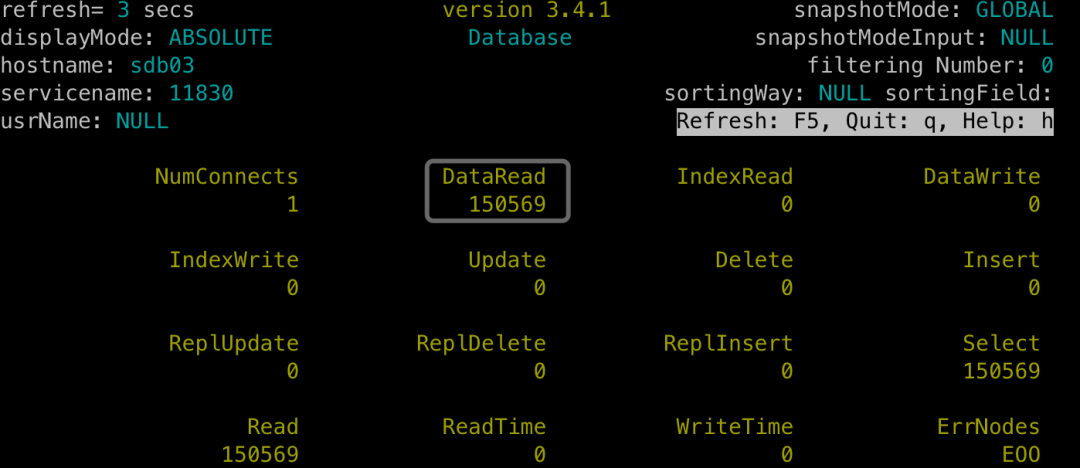
将上章节的JOIN查询连续运行10次,使用SequoiaDB的节点监控工具sdbtop,来观察各个副本的读写次数统计。
(备注:1、以数据组group1:11830为例,其他数据组效果相同;2、为了便于展示,此时重启了数据节点,将统计清零。)
sdb01上的主副本:无任何数据读取。
sdb02上的备副本:产生150472次数据读取。
sdb03上的备副本:产生150569次数据读取。
从结果可以看出:SequoiaDB的HTAP混合负载,已经通过多副本策略,实现了负载隔离效果:
• MySQL对主副本进行写入;
• SparkSQL实例对备副本进行只读查询;
• OLTP、OLAP的负载运行在不同服务器上,互相不产生干扰。
05 总结
HTAP混合负载,意味着数据库可以同时承载在线交易业务和统计分析业务。分布式数据库,利用计算-存储分离的架构特点和访问隔离功能,结合了MySQL、PostgreSQL引擎和Spark计算引擎,使复杂的联机分析处理(OLAP)与联机交易(OLTP)处理在一个数据库中得以实现。
分布式数据库提供了多种级别的隔离策略,来实现读写分离,使不同的业务场景访问不同类型的数据副本,使得业务访问性能得到了提升。
 往期技术干货
往期技术干货

