




写一个后记吧,上次说道从计算模型入手, 把业务转向查询新模型表, 其数据量精简300倍,从本质上使得业务查询可控。
但hive 可不是关系型数据库, 没有关系型数据库的主键索引。那么如何做到迅速响应业务速查呢?
背景:
新模型表数据量2.3千万。月增量30W+,如何速查这样表?
新模型表设计:
新模型表数据选择为ORC存储格式
官方资料
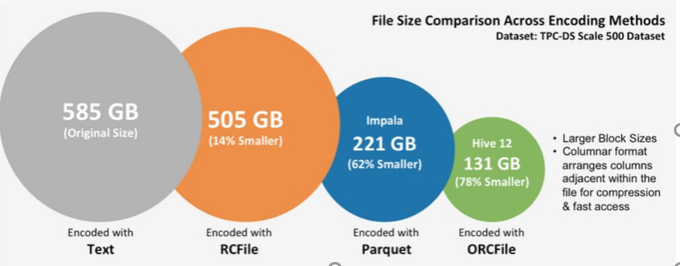
解释:TEXT文本文件为585GB,使用Hive早期的RCFILE压缩后为505GB,使用Impala中的PARQUET压缩后为221GB,而Hive中的ORC压缩后仅为131GB,压缩比最高。
所以数据压缩后扫描更容易:
本案例中最新模型表,2.3千万条数据,350M。
使用bloom filter index(ORC INDEX):
使用ORC INDEX 跳过不必扫描的stripe.
官方文档:https://orc.apache.org/docs/indexes.html

甚至做到“范围扫描”。(给hive贡献了范围扫描,无异于牛顿对物理学的贡献)
文档:https://community.cloudera.com/t5/Community-Articles/ORC-Creation-Best-Practices/ta-p/248963
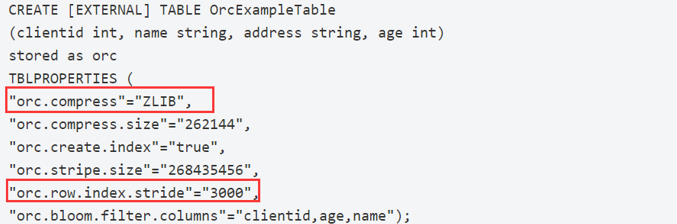

右图中跳过75%的数据,只扫描25%的数据就可完成查询。
(PS:我们的谓词条件也是user_id=XXXX.而且具有唯一性。这样的数据分布对stripe, index sride 都要有规划。)
参考文档:http://lxw1234.com/archives/2016/04/632.htm。也实现了“范围扫描”
控制存储文件个数
当模型表初步成型后,350M,但是其存储文件数量有1001个。 合并后2个数据文件。小文件也是hadoop/hive 中的痛点。模型上线前也是要严格管理的。当然这个也是模型设计适合需要解决的,以后写一篇文档专门说道说道这种模型怎么设计,怎么维护。
最终结果:
查询单一用户的最早业务时间:
老模型 | 新模型_v1 | 新模型_v2 |
查询大表 | 查询小表 | 查询小表 |
ORC存储 | ORC存储 | |
小文件合并 | ||
INDEX精密调整 | ||
1.5小时+(未完成,杀了会话) | 5min+/次 | 10S/次(可以进一步优化) |
