




本文解读的是SIGMOD 2020的论文 CockroachDB: The Resilient Geo-Distributed SQL Database ,主要介绍了著名开源分布式数据库 CockroachDB 的整体架构,包括容灾、高可用、强一致性事务和SQL引擎的设计。我们将着重谈论其中的事务处理部分。 由于论文本身篇幅限制,为了更好地理解CockroachDB的设计,本文会结合CockroachDB的源码、文档做一些补充。
整体介绍
基本概念
首先明确几个概念:
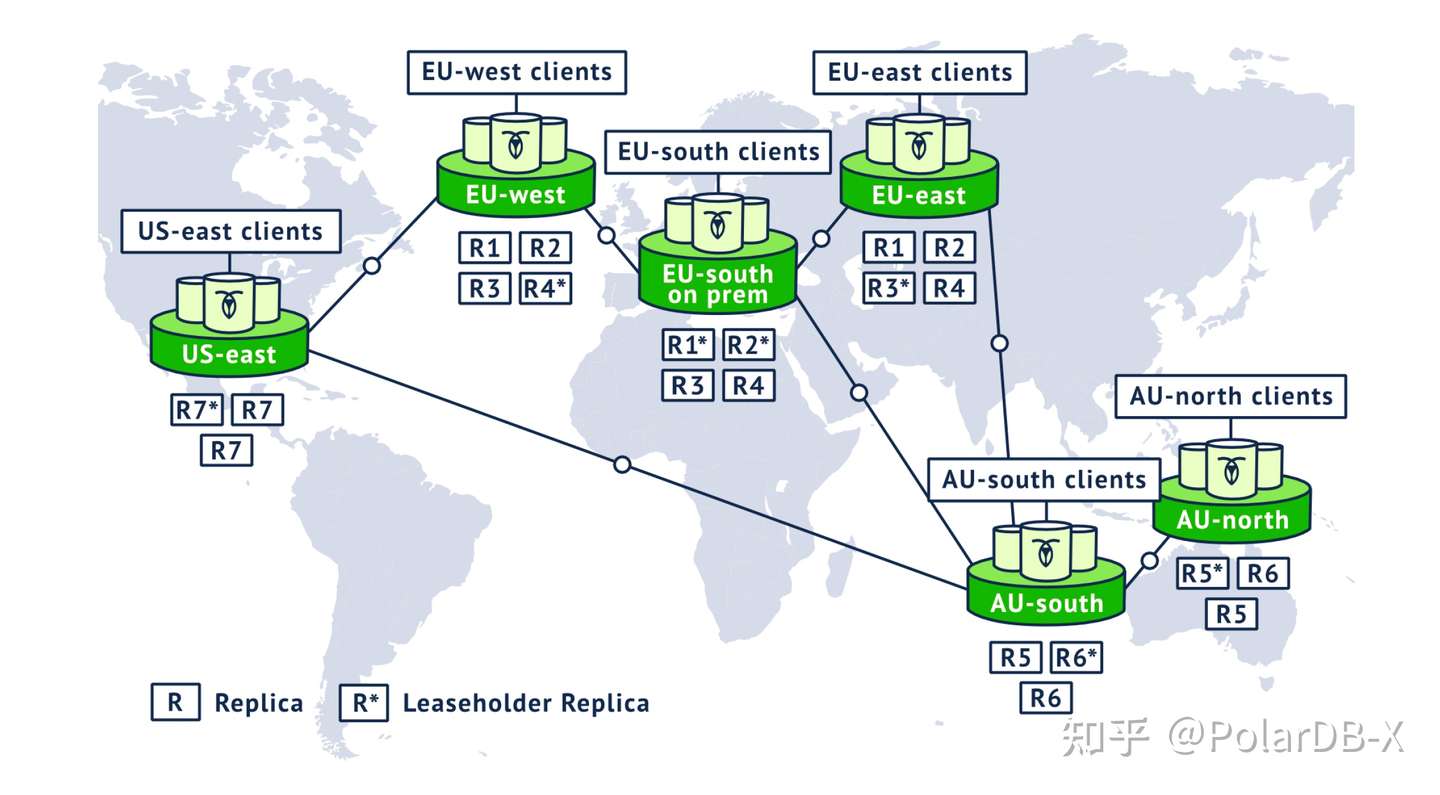
Range:CockroachDB使用范围分区的方式,将全局递增有序的K-V数据,划分为64MB单位大小的chunk,称为K-V Range。Range是路由、存储、复制的基本单位,具备自动分裂与合并的能力。
Leaseholder:CockroachDB中最重要的概念之一,涉及到lease机制。简单来说,持有lease的副本可以对外提供KV的一致性读写。如果一个raft group中的某个副本持有lease,那么该副本所在的节点称为leaseholder节点。持有lease的副本,一般也是raft group中的一个leader。
Gateway: gateway节点是和leaseholder节点相对的概念。gateway节点负责解析SQL请求、充当事务的coordinator,并将KV操作路由到正确的leaseholder节点上。
Raft Leader / Log / Replica:至少3的range可以组成一个raft group,对外保证高可用和一致性的读写。raft 中的leader、log、replica用于选举、日志复制等,属于Raft 算法的范畴,这里不再赘述。
例如,一个三节点的CockroachDB集群,有如下的结构:
一次SQL处理流程
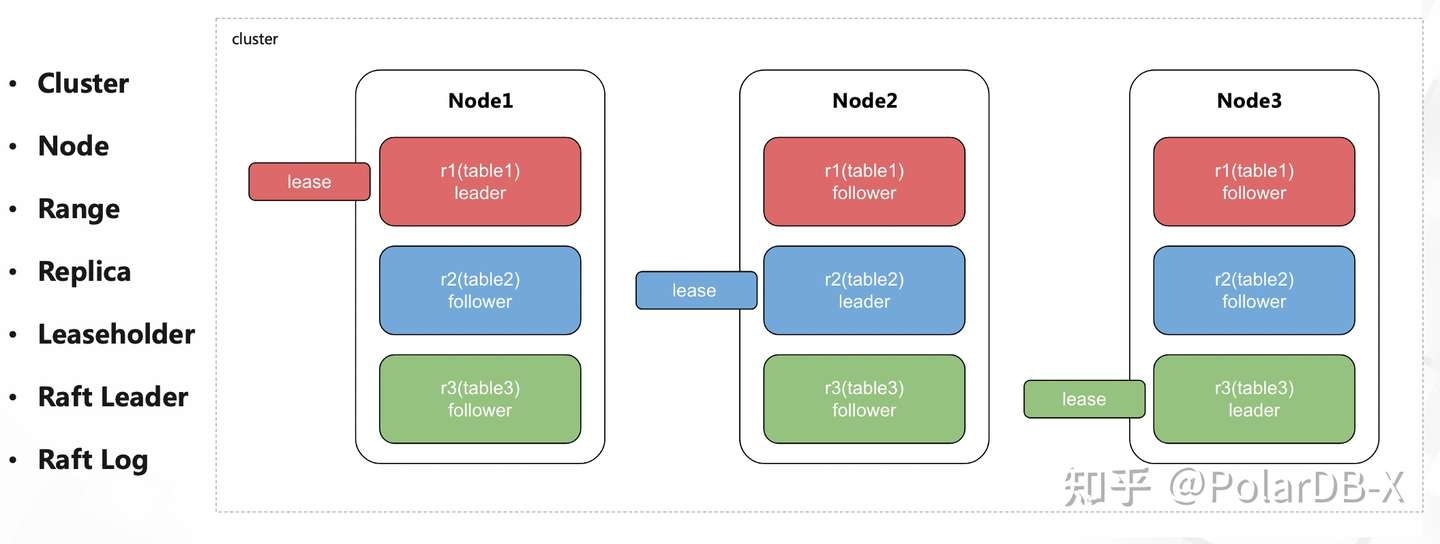
我们通过一个简化的模型,举例说明一次写入的过程。现有三个CockroachDB节点,数据库包含三张表,每个表只包含一个Range的数据,每个Range隶属于三副本raft group:
- 用户SQL发起对table 1的写入请求,被最近的节点3接收;
- 由于table1 所在range的leaseholder,位于节点1上,因此需要将请求路由到节点1执行;
- 节点1 处理写入请求,将相关日志复制到节点2、3的副本上;
- 节点2、3返回ack消息,节点1完成复制并apply日志;(实际上,节点2、3其中一个返回复制成功消息,就已经满足Quorum;CockroachDB 的write pipeline优化让这一步能够异步执行。)
- 节点1将写入成功的消息传给节点3;
- 节点3响应用户。
节点内部结构
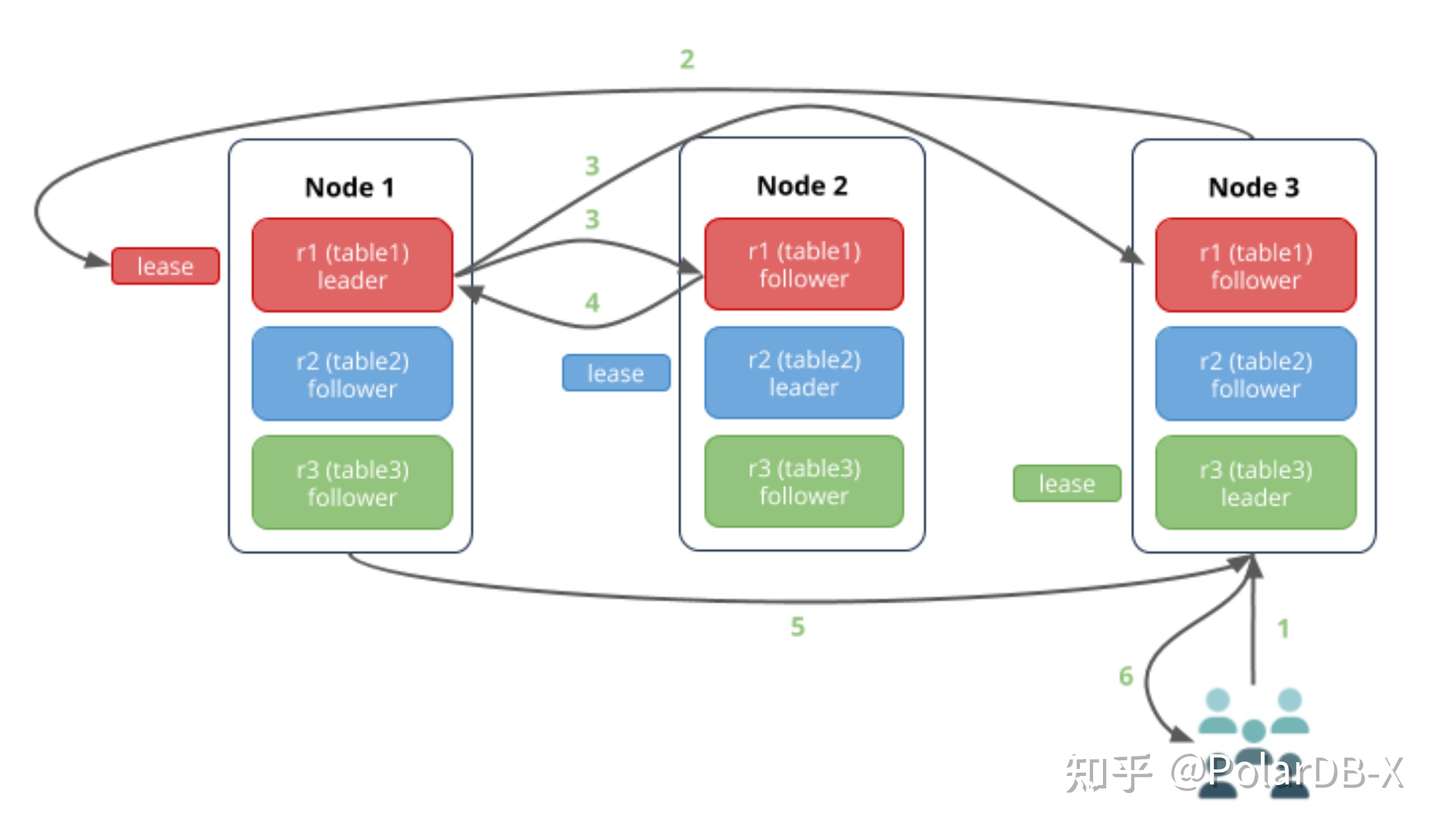
CockroachDB采用了Share-nothing的架构,所有节点同时承担着计算、存储能力。从节点内部结构来看,可以分为这么几个层次:
SQL层:接收客户端SQL,执行SQL的解析、优化,生成执行计划,最终将SQL转化为一组 K-V 请求;
Transaction层:接收SQL层的K-V请求,保证K-V操作的原子性和隔离性;
Distribution层:抽象了一层全局有序、单调递增的K-V存储空间,接收Transaction层的K-V请求,路由到正确的K-V Range 上。
Replication层:每个Range至少有三个副本,分布在不同的节点上,共同组成一个高可用的range group。
Storage层:基于RocksDB构建的本地KV存储。
结合之前的leaseholder/gateway的定义来看,可以粗略认为 SQL层、Transaction层和Distribution层的能力在gateway node上完成,repliction和storage层的能力在leaseholder node上完成。
事务整体流程
CockroachDB 利用MVCC机制,对外提供隔离级别为 Serializable 的一致性事务。当事务发起时,SQL首先会被转发到 gateway 节点。gateway 节点 负责与客户端进行直接交互,同时也充当着事务中transaction coordinator 的角色。应用通常会选择地理上最接近的 gateway 节点来发送SQL请求,以保证较低的延迟。
Transaction Coordinator 执行
下图中的algorithm 1介绍了transaction coordinator 的大致执行模式。当上层的SQL layer 将用户SQL请求处理为一个KV操作序列后,transaction coordinator 负责将 KV操作序列以满足事务语义的形式来执行。
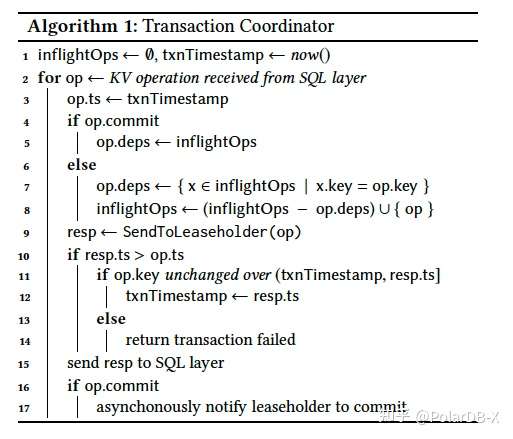
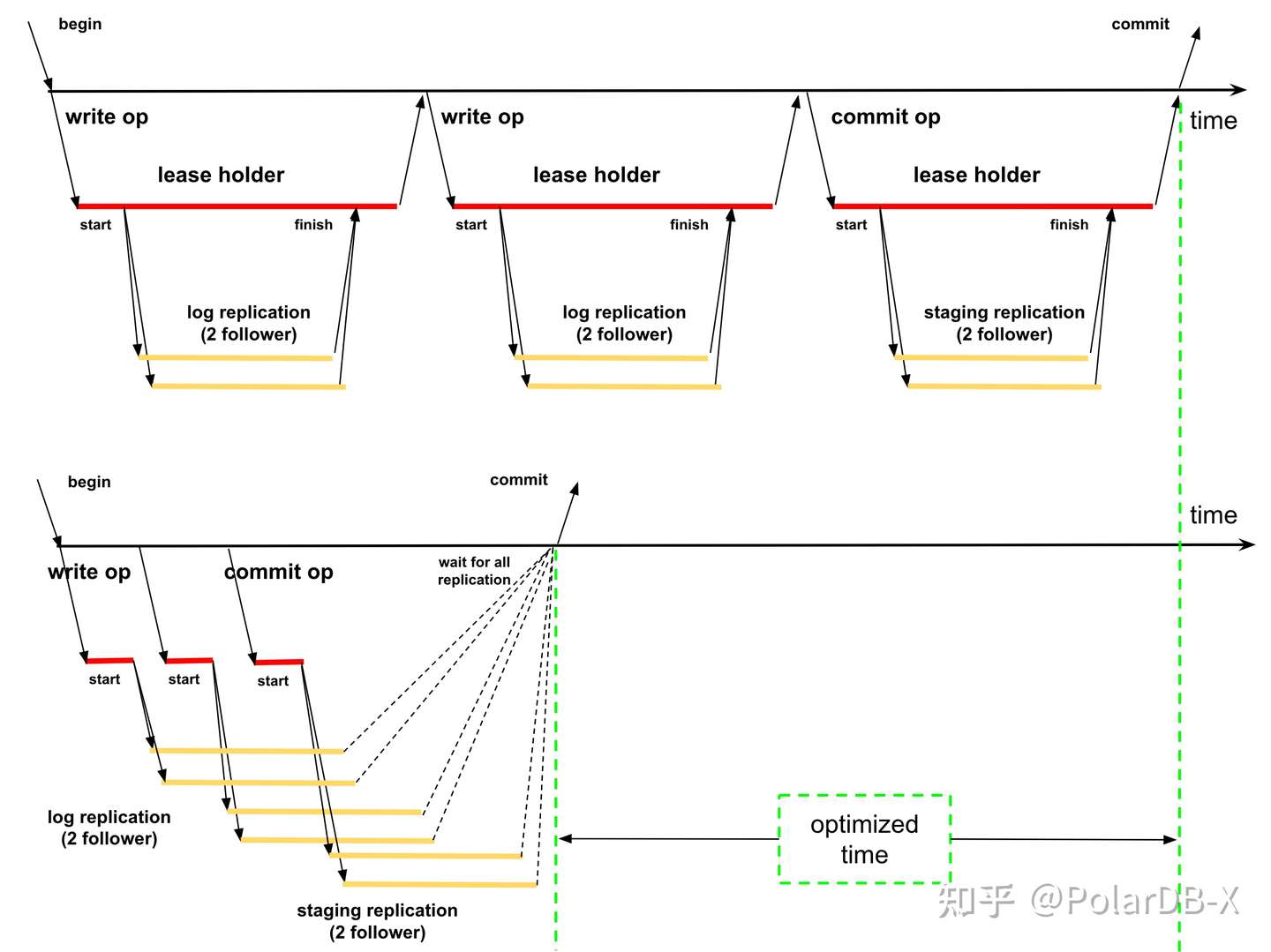
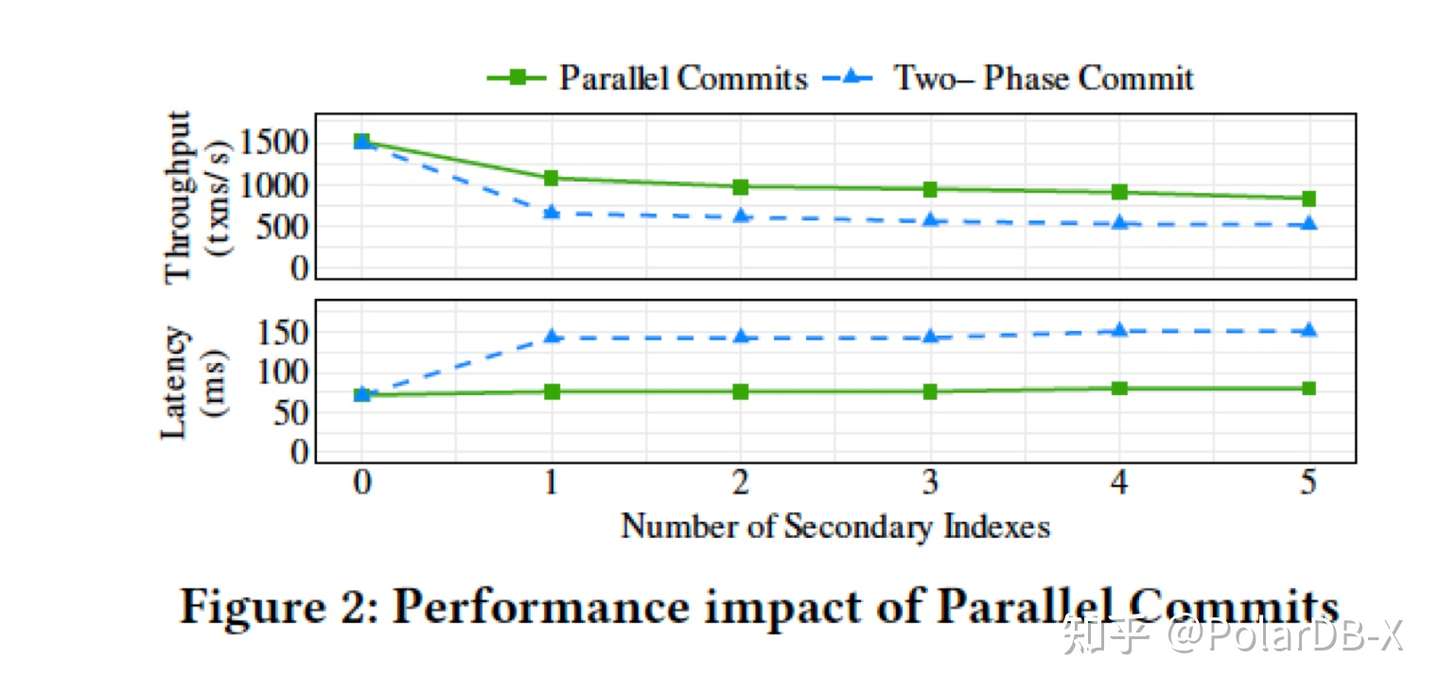
一般地,我们只有等待事务内的上一次SQL请求完成,才能处理事务内的下一次SQL请求。为了优化这一执行模式,CockroachDB 引入了两种重要的事务处理策略: Write Pipeline 和 Parallel commit 。Write Pipeline 顾名思义,就是让写操作像流水线一样执行。具体来说,Write Pipeline 允许一次写操作可以不等待复制完成,就返回写请求成功,从而达到流水线执行的效果;Paralllel Commit 则进一步地让事务提交(commit)和Write Pipeline中的复制操作也并行起来。在理想情况,上述两类事务执行策略,可以让包含多条SQL的事务,在一次复制rt中快速完成。
LeaseHolder执行
当lease holder节点接收到从coordinator发来的请求,会先检查租约是否有效(来保证一致性读写),并尝试为操作中的key获取锁(保证事务内操作执行的串行)。为了避免出现不一致的情况,还需要检查本次操作所依赖的写操作是否已经完成复制;接着,如果此次写操作与其他事务的读操作产生了冲突,则需要拉高本次事务的时间戳。
完成上述准备工作后,lease holder节点进行evaluation,把KV操作转换成更底层的command序列。注意在这一阶段,CockroachDB会利用并发控制机制,来处理事务间的冲突,保证事务的隔离性。我们将在下文中讲述。

Write Pipeline
对于上层结构传来的一条普通KV操作请求(非commit操作),只要它不和之前未完成复制的请求产生依赖关系,就有机会利用Write Pipeline 机制来实现流水线式的写入。 因此,Cockroach事务中需要检查每条KV请求与更早的、未完成复制的写操作(我们称为in-flight操作)是否在key上有重合,即存在依赖关系。如果检查出有依赖关系,则流水线需要暂停,本次操作需要等待其依赖的in-flight操作完成复制。这一流水线中断的现象称为“pipeline stall”。
在完成依赖检查后,transacntion coordinator 就可以将操作发送给上文提到的 lease holder节点来执行。关于lease holder节点的执行,我们将在下文详述。一旦lease holder节点执行完成,就会返回一个包含时间戳的response。 如果时间戳比事务开始时的时间戳要大,说明有其他事务的读操作对本次事务操作产生了影响(一般是因为产生了Read-Write冲突)。此时需要对本次事务内已经完成的读操作,在新的时间戳下逐个检查。如果读操作的结果与旧时间戳下有差异,则事务失败;否则事务可以正常继续执行。
我们可以用下图的形式来描述Write Pipeline优化的效果。在优化前,每次写操作需要同步等待两个follower节点完成复制;优化后,如果写操作间不存在依赖关系(pipeline stall现象),则仅需在commit时同步等待事务内所有复制完成,而不需要为每个写操作进行等待。绿色部分显示了write pipeline对于整个事务的优化效果。
Parallel Commit
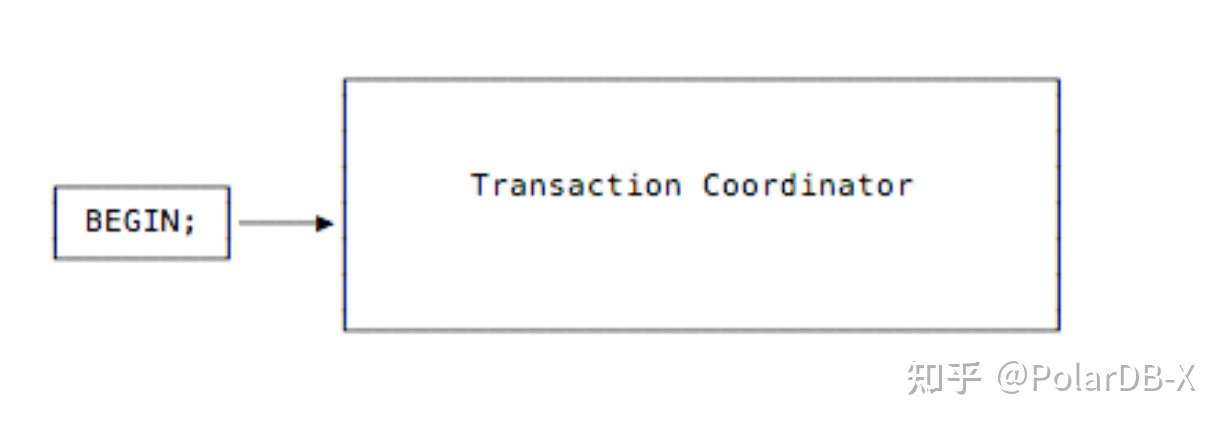
当上层传来的操作是一条事务commit请求,则会利用parallel commit 机制来处理。直观来说,当事务内所有写操作已经完成了复制,事务的commit 才能开始执行。这种执行模式一般花费至少两轮复制rt的时间。 而在parallel commit机制下,事务利用记录staging状态信息来避免多等待一个复制rt时间。我们用一个例子来解释这一过程:
- 当客户端发起一个事务,一个Transaction Coordinator实例被创建出来用于管理事务过程。
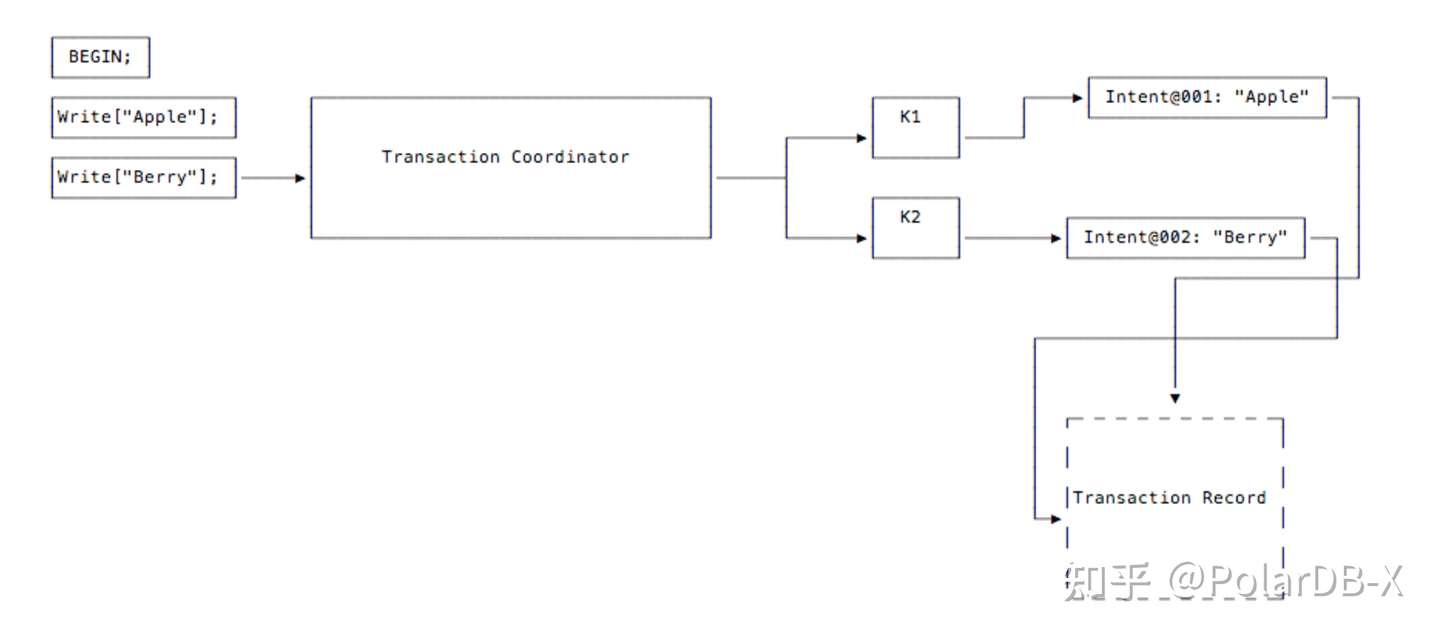
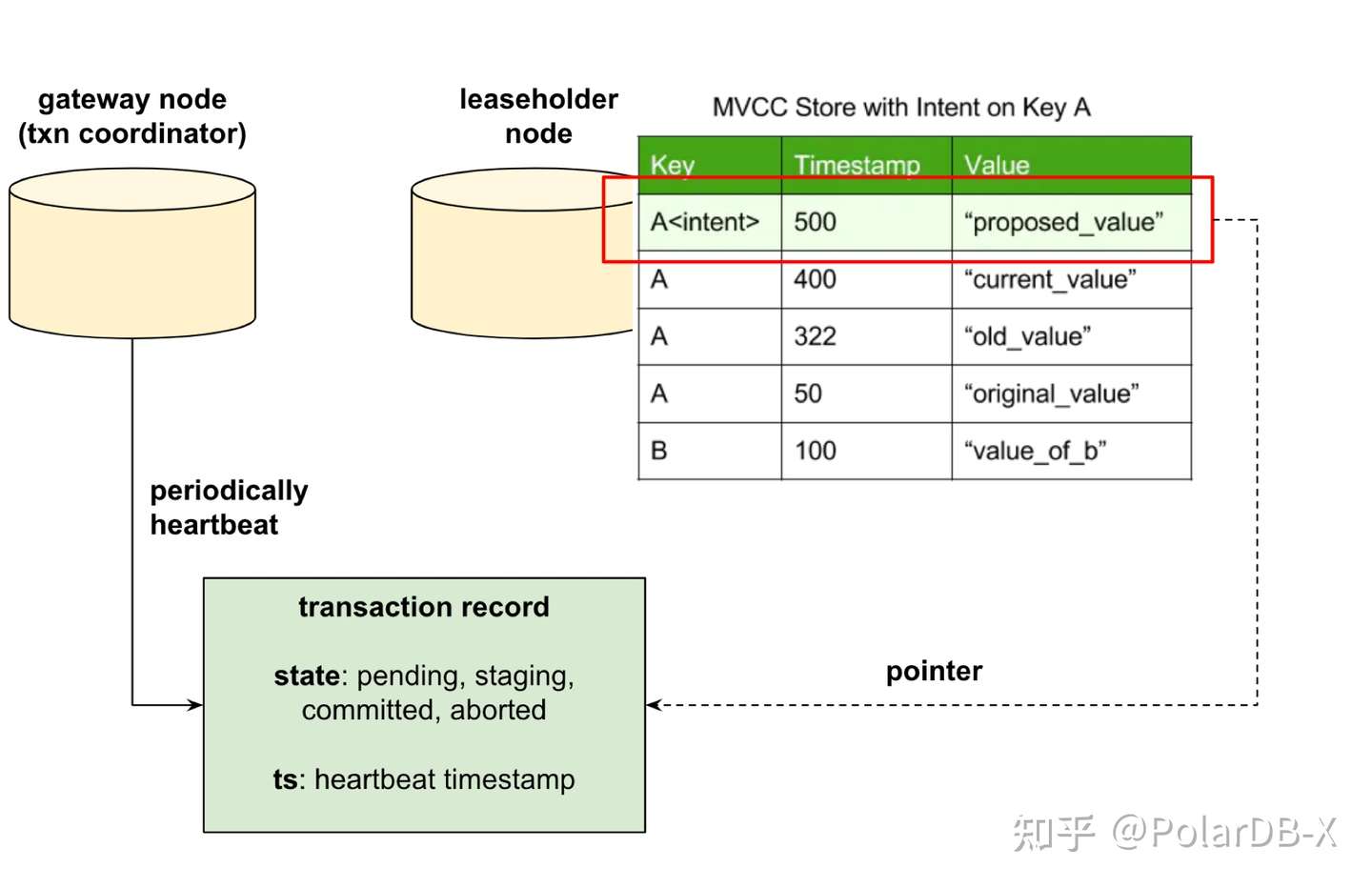
- 客户端分别在事务内写入了"Apple" 和 "Berry" 两条Key。由于事务还未提交,CockroachDB暂时以write intent的形式来保存写入的记录。与普通的key-value记录相比,write intent 维护一个指向Transaction record的指针(此时还是空指针,尚未初始化)。Transaction record 是系统表中的一条记录,用于维护事务的状态。
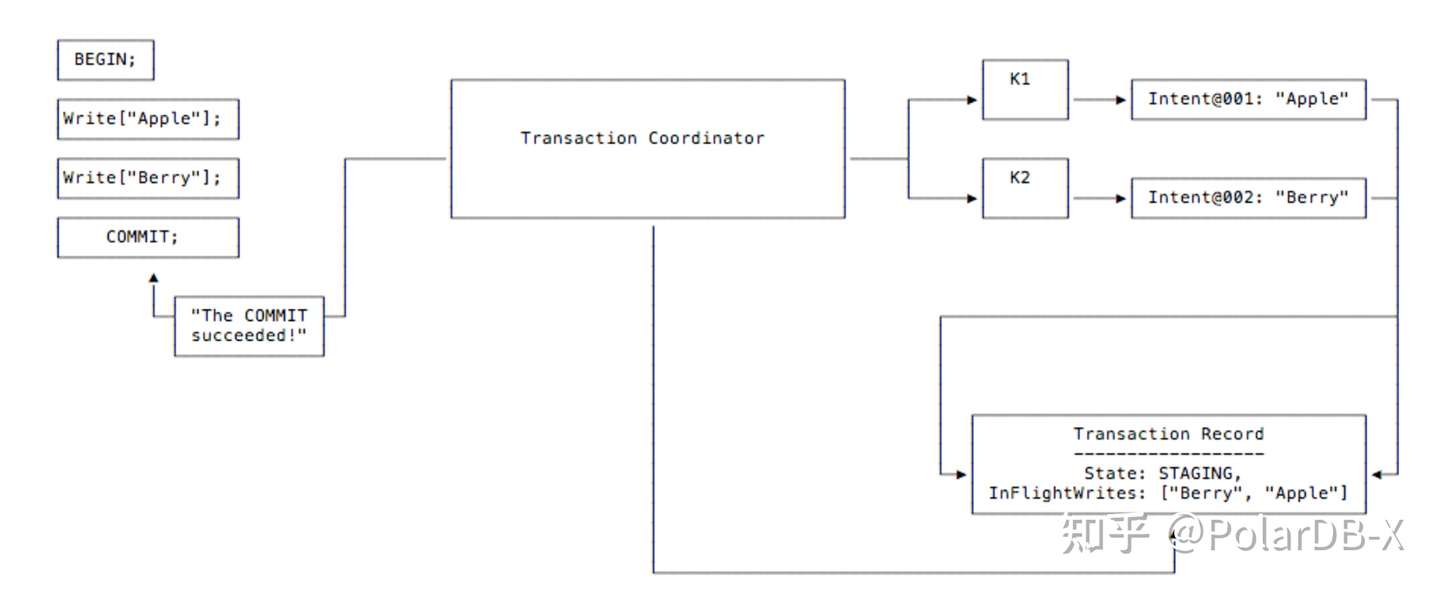
- 当客户端发出commit请求,coordinator会正式创建出Transaction Record,并将事务状态记录为Staging。同时,由于Write Pipeline机制的存在,此时尚未完成复制的写操作(in-flight操作)也会被记录到Transaction Record中。
Transaction Record 写入本身也是一次写操作,在Write Pipeline机制下,同样会不等复制完成就返回。接着,commit操作会等待所有的写操作的复制(包括所有in-flight写,和transaction record写)全部完成。理想情况下,等待时间是在一个复制rt时间范围内的。之后,coordinator立即响应客户端显示提交成功。
综上,parallel commit将整个事务的理想执行时间,压缩到了一个写复制rt时间内,对CockroackDB 事务吞吐带来了极大的提升:
原子性与并发控制
Atomicity
CockroachDB通过维护write intent和Transaction record来保证事务的原子性。关于这两者的定义,上文中已有介绍。Transaction Record保存在System Range中,能够表示当前事务的不同状态,包括pending, staging, committed和aborted,并确保write intent的可见性能够被原子性地改变。在长事务中,coordinator节点还会利用心跳包来维护处于pending阶段的transaction record。
当事务执行过程中遇到另一个事务写入的write intent时,就会触发一个intent resolving流程,读取并解析transaction record中的信息,并根据这些信息使用不同的策略来进行事务处理: committed:当write intent所属事务处于committed状态,本事务将此记录视为一个合法的常规记录,并帮助删除write intent中的指针,将其恢复为一个普通记录;
aborted: 当write intent所属事务处于aborted状态,本事务将此记录视为一个非法记录,并进行cleanup流程(清理事务记录和write intent)。
pending:当write intent所属事务处于pending状态,则可能有两类情况。首先最常见的,是该write intent所处事务尚未完成,此时需要阻塞并等待其执行完成;或者是通过检查transaction record上的心跳时间是否超时,来判断事务是否处于失效状态(例如coordinator节点异常崩溃)。如果已经失效,则进入abort流程。
staging:当write intent所属事务处于staging状态,说明事务已经进入提交流程。此时需要检查该事务所有写操作是否已经完成复制。如果是,则直接当做committed状态来处理。
Concurrency Control
在事务发生冲突时,CockroachDB基于对时间戳的顺序判断与调整,来进行并发控制。在这一过程中,应当始终保证已发生的读取操作,在时间戳发生调整后,依然是最新的、合法的。
Write-Read Conflict: 如果事务内在未完成提交的 write-intent上发生了读取,我们称之为 写读冲突。如果时间戳 T_write < T_read ,此时需要等待write-intent完成正常的事务提交流程。如果 T_write > T_read ,则读操作直接忽略write-intent内容,读取快照中的数据即可。
Read-Write Conflict:如果在一条key上有两个事务a和b分别进行了写和读操作,且时间戳关系为
T_a <= T_b ,此时CockroachDB会强制提升 T_a 的大小,使得 T_a > T_b 。
Write-Write Conflict:当一个事务的写操作,作用于另一个时间戳更小的write-intent上时,需要等待write-intent完成提交流程;而如果key上已经有更大时间戳的事务完成了提交,则写事务需要对时间戳进行Push.
文章来源:阿里云数据库
