




上一篇文章RocketMQ架构设计之启动过程解析 分析了 NameServer
, Broker
, Producer
, Consumer
四个部分的启动过程, 这边文章我们分析 消息的收发过程.
生产者发送消息过程解析
我们还是看上篇文章中的例子:
// 使用GroupName初始化Producer
DefaultMQProducer producer = new DefaultMQProducer("please_rename_unique_group_name");
// 指定NameSrv的地址: 也可以通过环境变量NAMESRV_ADDR来指定,则不需要下面这一行。
producer.setNamesrvAddr("name-server1-ip:9876;name-server2-ip:9876");
// 启动实例
producer.start();
try {
// 创建消息实例,指定 topic, tag, message body.
Message msg = new Message("TopicTest" /* Topic */,
"TagA" /* Tag */,
("Hello RocketMQ !!").getBytes(RemotingHelper.DEFAULT_CHARSET) /* Message body */
);
// 发送消息给Broker
SendResult sendResult = producer.send(msg);
System.out.printf("%s%n", sendResult);
} catch (Exception e) {
e.printStackTrace();
Thread.sleep(1000);
}
// 关闭生产者
producer.shutdown();
在上一篇文中,我们是看到了 producer.start();
, 现在我们接着来看 producer.send(msg);
的过程。上一篇文章中,有简单的介绍过消息的发送分为三步:
获取 topic
的元数据信息,包括:路由信息,是否为有序队列,MessageQueue
列表,消息会发送的队列的索引。选择 MessageQueue发送消息
具体实现的代码在 org.apache.rocketmq.client.impl.producer.DefaultMQProducerImpl#sendDefaultImpl
方法中。
在消息的发送过程中,首先会校验当前Producer
的运行状态,然后判断消息的group
,topic
等等是否为空。合法之后,会获取topic
的MessageQueue
列表。从messageQueue
列表中查找出一个发送的messageQueue
. 通过什么的机制选取MessageQueue
呢?这里会涉及到一个 Broker
的延迟容错机制,下面我们会详解的介绍这个机制。当消息第一次过来的时候,会通过Random
随机选择一个messageQueue
,进行发送,如果发送失败,会将该messageQueue
隔离起来,重试的时候,不会给这个 messageQueue
投递消息。选择出来了MessageQueue
之后,进行发送消息,发送消息首先会根据BrokerName
获取broker
的地址,执行几个 RpcHook
, 然后封装请求头,根据我们发送方式的不同,会选择对应的请求命令(Send_Message
,Send_Reply_Message
,Send_Reply_Message_V2
等等)发送,消息发送完成之后,会更新Producer
端的 broker容错表
。这样消息就发送出去了。
延迟容错机制
RocketMQ
发送消息的时候,由于 nameServer
检测 Broker
是否存活是有延迟的,在 选择消息队列的时候,也可能遇到宕机的Broker
, 因网络问题发送失败的不时会发生,因次 RocketMQ
实现这种 高可用的设计方案。
到底是怎么回事儿呢?
我们从代码中看看端倪。
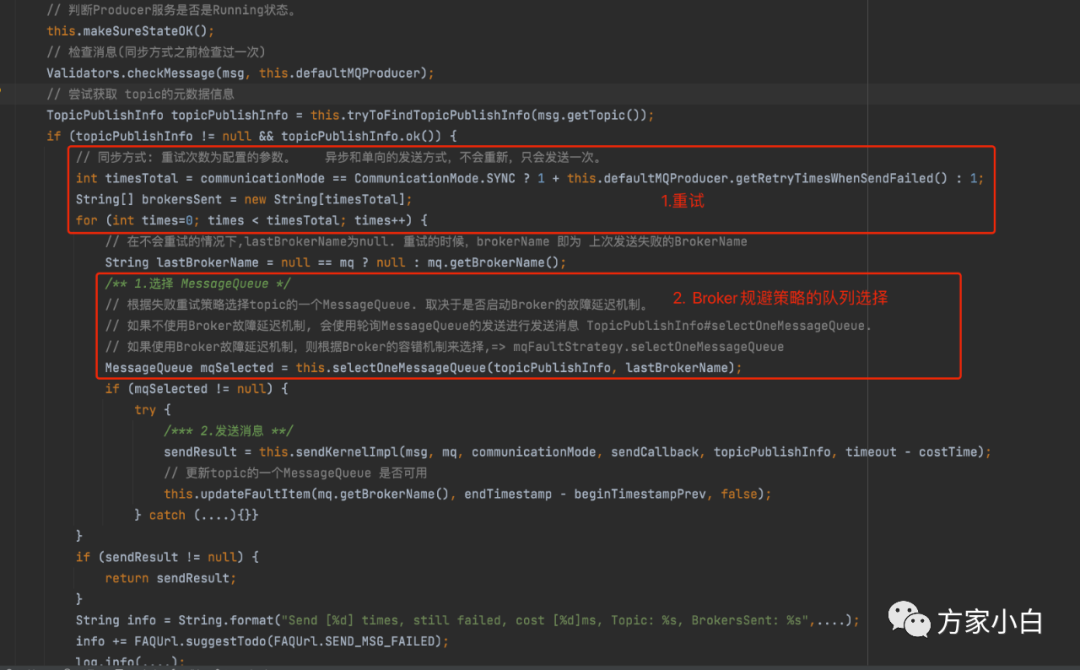
文中图片我标注了两处代码
重试
当消息是 同步方式发送的时候, 根据配置的属性进行重试,默认为3次。如果是单向方式或者异步的方式进行发送时,则就会发送一次,不会重试。可以看到确实可以从一定程度上提高消息发送成功的几率,但是,如果是broker
宕机,重试只会增加时长。
先不急着解决,我们看一下消息第一次发送是怎样的过程。图中2处,会根据 topicPublishInfo
取出一个MessageQueue
。跟进代码:

然后接着进入代码
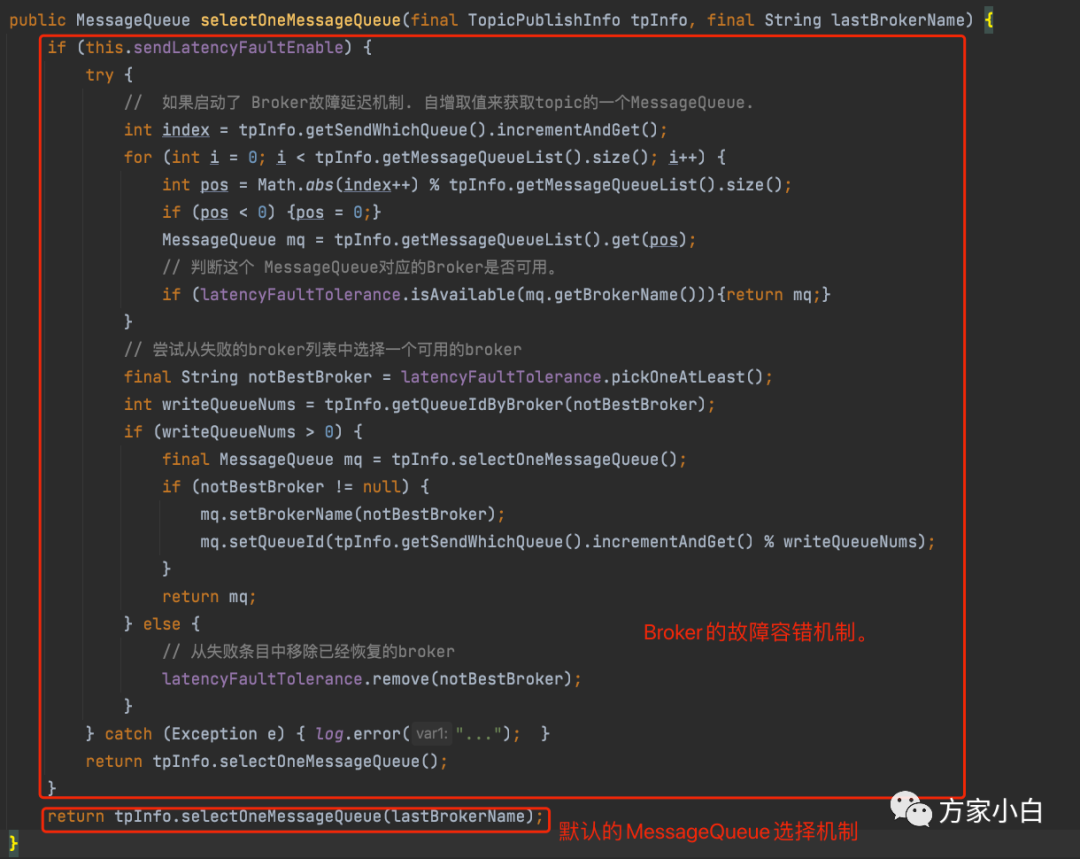
我们先假设 sendLatencyFaultEnable = false
. 我们再看一下具体实现:
其中 sendWhichQueue
字段就是上一次消息发送的MessageQueue List
的下标。
最后就是根据 selectOneMessage()
方法通过轮询的方式来选MessageQueue
了。第一次是通过随机的方式来选出第一个 MessageQueue
的,重试的都是 轮询的去取了。
那当: sendLatencyFaultEnable = true
的时候呢?
sendLatencyFaultEnable
是什么意思呢?它表示是否启用 Broker
故障延迟机制。看下图中的代码,我们假设 启用了 Broker
故障延迟机制。

图中标注的部分上面的逻辑 和刚才 选择MessageQueue的
机制是一样的。那奥秘肯定是在下面的代码中了(图中框选的部分)
latencyFaultTolerance
是什么呢? latencyFaultTolerance
是一个接口,直译就是:延迟容错。
/**
* 延迟容错
*
* @param <T>
*/
public interface LatencyFaultTolerance<T> {
/**
* 更新失败的Broker。
*
* @param name brokerName
* @param currentLatency 本次消息发送的时长
* @param notAvailableDuration 规避broker的时长
*/
void updateFaultItem(final T name, final long currentLatency, final long notAvailableDuration);
/**
* 判断Broker是否可以用
*
* @param name broker的名称
* @return
*/
boolean isAvailable(final T name);
/**
* 从Broker故障列表中移除
* @param name
*/
void remove(final T name);
/**
* 弹出最后一个 Broker
* @return
*/
T pickOneAtLeast();
}
我们来看一下 latencyFaultTolerance.isAvailable(mq.getBrokerName())
的实现
@Override
public boolean isAvailable(final String name) {
// faultItemTable 是一个 ConcurrentHashMap
final FaultItem faultItem = this.faultItemTable.get(name);
if (faultItem != null) {
// 判断该Broker(messageQueue)是否在规避时间内。
return faultItem.isAvailable();
}
return true;
}
faultItem.isAvailable()
的实现如下所示:
public boolean isAvailable() {
return (System.currentTimeMillis() - startTimestamp) >= 0;
}
从这两段代码中可以看出,判断 Broker
是否可用的判断依据就是:当前时间是否大于 startTimeStamp
。startTimeStamp
标识 该Broker
可以开始使用的时间。
看到这里,一头雾水。 分区容错到底是什么东西呢?
我们返回上一层,从框选的下面接着看:
如果还没有选出一个可用 MessageQueue
,则会中 故障的Broker
列表中选出一个Broker
,判断这个broker是否有MessageQueue
,如果有则随机(轮询)的选一个,如果没有则从故障的Broker
列表中移除一个,使用默认的机制选择一个MessageQueue
投送消息。
选择出来MessageQueue
之后,就会发送消息了。
发送完消息 还进行了一个操作
// 更新topic的一个MessageQueue 是否可用
this.updateFaultItem(mq.getBrokerName(), endTimestamp - beginTimestampPrev, false);
这是干什么呢?我们直译过来 更新故障(错误)的条目。去看一下代码实现:
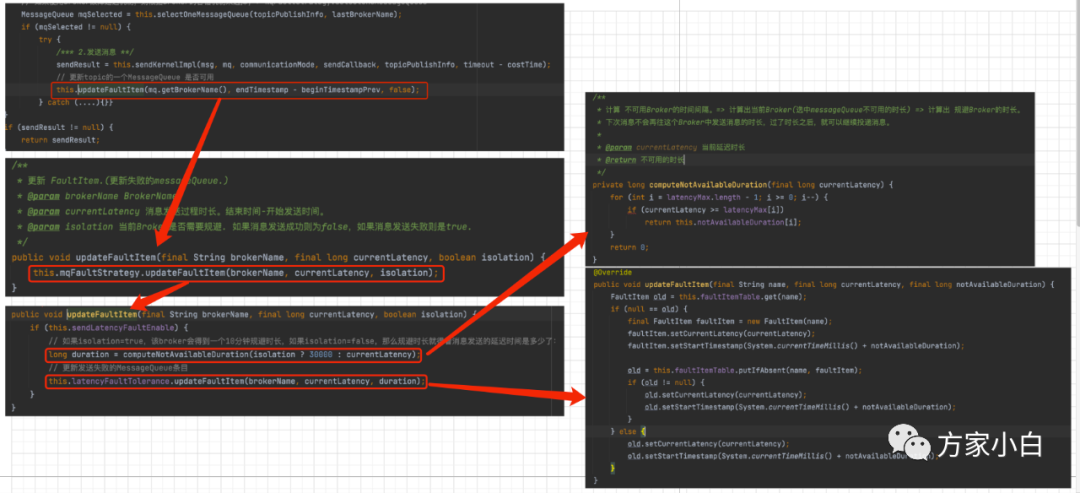
可以看到最终是调用了 MqFaultStrategty
的 updateFaultItem()
方法。这个方法中执行了两个方法,computeNotAvailableDuration
计算不可用的时长, 和 latencyFaultTolerance
的updateFaultItem
方法。
上图中贴出了 computeNotAvailableDuration
方法的实现。方法中使用了两个数组 latencyMax
和 notAvailableDuration
,这两个数组就是延迟机制的核心了. 数组的定义如下:
/**
* 延迟机制 - 本次消息发送时长区间,用于映射计算出需要规避Broker的时长。
*/
private long[] latencyMax = {50L, 100L, 550L, 1000L, 2000L, 3000L, 15000L};
/**
* 延迟机制 - 规避Broker的时长
*/
private long[] notAvailableDuration = {0L, 0L, 30000L, 60000L, 120000L, 180000L, 600000L};
方法中的形参 currentlatency
为本次消息发送的延迟时间。
调用computeNotAvailableDuration
方法的实参 isolation
表示该Broker
是否需要规避。如果消息发送成功,isolation
就是false
, 反之,就是代表Broker
需要被规避。从 computeNotAvailableDuration
方法的实现可以看出: 其会根据 本校消息发送的延迟时间 从 latencyMax
数组尾部找到第一个 比 currentlatency
小的数组下标i
,没有则返回0
, 将 notAvailableDuration[i]
进行返回。当isolation=true
的时候,就会默认有10
分钟的规避时长,反之,规避时长就会消息发送的延时是多少了。
我们接着看 latencyFaultTolerance
的updateFaultItem
方法

图中对代码进行注释,不过多解释了。其中 FaultItem
是 存储故障broker
的类,可以称为 失败条目,每个FaultItem
存储了broker
的名称,消息发送延迟的时长,故障规避结束的开始时间。
那么更新这两个字段的值有什么作用呢? 不知你是否有印象,刚才说有一头雾水的地方。
在选择MessageQueue
的时候,会判断messageQueue
是否可用,调用了 故障容器接口的 isAvalilable
方法,方法就是根据 startTimestamp
来进行判断改队列是否可用的。
public boolean isAvailable() {
return (System.currentTimeMillis() - startTimestamp) >= 0;
}
如果当前的系统时间大于故障规避开始时间,说明broker
可以加入轮询的队伍里。
以上就是 生产者发送消息 整个过程了。
生产者总结
我们知道了 生产者发送消息,三步完成,1.获取topic
的元数据信息,比如路由信息,MessageQueue
队列列表等, 2.选择合适的MessageQueue
,我们也着重介绍了 Broker
的故障延迟机制,这也是RocketMQ
实现高可用的方式之一。3.发送消息,这里我们并没有过多的介绍,使用nettyClient
将 Message
发送过 Broker
端。
Broker 存储消息
上面我们分析了生产者发送消息的整体过程,尤其着重的分析了 生产者选择MessageQueue
时候的容错机制。生产者会把消息发送给Broker
,进行存储,存储是一个怎样的流程呢?
我直接进入主题,从 SendMessageProcessor
说起。
为什么上来就说 这个类呢? 上篇文章中,我们分析了Broker
的启动过程中,可以知道的 Broker
启动了NettyServer
等待生产者,消费者发送来请求。这个 SendMessageProcessor
就是Broker
接受生产者发送消息的处理器。
具体的代码在 org.apache.rocketmq.broker.BrokerController#registerProcessor
中。
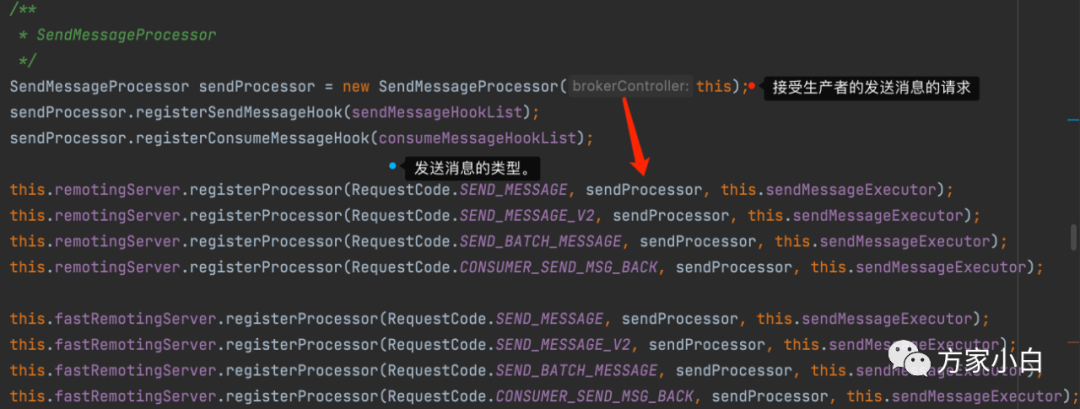
根据之前的内容,我们已知 发送的消息有 事务消息,批量消息,单条的普通消息三种类型,并且 RocketMQ
支持同步存储和异步存储两种方式。所以 肯定是Broker
端提供了这六种消息的存储方式。
实际上,也确实支持了这6种方式。我们先从 SendMessageProcessor
的类继承关系来看一下 Broker
是如何进行消息存储,我也会按照这样的思路来行文。
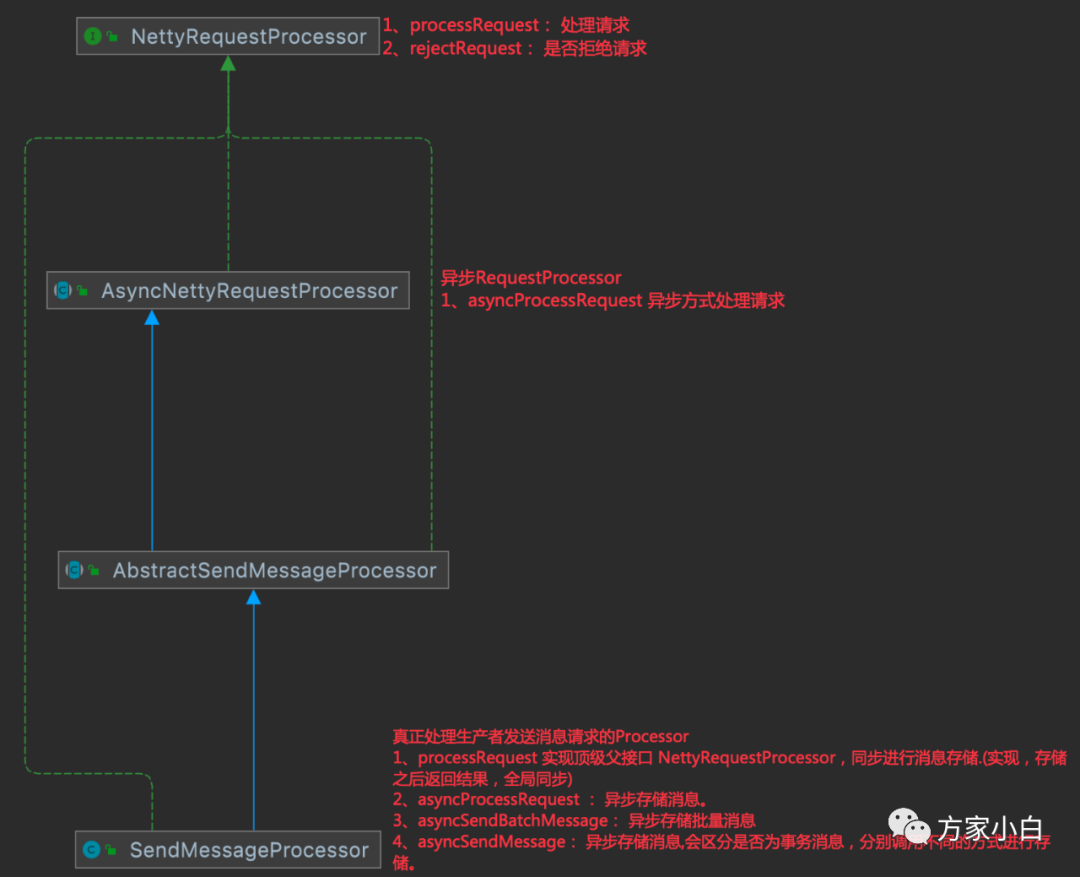
接收同步消息
同步消息处理的本质上还是异步的处理方式。
response = asyncProcessRequest(ctx, request).get();
接着往下看
异步消息处理
public CompletableFuture<RemotingCommand> asyncProcessRequest(ChannelHandlerContext ctx,
RemotingCommand request) throws RemotingCommandException {
final SendMessageContext mqtraceContext;
switch (request.getCode()) {
// 消费者发送回来的消息(可能是消费失败之后的?)
case RequestCode.CONSUMER_SEND_MSG_BACK:
return this.asyncConsumerSendMsgBack(ctx, request);
default:
// 处理生产者发送来的消息
SendMessageRequestHeader requestHeader = parseRequestHeader(request);
if (requestHeader == null) {
return CompletableFuture.completedFuture(null);
}
mqtraceContext = buildMsgContext(ctx, requestHeader);
// 消息发送前的钩子。在消息发送之前,执行一些操作。
this.executeSendMessageHookBefore(ctx, request, mqtraceContext);
if (requestHeader.isBatch()) {
// 如果是批量消息
return this.asyncSendBatchMessage(ctx, request, mqtraceContext, requestHeader);
} else {
// 不是批量消息
return this.asyncSendMessage(ctx, request, mqtraceContext, requestHeader);
}
}
}
可以看到,Broker
不仅处理来自 生产者发送来的消息,还需要处理 消费者 消费失败重试的消息。消费者重试的消息这部分比较复杂,我们后面再分析。我们先看处理生产者发送来的消息这部分。
代码中显示,会判断消息的类型,是否是批量消息,分别调用不同的方法,进行存储。如下图。
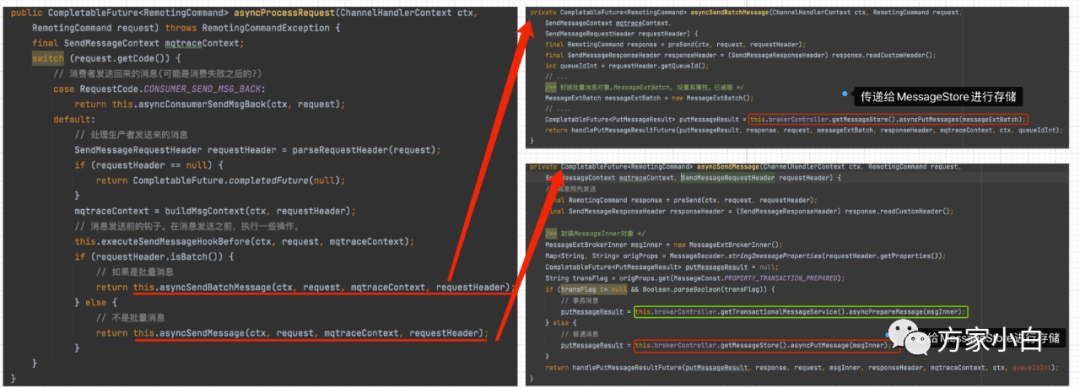
上图中不是完整的代码,我删除了一些不重要的代码,可以看出来,不管是批量消息还是单条消息(除事务消息)都是交给了 MessageStore
进行存储的。当然,事务消息是交给了 TransactionalMessageService
进行存储的,这个内容我们在分析RocketMQ
事务消息的时候,会着重的分析,本文中就不做分析了。
继续跟进代码
MessageStore
只是对消息 和 Broker
进行了简单的校验,并没有真正的去存储消息。而是把消息交给了 commitLog
进行存储消息。
我们以单条消息为例,来看一下 commitLog
将消息存储到文件中的具体流程。

如上图中, commitLog
收到消息,首先会选择一个MappedFile
, 这个 MappedFile
代表 磁盘上的物理文件在内容中的映射。指代 $HOME/store/commitlog
目录下的文件。也代表了消息要写入的文件。MappedFile
会把消息写到缓冲区中(即右上图), 消息顺利写完之后,就触发刷盘动作,刷盘有两种方式:同步写盘和异步刷盘。同步写盘是指等待 FlushCommitLogService
把消息真正写到物理磁盘上,然后再返回。异步刷盘是指 唤醒 FlushCommitLogService
执行的线程,不等待其是否真正把消息写入了物理磁盘中。最后,会把消息同步到其他的副本服务中。
存储消息流程总结
Broker
收到生产者发送的消息,会由 SendMessageProcessor
进行接收,然后会根据消息的类型单条消息,批量消息,还是事务消息,分别进行不同的处理。当然也会区分异步存储还是同步的存储消息。方法实现上本质还是调用 异步的方法来实现的,SendMessageProcessor
会把消息转交给 CommitLog
进行校验,会检查当前Broker
和当前消息的状态,然后交给MappedFile
真正的存储消息,MappedFile
表示存储消息的物理文件在内存中的映射,首先会把消息的内容写到缓冲区中,然后调用刷盘的方式(同步写盘或者异步刷盘)将消息真正的写到物理磁盘上。然后,将消息同步给其他副本。
再探讨一点细节
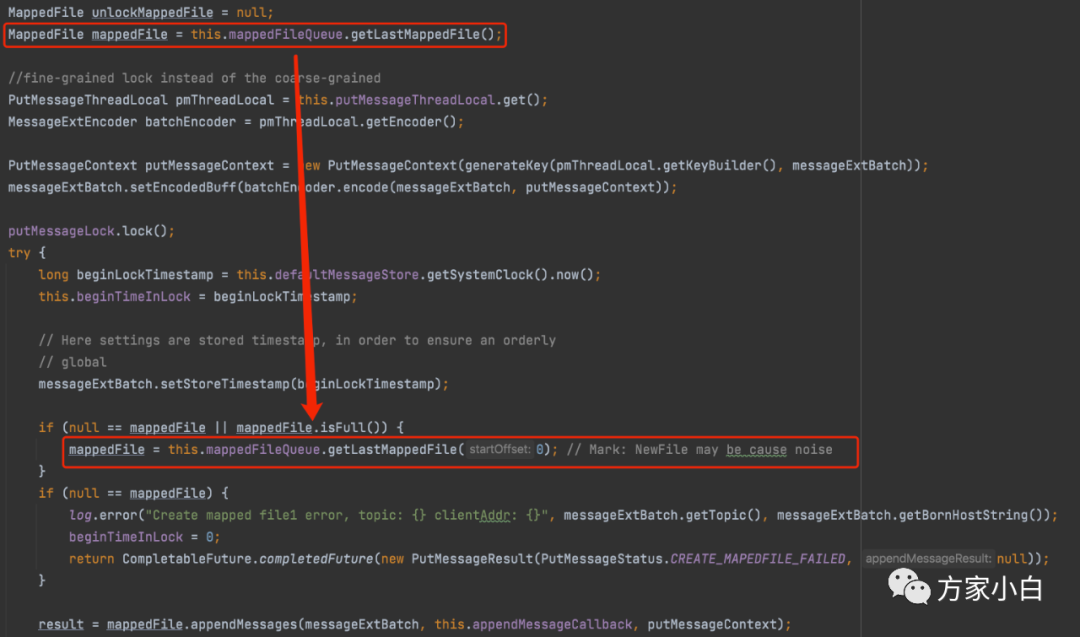
获取MappedFile
在Broker将消息写入 MappedFile 之前,就需要需要获取到一个MappedFile 进行写入。如何获取的呢?
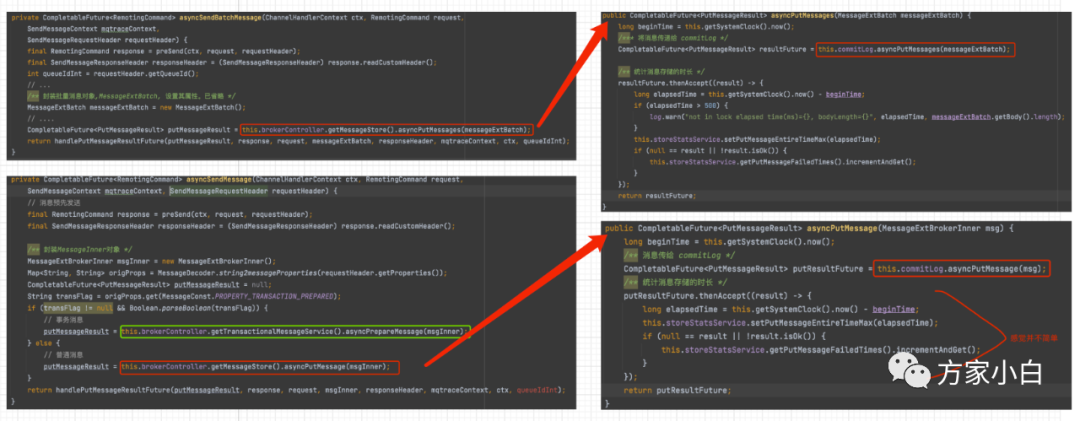
在 asyncPutMessages 方法中,有两处获取 MappedFile 的代码。
第一处代码,倒是没有复杂的逻辑
public MappedFile getLastMappedFile() {
MappedFile mappedFileLast = null;
while (!this.mappedFiles.isEmpty()) {
try {
mappedFileLast = this.mappedFiles.get(this.mappedFiles.size() - 1);
break;
} catch (IndexOutOfBoundsException e) {
//continue;
} catch (Exception e) {
log.error("getLastMappedFile has exception.", e);
break;
}
}
return mappedFileLast;
}
第二处代码,稍有猫腻。
public MappedFile getLastMappedFile(final long startOffset) {
return getLastMappedFile(startOffset, true);
}
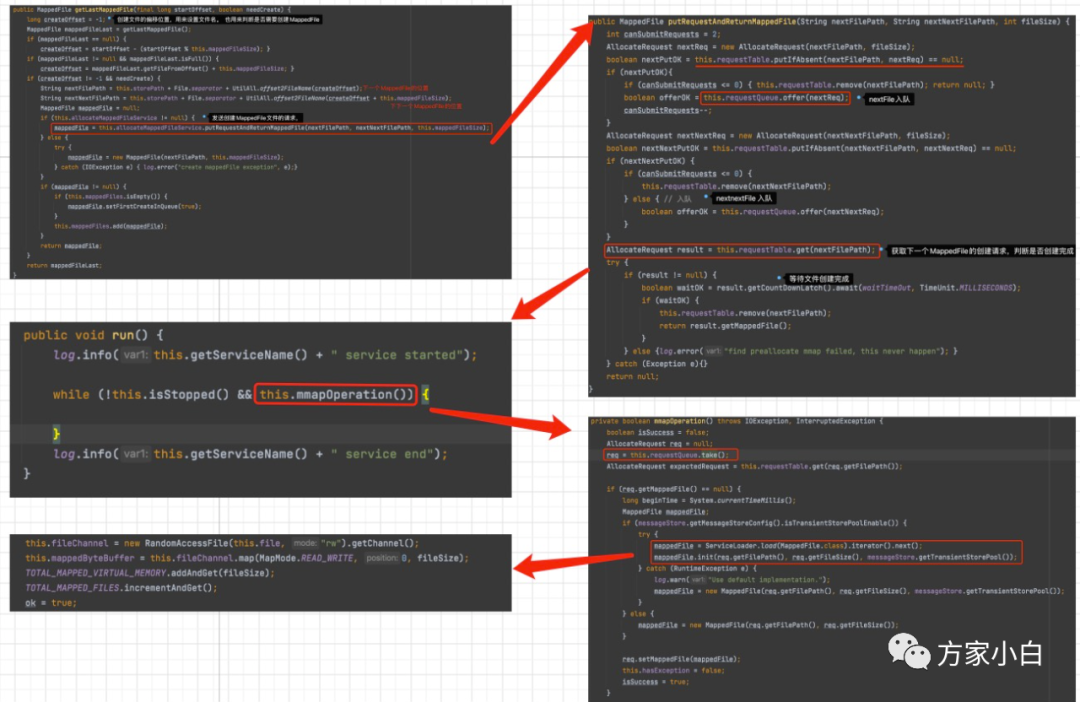
创建文件的代码和执行过程如上图所示,代码有删减。
解释一下猫腻: 创建 MappedFile
的时候,一次会创建两个MappedFile
, 这样下次就可以直接通过 一处的代码获取到 MappedFile
,而不用再去创建 MappedFile
了。由于 真实的创建MappedFile
是由 后台 AllocateMappedFileService
线程来创建的,所以也不会浪费时间。
代码显示,会把 AllocateRequest
分别放到 requestTable
和 requestQueue
中。AllocateRequest
是 创建 MappedFile
文件请求, requesetTable
是一个 concurrentHashMap
, key
是文件的路径,Value
是 AllocateRequest
。存储了 路径和AllocateRequest
的映射关系。requestQueue
,是请求的队列,PriorityBlockingQueue
,后台AllocateMappedFileService
线程会requestQueue
取出一个请求,分配的时候有两种策略,一种是使用Mmap
的方式来构建MappedFile
实例,另外一种是从TransientStorePool
堆外内存池中获取相应的DirectByteBuffer
来构建MappedFile
.
Consumer 消费消息
在上一篇文章中,我们介绍了 消费者有两种实现: DefaultLitePullConsumerImpl
和 DefaultMQPushConsumerImpl
. 我们先暂时抛开这两种具体的实现方式。从稍微高一点的角度来看一下消息者消费消息的逻辑。从 消费者注册, 负载均衡,拉取消息,消费消息 这个思路来行文。
消息者注册
消费者启动后,每隔10ms
会从 NameServer
查询一次用户订阅的所有话题路由信息.
/** 每10ms从NameServer拉取一下 TopicRouteInfo*/
this.scheduledExecutorService.scheduleAtFixedRate(new Runnable() {
@Override
public void run() {
try {
MQClientInstance.this.updateTopicRouteInfoFromNameServer();
} catch (Exception e) {
log.error("ScheduledTask updateTopicRouteInfoFromNameServer exception", e);
}
}
}, 10, this.clientConfig.getPollNameServerInterval(), TimeUnit.MILLISECONDS);
更新topic
路由信息在上篇文中已经介绍过了,这里就不详细的去介绍了,只是简单的串一下消息者消费消息的流程。
除此之外,还有一下操作:
每秒发送一次心跳检测. 每10s 持久化一次 Consumer
的offset
. 说到这类, 在启动的时候也会加载指定目录下的consumeOffset
.每分钟 扫描 consumerTable
自动调整线程池大小
消费者负载均衡
在消费者启动过程中,会启动 RebalenceService
. 看名字就知道这是一个负载均衡服务。什么作用呢? 在任何一个消费者 启动,关闭,重置消费偏移 的时候,都会触发这个这个服务的重平衡操作。
// 本机 启动时=>其他的消费者会受到 consumerIds发生变更的请求。
/** 5.启动负载均衡服务 org.apache.rocketmq.client.impl.factory.MQClientInstance#start*/
this.rebalanceService.start();
// 其他的消息者启动或者关闭时,即 consumerId 发生变动的时候 org.apache.rocketmq.client.impl.ClientRemotingProcessor#processRequest
case RequestCode.NOTIFY_CONSUMER_IDS_CHANGED:
return this.notifyConsumerIdsChanged(ctx, request);
// 控制端 重置消费偏移量时 org.apache.rocketmq.client.impl.ClientRemotingProcessor#processRequest
case RequestCode.RESET_CONSUMER_CLIENT_OFFSET:
return this.resetOffset(ctx, request);
重平衡操作发生了什么?
我们都知道 在Broker
端管理消息的最小单位是MessageQueue
,而不是 topic
。比如 当你发送了 10
条相同话题的消息,这 10
条话题可能存储在了不同 Broker
服务器的不同队列中。所以 当我们讨论消息队列负载均衡的时候,就是在讨论服务器端的所有队列如何给所有消费者消费的问题。在 RocketMQ
中,客户端有两种消费模式,一种是广播模式,另外一种是集群模式。
我们现在假设总共有两台 Broker
服务器,假设用户使用 Producer
已经发送了 8
条消息,这 8
条消息现在均衡的分布在两台 Broker 服务器的 8
个队列中,每个队列中有一个消息。现在有 3
台消费者都订阅了 Test
话题的消费者实例,我们来看在不同消费模式下,不同的消费者会收到哪几条消息。
广播模式
这种方式下,每台消费者都会收到8
条消息。所以,在广播的模式下,重平衡操作执行如下所示:
// 消费者的模式: 广播还是集群模式
switch (messageModel) {
// 广播方式。
case BROADCASTING: {
// topicSubscribeInfoTable: 存储topic 对应的 MessageQueue 列表.
Set<MessageQueue> mqSet = this.topicSubscribeInfoTable.get(topic);
if (mqSet != null) {
// 更新 消费者消费订阅表。返回是否发生了变动。
boolean changed = this.updateProcessQueueTableInRebalance(topic, mqSet, isOrder);
if (changed) {
// 如果发生了变动,则根据不同的消费消费方式处理:
// push,则需要通知给Broker,更新各个消费者的订阅关系。
// pull,则会通知消费者,执行消费逻辑。
this.messageQueueChanged(topic, mqSet, mqSet);
log.info("messageQueueChanged {} {} {} {}", consumerGroup, topic, mqSet, mqSet);
}
} else {
log.warn("doRebalance, {}, but the topic[{}] not exist.", consumerGroup, topic);
}
break;
}
case ....:
// 省略..
}
如上面代码中的注释, 主要注意的是,广播模式下,messageQueue
发生变动,需要根据不同的消费方式(pull
/push
),执行不同的逻辑。
push
方式:会更新消息消费订阅表的版本,然后会通知Broker
,触发consumerId
变动。pull
方式: 会重新pull
消息,执行pullTask
.
集群模式
集群模式是指所有的消息队列会按照某种分配策略来分给不同的消费者客户端。
集群方式,不就是多个消费者协同的消费一个topic
的数据吗,也就是说多个消费者协同的订阅topic
下的多个消息队列(MessageQueue
). 那就需要一种策略去分配多个MessageQueue
给每个消费者。
RocktMQ
提供了六种MessageQueue
的消费策略。
// 当前消费者 需要消费哪几个消息队列中消息的分配策略。
AllocateMessageQueueStrategy strategy = this.allocateMessageQueueStrategy;
List<MessageQueue> allocateResult = null;
try {
// mqAll:当前topic和group下的消费队列列表. cidAll: 所有消费队列的id.
// 两者一一对应。
allocateResult = strategy.allocate(this.consumerGroup, this.mQClientFactory.getClientId(),
mqAll, cidAll);
}catch(Throwable e){}
根据分配策略分配好自己要订阅的MessageQueue
之后,就会 更新消费者消费订阅表。然后需要根据不同的消费方式(pull
/push
),执行不同的逻辑。
push
方式:会更新消息消费订阅表的版本,然后会通知Broker
,触发consumerId
变动。pull
方式: 会重新pull
消息,执行pullTask
.
我们就一起看下 AllocateMessageQueueStrategy
的六种实现。
平均哈希队列算法(AllocateMessageQueueAveragely)
这种策略比较简单。举个例子来说明:
假设有5
个mq
, 3
个消费者,那么消费者id
为1
的C1
会订阅mq1,mq2
. C2=>mq3,mq4
. C3=>mq5
.
假设有5
个mq
, 6
个消费者,那么订阅关系则为: C1=>mq1
,C2=>mq2
,C3=>mq3
,C4=>mq4
,C5=>mq5
,C6=>[]
// cidAll: 消费者id列表
int index = cidAll.indexOf(currentCID);
// mqAll: 消息队列的列表
// mod: 表示 有多个队列无法平均分配。
int mod = mqAll.size() % cidAll.size();
// 4 <= 5 ? 1 : (4 > 0 && 1 < 4 ? 4 / 5 + 1 : 4 / 5)
int averageSize;
if (mqAll.size() <= cidAll.size()) {
// 队列比消费者少,每个消费者最大消费1个队列。
averageSize = 1;
} else {
if (mod > 0 && index < mod) {
// 不能平均分, 并且消费者的id比余数小。那么该消费者要多消费一个MessageQueue.
averageSize = mqAll.size() / cidAll.size() + 1;
} else {
// 正好平均分 或者 当前消费者的id大于mod, 那么该消费者就平均分.
// 会有两种情况: 1、mq有5个,consumer有5个, cid=5,则每个消费者都正好订阅一个mq
// 2、mq有5个,consumer有6个,cid=6, 则该消费者不会订阅mq
averageSize = mqAll.size() / cidAll.size();
}
}
// int averageSize =
// mqAll.size() <= cidAll.size() ? 1 : (mod > 0 && index < mod ? mqAll.size() / cidAll.size()
// + 1 : mqAll.size() / cidAll.size());
// 订阅mq 的起始 索引. 比如5个mq,3个consumer, 那么,c1=>m1,m2; c2=>m3,m4; c3=>m5
int startIndex = (mod > 0 && index < mod) ? index * averageSize : index * averageSize + mod;
int range = Math.min(averageSize, mqAll.size() - startIndex);
for (int i = 0; i < range; i++) {
result.add(mqAll.get((startIndex + i) % mqAll.size()));
}
return result;
循环平均哈希队列算法(AllocateMessageQueueAveragelyByCircle)
这种实现页是很简单的实现。举例来说明,不过多介绍了。
假设有5
个mq
, 3
个消费者,那么订阅关系则为:C1=>mq1,mq4
.C2=>mq2,mq5
.C3=>mq3
.
假设有5
个mq
, 6
个消费者,那么订阅关系则为: C1=>mq1
,C2=>mq2
,C3=>mq3
,C4=>mq4
,C5=>mq5
,C6=>[]
// index: 表示第index个消费者
int index = cidAll.indexOf(currentCID);
for (int i = index; i < mqAll.size(); i++) {
// 循环分配给消费者。
if (i % cidAll.size() == index) {
result.add(mqAll.get(i));
}
}
一致性哈希队列算法(AllocateMessageQueueConsistentHash)
这个算法实现起来比较复杂,涉及到了一个分布式算法,一致性哈希算法。
具体的算法实现内容可以参考: 哈希算法
// 哈希环的节点
Collection<ClientNode> cidNodes = new ArrayList<>();
for (String cid : cidAll) {
cidNodes.add(new ClientNode(cid));
}
// 创建一致性哈希的Router
final ConsistentHashRouter<ClientNode> router;
if (customHashFunction != null) {
router = new ConsistentHashRouter<>(cidNodes, virtualNodeCnt, customHashFunction);
} else {
router = new ConsistentHashRouter<>(cidNodes, virtualNodeCnt);
}
// 将MQf通过Router分配给消费者
List<MessageQueue> results = new ArrayList<>();
for (MessageQueue mq : mqAll) {
ClientNode clientNode = router.routeNode(mq.toString());
if (clientNode != null && currentCID.equals(clientNode.getKey())) {
results.add(mq);
}
}
return results;
这种算法的好处也特别明显: 当有消费者加入或者退出的时候,不会移动跨节点的MQ
分配情况。
通过配置的属性分配队列(AllocateMessageQueueByConfig)
这种算法就是 根据配置的MQ
,进行消费。
通过 set
方法设置该消费者要消费的MQ
,
public void setMessageQueueList(List<MessageQueue> messageQueueList) {
this.messageQueueList = messageQueueList;
}
分配方法则,直接将 messageQueueList
返回即可。
@Override
public List<MessageQueue> allocate(String consumerGroup, String currentCID, List<MessageQueue> mqAll,
List<String> cidAll) {
return this.messageQueueList;
}
机房Hash队列算法(AllocateMessageQueueByMachineRoom)
这个算法 和 循环平均哈希队列算法 是一样的。只不过是根据 brokerName
进行Hash
计算的。
举个例子来说:
假设5个mq
(fxb-test01@fxb.com
,fxb-test02@fxb.com
,fxb-test03@fxb.com
,fxb-test04@fxb.com
,fxb-test05@fxb.com
),3个消费者。则订阅关系如下:C1=>mq1,mq4
.C2=>mq2,mq5
.C3=>mq3
.
代码实现如下:
List<MessageQueue> premqAll = new ArrayList<MessageQueue>();
for (MessageQueue mq : mqAll) {
String[] temp = mq.getBrokerName().split("@");
if (temp.length == 2 && consumeridcs.contains(temp[0])) {
premqAll.add(mq);
}
}
int mod = premqAll.size() / cidAll.size();
int rem = premqAll.size() % cidAll.size();
int startIndex = mod * currentIndex;
int endIndex = startIndex + mod;
for (int i = startIndex; i < endIndex; i++) {
result.add(premqAll.get(i));
}
if (rem > currentIndex) {
result.add(premqAll.get(currentIndex + mod * cidAll.size()));
}
return result;
基于机房远近优先(AllocateMachineRoomNearby)
这种算法会根据消费者的命名来区分。比如相同机房的消费者有相同的命名格式:beijing-mxy-001
,beijing-mxy-002...
,那么这类的消费者和MQ
会被认为属于同一个机房。在同一个机房内的MQ
会优先被本机房的消费者进行消费 如果本机房内没有存活的消费者,那该机房中的MQ
会被所有的消费者所共享。 至于某一个消费者会订阅哪个MQ
,则由具体指定的分配策略来分配。具体如下代码。
// 根据机房分组 broker,
Map<String/*machine room */, List<MessageQueue>> mr2Mq = new TreeMap<String, List<MessageQueue>>();
for (MessageQueue mq : mqAll) {
String brokerMachineRoom = machineRoomResolver.brokerDeployIn(mq);
if (StringUtils.isNoneEmpty(brokerMachineRoom)) {
if (mr2Mq.get(brokerMachineRoom) == null) {
mr2Mq.put(brokerMachineRoom, new ArrayList<MessageQueue>());
}
mr2Mq.get(brokerMachineRoom).add(mq);
} else {
throw new IllegalArgumentException("Machine room is null for mq " + mq);
}
}
//根据机房分组consumer
Map<String/*machine room */, List<String/*clientId*/>> mr2c = new TreeMap<String, List<String>>();
for (String cid : cidAll) {
// 根据cid判断出所属的机房==> 相同机房的消费需要有相同的命名格式.
String consumerMachineRoom = machineRoomResolver.consumerDeployIn(cid);
if (StringUtils.isNoneEmpty(consumerMachineRoom)) {
if (mr2c.get(consumerMachineRoom) == null) {
mr2c.put(consumerMachineRoom, new ArrayList<String>());
}
mr2c.get(consumerMachineRoom).add(cid);
} else {
throw new IllegalArgumentException("Machine room is null for consumer id " + cid);
}
}
List<MessageQueue> allocateResults = new ArrayList<MessageQueue>();
// 计算当前consumer可以消费的MQ. 当前机房有多个消费者的时候,则使用真正分配策略(其他的分配策略)进行分配。
// 1.allocate the mq that deploy in the same machine room with the current consumer
String currentMachineRoom = machineRoomResolver.consumerDeployIn(currentCID);
List<MessageQueue> mqInThisMachineRoom = mr2Mq.remove(currentMachineRoom);
List<String> consumerInThisMachineRoom = mr2c.get(currentMachineRoom);
if (mqInThisMachineRoom != null && !mqInThisMachineRoom.isEmpty()) {
allocateResults.addAll(allocateMessageQueueStrategy.allocate(consumerGroup, currentCID, mqInThisMachineRoom, consumerInThisMachineRoom));
}
// 2.allocate the rest mq to each machine room if there are no consumer alive in that machine room
// 如果当前机房没有存活的消费者,那么当前机房的MQ会被所有的消费者共享。根据真实的分配策略进行分配
for (String machineRoom : mr2Mq.keySet()) {
if (!mr2c.containsKey(machineRoom)) { // no alive consumer in the corresponding machine room, so all consumers share these queues
allocateResults.addAll(allocateMessageQueueStrategy.allocate(consumerGroup, currentCID, mr2Mq.get(machineRoom), cidAll));
}
}
return allocateResults;
以上就是RocketMQ
使用的负载均衡的内容了,当然,我们也可以自定义 分配策略。只需要实现 AllocateMessageQueueStrategy
, 在创建消费者实例的时候使用就好了。
拉取消息
我们知道的是, RocketMQ支持两种消费者类型,一种是推送方式的,一种是主动拉取消息。
这里我们先从拉取消息说起。 你懂的,我们是要讲的是: DefaultLitePullConsumer
.
DefaultLitePullConsumer
DefaultLitePullConsumer
,会为每个 messageQueue
创建一个PullTaskImpl
. 它会定时的从 Broker
端拉取消息。然后封装成 PullRequest
, 放到 consumeRequestCache
这个阻塞队列中, 然 后 DefaultLitePullConsumer
会调用poll
方法,获取 List
是客户端 定时任务主动想Broker
端发送请求,拉取消息。
而 推的方式,就不是这么简单了。
DefaultMQPushConsumer
这还是要从Broker
端存储完消息之后说起,Broker会运行一个 ReputMessageService
. 这是一个线程,有什么作用呢?
它是推送消息的线程,负责将写入CommitLog
的消息推送给对应的消费者。
这里会有两个问题:
1、 ReputMessageService
怎么知道要去推送消息给消费者呢
ReputMessageService
每隔 1 秒会检查一下这个 CommitLog
是否有新的数据写入。ReputMessageService
自身维护了一个偏移量 reputFromOffset
,用以对比和 CommitLog
文件中的消息总偏移量的差距。当这两个偏移量不同的时候,就代表有新的消息到来了。
如下图:
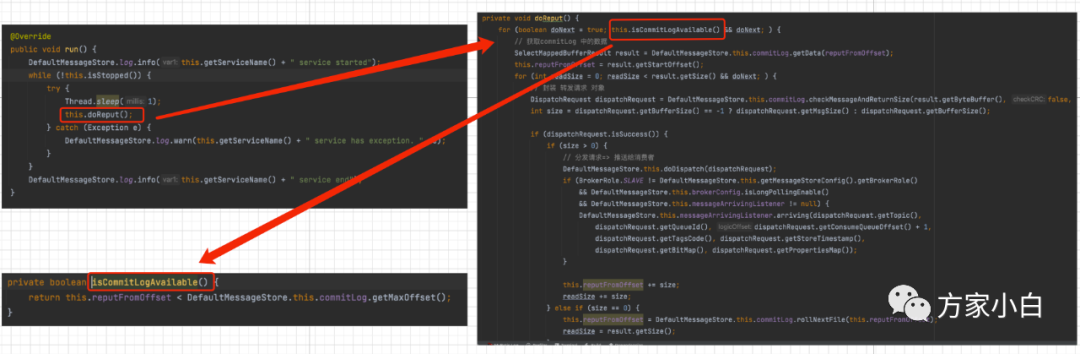
ReputMessageService
是怎样推送消息的
从上图中可以看见, ReputMessageService
封装了一个 DispatchRequest
,然后通过 DefaultMessageStore.doDispatch
方法,转发了出去。虽说是转发了出去,但是并非直接发送给了消费者。
而是转发给了 CommitLogDispatcherBuildConsumeQueue
. 它主要是根据这条请求按照不同的队列 ID
创建不同的消费队列文件,并在内存中维护一份消费队列列表。然后将 DispatchRequest
请求中这条消息的消息偏移量、消息大小以及消息在发送时候附带的标签的 Hash
值写入到相应的消费队列文件中去。
public void putMessagePositionInfo(DispatchRequest dispatchRequest) {
ConsumeQueue cq = this.findConsumeQueue(dispatchRequest.getTopic(), dispatchRequest.getQueueId());
cq.putMessagePositionInfoWrapper(dispatchRequest);
}
后台通过FlushConsumeQueueService
线程来定时的持久化到磁盘中,写文件和 Broker
写入MappedLogFile
一样。只是位置不同。
好家伙,到现在还没有给消息推送消息,自己先存起来了。
而事实上,RocketMQ 并没有实现 Broker端 发送消息给 消费者。推模型的消息消费模式,是通过拉模式实现的。
这里需要区分 广播模式 和 集群模型分开来说了。
广播模式
每个消费队列的偏移量肯定不能存储在 Broker
服务器端,因为多个消费者对于同一个队列的消费可能不一致,偏移量会互相覆盖掉。因此,在广播模式下,每个客户端的消费偏移量是存储在本地的,然后每隔 5
秒将内存中的 offsetTable
持久化到磁盘中。当首次从服务器获取可消费队列的时候,偏移量是直接从本地文件中读取的。
集群模式
在集群模式下,由于每个客户端所消费的消息队列不同,所以每个消息队列已经消费到哪里的消费偏移量是记录在 Broker
服务器端的。
消费者客户端在内存中维护了一个 offsetTable
表,在 Broker
服务器端也维护了一个偏移量表。在消费者客户端,RebalanceService
服务会定时地 (默认 20 秒) 从 Broker
服务器获取当前客户端所需要消费的消息队列,并与当前消费者客户端的消费队列进行对比,看是否有变化。对于每个消费队列,会从 Broker
服务器查询这个队列当前的消费偏移量。然后根据这几个消费队列,创建对应的拉取请求 PullRequest
准备从 Broker
服务器拉取消息。当从 Broker
服务器拉取下来消息以后,只有当用户成功消费的时候,才会更新本地的偏移量表。本地的偏移量表再通过定时服务每隔 5
秒同步到 Broker
服务器端,维护在 Broker
服务器端的偏移量表也会每隔 5
秒钟序列化到磁盘中.
那么重点来了,创建的PullRequest
就会被放到 pullRequestQueue
中。
拉取消息
在 消费者启动 一文中,可以知道 消费者启动后,后台会一直运行一个 PullMessageService
线程。它会阻塞的从 pullRequestQueue
中获取 PullRequest
向Broker
端发送请求。
@Override
public void run() {
while (!this.isStopped()) {
try {
// 出队
PullRequest pullRequest = this.pullRequestQueue.take();
// 拉取消息
this.pullMessage(pullRequest);
}
}
}
pullRequestQueue
便是 pull Message Request Queue
了。(拉取消息请求的队列了)
当真正尝试拉取消息之前,其会检查当前请求的内部缓存的消息数量、消息大小、消息阈值跨度是否超过了某个阈值,如果超过某个阈值,则推迟 50
毫秒重新执行这个请求,当执行完一些必要的检查之后,客户端会将用户指定的过滤信息以及一些其它必要消费字段封装到请求信息体中,然后才开始从 Broker
服务器拉取这个请求从当前偏移量开始的消息,默认一次性最多拉取 32
条,服务器返回的响应会告诉客户端这个队列下次开始拉取时的偏移量。客户端每次都会注册一个 PullCallback
回调,用以接受服务器返回的响应信息,根据响应信息的不同状态信息,然后修正这个请求的偏移量,并进行下次请求。
对了,都有些什么时候会将 PullRequest
放入 pullRequestQueue
中的呢?
重平衡的时候 有消费者加入,发生重平衡 定时任务,发送重平衡。 消息消费失败,重试。 启动的时候。
这些都是会触发拉取消息的。
最后,终于到最后一步了, 消费消息。
消费消息
当把消息放在 PullRequestQueue
这个阻塞队列中之后,后台线程会不断从这个阻塞队列中获取 PullRequest
. 如下图代码中所示。拿到了 PullRequest
则会提交了一个 ConsumeRequest
. 我想这又被你猜到了。哈哈。这里将 ConsumeRequest
submit
给了一个后台线程 consumeExecutor
。接着往下看吧。该线程会每分钟执行一次。进行消息消费。
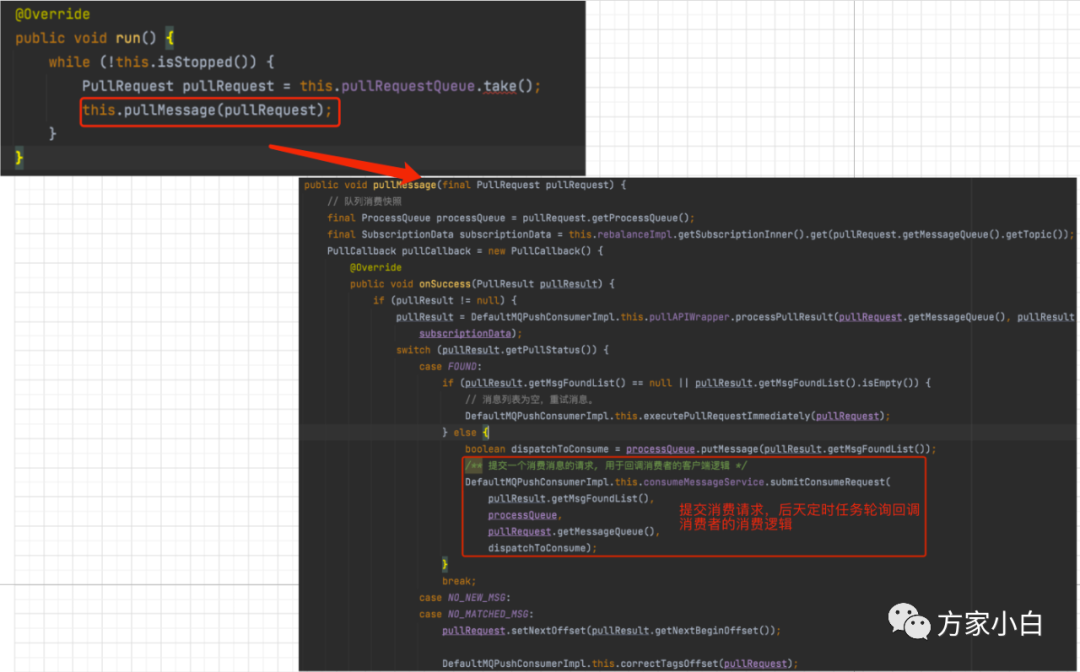
依赖于用户指定的消息回调函数的不同,消息的消费分为两种: 并发消费和有序消费。
并发消费没有考虑消息发送的顺序,客户端从服务器获取到消息就会直接回调给用户。而有序消费会考虑每个队列消息发送的顺序,注意此处并不是每个话题消息发送的顺序,一定要记住 RocketMQ
控制消息的最细粒度是消息队列。当我们讲有序消费的时候,就是在说对于某个话题的某个队列,发往这个队列的消息,客户端接受消息的顺序与发送的顺序完全一致。
并发消费
当用户注册消息回调类的时候,如果注册的是 MessageListenerConcurrently
回调类,那么就认为用户不关心消息的顺序问题。我们在上文提到过每个 PullRequest
都关联了一个处理队列 ProcessQueue
,而每个处理队列又都关联了一颗消息树 msgTreeMap
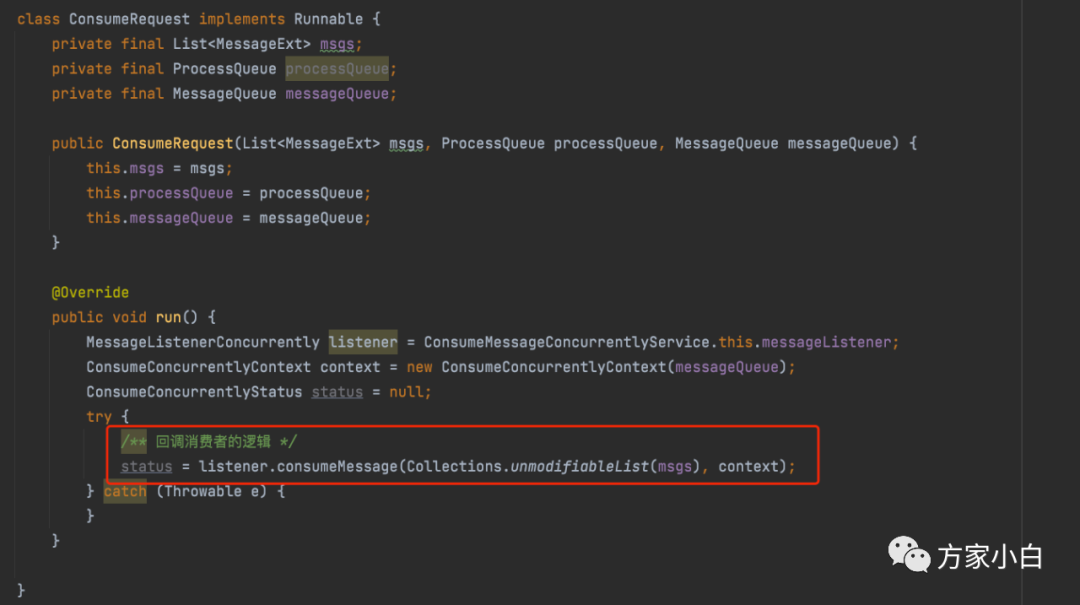
。当客户端拉取到新的消息以后,其先将消息放入到这个请求所关联的处理队列的消息树中,然后提交一个消息消费请求,用以回调用户端的代码消费消息.
提交给 consumeExecutor
之后, ConsumeRequest
实现逻辑如下:
有序消费
RocketMQ
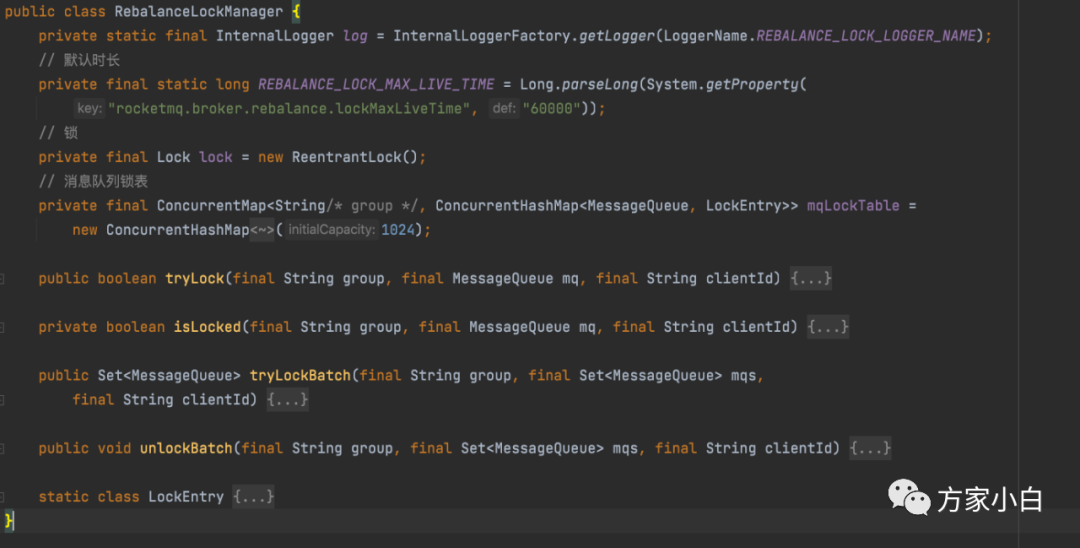
的有序消费主要依靠两把锁,一把是维护在 Broker
端,一把维护在消费者客户端。Broker
端有一个 RebalanceLockManager
服务,其内部维护了一个 mqLockTable
消息队列锁表:
在有序消费的时候,Broker
需要确保任何一个队列在任何时候都只有一个客户端在消费它,都在被一个客户端所锁定。当客户端在本地根据消息队列构建 PullRequest
之前,会与 Broker
沟通尝试锁定这个队列,另外当进行有序消费的时候,客户端也会周期性地 (默认是 20
秒) 锁定所有当前需要消费的消息队列.
代码逻辑如下
/**
* 顺序消费
* 每秒 定时多实例消费的所有队列,上锁成功将 ProcessQueue的lock属性设置为true
*/
@Override
public void start() {
if (MessageModel.CLUSTERING.equals(ConsumeMessageOrderlyService.this.defaultMQPushConsumerImpl.messageModel())) { /// 只支持集群模式
this.scheduledExecutorService.scheduleAtFixedRate(new Runnable() {
@Override
public void run() {
ConsumeMessageOrderlyService.this.lockMQPeriodically();
}
}, 1000 * 1, ProcessQueue.REBALANCE_LOCK_INTERVAL, TimeUnit.MILLISECONDS);
}
}
而在 Broker
这端,每个客户端所锁定的消息队列对应的锁项 LogEntry
有一个上次锁定时的时间戳,当超过锁的超时时间 (默认是 60 秒) 后,也会判定这个客户端已经不再持有这把锁,以让其他客户端能够有序消费这个队列。
在前面我们说到过 RebalanceService
均衡服务会定时地依据不同消费者数量分配消费队列。我们假设 Consumer-1
消费者客户端一开始需要消费 3
个消费队列,这个时候又加入了 Consumer-2
消费者客户端,并且分配到了 MessageQueue-2
消费队列。当 Consumer-1
内部的均衡服务检测到当前消费队列需要移除 MessageQueue-2
队列,这个时候,会首先解除 Broker
端的锁,确保新加入的 Consumer-2
消费者客户端能够成功锁住这个队列,以进行有序消费。
消费者客户端每一次拉取消息请求,如果有发现新的消息,那么都会将这些消息封装为 ConsumeRequest
来喂给消费线程池,等待消费。如果消息特别多,这样一个队列可能有多个消费请求正在等待客户端消费,用户可能会先消费偏移量大的消息,后消费偏移量小的消息。所以消费同一队列的时候,需要一把锁以消费请求顺序化。
代码如下:
public class ConsumeMessageOrderlyService implements ConsumeMessageService {
class ConsumeRequest implements Runnable {
private final ProcessQueue processQueue;
private final MessageQueue messageQueue;
public ConsumeRequest(ProcessQueue processQueue, MessageQueue messageQueue) {
this.processQueue = processQueue;
this.messageQueue = messageQueue;
}
public ProcessQueue getProcessQueue() {
return processQueue;
}
public MessageQueue getMessageQueue() {
return messageQueue;
}
@Override
public void run() {
final Object objLock = messageQueueLock.fetchLockObject(this.messageQueue);
synchronized (objLock) {
if (MessageModel.BROADCASTING.equals(ConsumeMessageOrderlyService.this.defaultMQPushConsumerImpl.messageModel())|| (this.processQueue.isLocked() && !this.processQueue.isLockExpired())) {
for (boolean continueConsume = true; continueConsume; ) {
// 每次获取消息的数量
final int consumeBatchSize =
ConsumeMessageOrderlyService.this.defaultMQPushConsumer.getConsumeMessageBatchMaxSize();
// 拿到可以消费的消息列表。默认为 1 条。
List<MessageExt> msgs = this.processQueue.takeMessages(consumeBatchSize);
defaultMQPushConsumerImpl.resetRetryAndNamespace(msgs, defaultMQPushConsumer.getConsumerGroup());
if (!msgs.isEmpty()) {
final ConsumeOrderlyContext context = new ConsumeOrderlyContext(this.messageQueue);
ConsumeOrderlyStatus status = null;
ConsumeMessageContext consumeMessageContext = null;
try {
// 消费者加锁
this.processQueue.getConsumeLock().lock();
// 回调消费者消息
status = messageListener.consumeMessage(Collections.unmodifiableList(msgs), context);
} catch (Throwable e) {
} finally {
this.processQueue.getConsumeLock().unlock();
}
continueConsume = ConsumeMessageOrderlyService.this.processConsumeResult(msgs, status, context, this);
} else {
continueConsume = false;
}
}
} else {
ConsumeMessageOrderlyService.this.tryLockLaterAndReconsume(this.messageQueue, this.processQueue, 100);
}
}
}
}
}
这样消息就消费完了。不得不说,这个消费的整体消费的逻辑是真的复杂。
总结
我们从生产者发送消息,到 Broker
端存储消息, 再到 消费者消费消息。将整个流程都跑通了。每个过程都不是我们想象的那样直接发送消息给Broker
,Broker
将消息直接写入硬盘, 消费者直接去Broker
中拉取消息,拉取到之后直接调用客户端进行消费。
接下来,我们会深入到 RocketMQ
某个特性的具体实现中去。会逐一分析 事务消息,延时消息,消息可靠性措施,载均衡,消息重放,消息过滤等功能的实现。
下一篇文章: 事务消息. 请期待~
最后
期望和你一起遇见更好的自己

