




goroutine
定义
“Goroutine
是一个与其他 goroutines
并行运行在同一地址空间的 Go
函数或方法。一个运行的程序由一个或更多个 goroutine
组成。它与线程、协程、进程等不同。它是一个 goroutine
” —— Rob PikeGoroutines
在同一个用户地址空间里并行独立执行 functions
, channels
则用于 goroutines
间的通信和同步访问控制。
goroutine VS thread
内存占用. 创建一个 goroutine
的栈内存消耗为2 KB
(Linux AMD64
Go v1.4
后),运行过程中,如果栈空间不够用,会自动进行扩容。创建一个thread
为了尽量避免极端情况下操作系统线程栈的溢出,默认会为其分配一个较大的栈内存(1 - 8 MB
栈内存,线程标准POSIX Thread
),而且还需要一个被称为“guard page”
的区域用于和其他thread
的栈空间进行隔离。而栈内存空间一旦创建和初始化完成之后其大小就不能再有变化,这决定了在某些特殊场景下系统线程栈还是有溢出的风险。创建/销毁,线程创建和销毀都会有巨大的消耗,是内核级的交互( trap
)。POSIX
线程(定义了创建和操纵线程的一套API
) 通常是在已有的进程模型中增加的逻辑扩展,所以线程控制和进程控制很相似。而进入内核调度所消耗的性能代价比较高,开销较大。goroutine
是用户态线程,是由go runtime
管理,创建和销毁的消耗非常小。调度切换 抛开陷入内核,线程切换会消耗 1000-1500
纳秒(上下文保存成本高,较多寄存器,公平性,复杂时间计算统计),一个纳秒平均可以执行12-18
条指令。所以由于线程切换,执行指令的条数会减少12000-18000
。goroutine
的切换约为200ns
(用户态、3个寄存器),相当于2400-3600
条指令。因此,goroutines
切换成本比threads
要小得多。复杂性 线程的创建和退出复杂,多个 thread
间通讯复杂(share memory
)。不能大量创建线程(参考早期的httpd
),成本高,使用网络多路复用,存在大量callback
(参考twemproxy
、nginx
的代码) 。对于应用服务线程门槛高,例如需要做第三方库隔离,需要考虑引入线程池等。
Goroutine
运行原理
Go
程序的执行由两层组成:Go Program
,Runtime
,即用户程序和运行时。它们之间通过函数调用来实现内存管理、channel
通信、goroutines
创建等功能。用户程序进行的系统调用都会被 Runtime
拦截,以此来帮助它进行调度以及垃圾回收相关的工作。
M:N
模型
Go runtime
会负责 goroutine
的生老病死,从创建到销毁,都一手包办。Runtime
会在程序启动的时候。Go
创建 M
个线程(CPU
执行调度的单元,内核的 task_struct
),之后创建的 N
个 goroutine
都会依附在这 M
个线程上执行,即 M:N
模型。它们能够同时运行,与线程类似,但相比之下非常轻量。因此,程序运行时,Goroutines
的个数应该是远大于线程的个数的(phread
是内核线程?)。
同一个时刻,一个线程只能跑一个 goroutine
。当 goroutine
发生阻塞 (chan
阻塞、mutex
、syscall
等等) 时,Go 会把当前的 goroutine
调度走,让其他 goroutine
来继续执行,而不是让线程阻塞休眠,尽可能多的分发任务出去,让 CPU
忙。
GM 调度模型
go
在1.2
版本之前,调度模型使用的是 GM
调度模型。
G
goroutine
的缩写,每次 go func()
都代表一个 G
,无限制。使用 struct runtime.g
,包含了当前 goroutine
的状态、堆栈、上下文。
M
工作线程(OS thread
)也被称为 Machine,使用 struct runtime.m
,所有 M
是有线程栈的。如果不对该线程栈提供内存的话,系统会给该线程栈提供内存(不同操作系统提供的线程栈大小不同)
。当指定了线程栈,则 M.stack→G.stack
,M
的 PC
寄存器指向 G
提供的函数,然后去执行。
GM 调度
Go 1.2
前的调度器实现,限制了 Go
并发程序的伸缩性,尤其是对那些有高吞吐或并行计算需求的服务程序。每个 goroutine
对应于 runtime
中的一个抽象结构:G
,而 thread
作为“物理 CPU”
的存在而被抽象为一个结构:M(machine
)。当 goroutine
调用了一个阻塞的系统调用,运行这个 goroutine
的线程就会被阻塞,这时至少应该再创建/唤醒一个线程来运行别的没有阻塞的 goroutine
。线程这里可以创建不止一个,可以按需不断地创建,而活跃的线程(处于非阻塞状态的线程)的最大个数存储在变量 GOMAXPROCS
中。
调用过程如下所示:
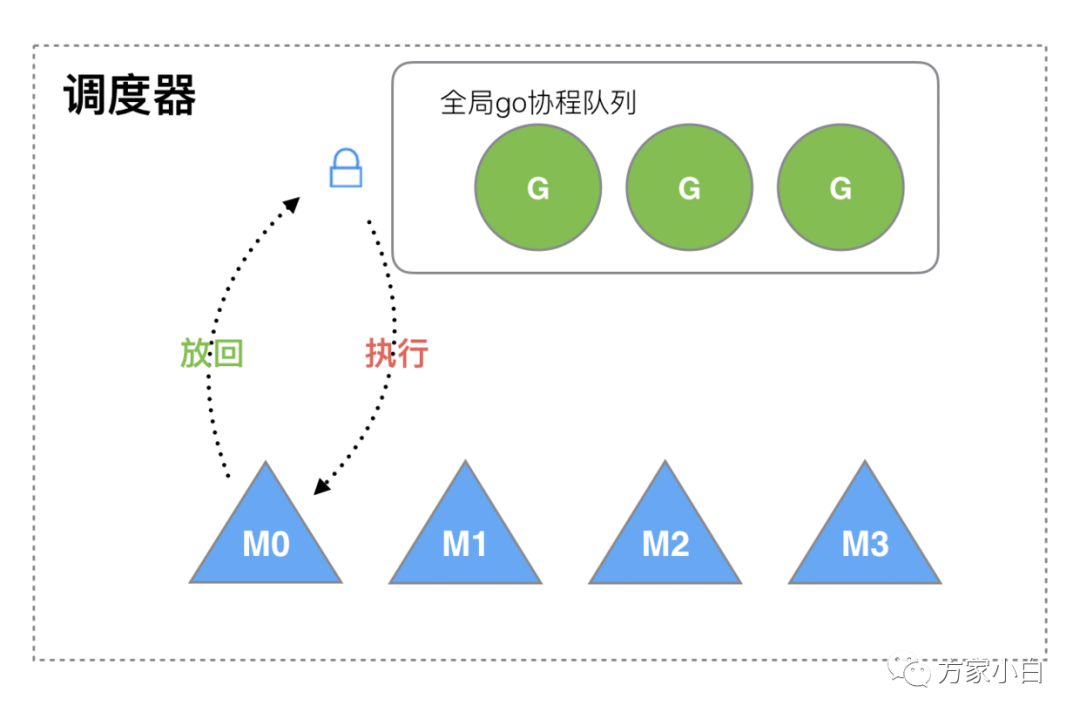
M
想要执行、放回 G
都必须访问全局 G
队列,并且 M
有多个,即多线程访问同一资源需要加锁进行保证互斥 同步,所以全局 G
队列是有互斥锁进行保护的
GM 调度模型的问题
单一全局互斥锁( Sched.Lock
)和集中状态存储 导致所有goroutine
相关操作,比如:创建、结束、重新调度等都要上锁。Goroutine
传递问题M
经常在M
之间传递”可运行”的goroutine
,这导致调度延迟增大以及额外的性能损耗(刚创建的G
放到了全局队列,而不是本地 M 执行,不必要的开销和延迟)。Per-M
持有内存缓存 (M.mcache
) 每个M
持有mcache
和stackalloc
,然而只有在M
运行Go
代码时才需要使用的内存(每个mcache
可以高达2mb
),当M
在处于syscall
时并不需要。运行Go
代码和阻塞在syscall
的M
的比例高达1:100
,造成了很大的浪费。同时内存亲缘性也较差,G
当前在M
运行后对 M 的内存进行了预热,因为现在G
调度到同一个M
的概率不高,数据局部性不好。严重的线程阻塞/解锁 在系统调用的情况下,工作线程经常被阻塞和取消阻塞,这增加了很多开销。比如 M
找不到G
,此时M
就会进入频繁阻塞/唤醒来进行检查的逻辑,以便及时发现新的G
来执行。by Dmitry Vyukov “Scalable Go Scheduler Design Doc”
GMP 调度模型
在 go 1.2
版本及以后,go 引入 GMP
调度模型
G
goroutine
的缩写,每次 go func()
都代表一个 G
,无限制。使用 struct runtime.g
,包含了当前 goroutine
的状态、堆栈、上下文。
M
工作线程(OS thread
)也被称为 Machine,使用 struct runtime.m
,所有 M
是有线程栈的。如果不对该线程栈提供内存的话,系统会给该线程栈提供内存(不同操作系统提供的线程栈大小不同)
。当指定了线程栈,则 M.stack→G.stack
,M
的 PC
寄存器指向 G
提供的函数,然后去执行。
P
“Processor”
是一个抽象的概念,并不是真正的物理 CPU
。
Dmitry Vyukov
的方案是引入一个结构 P
,它代表了 M
所需的上下文环境,也是处理用户级代码逻辑的处理器。它负责衔接 M
和 G
的调度上下文,将等待执行的 G
与 M
对接。当 P 有任务时需要创建或者唤醒一个 M
来执行它队列里的任务。所以 P/M
需要进行绑定,构成一个执行单元。P
决定了并行任务的数量,可通过 runtime.GOMAXPROCS
来设定。在 Go1.5
之后 GOMAXPROCS
被默认设置可用的核数,而之前则默认为1
。
Runtime
起始时会启动一些 G
:垃圾回收的 G
,执行调度的 G
,运行用户代码的 G
;并且会创建一个 M
用来开始 G
的运行。随着时间的推移,更多的 G
会被创建出来,更多的 M
也会被创建出来。
Tips: https://github.com/uber-go/automaxprocsAutomatically set GOMAXPROCS to match Linux container CPU quota.mcache/stackalloc
从 M
移到了 P
,而 G
队列也被分成两类,保留全局 G
队列,同时每个 P
中都会有一个本地的 G
队列。
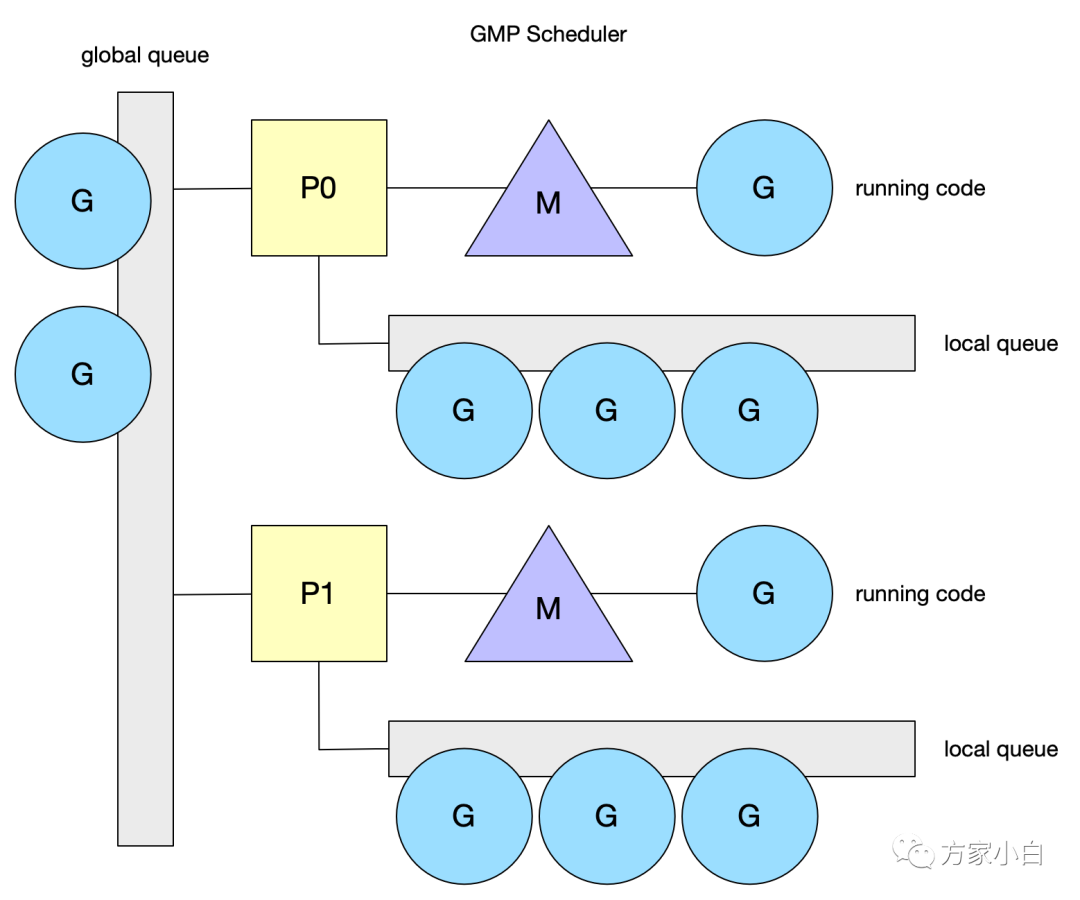
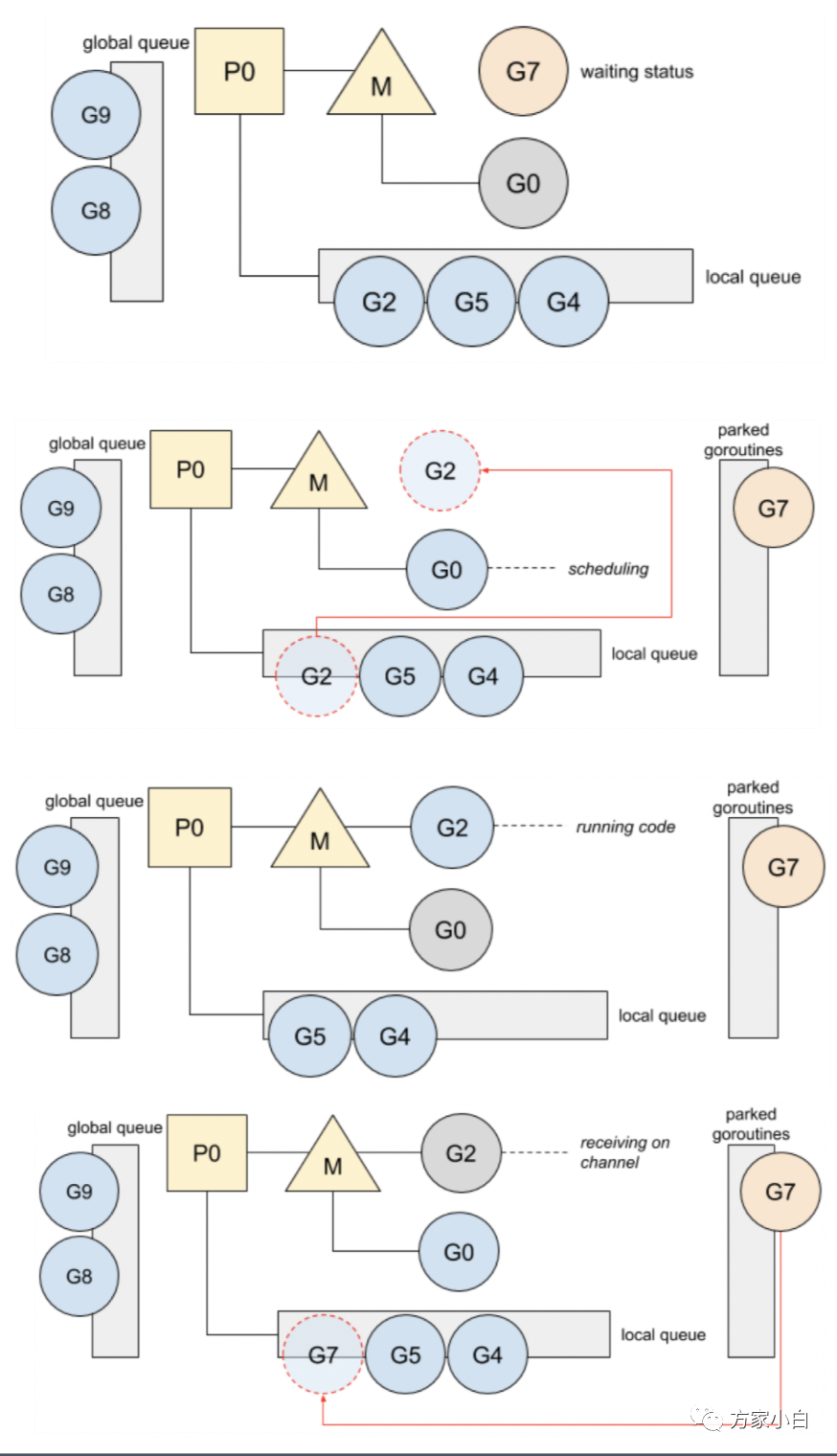
GMP
调度
GMP
调度模型, 引入了 local queue
,因为 P
的存在,runtime
并不需要做一个集中式的 goroutine
调度,每一个 M
都会在 P's local queue
、global queue
或者其他 P
队列中找 G
执行,减少全局锁对性能的影响。这也是 GMP Work-stealing
调度算法的核心。注意 P
的本地 G
队列还是可能面临一个并发访问的场景,为了避免加锁,这里 P
的本地队列是一个 LockFree
的队列,窃取 G
时使用 CAS
原子操作来完成。关于LockFree
和 CAS
的知识参见 Lock-Free
。
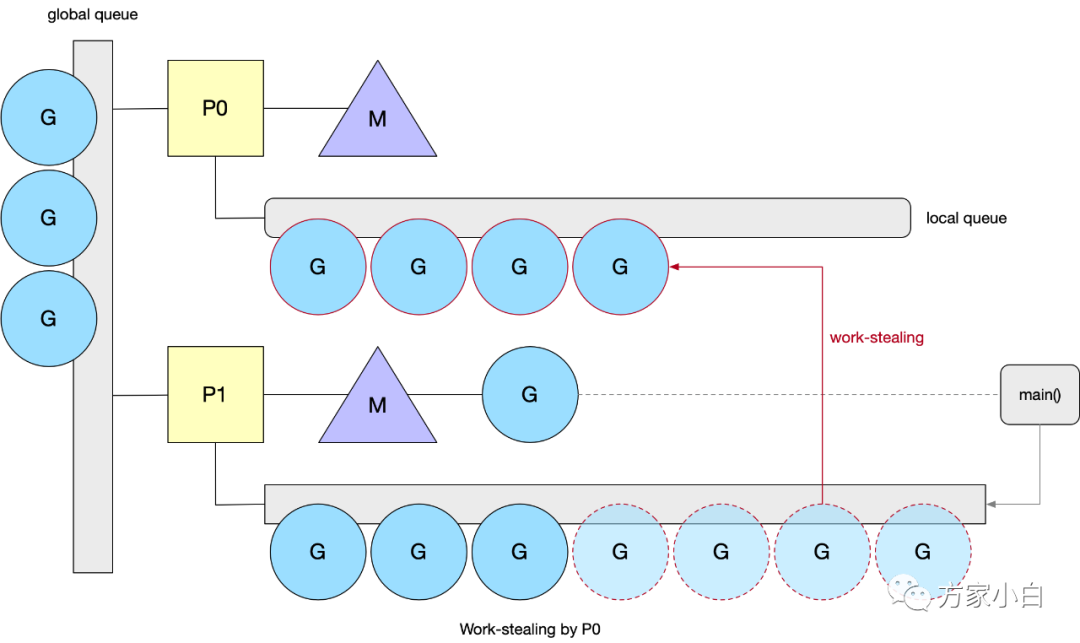
Work Stealing
当一个 P
执行完本地所有的 G
之后,并且全局队列为空的时候,会尝试挑选一个受害者 P
,从它的 G
队列中窃取一半的 G
。否则会从全局队列中获取(当前个数/GOMAXPROCS
)个 G
。为了保证公平性,从随机位置上的 P
开始,而且遍历的顺序也随机化了(选择一个小于 GOMAXPROCS
,且和它互为质数的步长),保证遍历的顺序也随机化了。
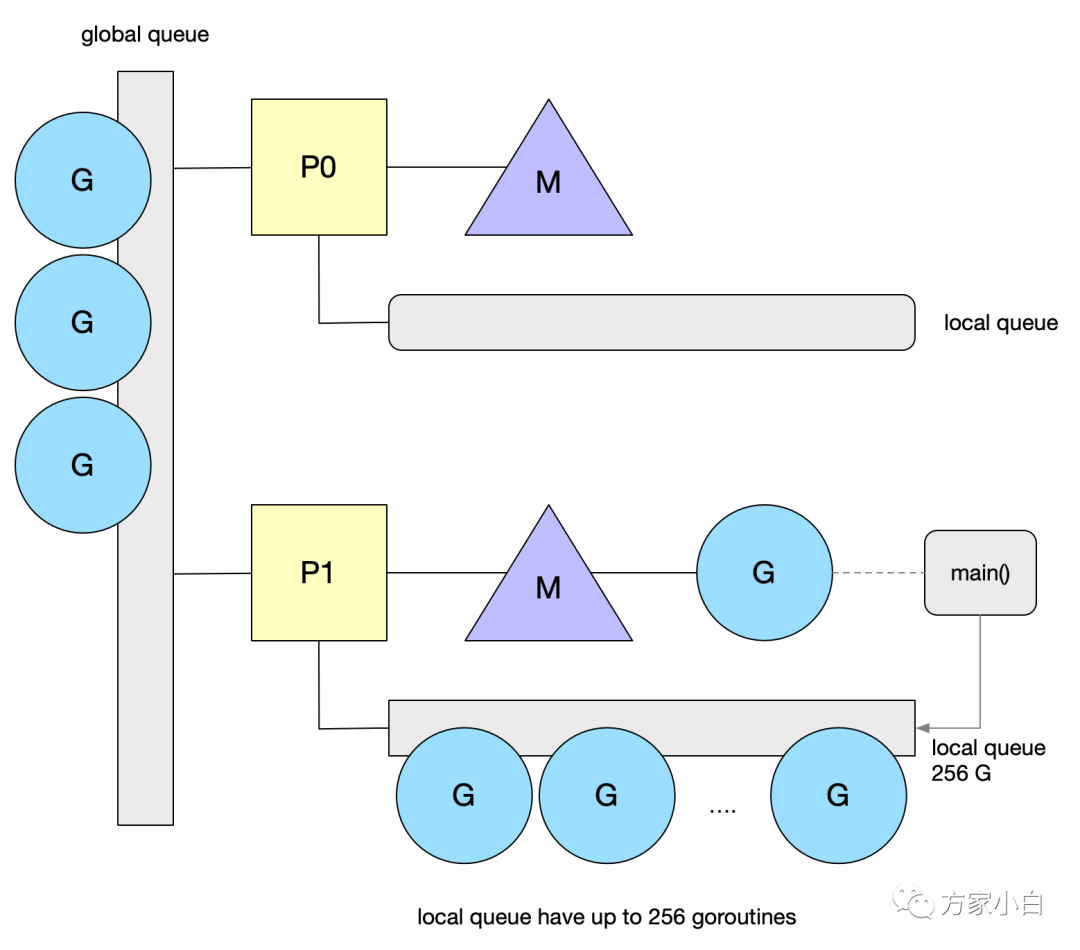
光窃取失败时获取是不够的,可能会导致全局队列饥饿。P
的调度算法中还会每个 N
轮调度之后就去全局队列拿一个 G
。如下图。

谁放入的全局队列呢
有两种情况会把G
放到全局队列中。
新建 G
时P
的本地G
队列放不下已满并达到256
个的时候会放半数G
到全局队列去。阻塞的系统调用返回时找不到空闲 P
也会放到全局队列。
SysCall 系统调用
当 G
调用 syscall
后会解绑 P
,然后 M
和 G
进入阻塞,而 P
此时的状态就是 syscall
,表明这个 P
的 G
正在 syscall
中,这时的 P
是不能被调度给别的 M
的。如果在短时间内阻塞的 M
就唤醒了,那么 M
会优先来重新获取这个 P
,能获取到就继续绑回去,这样有利于数据的局部性。系统监视器 (system monitor
),称为 sysmon
,会定时扫描。在执行 syscall
时, 如果某个 P
的 G
执行超过一个 sysmon tick
(10ms
),就会把他设为 idle
,重新调度给需要的 M
,强制解绑。
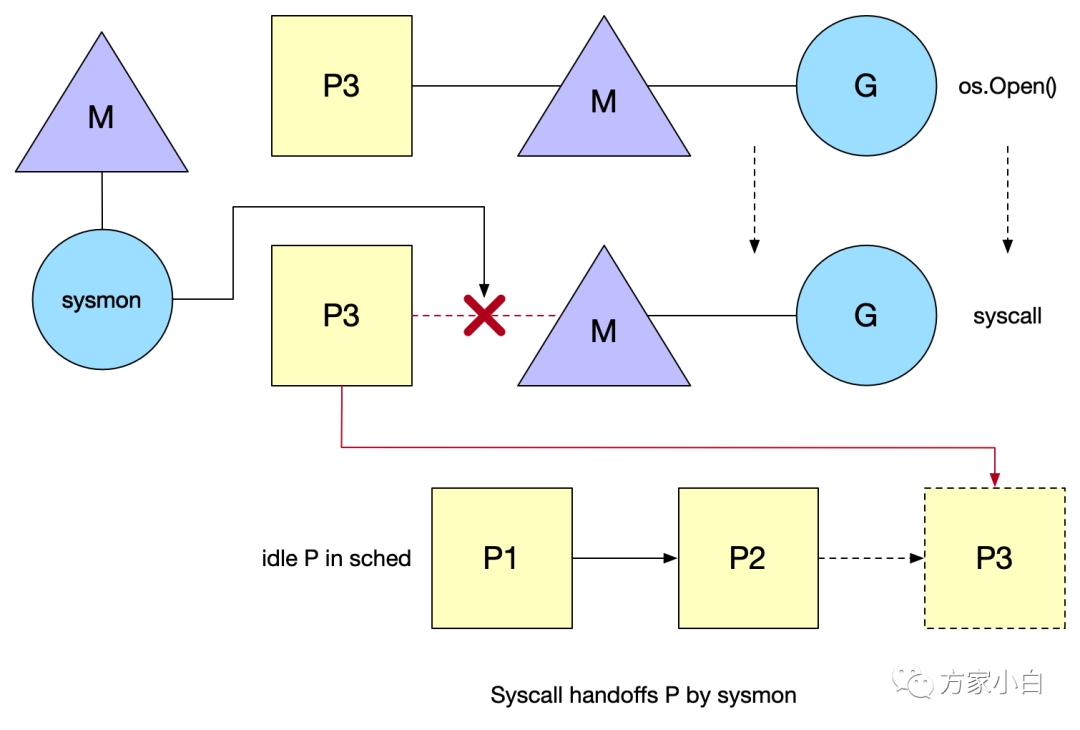
P3
和 M
脱离后目前在 idle list
中等待被绑定(处于 syscall
状态)。而 syscall
结束后 M
按照如下规则执行直到满足其中一个条件:
尝试获取同一个 P
(P3
),恢复执行G尝试获取 idle list
中的其他空闲P
,恢复执行G找不到空闲 P
,把G
放回global queue
,M
放回到idle list
再举一个例子:如下图.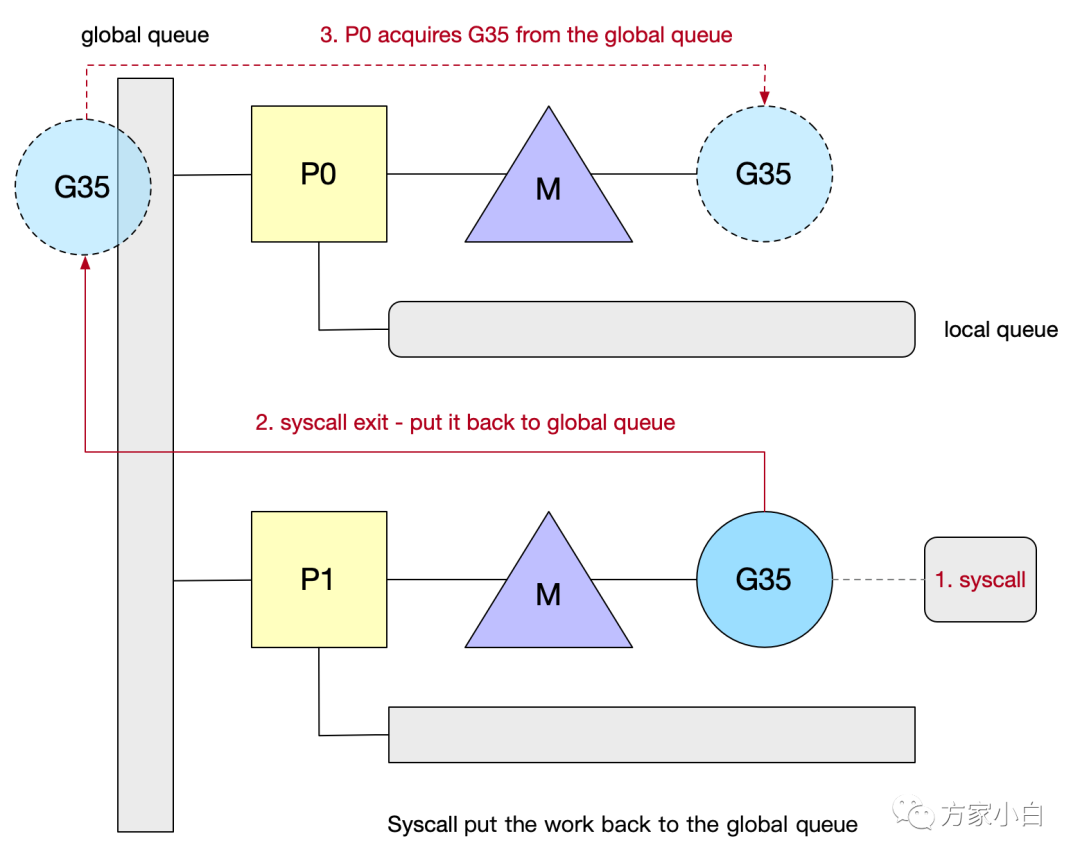
第一步: G35
发生了系统调用,长时间没有返回。P1
和M
解绑。(p1
不会马上被推送到idle list
, 而是经过一段时间才会推送到idle list.
)第二步: G35
系统调用完成,将G35
推向了全局队列.第三步: G35
被其他的P捞到了(可能P0
经过1/61
轮次正好check
全局队列), 这样G35
就可以继续执行了。
需要注意的是:当使用了 Syscall
,Go
无法限制 Blocked OS threads
的数量:The GOMAXPROCS variable limits the number of operating system threads that can execute user-level Go code simultaneously. There is no limit to the number of threads that can be blocked in system calls on behalf of Go code; those do not count against the GOMAXPROCS limit. This package’s GOMAXPROCS function queries and changes the limit.
Tips
: 使用 syscall
写程序要认真考虑 pthread exhaust
问题。
Spining Thread.
线程自旋是相对于线程阻塞而言的,表象就是循环执行一个指定逻辑(调度逻辑,目的是不停地寻找 G)。这样做的问题显而易见,如果 G
迟迟不来,CPU
会白白浪费在这无意义的计算上。但好处也很明显,降低了 M 的上下文切换成本,提高了性能。在两个地方引入自旋:
类型1: M
不带P
的找P
挂载(一有P
释放就结合)类型2: M
带P
的找G
运行(一有runable
的G
就执行)。这种情况下会首先 按照1/61
轮次的查询global Queue
, 然后再查看local Queue
是否有G
. 如果没有,则去查看Global Queue
, 如果没有再去检查net poller
, 看看是否有可用的goroutine
. 为了避免过多浪费CPU
资源,自旋的M
最多只允许GOMAXPROCS
(Busy P
)。同时当有类型1的自旋M
存在时,类型2
的自旋M
就不阻塞,阻塞会释放P
,一释放P
就马上被类型1
的自旋M
抢走了,没必要。
在新 G
被创建、M
进入系统调用、M
从空闲被激活这三种状态变化前,调度器会确保至少有一个自旋 M
存在(唤醒或者创建一个 M
),除非没有空闲的 P
。
为什么呢?
当新 G
创建,如果有可用P
,就意味着新G
可以被立即执行,即便不在同一个P
也无妨,所以我们保留一个自旋的 M(这时应该不存在类型1的自旋只有类型2的自旋)就可以保证新 G 很快被运行。当 M
进入系统调用,意味着M
不知道何时可以醒来,那么M
对应的P
中剩下的G
就得有新的M
来执行,所以我们保留一个自旋的M
来执行剩下的G
(这时应该不存在类型2
的自旋只有类型1
的自旋)。如果 M
从空闲变成活跃,意味着可能一个处于自旋状态的M
进入工作状态了,这时要检查并确保还有一个自旋M
存在,以防还有G
或者还有P
空着的。
GMP
模型问题总结
单一全局互斥锁( Sched.Lock
)和集中状态存储G
被分成全局队列和P
的本地队列,全局队列依旧是全局锁,但是使用场景明显很少,P
本地队列使用无锁队列,使用原子操作来面对可能的并发场景。Goroutine
传递问题G
创建时就在P
的本地队列,可以避免在G
之间传递(窃取除外),G
对P
的数据局部性好; 当G
开始执行了,系统调用返回后M
会尝试获取可用P
,获取到了的话可以避免在M
之间传递。而且优先获取调用阻塞前的P
,所以G
对M
数据局部性好,G
对P
的数据局部性也好。Per-M
持有内存缓存 (M.mcache
) 内存mcache
只存在P
结构中,P
最多只有GOMAXPROCS
个,远小于M
的个数,所以内存没有过多的消耗。严重的线程阻塞/解锁 通过引入自旋,保证任何时候都有处于等待状态的自旋 M,避免在等待可用的 P
和G
时频繁的阻塞和唤醒。
syscon
sysmon
也叫监控线程,它无需 P
也可以运行,他是一个死循环,每20us~10ms
循环一次,循环完一次就 sleep
一会,为什么会是一个变动的周期呢,主要是避免空转,如果每次循环都没什么需要做的事,那么 sleep
的时间就会加大。
释放闲置超过 5
分钟的span
物理内存;如果超过2分钟没有垃圾回收,强制执行; 将长时间未处理的 netpoll
添加到全局队列;向长时间运行的 G
任务发出抢占调度;收回因 syscall
长时间阻塞的P
;
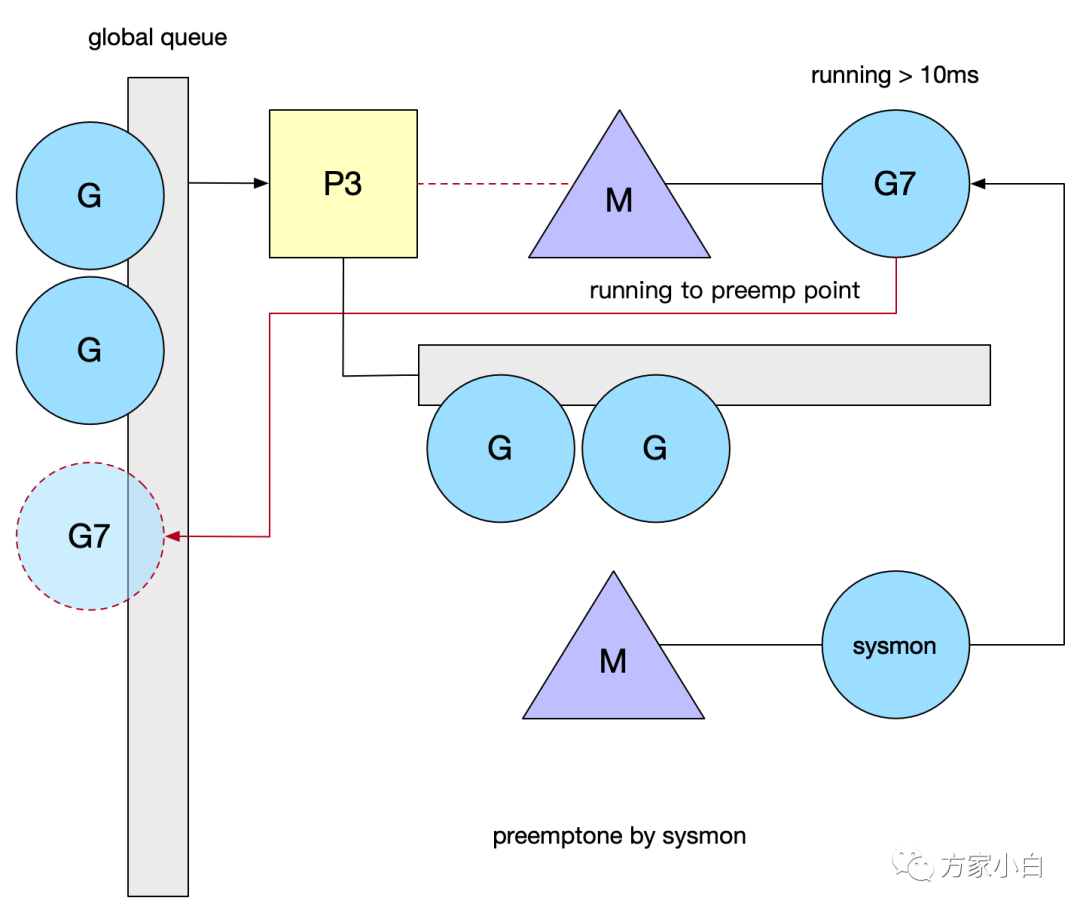
当 P
在 M
上执行时间超过10ms
,sysmon
调用 preemptone
将 G
标记为 stackPreempt
。因此需要在某个地方触发检测逻辑,Go
当前是在检查栈是否溢出的地方判定(morestack()
),M
会保存当前 G
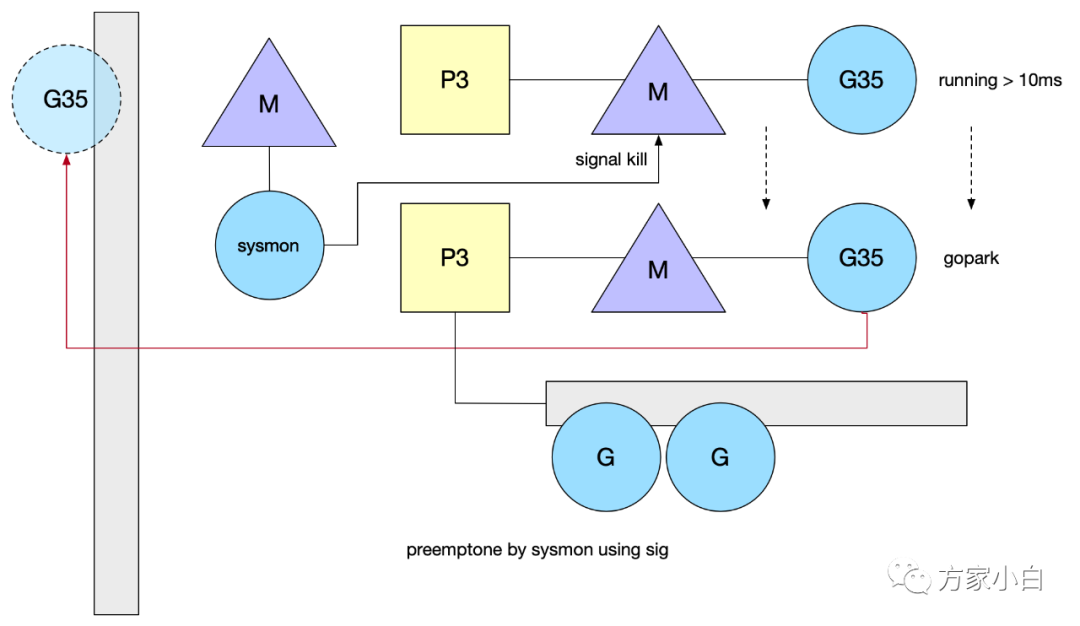
的上下文,重新进入调度逻辑, 这样就不会死循环了。死循环:issues/11462信号抢占:go1.14基于信号的抢占式调度实现原理异步抢占,注册 sigurg
信号,通过 sysmon
检测,对 M
对应的线程发送信号,触发注册的 handler
,它往当前 G
的 PC
中插入一条指令(调用某个方法),在处理完 handler
,G
恢复后,自己把自己推到了 global queue
中。
Network poller
Go
所有的 I/O
都是阻塞的。然后通过 goroutine + channel
来处理并发。因此所有的 IO
逻辑都是直来直去的,你不再需要回调,不再需要 future
,要的仅仅是 step by step
。这对于代码的可读性是很有帮助的。G
发起网络 I/O
操作也不会导致 M
被阻塞(仅阻塞G
),从而不会导致大量 M
被创建出来。将异步 I/O
转换为阻塞 I/O
的部分称为 netpoller
。打开或接受连接都被设置为非阻塞模式。如果你试图对其进行 I/O
操作,并且文件描述符数据还没有准备好,G
会进入 gopark
函数,将当前正在执行的 G
状态保存起来,然后切换到新的堆栈上执行新的 G
。
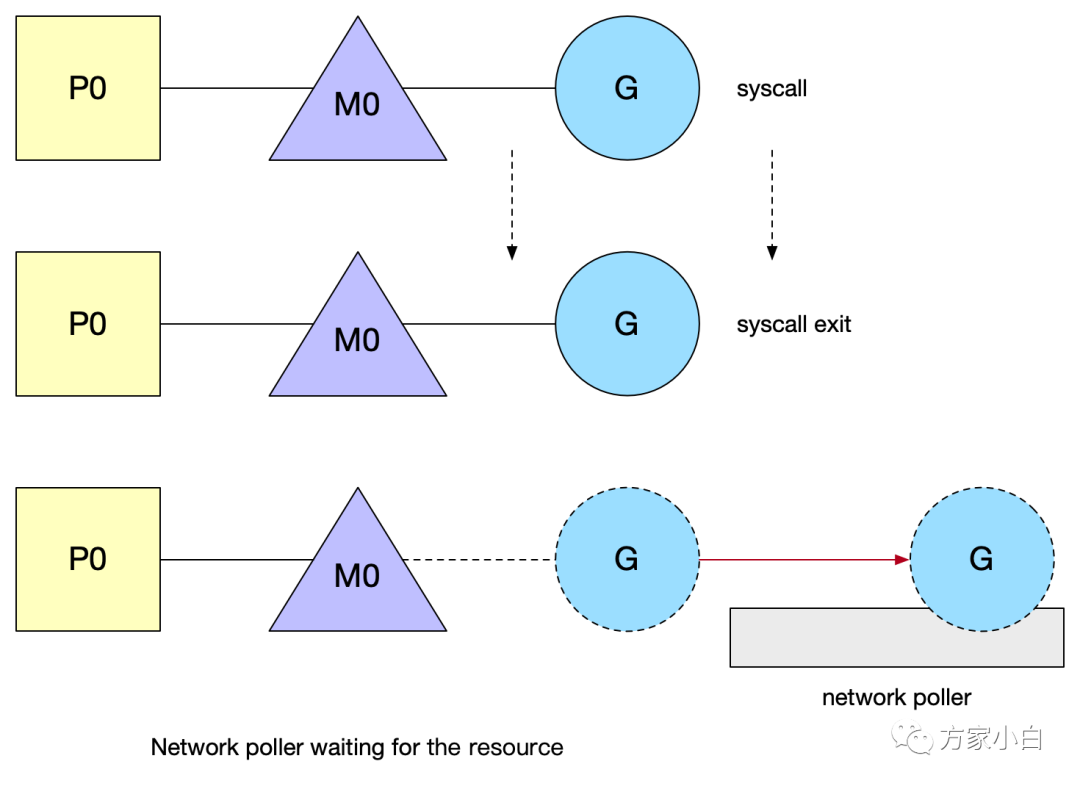
那什么时候 G
被调度回来呢?
sysmonschedule()
:M
找G
的调度函数GC
:start the world
调用netpoll()
在某一次调度G
的过程中,处于就绪状态的fd
对应的G
就会被调度回来。G
的gopark
状态:G
置为waiting
状态,等待显示goready
唤醒,在poller
中用得较多,还有锁、chan
等。
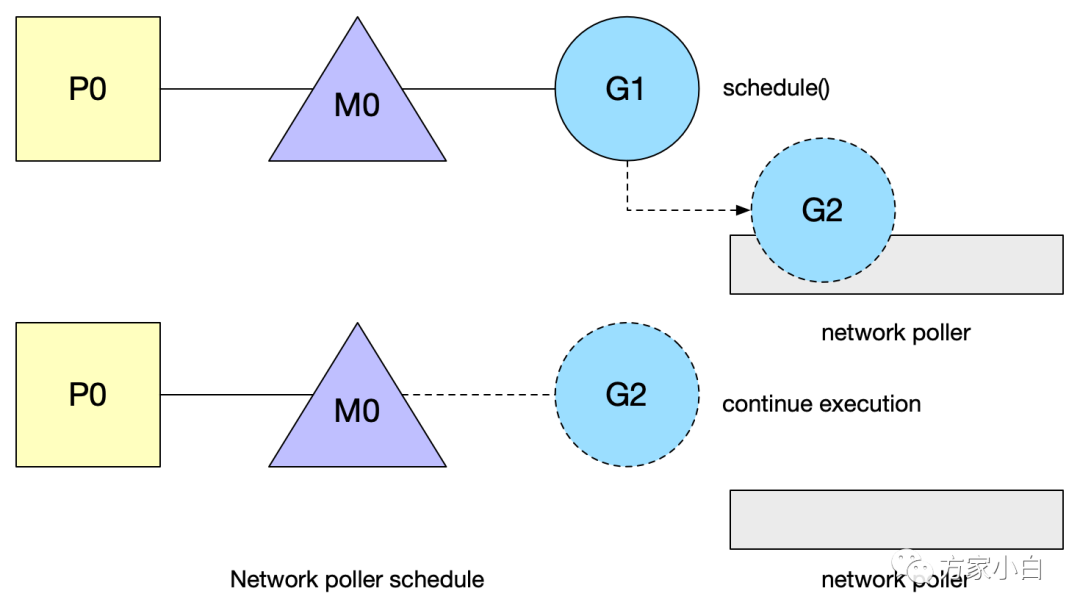
Scheduler Affinity 调度亲和性
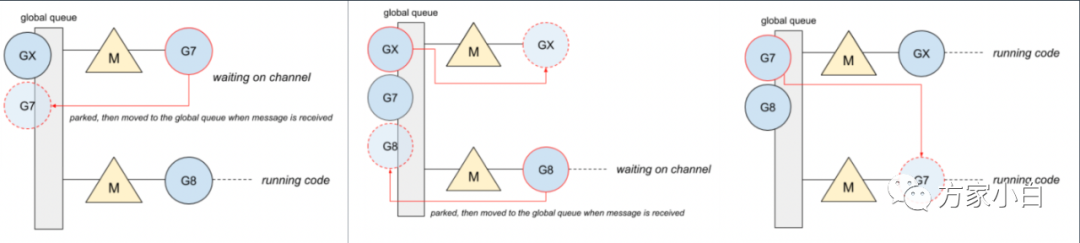
GM
调度器时代的,chan
操作导致的切换代价。
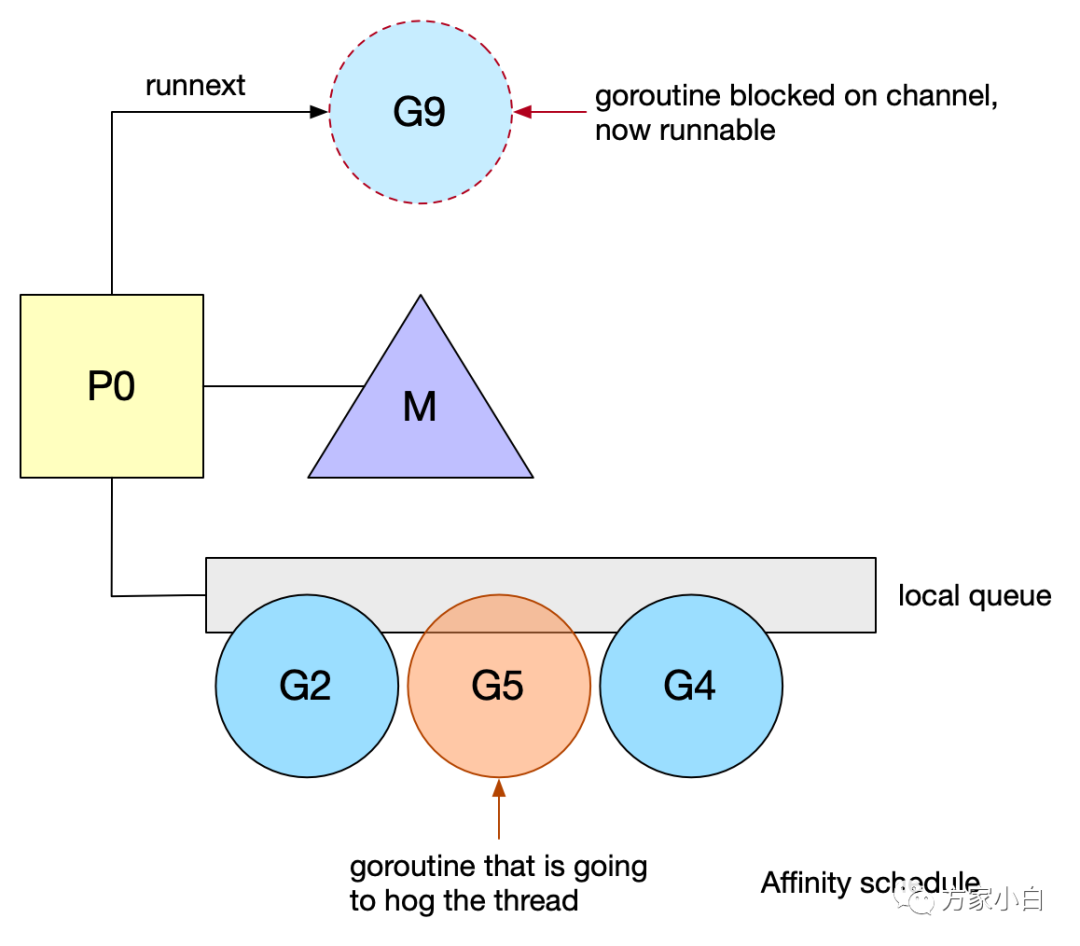
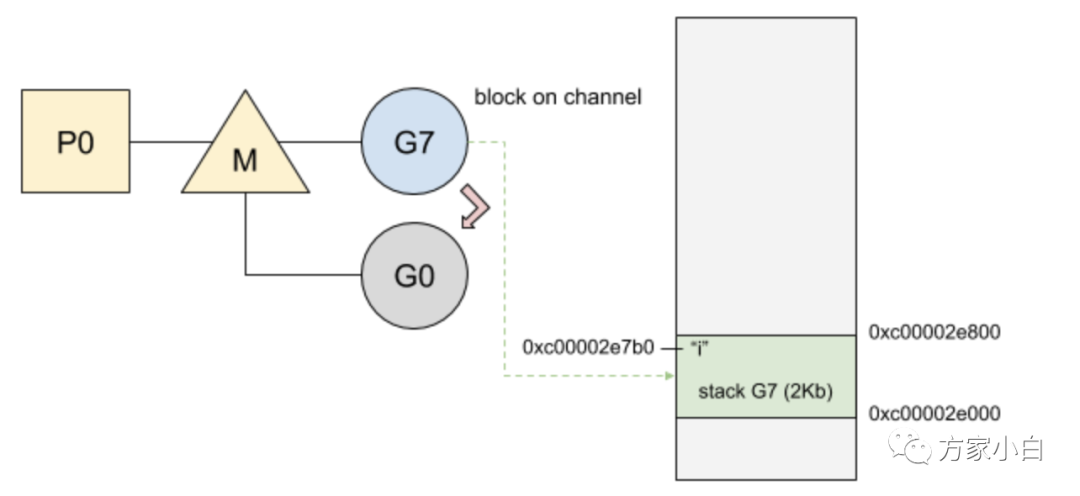
Goroutine#7
正在等待消息,阻塞在chan
。一旦收到消息,这个goroutine
就被推到全局队列。然后, chan
推送消息,goroutine#X
将在可用线程上运行,而goroutine#8
将阻塞在chan
。goroutine#7
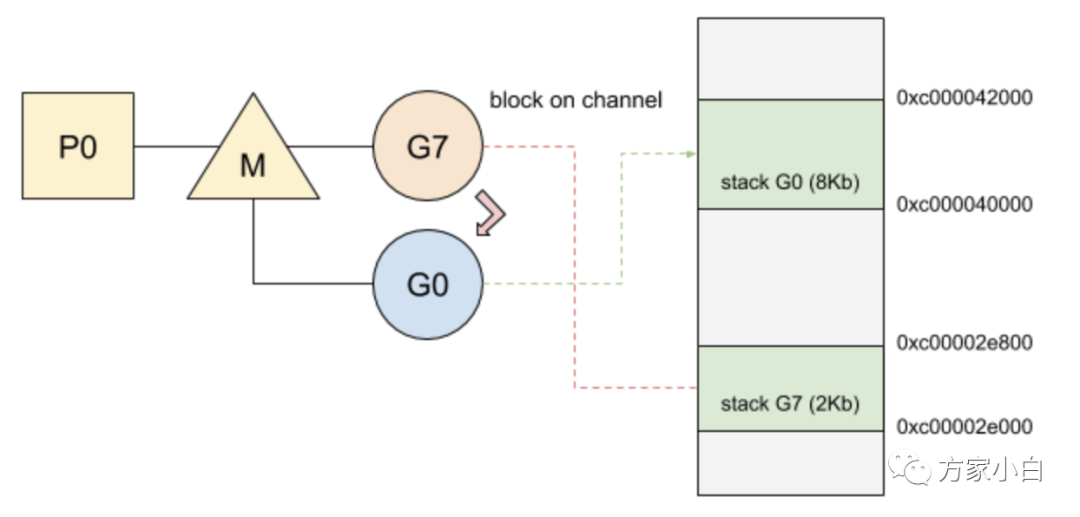
现在在可用线程上运行。在chan
来回通信的goroutine
会导致频繁的blocks
,即频繁地在本地队列中重新排队。然而,由于本地队列是FIFO
实现,如果另一个goroutine
占用线程,unblock goroutine
不能保证尽快运行。同时Go
亲缘性调度的一些限制:Work-stealing
、系统调用。goroutine #9
在chan
被阻塞后恢复。但是,它必须等待#2
、#5
和#4
之后才能运行。goroutine #5
将阻塞其线程,从而延迟goroutine #9
,并使其面临被另一个P
窃取的风险。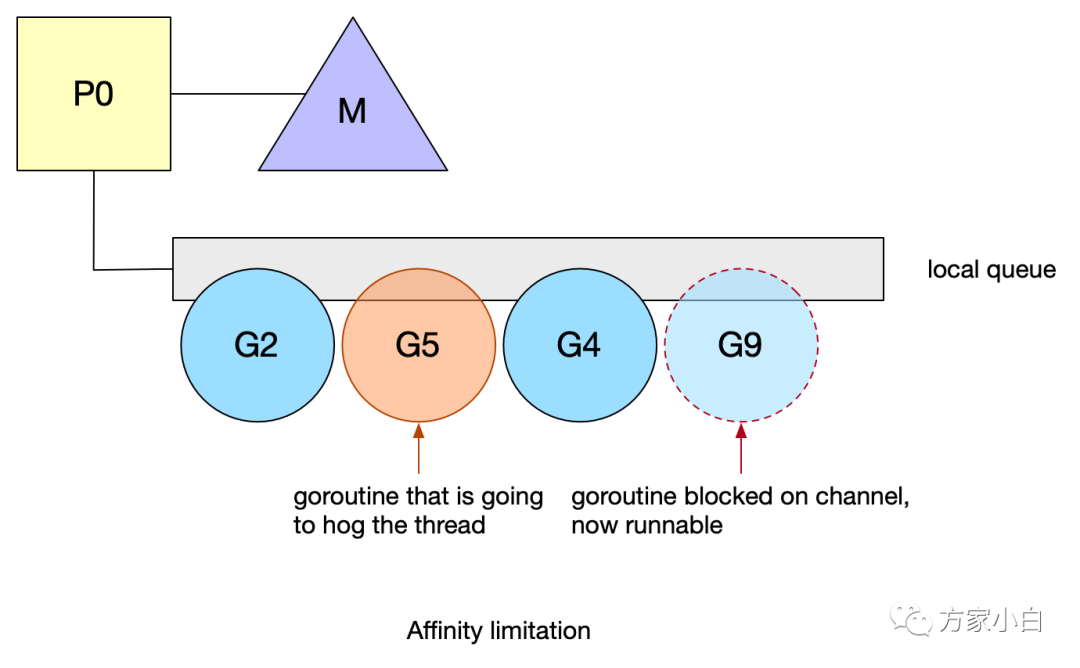
针对 communicate-and-wait
模式,进行了亲缘性调度的优化。Go 1.5
在 P
中引入了 runnext
特殊的一个字段,可以高优先级执行 unblock G
。goroutine #9
现在被标记为下一个可运行的。这种新的优先级排序允许 goroutine
在再次被阻塞之前快速运行。这一变化对运行中的标准库产生了总体上的积极影响,提高了一些包的性能。
Goroutine Lifecycle
go 程序的启动
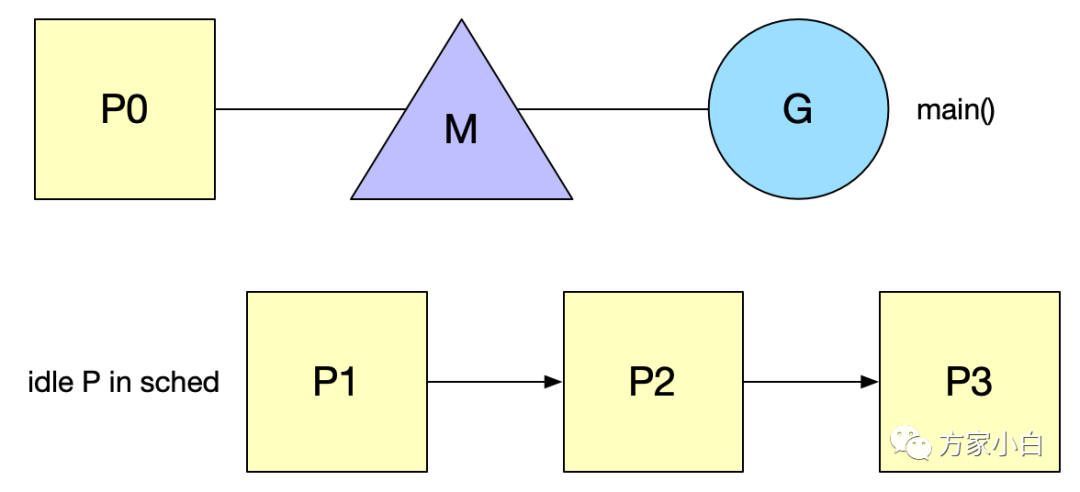
整个程序始于一段汇编,而在随后的 runtime·rt0_go(也是汇编程序)中,会执行很多初始化工作。

绑定 m0 和 g0,m0就是程序的主线程,程序启动必然会拥有一个主线程,这个就是 m0。g0 负责调度,即 shedule() 函数。 创建 P,绑定 m0 和 p0,首先会创建 GOMAXPROCS 个 P ,存储在 sched 的 空闲链表(pidle)。 新建任务 g 到 p0 本地队列,m0 的 g0 会创建一个 指向 runtime.main() 的 g ,并放到 p0 的本地队列。runtime.main(): 启动 sysmon 线程;启动 GC 协程;执行 init,即代码中的各种 init 函数;执行 main.main 函数。
Os Thread 创建
准备运行的新 goroutine 将唤醒 P 以更好地分发工作。这个 P 将创建一个与之关联的 M 绑定到一个 OS thread。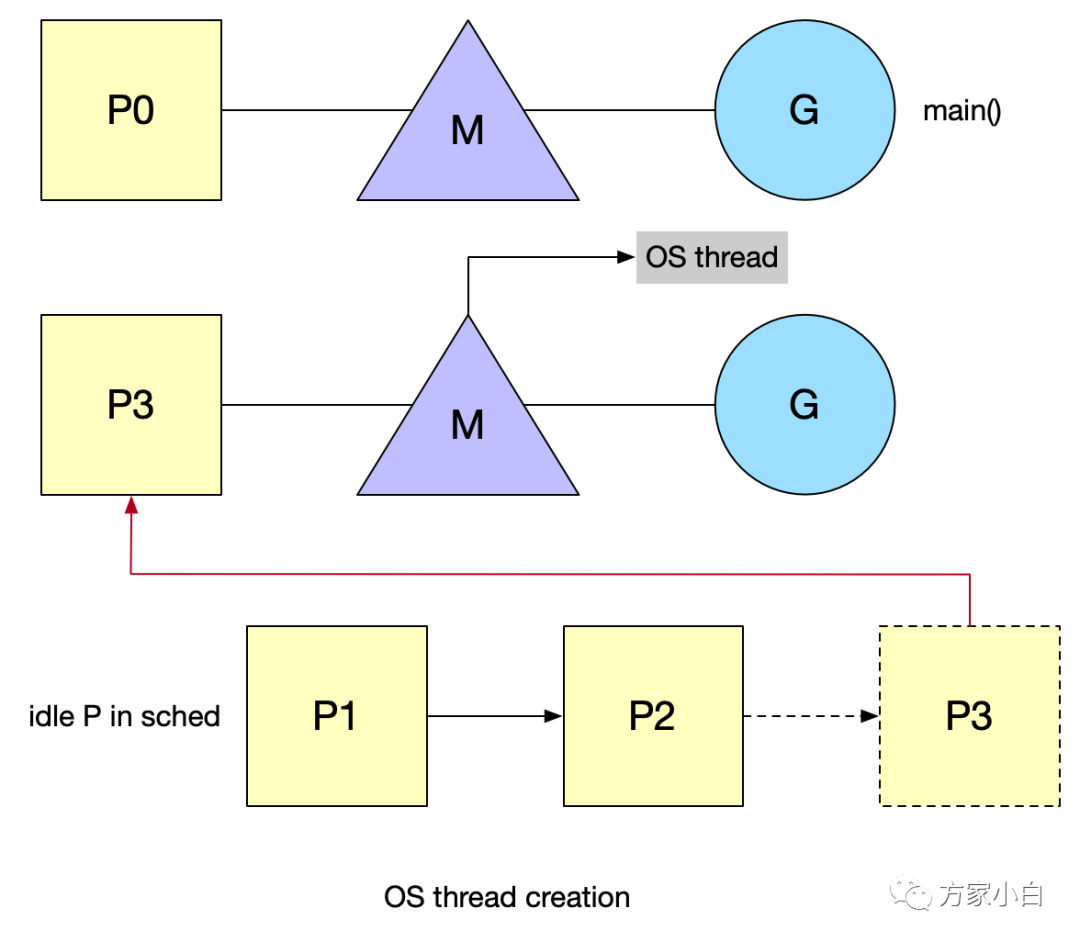
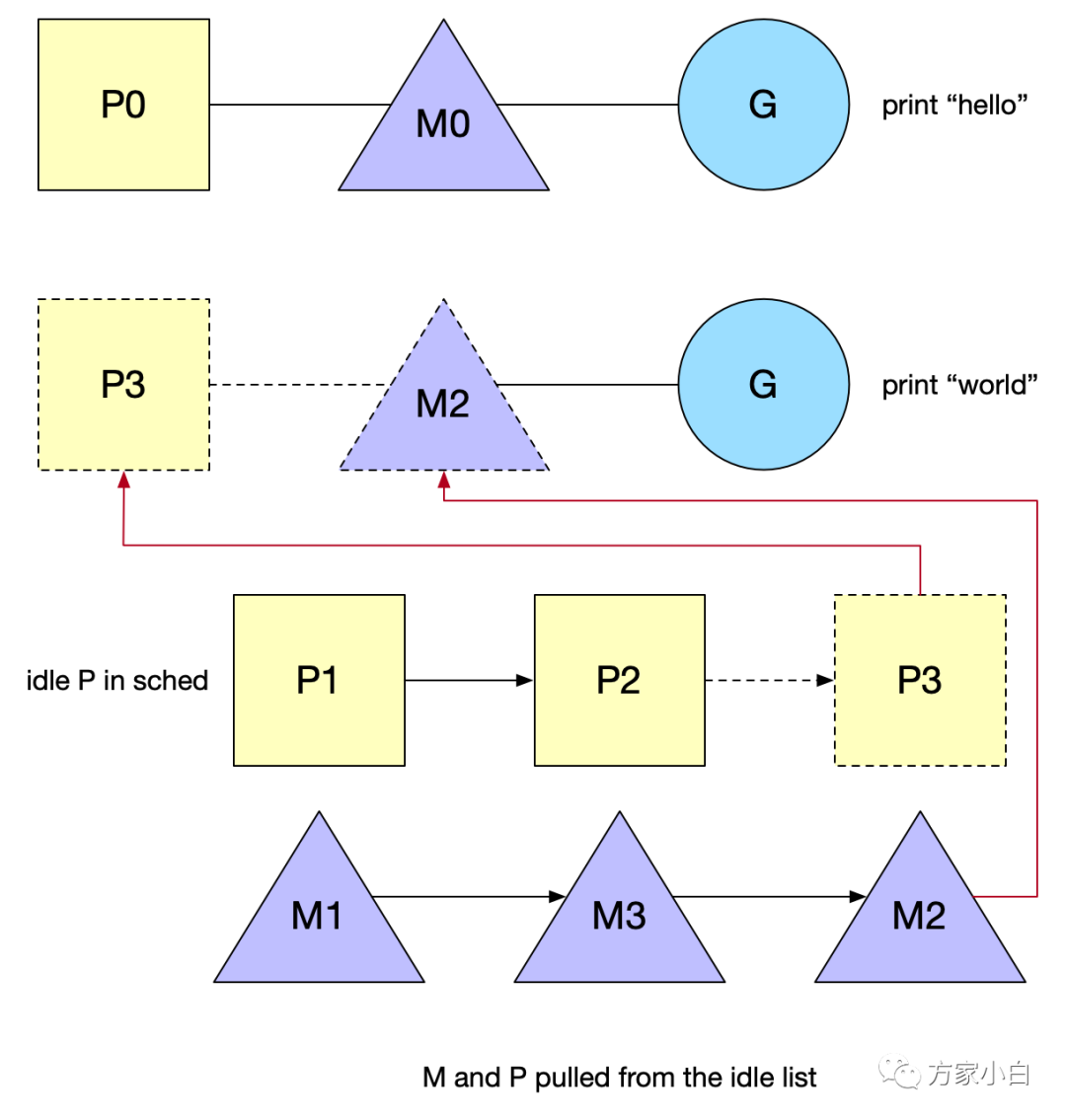
go func()
中 触发 Wakeup
唤醒机制:有空闲的 P
而没有在 spinning
状态的 M 时候, 需要去唤醒一个空闲(睡眠)的 M
或者新建一个。当线程首次创建时,会执行一个特殊的 G
,即 g0
,它负责管理和调度 G
。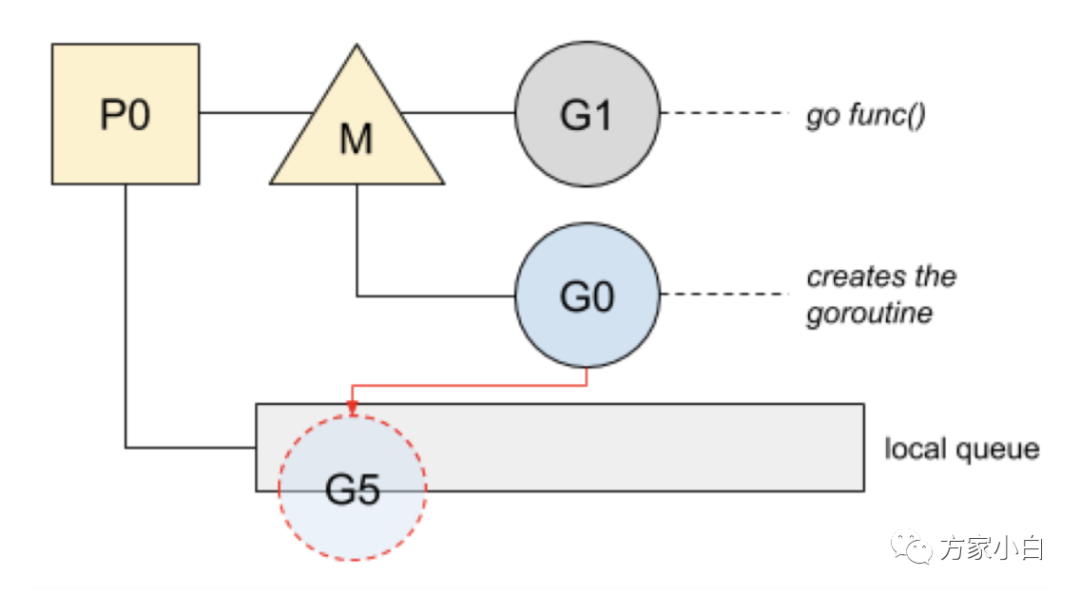
特殊的g0
Go
基于两种断点将 G
调度到线程上:
当 G
阻塞时:系统调用、互斥锁或chan
。阻塞的G
进入睡眠模式/进入队列,并允许Go
安排和运行等待其他的G
。在函数调用期间,如果 G
必须扩展其堆栈。这个断点允许Go
调度另一个G
并避免运行G
占用CPU
。在这两种情况下,运行调度程序的g0
将当前G
替换为另一个G
,即ready to run
。然后,选择的G
替换g0
并在线程上运行。与常规G
相反,g0
有一个固定和更大的栈。Defer
函数的分配GC
收集,比如STW
、扫描G
的堆栈和标记、清除操作栈扩容,当需要的时候,由 g0
进行扩栈操作
Schedule
在 Go
中,G
的切换相当轻便,其中需要保存的状态仅仅涉及以下两个:
Goroutine
在停止运行前执行的指令,程序当前要运行的指令是记录在程序计数器(PC
)中的,G
稍后将在同一指令处恢复运行;G
的堆栈,以便在再次运行时还原局部变量;在切换之前,堆栈将被保存,以便在G
再次运行时进行恢复:
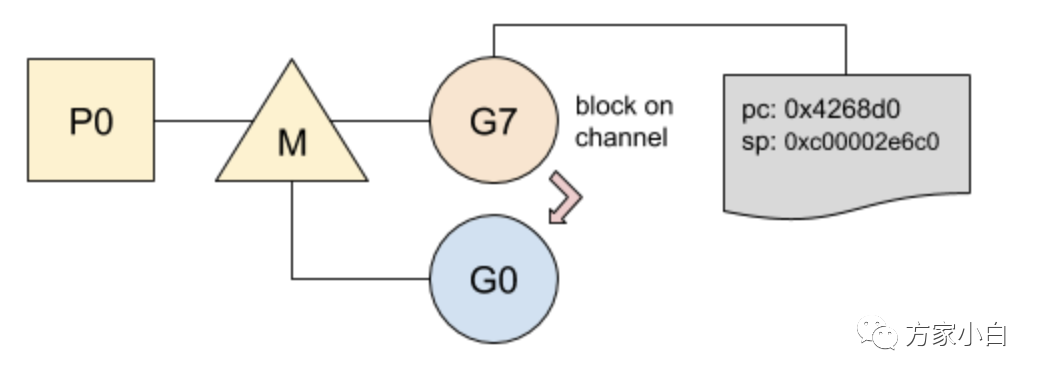
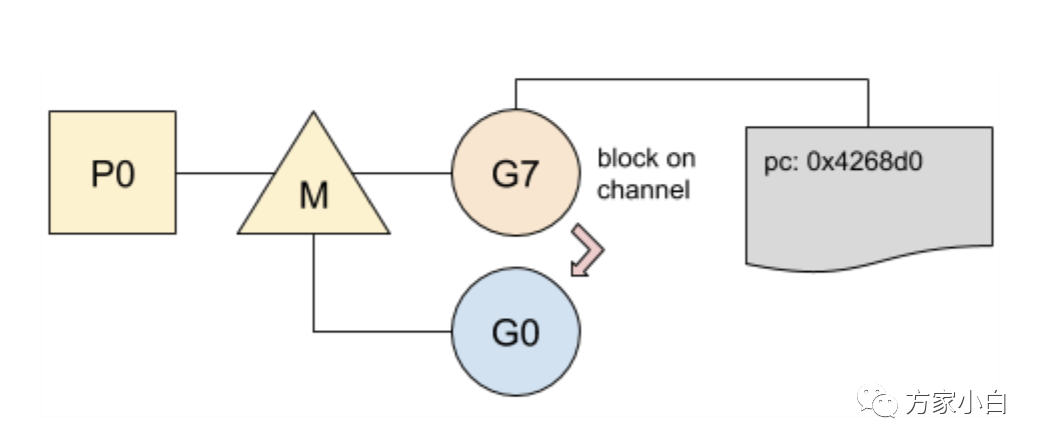
从 g
到 g0
或从 g0
到 g
的切换是相当迅速的,它们只包含少量固定的指令(9-10ns
)。相反,对于调度阶段,调度程序需要检查许多资源以便确定下一个要运行的 G
。当前 g
阻塞在 chan 上并切换到 g0
:
1、PC 和堆栈指针一起保存在内部结构中; 2、将 g0 设置为正在运行的 goroutine; 3、g0 的堆栈替换当前堆栈;
g0
寻找新的 Goroutine
来运行g0
使用所选的 Goroutine
进行切换:
1、 PC
和堆栈指针是从其内部结构中获取的;2、程序跳转到对应的 PC
地址;

Goroutine Recycle
goroutine
重用
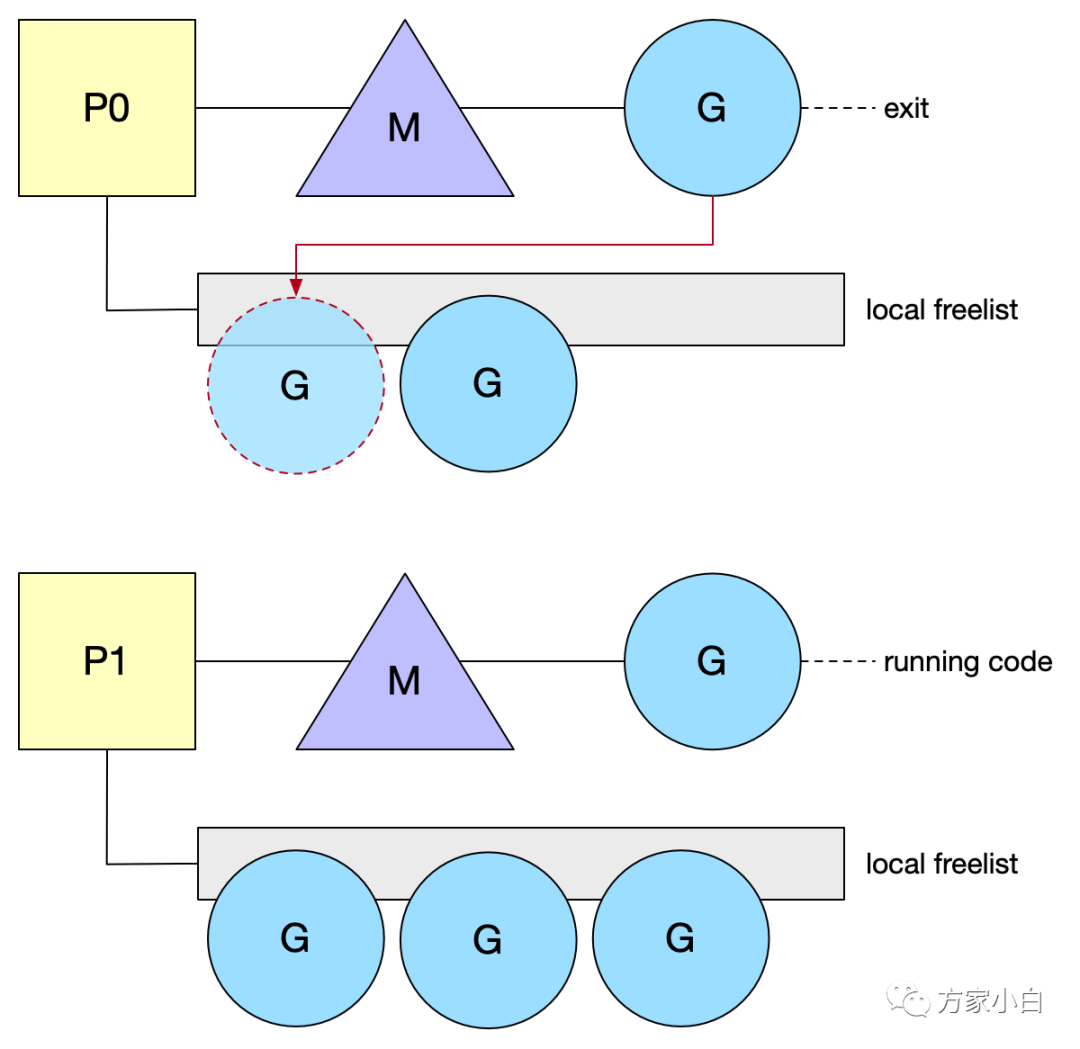
G
很容易创建,栈很小以及快速的上下文切换。基于这些原因,开发人员非常喜欢并使用它们。然而,一个产生许多 shortlive
的 G
的程序将花费相当长的时间来创建和销毁它们。每个 P
维护一个 freelist G
,保持这个列表是本地的,这样做的好处是不使用任何锁来 push/get
一个空闲的 G
。当 G
退出当前工作时,它将被 push
到这个空闲列表中。
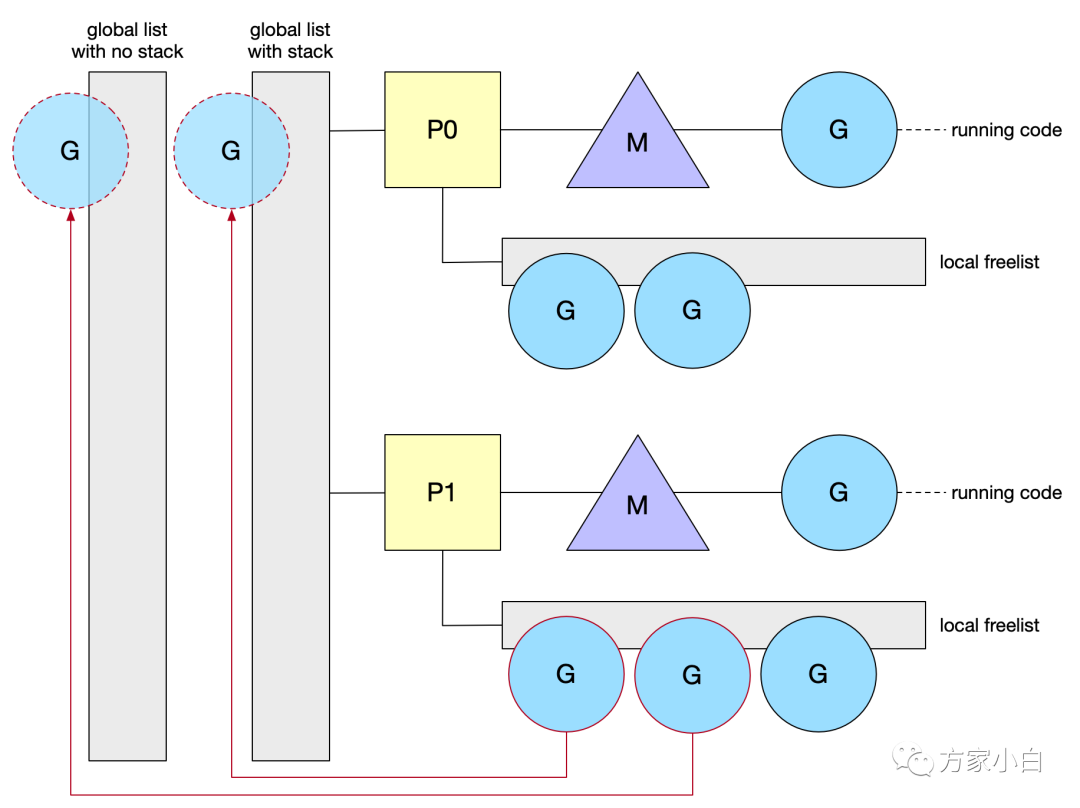
为了更好地分发空闲的 G
,调度器也有自己的列表。它实际上有两个列表:一个包含已分配栈的 G
,另一个包含释放过堆栈的 G
(无栈)。锁保护 central list
,因为任何 M 都可以访问它。当本地列表长度超过64时,调度程序持有的列表从 P
获取 G
。然后一半的 G
将移动到中心列表(central list
)。需求回收 G
是一种节省分配成本的好方法。但是,由于堆栈是动态增长的,现有的G
最终可能会有一个大栈。因此,当堆栈增长(即超过2K
)时,Go
不会保留这些栈。
最后
希望和你一起遇见更好的自己

看到这里啦,就点个关注再走吧~
