




点击蓝字关注我吧
目录
本文篇幅较长我准备拆成四部分进行说明:如果你想一次看完,我把它放在了CSDN和知乎上了。点击查看原文吧。
HashMap基本介绍
HashMap的增加过程
HashMap的删除过程
HashMap的修改和查找过程
HashMap的其他功能介绍
要思考的问题
HashMap的底层数据结构(节点结构,这种结构有什么优点)
如何处理hash冲突
怎么扩容?扩展机制是什么?
增删改查过程
链表到红黑树的转换过程,反之?
红黑树相关(见另一篇数据结构之红黑树)
hash计算
达到的目标
[x] 掌握底层数据结构
[x] 掌握扩容原理
[x] 掌握hash冲突的处理过程
[x] 掌握增删改查过程
看之前要掌握的知识点
红黑树
看之前大体了解的知识点
hash算法[2]
poisson分布[1]
开始
HashMap的继承体系
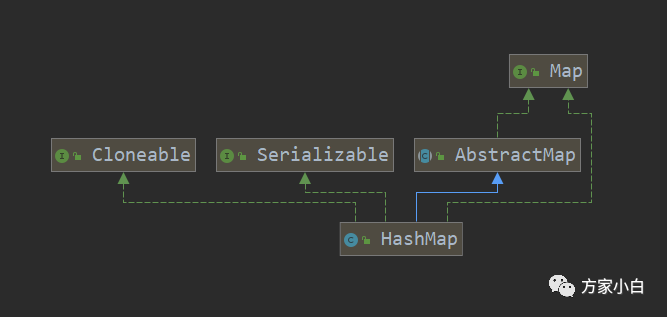
AbstractMap: map的抽象类,以最大限度的减少实现Map接口的类的工作量。
hashMap结构
字段解释
常量字段(默认值字段)
DEFAULT_INITIAL_CAPACITY=1<<4: 默认的初始容量,默认是为16,必须是2的n次方.为什么呢? 见扩容的方法。
DEFAULT_LOAD_FACTOR=0.75f: 默认的负载因子。它和哈希表的容量的乘积是决定是否重新hash的阈值。
TREEIFY_THRESHOLD=8: 使用树而不是链表的计数阈值。当桶的元素添加到具有至少这么多节点时,桶被转换为树。
UNTREEIFY_THRESHOLD=6: 用于在调整大小操作期间解除(拆分)桶的桶计数阈值。(untreeifying不是一个英语单词,这里理解为非树化,即转换成普通列表的过程).也就是说从树转换成普通的桶(链表)的阈值。
MAXIMUM_CAPACITY=1<<30: 最大的容量:
1<<30
,如果具有参数的任一构造函数隐式指定更高的值,则使用此参数。必须是2的n次方,小于等于1<<30MIN_TREEIFY_CAPACITY=64: 容器可以树化的最小容量(否则,如果bin中的节点太多,则会调整表的大小.)应该至少为 4 * TREEIFY_THRESHOLD,以避免调整大小和树化阈值之间的冲突.
类属性
table:
transient HashMap.Node<K,V>[] table
; table在首次使用时初始化,并根据需要调整大小。分配时,长度始终是2的幂。(我们还在一些操作中容忍长度为零,以允许当前不需要的自举机制)entrySet:
transient Set<Map.Entry<K,V>> entrySet
; 保存缓存的entrySet.size:
transient int size
; map中元素的数量。结构修改是那些改变HashMap中映射数量或以其他方式修改其内部结构(例如,rehash)的修改。此字段用于在HashMap的Collection-views上快速生成迭代器(见ConcurrentModificationException)
注意: 这些字段都是 transient
的? 为什么呢?
loadFactor:
final float loadFactor;
hash表的负载因子,在实例化hashTable的时候指定,该对象内不能变更(final);threshold:
int threshold;
, 下一次调整容器大小的阈值. threshold=capacity * load factor
HashMap的两种节点
基本的哈希桶的节点(链表的结点) Node
static class Node<K,V> implements Map.Entry<K,V>
它继承了Map的Entry,是对子类的行为规范。要求提供了getKey(),getValue()等常用方法。
链表节点的结构如下:
static class Node<K,V> implements Map.Entry<K,V> {
final int hash; // 避免重复计算key的hash值
final K key;
V value;
// 指向下一个节点的指针
HashMap.Node<K,V> next;
Node(int hash, K key, V value, HashMap.Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
@Override
public final K getKey() { return key; }
@Override
public final V getValue() { return value; }
@Override
public final String toString() { return key + "=" + value; }
// todo 没有找到在哪里使用了这个方法
@Override
public final int hashCode() {
return Objects.hashCode(key) ^ Objects.hashCode(value);
}
@Override
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
public final boolean equals(Object o) {
if (o == this)
return true;
if (o instanceof Map.Entry) {
Map.Entry<?,?> e = (Map.Entry<?,?>)o;
if (Objects.equals(key, e.getKey()) &&
Objects.equals(value, e.getValue()))
return true;
}
return false;
}
}
Tree的节点 TreeNode
static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V>
继承了其子类的Entry, 子类的Entry继承了父类的Node.注意了,这里乍一看还挺乱。来张图吧。
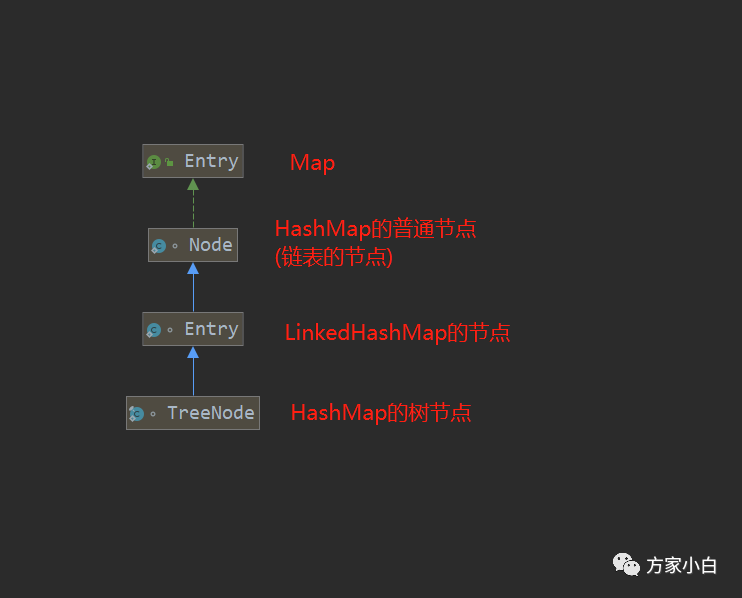
这里呢,TreeNode其实是Node的孙子, 也就是说HashMap的树节点是链表节点的孙子辈儿的。为什么要使两种节点有继承关系呢? 为什么TreeNode不直接继承Node节点呢?
static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> {
HashMap.TreeNode<K,V> parent; // red-black tree links
HashMap.TreeNode<K,V> left;
HashMap.TreeNode<K,V> right;
HashMap.TreeNode<K,V> prev; // needed to unlink next upon deletion
boolean red;
TreeNode(int hash, K key, V val, HashMap.Node<K,V> next) {
super(hash, key, val, next);
}
// 省略其他代码
}
这篇文章先说到这里,比较简单,我们介绍了HashMap的基本属性,常量字段,类字段,基本的两类节点,一定要理解这两类的节点的继承关系,否则到下面看增加,扩容的时候,就理解不会很透彻了。
下篇文章见喽。预警: 下一篇超长的!!!!
参考资料
poisson分布: http://en.wikipedia.org/wiki/Poisson_distribution



扫码关注
