




本期将分享近期全球知识图谱相关
行业动态、论文推荐
2022大数据十大关键词

由中国信息通信研究院、中国通信标准化协会指导,中国通信标准化协会大数据技术标准推进委员会主办的“2022大数据产业峰会”近日在京举办。会上,中国信通院云大所所长何宝宏发布「2022大数据十大关键词」,对大数据行业的最新发展趋势进行了总结与分析。
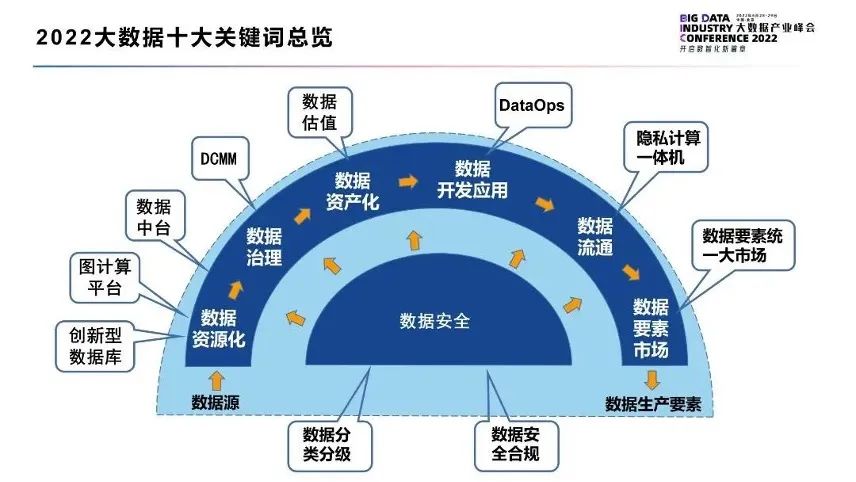
关键词之一:图计算平台助力大规模图数据资源化
图数据与传统行列式数据不同,它通过点、边模型,高效描述实体、属性、关系的数据模型,近年来被广泛用于企业智能营销风控等必要数据应用中。随着行业数据智能转型的深入,图数据在数据总量中的比例也正在快速上升。Gartner预计,到2025年图技术在数据和分析创新中的占比将从2021年的10%上升到80%。
随着图数据规模的变大,开启了图数据的“大数据”时代,起源于80年代的传统关系型数据库,以及起源于2000年左右的专用图数据库已经无法支撑大规模图数据的高效存储与计算。
图计算平台通过抽象计算层和集成层,在图数据库基础上增强了兼容性和大规模数据计算能力,实现了多种存储介质中图数据的高效汇聚以及多跳情况下的复杂计算能力。
目前该领域政策扶持力度不断加大,开源体系发展迅猛,商用产品层出不穷,从而快速支撑了图数据这一重要要素类型的价值释放。
Galaxybase免费版发布会
7月19日下午2点Galaxybase图数据库免费版正式发布

美通社报道预计到 2028 年全球图数据库行业预计将达到 81 亿美元

美通社报道,到2028 年,全球图形数据库市场规模预计将达到81 亿美元,在预测期内以 22.2% 的复合年增长率增长。
COVID-19的爆发给世界各地的各个经济体造成了严重的衰退。新型冠状病毒的爆发减缓了全球众多企业的发展。此外,由于感染的迅速传播,世界各国政府被迫在全国范围内实施封锁。
由于封锁期间的旅行限制,各种商品以及中间商品的供应链受到严重干扰。此外,封锁还对全球各种制造设施造成了相当大的阻碍。此外,COVID-19 的爆发暴露了各个垂直领域的商业模式缺陷,随着云、分析、人工智能、物联网和区块链等技术的使用和整合在整个地区激增,它还为企业在地域之外扩展和数字化提供了各种机会锁定时间。市场增长因素
对能够处理低延迟查询的解决方案的需求不断增长
图数据库服务和工具在世界范围内得到广泛使用,以至于一些传统数据库提供商正试图将图数据库模式集成到他们流行的关系数据库基础设施中。虽然该策略在理论上可能看起来可以节省资金,但实际上它可能会减慢并降低针对数据库运行的查询的性能。就数字业务活动而言,图形数据库正在将传统的实体业务转变为数字业务强国。当涉及到在数据库中存储大量连接数据时,公司面临着不适合手头任务的问题。开放知识网络的出现
知识网络必须具有数据集、方法和文档,以确保跨应用程序的可访问性,支持知识密集型应用程序,并链接众多学科以创建跨域知识网络。生物识别、家庭环境、患者健康历史和实时行为都是高级患者护理和监测等应用所必需的。除了用于医疗保健的个性化知识图谱外,知识网络还可以互连从多个来源收集的多模式跨域数据和信息。这个信息网络中的某些知识图谱仍然是专有的,大学或研究人员使用通常非常昂贵。市场制约因素
虽然从技术上讲,图数据库是 NoSQL 数据库,但实际上它们必须在单个服务器上运行,因为它们不能分布在低成本的集群中。这就是导致网络性能迅速恶化的原因。另一个潜在的缺点是开发人员必须用 Java 编写查询,因为没有 SQL 可以从图形数据库中检索数据,因此需要聘请昂贵的程序员。或者,开发人员可以使用 SparcQL 或为支持图形数据库而开发的其他查询语言之一,但这需要学习新技能。结果,图形数据库系统缺乏标准化和编程便利性。有图形数据库的可视化工具,尽管它们仍处于开发的早期阶段。
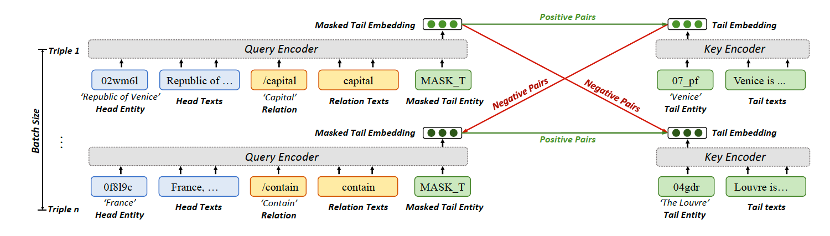
本周推荐的工作是近期发布于arxiv上的文章:Language Models as Knowledge Embeddings,提出了一个使用语言模型生成知识图谱表示的框架LMKE,作者是来自复旦大学的肖仰华教授等。

知识图谱近年来在信息检索、推荐系统、智能问答等任务中应用广泛,这其中知识表示发挥了不可或缺的作用。知识表示致力于将知识图谱映射到低维向量空间,可以分为传统的基于图结构的方法和近年来基于描述文本的方法,但是现有方法存在难以处理长尾实体、缺乏有效的负采样策略、过于依赖描述文本等问题。
为此,本文提出LMKE,一种利用语言模型生成知识表示的方法,致力于应对现有的基于描述文本的知识表示方法的两个局限。一方面,把实体及其描述文本输入预训练语言模型得到其嵌入表示,可以利用语言模型中的隐式知识,且对没有描述文本的实体也同样适用;另一方面,本文提出了一个如下图所示的对比学习框架,将给定的实体-关系对和目标实体分别充当对比学习中的query和key,只在小批次中进行负采样,有效降低了负采样开销。
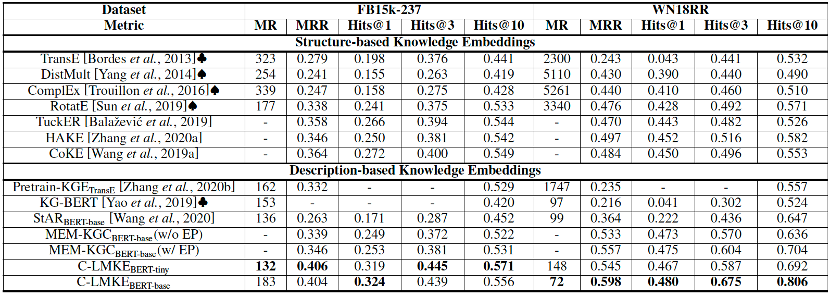
文章在FB15K-237和WN18RR等数据集上进行链接预测的实验,充分证明了本文方法的有效性。
文章的数据集和代码等已经开源,感兴趣的读者可以关注:https://github.com/Neph0s/LMKE。
更多链接
内容:代雪佩、肖欣、袁玮鸿、薛冰聪、王图图
编辑:王图图
排版:王图图

诚邀您加入我们的gStore社区,我们将在群内解决使用问题,分享最新成果~
请在微信公众号图谱学苑发送“社区”入群~或扫码入群



免责声明:本文全部内容均来源于网络开放信息整理,如有侵权,请联系删除
