




最近几年参加过开放基础设施峰会的人肯定听说过第一个超级用户奖的获得者CERN(欧洲核子研究中心)。
几年来,CERN IT数据中心中部署的所有物理服务器都是OpenStack私有云产品的一部分,使用Nova和Ironic。最初只有几个测试节点,现在已经发展到5000多台物理机,目标是大约10000个节点。
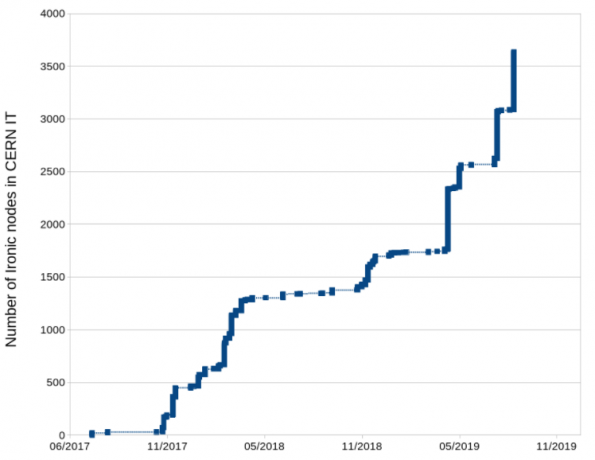
CERN的Nova和Ironic部署
CERN重度使用OpenStack,早在2013年就在生产中部署了OpenStack,大约8500个计算节点,拥有30万个内核,在大约80个单元中部署了3.5万个实例。此外,部署了三个区域,主要是为了扩展性和简化新功能的推出。
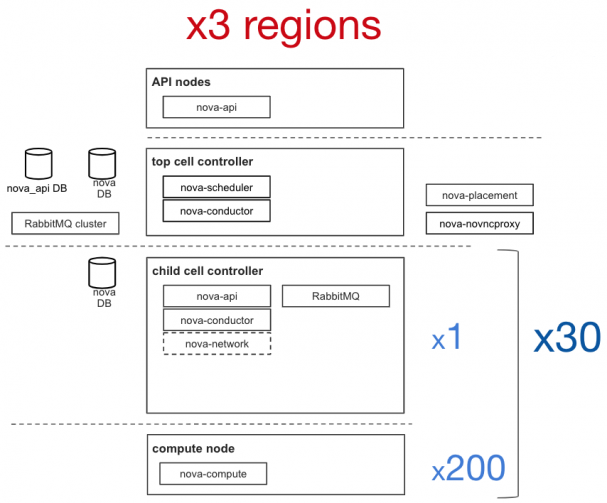
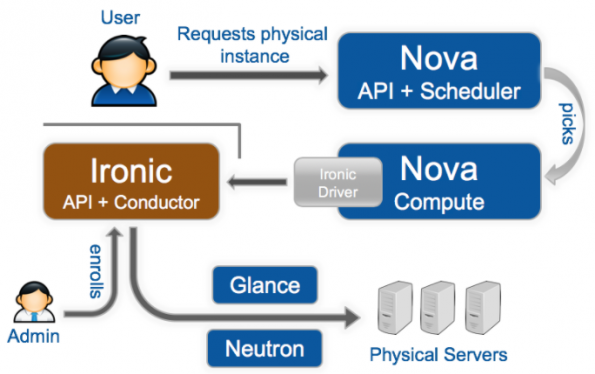
使用Nova和Ironic扩展裸金属时的问题和解决方案
当用Nova和Ironic将裸金属部署扩展到几千个节点时,遇到了三个主要问题:控制器崩溃、API响应性、资源发现。
问题1:控制器崩溃
CERN云基础设施团队为Ironic使用iscsi部署接口。这意味着部署时节点将iscsi设备导出到控制器,然后控制器将从Glance下载的镜像转储到该节点上。(请注意,此部署接口将在将来被弃用,因此应改用direct部署接口。)
对于部署,由于镜像是通过控制器进行“隧道”传输的,因此许多并行部署将使conductor出现内存不足(OOM)的情况。结果,控制器会崩溃,使节点处于错误状态。
为了解决这个问题,CERN水平扩展了控制器,并引入了“wing”控制器来处理请求。另一种解决方案是使用可扩展的部署接口,例如direct或ansible,让节点直接下载镜像。
问题2:API响应性
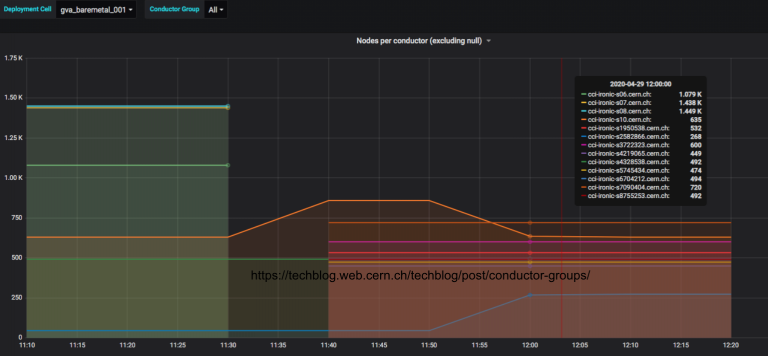
在扩展基础设施时,CERN注意到所有涉及数据库的请求都很慢。查看请求日志,发现inspector作为在控制器上运行的另一个组件,每60秒获得一个所有节点的列表来清理它的数据库。此外,当有1000个节点时,CERN禁用了分页,这意味着每个到API的请求都将所有节点集合在一个巨大的请求中,并试图将其返回给请求者。
为了解决这个问题,CERN重新启用了分页,并将同步间隔从60秒改为1小时。你可以从下图中看到此解决方案如何影响响应时间。为了更具可扩展性,CERN引入了“Inspector Leader Election”,这是CERN与上游一起开发的,现已部署到生产中。Inspector Leader Election将在Victoria版本中提供。
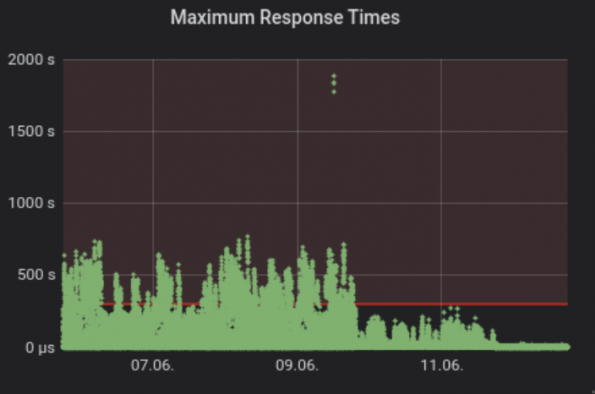
问题3:资源发现
在增加Ironic管理的物理节点数量时,CERN面临的另一个问题是在每个nova计算中运行的资源跟踪器(RT)向Placement报告所有可用资源所需的时间。从下面的图表中,你可以看到CERN专用裸金属单元的原始OpenStack Nova和CERNIronic设置。
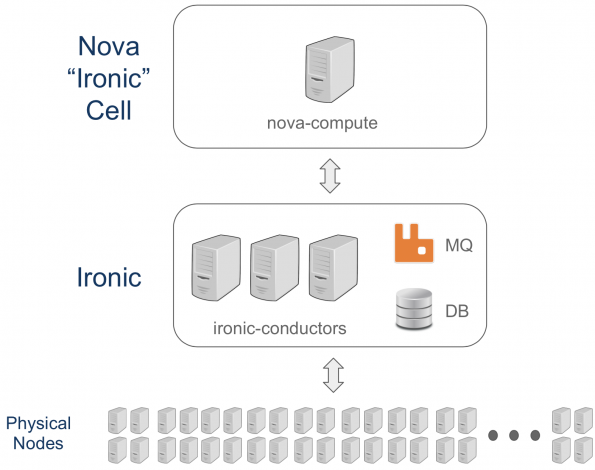
Ironic有一个专用的Nova单元,这是划分和管理基础设施的标准方法。在专用的Nova单元中,只有单元控制平面、nova-conductor、RabbitMQ和nova-compute。这个nova-compute负责Nova和Ironic之间使用Ironic API的所有通信。可以基于哈希环并行运行几个nova-compute来管理节点,但是当测试这个功能时,发现了几个问题。
由于只有一个nova-compute与Ironic交互,而RT需要报告所有Ironic资源,因此当Ironic中的资源数量增加时,RT周期需要很长时间。事实上,CERN花了3个多小时才完成部署(大约有5000个节点)。在RT周期中,所有用户的操作都将排队,直到所有资源都被更新。这造成了糟糕的用户体验,因为创建新资源需要几个小时。
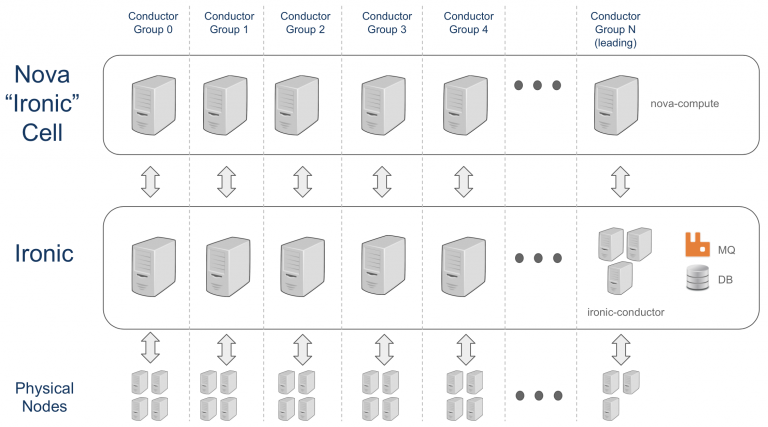
conductor groups
为了在Ironic中拥有故障域并允许分割基础设施,在Ironic和Nova的Stein版本中引入了一个新功能。它被称为“conductor groups”。conductor groups是一组物理节点和一组(一个或多个)管理这些物理节点的Ironic conductors之间的关联。这种关联减少了conductor要处理的节点数,这是扩展部署的关键。
配置
Ironic的配置文件”ironic.conf“中配置了Ironic conductor负责的conductor group:
[conductor] conductor_group = MY_CONDUCTOR_GROUP
接下来,需要将每个Ironic资源映射到选定的conductor group,这可以在Ironic API中完成。
openstack baremetal node set --conductor-group "MY_CONDUCTOR_GROUP" <node_uuid>
最后,每个nova-compute节点组需要配置为只管理一个conductor group。这是为每个“nova compute”节点在Nova的配置文件“nova.conf”中完成的:
[ironic]partition_key = MY_CONDUCTOR_GROUPpeer_list = LIST_OF_HOSTNAMES
现在,每个conductor group有一个nova-compute,你可以在下面的图中看到部署的样子。
过渡步骤
CERN是如何部署conductor group的?下面的过渡步骤总结自CERN的一篇博客《Scaling Ironic with Conductor Groups》。
——Nova compute和Ironic服务已停止,因为数据库将手动更新。
——用conductor group的名称更新Ironic和Nova配置文件。
——更新Ironic“节点”表,将conductor group映射到节点。
——更新Nova“compute\u nodes”和“instances”表,以设置用于conductor group的新Nova compute。
——最后,重新开始所有服务。
对Resource Tacker(RT)周期时间的影响
在下图中,你可以看到每个conductor group的Placement请求数。因此,RT周期时间现在只需要15分钟就可以完成,而不是以前的3小时,因为它现在被conductor group的数量划分。
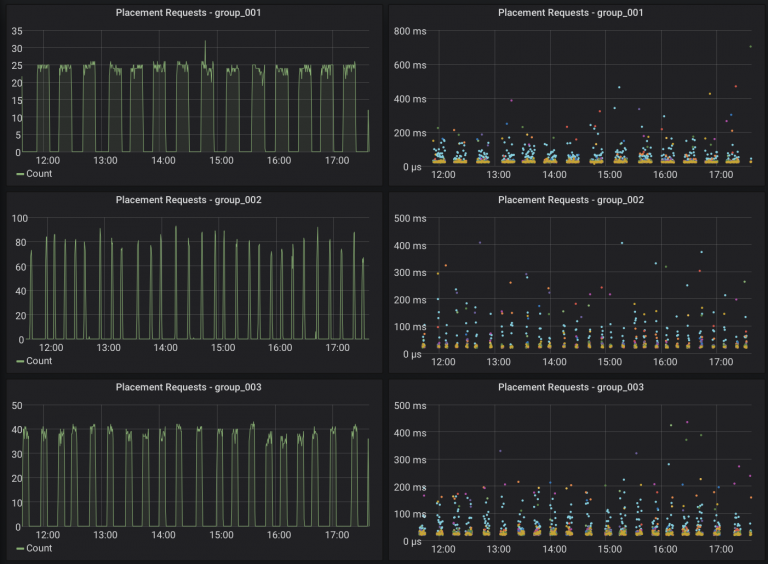
每个conductor group的资源数
我们如何决定每个conductor group的资源数量?RT周期时间随资源数线性增加。在CERN的部署中,管理和RT周期时间之间的折中是每个conductor group大约500个节点。当添加conductor group时,部署会水平扩展。
结论与展望
扩展基础设施是一个永恒的挑战!通过引入conductor group,CERN云基础设施团队能够将这种锁定分开,并将有效锁定时间从3小时减少到15分钟(在“leading”小组中甚至更短)。
但是,仍有一些问题尚未解决,可能还会出现新的问题。必须记住,良好的监控是发现和理解问题的关键。
原文链接:
Scaling Bare Metal Provisioning with Nova and Ironic at CERN: Challenges & Solutions - Superuser (openstack.org)


