




在自动化巡检中,我们需要生成几个图形,直观反映数据库性能、表空间、逻辑读、物理读趋势等。dbtime的曲线图就是其中一只,dbtime可以反馈数据库在各个时段的繁忙程度,绘制一个张dbtime曲线图,可以很好地了解数据库繁忙程度。
话不多说,开始。
第一步:安装pyecharts
目前可下载的最新版本为1.9.0:
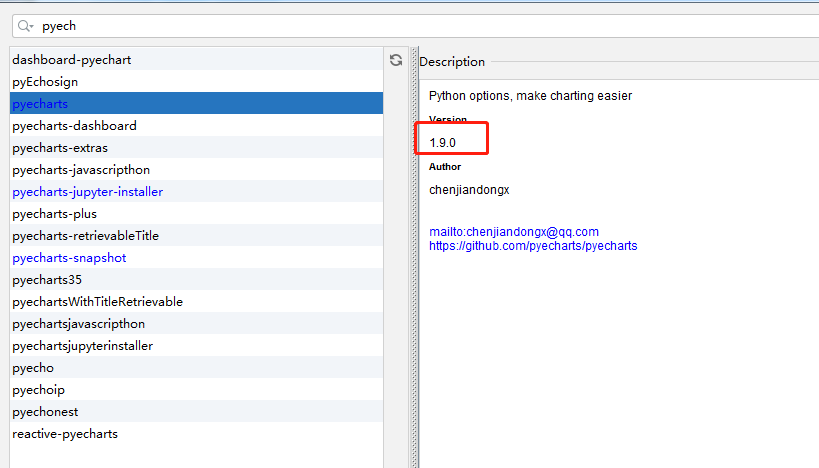
本程序是基于pycharts 的1.9.0开发。
pyecharts是基于python非常好的图标插件,相信信息可以参考:
https://pyecharts.org/#/zh-cn/intro
本次我们用到折线图,效果如下:

该折线图上,反映了数据库实例平均dbtime/s及最大、最小dbtime。dbtime/s在awr中是反应数据库压力的一个重要指标。
第二步:采集数据库dbtime
用每个dba自己喜欢的形式采集dbtime数据,我用的脚本如下:
select a.instance_number,to_char(end_interval_time,'yyyy-mm-dd-hh24:mi') start_time,
round((CASE
when round((b.value-a.value)/1000000/
round((to_date(to_char(c.END_INTERVAL_TIME, 'yyyy-mm-dd hh24:mi:ss'),
'yyyy-mm-dd hh24:mi:ss') -
to_date(to_char(c.BEGIN_INTERVAL_TIME,
'yyyy-mm-dd hh24:mi:ss'),
'yyyy-mm-dd hh24:mi:ss')) * 24 * 60,
2),2)< 0 then
0
else
round((b.value-a.value)/1000000/
round((to_date(to_char(c.END_INTERVAL_TIME, 'yyyy-mm-dd hh24:mi:ss'),
'yyyy-mm-dd hh24:mi:ss') -
to_date(to_char(c.BEGIN_INTERVAL_TIME,
'yyyy-mm-dd hh24:mi:ss'),
'yyyy-mm-dd hh24:mi:ss')) * 24 * 60,
2),2)
end)/(round((to_date(to_char(c.END_INTERVAL_TIME, 'yyyy-mm-dd hh24:mi:ss'),'yyyy-mm-dd hh24:mi:ss')
- to_date(to_char(c.BEGIN_INTERVAL_TIME,'yyyy-mm-dd hh24:mi:ss'), 'yyyy-mm-dd hh24:mi:ss')) * 24 * 60,2)),2)
"dbtime/s",
a.SNAP_ID,
a.con_id
from cdb_hist_sys_time_model a,cdb_hist_sys_time_model b ,cdb_hist_snapshot c
where a.stat_name='DB time' and b.stat_name='DB time'
and a.dbid=b.dbid and a.dbid=(select dbid from v$database)
and a.instance_number= b.instance_number and c.instance_number=b.instance_number
and a.snap_id=c.snap_id
and b.snap_id=c.snap_id+1
and C.END_INTERVAL_TIME>=sysdate-7
order by a.instance_number,a.SNAP_ID asc;
采集的到的样式如下:
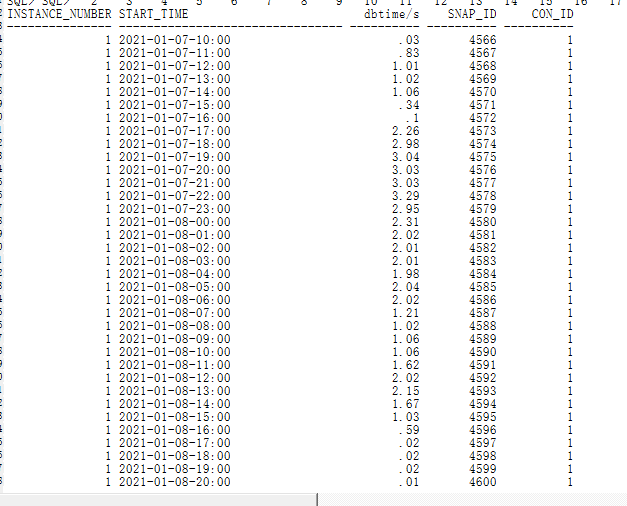
INSTANCE_NUMBER是实例号,START_TIME是snap开始时间,dbtime/s是每秒的dbtime,snap_id及con_id是snap编号及pdb编号(12c以下版本无con_id,可以将去掉该字段,同时把视图中的cdb改成dba即可。)
第三步:编写python代码
(1)遍历有几个实例
有几个实例,绘制几条线:
number = []
for lss in lines:
m = lss.replace('\n', '')
if len(lss)>10:
inst_id = lss.split()[0]
if inst_id not in number:
number.append(inst_id)
将遍历出的实例编号放到number中,然后以nunber为外层循环,逐层读取START_TIME及dbtime/s,START_TIME数据做x轴,dbtime/s数据库做y轴线。
(2)读取x轴、y轴数据到list中
将时间及cost对应读取到list中,样式如下:
{‘time_id’: ‘2021-01-07-10:00’, ‘cost’: ‘.03’}
ALL_DATA = []
# 初始化图形组件
line = Line()
for j in range(len(number)):
inst_id_w = number[j]
for lss in lines:
lss = lss.replace('\n', '')
inst_id_n = lss.split()[0]
if inst_id_w == inst_id_n:
time_id = lss.split()[1]
cost = lss.split()[2]
ALL_DATA.append({"time_id": time_id, "cost": cost})
show_data = ALL_DATA
这里,我们用二维数组以key-value的方式存放了dbtime数据。方法中用到的关键函数就是split函数,用空格分割字符串,分割后,第一个字段为实例号,第二个字段是时间,第三个是dbtime/s,第四个是snap,第五个是con_id.
然后从这个list中,分别提取x轴、y轴数据:
data_time_x = list(map(lambda ALL_DATA: ALL_DATA["time_id"], show_data))
data_dbtime_y = list(map(lambda ALL_DATA: float(ALL_DATA["cost"]), show_data))
当然,可以定义两个不同的list,这样分别给x,y轴赋值,就不用这么麻烦了。
(3)赋值x轴,y轴数据
line.add_xaxis(data_time_x)
line.add_yaxis(f'实例{inst_id_w}', data_dbtime_y, is_selected=True)
line.set_global_opts(title_opts=opts.TitleOpts(title=f"{dbname}库DBTIME变化趋势图",
subtitle='DBTIME 通过与cpu及时间的比较,计算数据库的繁忙程度'),
xaxis_opts = opts.AxisOpts(
splitline_opts=opts.SplitLineOpts(is_show=True)
), # 设置x轴
yaxis_opts = opts.AxisOpts(
splitarea_opts=opts.SplitAreaOpts(is_show=True, areastyle_opts=opts.AreaStyleOpts(opacity=1))
), # 设置y轴
toolbox_opts = opts.ToolboxOpts(is_show=True),
)
line.set_series_opts(
markpoint_opts=opts.MarkPointOpts(
data=[
opts.MarkPointItem(type_="max", name="最大值"),
opts.MarkPointItem(type_="min", name="最小值"),
]),
markline_opts=opts.MarkLineOpts(
data=[
opts.MarkLineItem(type_="average", name="平均值"),
]
),
)
ALL_DATA = [] #本次循环完成后,将ALL_DATA 数据清空,防止已有数据干扰下一个实例
(4)生成图片
图片有两种方式生成,一种是html形式,一种是gif形式,期中gif形式用于自动巡检报告,作为图片,可以自动插入到巡检报告中。
f_out = f'D:\\巡检自动化\\dbtime_list\sql_cost_line_{dbname}'
line.render(f'{f_out}.html')
make_snapshot(snapshot, line.render(), f'{f_out}.gif')
如果要将生成的图片插入到自动化巡检生成的word中,可以采用如下方式:
Docx.add_picture(f'D:\巡检自动化\dbtime_list\\sql_cost_line_{db_name}.gif', width=Inches(6.0),height=Inches(2.0))
这一部分设计到python对docx的操作,感兴趣的可以阅读笔者之前的文章。
(5)完整函数代码
最后,放送上“利用python生成ORACLE DBTIME曲线图并保存为图片”函数全部代码:
from pyecharts import options as opts
from pyecharts.charts import Line
from pyecharts.render import make_snapshot
from snapshot_selenium import snapshot
def show_db_time(str_dbtime,dbname):
# str_dbtime是传入的采集sql执行的全部结果,包括sql head等信息,因此会掐头、去尾
print('正在绘制dbtime趋势图,该趋势图反应数据库繁忙程度...')
lines = str_dbtime[0].splitlines()
lines = lines[4:len(lines)-4]
number = []
for lss in lines:
m = lss.replace('\n', '')
if len(lss)>10:
inst_id = lss.split()[0]
if inst_id not in number:
number.append(inst_id)
ALL_DATA = []
# 初始化图形组件
line = Line()
for j in range(len(number)):
inst_id_w = number[j]
for lss in lines:
lss = lss.replace('\n', '')
inst_id_n = lss.split()[0]
if inst_id_w == inst_id_n:
time_id = lss.split()[1]
cost = lss.split()[2]
ALL_DATA.append({"time_id": time_id, "cost": cost})
# 一个sql_id相关数据获取完成,开始画图
show_data = ALL_DATA
data_time_x = list(map(lambda ALL_DATA: ALL_DATA["time_id"], show_data))
data_dbtime_y = list(map(lambda ALL_DATA: float(ALL_DATA["cost"]), show_data))
#if i == 0:
line.add_xaxis(data_time_x)
# i = i +1
line.add_yaxis(f'实例{inst_id_w}', data_dbtime_y, is_selected=True)
line.set_global_opts(title_opts=opts.TitleOpts(title=f"{dbname}库DBTIME变化趋势图",
subtitle='DBTIME 通过与cpu及时间的比较,计算数据库的繁忙程度'),
xaxis_opts = opts.AxisOpts(
splitline_opts=opts.SplitLineOpts(is_show=True)
), # 设置x轴
yaxis_opts = opts.AxisOpts(
splitarea_opts=opts.SplitAreaOpts(is_show=True, areastyle_opts=opts.AreaStyleOpts(opacity=1))
), # 设置y轴
toolbox_opts = opts.ToolboxOpts(is_show=True),
)
line.set_series_opts(
# 设置系列配置
markpoint_opts=opts.MarkPointOpts(
data=[
opts.MarkPointItem(type_="max", name="最大值"),
opts.MarkPointItem(type_="min", name="最小值"),
]),
markline_opts=opts.MarkLineOpts(
data=[
opts.MarkLineItem(type_="average", name="平均值"),
]
),
)
ALL_DATA = []
f_out = f'D:\\巡检自动化\\dbtime_list\sql_cost_line_{dbname}'
line.render(f'{f_out}.html')
make_snapshot(snapshot, line.render(), f'{f_out}.gif')
if len(data_dbtime_y) > 0:
return data_dbtime_y
else:
return [0]
