




1. 检查支票帐户的余额高于20000元;
2. 从支票账户减去20000元;
3. 在储蓄账户余额中增加20000元;
以上三个步骤的操作必须打包在一个事务中,任何一个步骤失败,必须回滚所有步骤。为了解决这种问题,MySQL InnoDB 存储引擎支持事务操作,保证在一个事务中的操作要么都完成,要么都失败回滚。
什么是事务,事务特性有哪些?
事务就是一组相关联的原子性的 SQL 语句,事务内的语句要么全部执行成功,要么全部执行失败回滚,事务具有四大特性,分别是:原子性(atomicity)、一致性(consisitency)、隔离性(isolation)、持久性(durability);
| 事务特性 | 特点 |
| 原子性(Atomicity) | 一个事务必须被视为一个不可分割的最小工作单元,整个事务的所有操作要么全部提交成功,要么全部失败回滚,对于一个事务来说,不可能只执行其中的一部分操作,这就是事务的原子性; |
| 一致性(Consistency) | 数据库总是从一个一致性的状态转换到另一个一致性状态。从前面的例子中,一致性确保了在执行到过程3前,系统发生了崩溃,支票账户也不会损失20000元,因为事务没有提交,所以事务中所做的修改也不会保存到数据库中; |
| 隔离性(Isolation) | 通常来说,一个事务所做的修改在最终提交以前,对其他事务是不可见的,像前面的例子,事务A执行在步骤3时,本事务内支票余额减少了20000元,而事务B去查询时,支票余额并没有减少,这就是事务的隔离性,通常来说不同的事务未提交前是不可见的;当然也得看事务隔离级别; |
| 持久性(Durability) | 一旦事务提交,则其所做的修改就会永久保存到数据库中,即使系统崩溃,修改的数据也不会丢失。 |
| 隔离级别 | 说明 | 脏读可能性 | 不可重复读 | 幻读可能性 | 加锁读 |
| 未提交读 (READ UNCOMMITTED) | 事务中的修改,即使没有提交,对其他事务也都是可见的,事务可以读取未提交的数据,这也被为脏读(Dirty Read)。实际应用中一般很少使用; | yes | yes | yes | no |
| 提交读 (READ COMMITTED) | 大多数数据库系统的默认隔离级别都是READ COMMITTED(但MySQL不是),READ COMMITTED满足前面提到的隔离性的定义:一个事务开始时,只能看见已提交的事务所做的修改,换句话说,一个事务从开始直到提交前,所做的任何修改对其他事务都是不可见的。这个级别有时候也叫做不可重复读(nonrepeatable read),因为两次执行同样的查询,可能会得到不一样的结果;不可重复读是因为两次读取的结果有可能不一样; | no | yes | yes | no |
| 可重复读 (REPEATABLE READ) | REPEATABLE READ 解决了脏读的问题,该级别保证了同一个事务中多次同样读取,读取到的记录结果是一致的。但是理论上可重复读还是无法解决另一个幻读问题(Phantom Read)。所谓幻读指的是某个事务在读取某个范围内的记录时,另外的一个事务又在该范围插入了新的记录,当之前的事务再次读取该范围的记录时,会产生幻行(Phantom Row)。InnoDB存储引擎通过多版本并发控制(MVCC,Multiversion Concurrency Control)解决了幻读问题; | no | no | yes | no |
| 可串行化 (SERIALZABLE) | SERIALZABLE 是最高隔离级别,它是通过强制事务串行执行,避免前面的幻读问题,简单来说,SERIALZABLE 会在读取的每一行数据上都加锁,所以可能导致大量的超时和锁争用的问题。实际应用中,也很少使用这个隔离级别。 | no | no | no | yes |
读未提交(可以读取到未提交的事务数据)
读未提交是指可以读到其它事务未提交的数据,由于其实事务未提交,很有可能会回滚操作,此时如果读取了未提交的事务,并且也使用了读到的数据,就会出现脏数据的问题,即脏读;
MySQL [(none)]> set global transaction isolation level read uncommitted;
Query OK, 0 rows affected (0.00 sec)
| 操作顺序 | session A | session b | 备注 |
| 1 | 1. begin; 2. update test4 set name="k8svip" where id=1; | session A 事务中更新数据,并未提交事务 | |
| 2 | 3. select * from test4; | session B 中事务中直接,可以读取到事务A中未提交的数据,此时如果我使用了Session A 中未提交的数据,而此时Session A进行了回滚操作,就会造成脏读; | |
| 3 | 4. rollback; | session B 事务中已经使用了已回滚的事务,那结果肯定也是有问题的; |
读未提交示例截图:
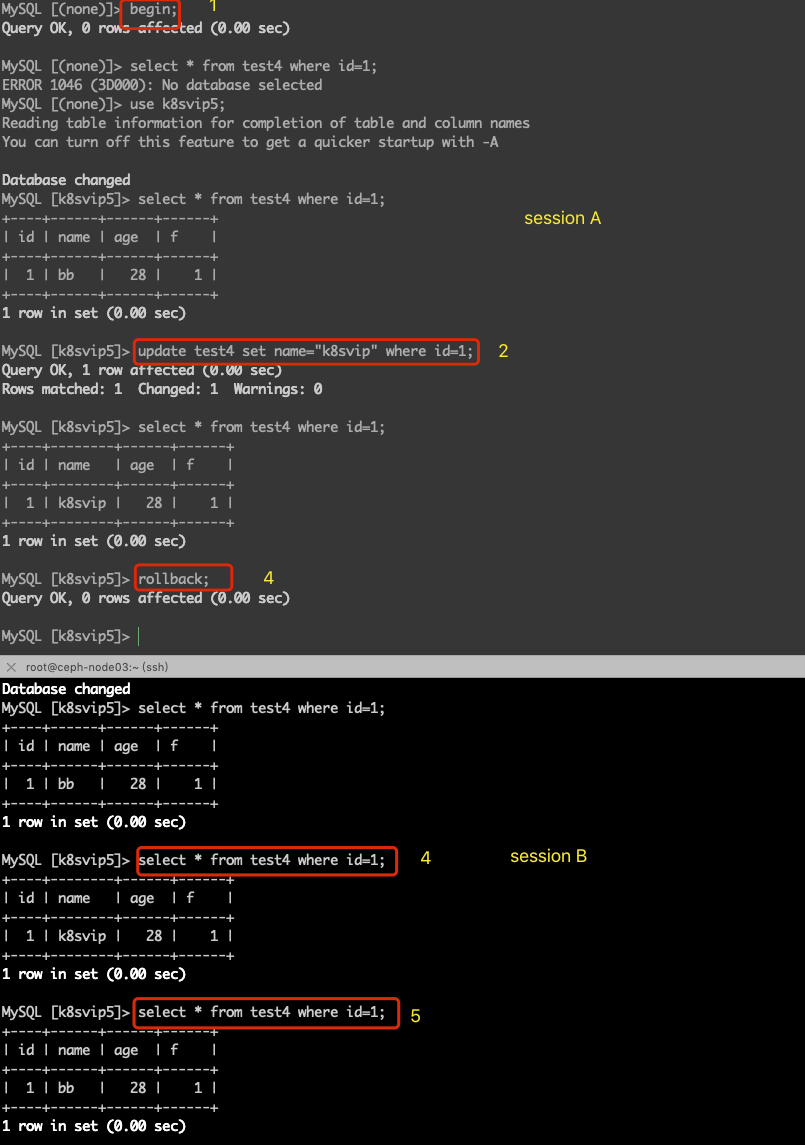
读提交(只能读取到事务提交的数据)
既然读未提交没办法解决脏读问题,那么就出现了读提交,它是指一个事务中,只读读取到其他事务已经提交过的数据,也就是其它事务调用commit命令之后的数据。在这个隔离级别中,就不会出现脏读的问题;
MySQL [(none)]> set global transaction isolation level read committed;
Query OK, 0 rows affected (0.00 sec)
| 操作顺序 | session A | session b | 备注 |
| 1 | 1. begin; 2. update test4 set name="k8svip" where id=1; 3. select * from test4; | session A 事务中更新数据,并未提交事务 | |
| 2 | 4. select * from test4; | session B中查看到的数据,都是原始数据; | |
| 3 | 5. commit; | session A 事务提交 | |
| 4 | 6. select * from test4; | session B中查看到事务A提交过的数据; |
读提交示例截图:
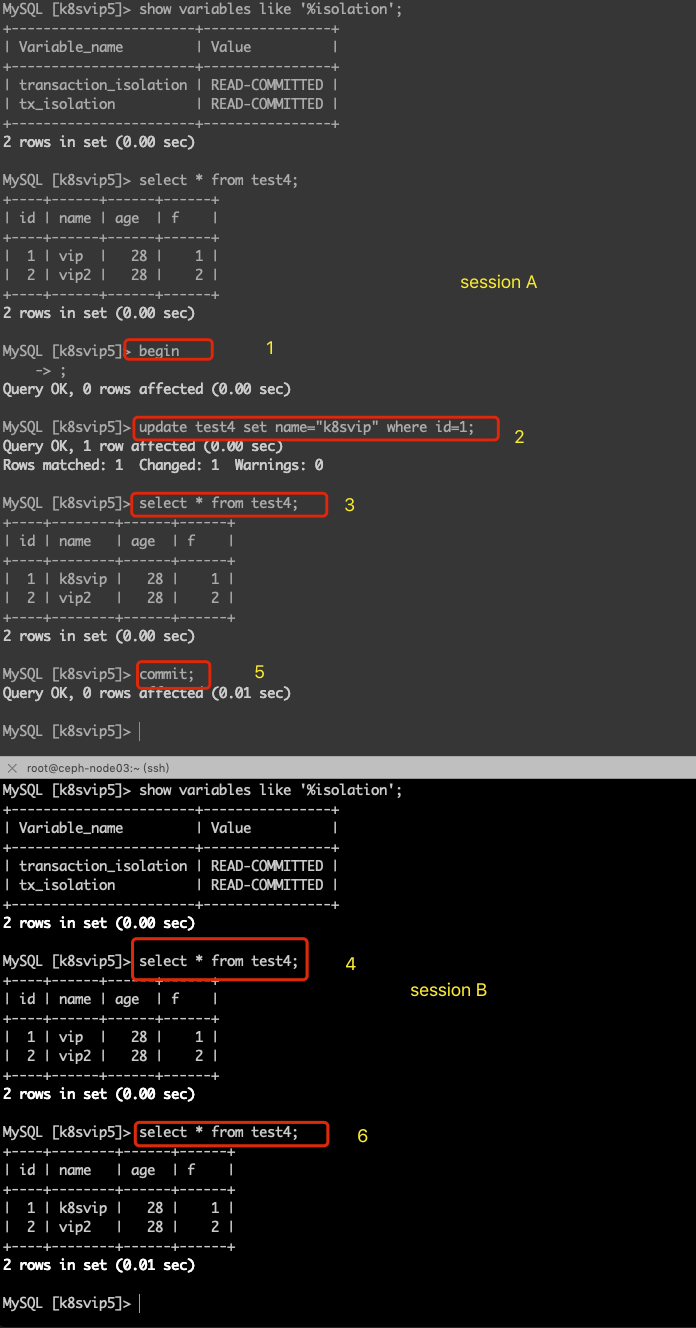
可重复读
可重复读指的即使其它事务已经提交了,此级别还是不可见其它事务已经提交的数据,可以重读开启事务时的快照。
可重复读是对比不可重复读而言的,上面说不可重复读是指同一事务不同时刻读到的数据值可能不一致,而可重复读是指,事务不会读到其他事务对已有数据的修改,即使其他事务已提交,也就是说在事务开始时读到的数据是什么,在事务提交前的任意时刻,这些数据值都是一样的。但是对于其他事务新插入的数据是可以读到的,这就是幻读问题;
MySQL [(none)]> set global transaction isolation level repeatable read;
Query OK, 0 rows affected (0.00 sec)
| 操作顺序 | session A | session b | 备注 |
| 1 | 1. begin; 2. select * from test4; | 1. begin; 2. select * from test4; | session A、B同时开启事务; |
| 2 | 3. update test4 set name="aaa" where id = 1; 4. select * from test4; | session A中做更新操作; | |
| 3 | 3. select * from test4; | session B 中查看 | |
| 4 | 5. commit; | ||
| 5 | 4. select * from test4; | 即使session A中事务已经提交,但session B中查看到的还是原来的;在事务退出之前,不会受其它事务是否提交的影响 ; | |
| 6 | commit; |
可重复读示例:
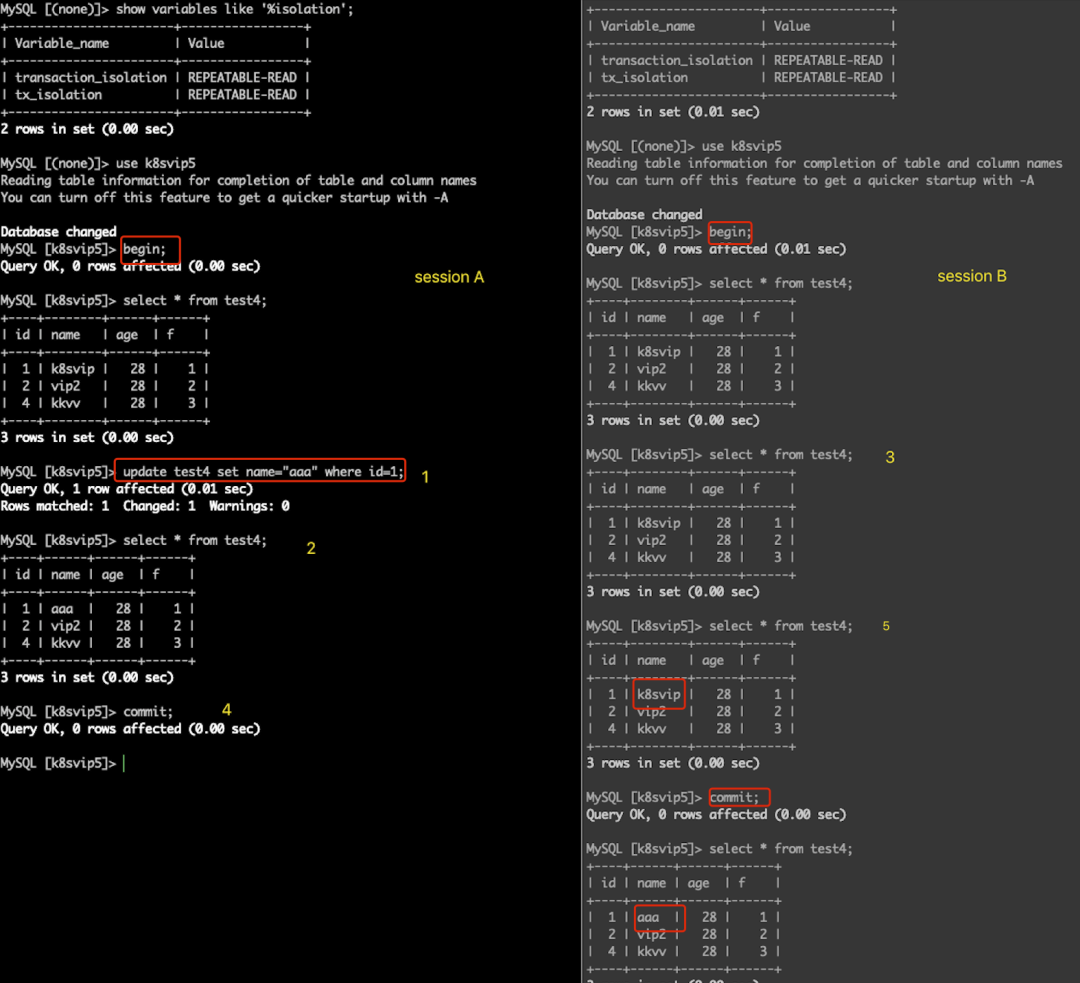
幻读
当在 MySQL 中测试幻读的时候,并不会出现之前定义中的情况,幻读现象并没有发生,这是转为MySQL 的可重复读隔离级别其实解决了幻读问题,这会在后面的内容说明。
| 操作顺序 | session A | session b | 备注 |
| 1 | 1. begin; 2. select * from test4; | 1. begin; 2. select * from test4; | sessoin A、B开启事务 |
| 2 | 3. update test4 set name="bb" where id = 1; 4. select * from test4; | session A中更新 | |
| 3 | 3. insert into test4(5,"cc",28,5); | session B中插入; | |
| 4 | 4. commit; | session B 中提交 | |
| 5 | 5. select * from test4; | session A中查看,并没有出现幻读现象。 | |
| 6 | 6. commit; |
幻读示例:
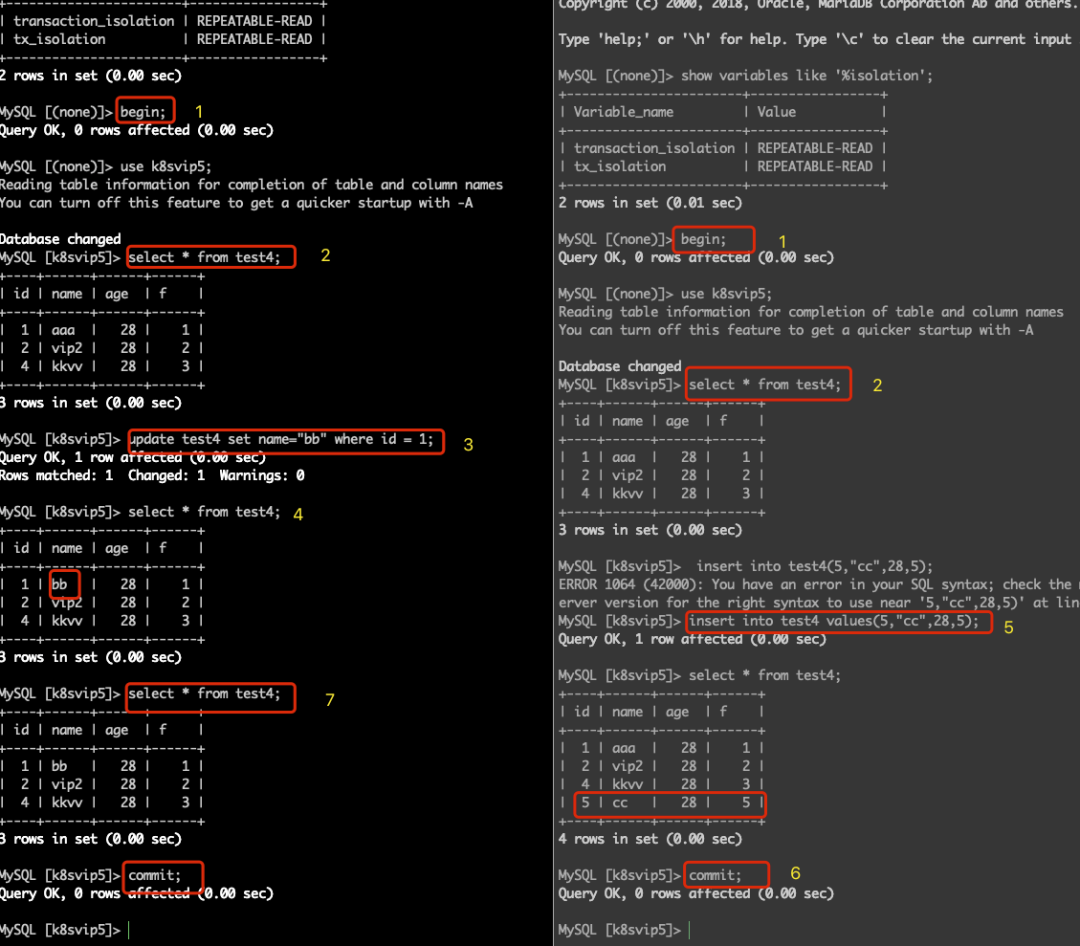
串行化
串行化隔离效果最好,解决了脏读、可重复读、幻读问题,但效率最低,因为事务的执行是串行执行,与其它隔离级别对比的话,其它的相当于多线程可同时执行,而串行化级别相当于单线程,后一个事务执行必须等待前一个事务结束。
MySQL 中如何实现事务隔离的?
首先:读未提交,性能好,存在脏读、不可重复读、幻读现象,根本就谈不上隔离,可以理解为没有隔离;
其次:串行化隔离级别,读的时候加共享锁,也就是其他事务可以并发读,但不能写;写的时候加排它锁,其它事务即不能读,也不能写;
最后,读提交与可重复读,这两种隔离级别比较复杂,下面详细讲解下。
可重复读如何实现的?
为了解决读提交、或者说是为了实现可重复读,MySQL 采用 MVCC(多版本控制)的方式来解决可重复读问题,在数据表中看到的一行记录可能实际上有多个版本,每个版本的记录除了数据本身外,还要有一个版本字段,记为row trx_id,而这个字段就是用来记录事务的ID,在事务开始的时候向事务系统申请,按时间顺序递增。
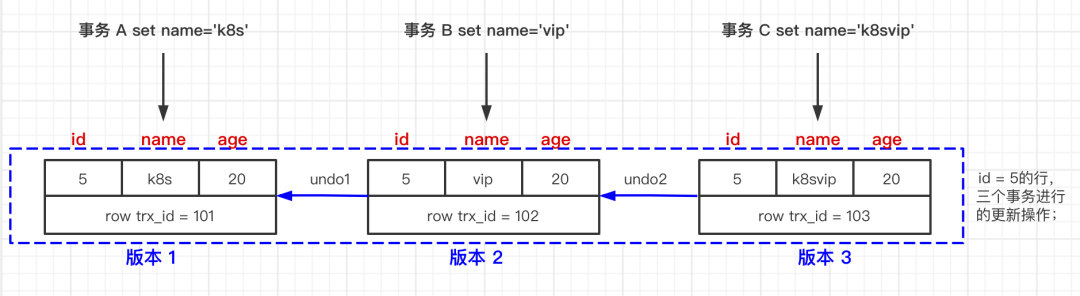
读提交和可重复读的时候有一个快照的概念,学名叫做一致性视图,这是可重复读与不可重复读的关键;可重复读是在一个事务开始的时候生成一个当前事务的全局性快照,而读提交则是每次执行语句都重新生成一次快照;
对于一个快照来说,它能够读到那些事务版本的数据,需要新遵循以下规则:
1. 当前事务内的更新,可以读到;
2. 当前事务版本未提交,不能读到;
3. 当前版本事务A已提交,但是其它事务B的快照,是在快照(事务B的快照)创建后提交(事务A提交)的,不能读到;(可重复读,解决不可重复读);
4. 当前版本事务已提交,是在其它事务快照创建前提交的,可以读到。
读提交和可重复读的区别就在创建快照的机制上面,读提交每执行一条语句的时候,都要重新创建一次快照,而可重复读是在事务开始时,一次创建,直到事务结束。
并发写问题是如何通过行锁解决的?
事务A 更新表A中的id=1的行,事务B也进行更新表A中的id=1的行,但事务A未commit,事务B就会等待,此时的锁机制是怎么样的?如何加锁的
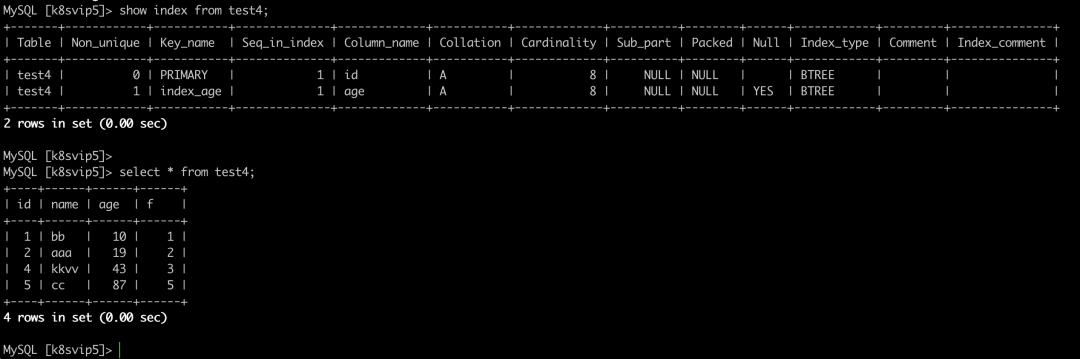
加锁过程分有索引和无索引两种情况,例如 update test4 set name="k8svip" where id=1; id是索引列,那么MySQL就在索引中直接找到这行数据,直接对行加锁即可。而如果是 update test4 set name="k8svip" where age=18; 而age不是索引列的时候,MySQL就无法定位到这行数据,那怎么处理呢?InnoDB也不是给表表锁,而是会把这张表中的所有行加行锁,但是呢,加上行锁后,MySQL 会进行一次遍历过滤,发现不满足的行就释放锁,最终只保留符合条件的行,虽然最终只为符合条件的行加了行锁,但是这一锁一释放的过程对大表的性能影响极大,大表的话,还是建议合理建立索引。
幻读是通过间隙锁解决的?
并发写问题,是通过行锁解决的,而解决幻读问题使用的方式也是锁--间隙锁,MySQL 把行锁和间隙锁合并在一起,解决了并发写和幻读的问题,这个锁叫做Next-key锁。例如表数据如下
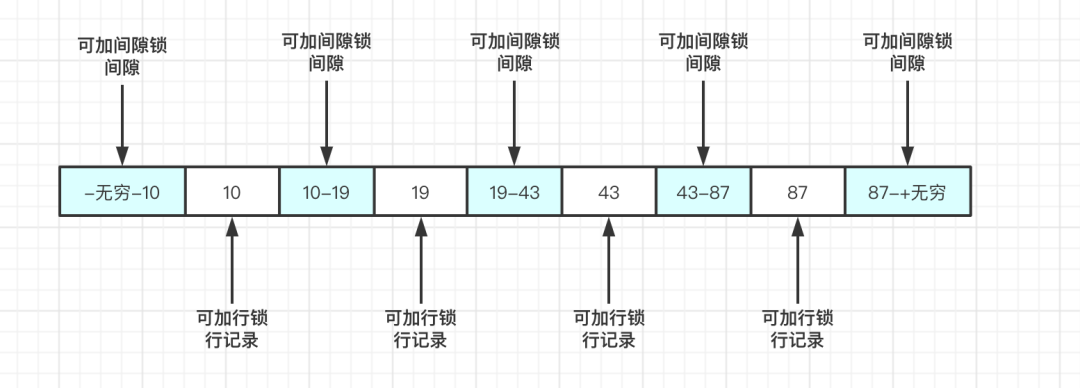
| 操作顺序 | session A(age=19决定上下间隙) | session B(操作10-19间隙) | session C(操作19-43间隙) | 备注 |
| 1 | 1. begin; | 1. begin; | 1. begin; | |
| 2 | 2. select * from test4; | 2. select * from test4; | 2. select * from test4; | |
| 3 | 3. update test4 set name="aaa" where age=19; | |||
| 4 | 3. insert into test4(name,age,f)values("a8",8,8); | 3. insert into test4(name,age,f)values("a8",45,8); | 间隙外都可插入成功 | |
| 5 | 4. insert into test4(name,age,f)values("a5",15,8); | 4. insert into test4(name,age,f)values("a54",40,8); | 间隙内不可操作 | |
| 6 | 4. commit; |
间隙锁示例:
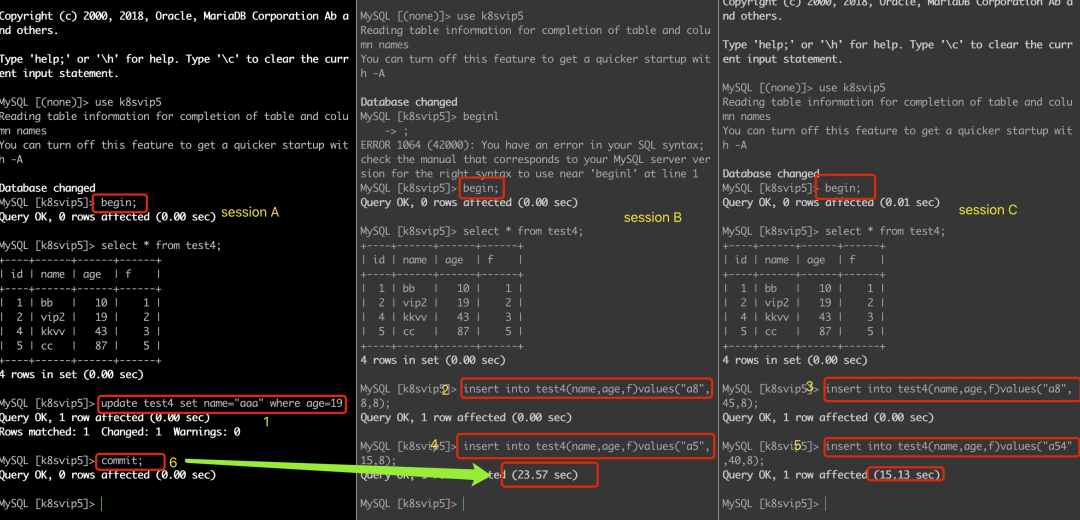
以上实验age是有索引的情况,如果 age 不是索引列,那么数据库会为整个表加上间隙锁。所以,如果是没有索引的话,所有可加间隙锁的地方,都会加上间隙锁。
总结
MySQL 事务隔离性比较复杂,详细总结下事务隔离级别:读未提交,基本不会使用,会产生脏读问题,读提交解决了脏读问题,但未解决可重复读问题,可重复读级别解决了幻读问题,是通过行锁和间隙锁的组合 Next-Key 锁实现的,行锁解决了并发问题。
您的关注是我写作的动力
文章推荐
讲讲 tcp_tw_recycle,tcp_tw_reuse
基础小知识
专辑分享
kubeadm使用外部etcd部署kubernetes v1.17.3 高可用集群
第一篇 使用 Prometheus 监控 Kubernetes 集群理论篇
参考:《高性能MySQL》

