大数据技术之ClickHouse
1.数据库
1.1 数据库设计
数据库类型
•数据库设计的一个根基就是要弄清楚数据库的类型。
•当今的数据处理大致可以分成两大类:
–联机事务处理OLTP(on-line transaction processing在线事务处理,联机事务处理)
–联机分析处理OLAP(On-Line Analytical Processing在线分析处理,联机分析处理)
•OLTP是传统的关系型数据库的主要应用,主要是基本的、日常的事务处理,例如银行交易。
•OLAP是数据仓库系统的主要应用,支持复杂的分析操作,侧重决策支持,并且提供直观易懂的查询结果
•联机分析处理(OLAP,On-line Analytical Processing),数据量大,DML少。使用数据仓库模板
•联机事务处理(OLTP,On-line Transaction Processing),数据量少,DML频繁。使用一般用途或事务处理模板
1.2 OLAP 存储系统设计技术探讨
•一个专门用来做 OLAP 分析的存储引擎该如何设计
•如何在海量数据中,针对大量数据进行查询分析呢?
•核心需求是 实现海量数据集中的高性能、低延迟查询分析功能,一些常见的方案和手段如下
01、数据排序
02、数据分区分片 + 分布式查询
03、列式存储 + 字段类型统一
04、列裁剪
05、预聚合(搜索引擎:输入关键词,搜索引擎根据关键词到 数据库 找到这个 关键词对应的所有的 URL:这些 URL 就是提前计算出来的 )
06、利用CPU特性:向量化引擎,操作系统必须支持
07、主键索引 + 二级索引 + 位图索引 + 布隆索引 等等各种索引技术
08、支持近似计算, pv 一个电商平台的 sku 总数
09、定制引擎:多样化的存储引擎满足不同场景的特定需要
10、多样化算法选择:Volnitsky高效字符串搜索算法 和 HyperLogLog基于概率高效去重算法
1.3 ClickHouse数据库
•ClickHouse是一个用于联机分析(OLAP)的列式数据库管理系统(DBMS)。
2.ClickHouse 底层引擎详解
2.1 ClickHouse 库引擎
•ClickHouse 也支持在创建库的时候,指定库引擎,目前支持 5 种,分别是:Ordinary,Dictionary, Memory, Lazy,MySQL
•其实 Ordinary 是默认库引擎,在此类型库引擎下,可以使用任意类型的表引擎
1、Ordinary引擎:默认引擎,如果不指定数据库引擎创建的就是 Ordinary 数据库
2、Dictionary引擎:此数据库会自动为所有数据字典创建表
3、Memory引擎:所有数据只会保存在内存中,服务重启数据消失,该数据库引擎只能够创建 Memory 引擎表
4、MySQL引擎:改引擎会自动拉取远端 MySQL 中的数据,并在该库下创建 MySQL 表引擎的数据表
5、Lazy延时引擎:在距最近一次访问间隔 expiration_time_in_seconds 时间段内,将表保存在内存中,仅适用于 Log 引擎表
2.2 ClickHouse 表引擎
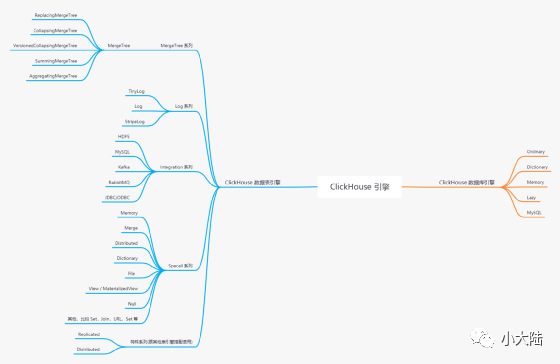
•ClickHouse 的表引擎提供了四个系列(Log、MergeTree、Integration、Special)大约 28 种表引擎,各有各的用途。比如
–Log 系列用来做小表数据分析,
–MergeTree 系列用来做大数据量分析,
–而 Integration 系列则多用于外表数据集成。
–Log、Special、Integration 系列的表引擎相对来说,应用场景有限,功能简单,应用特殊用途,
–MergeTree 系列表引擎又和两种特殊表引擎(Replicated,Distributed)正交形成多种具备不同功能的 MergeTree 表引擎
•MergeTree 作为家族中最基础的表引擎,提供了主键索引、数据分区、数据副本和数据采样等基本能力,而家族中其他的表引擎则在 MergeTree 的基础之上各有所长
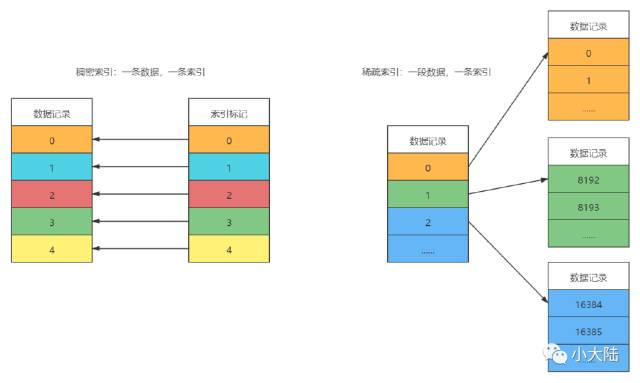
–MergeTree 主键索引,是 稀疏索引
•稠密索引:一条数据创建一条索引
•稀疏索引:一段数据创建一条索引
3.ClickHouse工作原理
•MergeTree 表引擎的内部工作细节!最终就是告诉你:为什么 clickhouse 做查询分析,那么快?
•ClickHouse 从 OLAP 场景需求出发,定制开发了一套全新的高效列式存储引擎,并且实现了数据有序存储、主键索引、稀疏索引、数据 Sharding、数据Partitioning、TTL、主备复制等丰富功能。这些功能共同为 ClickHouse 极速的分析性能奠定了基础。
•核心功能原理如下:
–clickhouse 数据分区
–clickhouse 列式存储
–clickhouse 一级索引 主键索引
–clickhouse 二级索引 跳数索引
–clickhouse 数据压缩
–clickhouse 数据标记
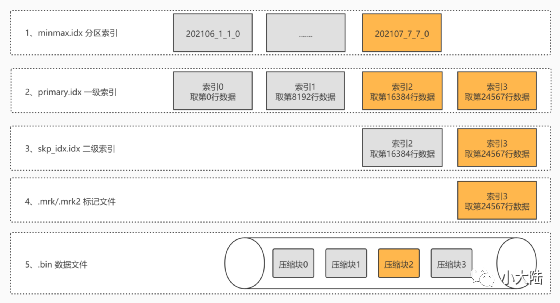
标记文件的最重要的作用,就是 建立了 主键索引 到 数据文件 的 数据映射,即桥梁的作用
3.1 数据分区
•表分区目录结构:MergeTree 表的分区目录物理结构
•当创建好了表之后,那么一次批量插入,就可能形成多个分区,其实每个分区,就是表存储目录中的一个子文件夹
•假设用一个 文件夹来存储这张表的所有数据,为了提高效率,可以考虑把 表的所有数据,按照某个维度,分割成多个子文件夹,假设以日期字段为例,查询不同的月份,到表文件夹的不同子文件夹中寻找即可
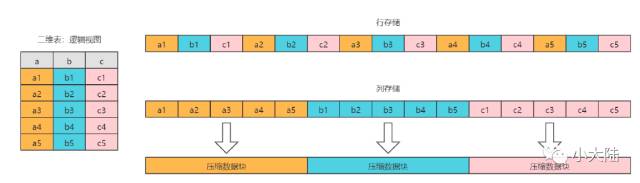
3.2 列式存储
•对于 OLAP 技术来说,一般都是这对大量行少量列做聚合分析,所以列式存储技术基本可以说是 OLAP 必用的技术方案。
•列式存储相比于行式存储,列式存储在分析场景下有着许多优良的特性
–列存储数据读取方便。分析场景中往往需要读大量行但是少数几个列。在行存模式下,数据按行连续存储,所有列的数据都存储在一个block中,不参与计算的列在IO时也
–而列存模式下,只需要读取参与计算的列即可,极大的减低了IO cost,加速了查询。
–同一列中的数据属于同一类型,压缩效果显著,压缩比高。
–占用空间小。更高的压缩比意味着更小的data size,从磁盘中读取相应数据耗时更短。
–自由的压缩算法选择。不同列的数据具有不同的数据类型,适用的压缩算法也就不尽相同。可以针对不同列类型,选择最合适的压缩算法。
–高压缩比,意味着同等大小的内存能够存放更多数据,系统cache效果更好
3.3 一级索引
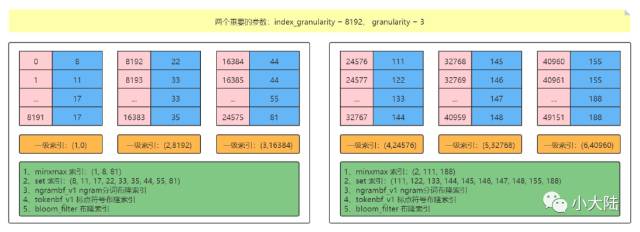
•一级索引:MergeTree 的主键使用 PRIMARY KEY 定义,待主键定义之后,MergeTree 会依据 index_granularity 间隔(默认 8192 行),为数据表生成一级索引并保存至 primary.idx 文件内
•一级索引是稀疏索引
需要注意的是:
1.每一段数据生成一条索引记录,而不是每一条数据都生成索引,如果是每一条数据都生成索引,则是稠密索引
2.稀疏索引的好处,就是少量的索引标记,就能记录大量的数据区间位置信息
3.书的目录,就是稀疏索引!一个章节,一条索引,而不是一页一条索引
4.ClickHouse 的主键索引与 MySQL 等数据库不同,它并不用于去重,即便 primary key 相同的行,也可以同时存在于数据库中。要想实现去重效果,需要结合具体的表引擎 ReplacingMergeTree、CollapsingMergeTree、VersionedCollapsingMergeTree 实现
3.4 二级索引
•二级索引:又称之为跳数索引。目的和一级索引一样,是为了减少待搜寻的数据的范围
•跳数索引一共支持四种类型:minmax(最大最小)、set(去重集合)、ngrambf_v1(ngram 分词布隆索引) 和 tokenbf_v1(标点符号分词布隆索引),一张数据表支持同时声明多个跳数索引
3.5 数据压缩
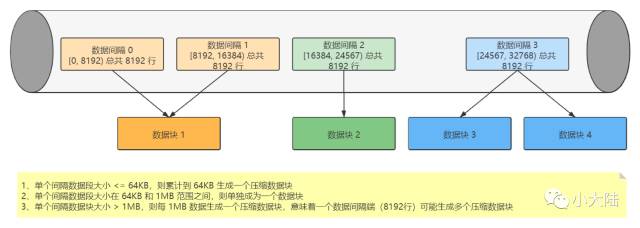
•数据压缩:ClickHouse 的数据存储文件 column.bin 中存储是一列的数据,由于一列是相同类型的数据,所以方便高效压缩
•一个 [Column].bin 其实是由一个个的压缩数据块组成的。每个压缩块的大小在:64kb - 1M 之间

3.6 数据标记
•数据标记:数据标记文件也与 .bin 文件一一对应,是一级索引 和 数据 之间的桥梁
•数据读取流程:
–先根据一级索引,找到标记文件中的对应数据压缩块信息(压缩块在 .bin 文件中的起始偏移量和未压缩之前该条数据的是偏移量)
–然后从 .bin 文件中,把压缩块加载到内存,解压缩之后,执行读取
4.ClickHouse核心流程
4.1 写入数据
4.2 查询数据
•数据查询的本质,可以看作一个不断减小数据范围的过程。
•在最理想的情况下,MergeTree 首先可以依次借助分区索引、一级索引和二级索引,将数据扫描范围缩至最小。然后再借助数据标记,将需要解压与计算的数据范围缩至最小
•提高数据查询效率的核心原则只有一个:快速降低待搜寻的数据范围
•分布式系统的核心思想:分而治之,必须提供一套架构方便用户的请求被快速的定位到某个单台服务器去处理。一般来说,这个服务器处理这个请求,都是很快的