





点击上方蓝字关注我们
1月11号检查平台发现数据采集异常,平台数据查询报错,经核查发现后台脚本采集程序发生大量kafka连接错误,且日志文件一夜涨至200G左右,MySQL主机存储撑爆,最终导致平台使用异常。
Kafka后台报错大量org.apache.kafka.common.network.Selector异常,查询资料发现该问题是
socket.request.max.bytes参数值过低导致(默认值为100M),调整到告警值的两倍后重启正常。
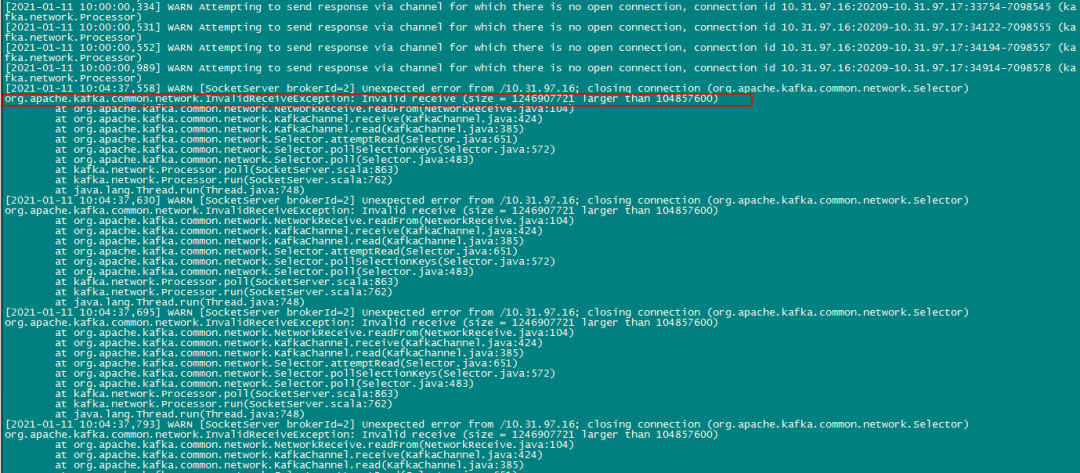
但随后在下午发现平台监控采集数据又中断了,再次检查kafka发现有新的报错信息:
(java.lang.OutOfMemoryError:Java heap space)
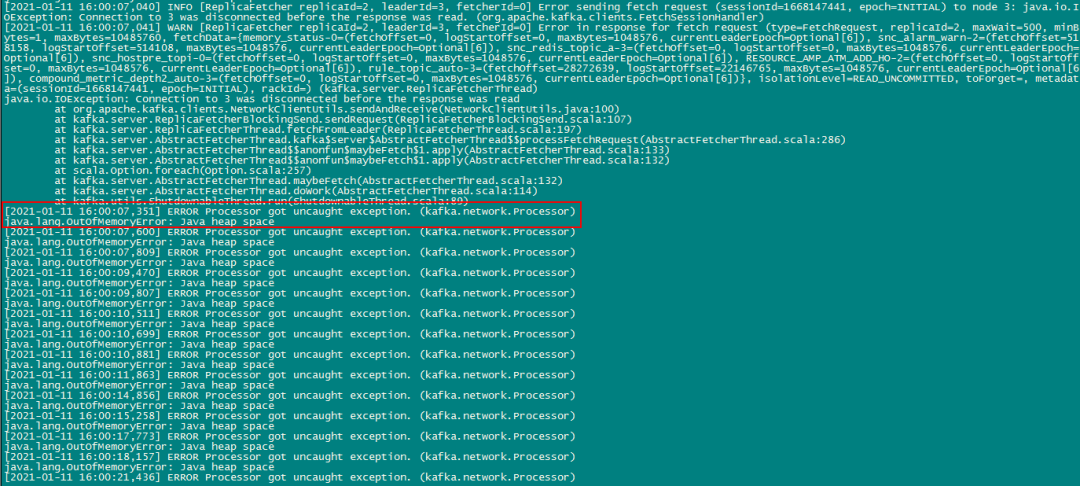
这次错误比较明显,内存溢出导致,需要调整kafaka启动内存,随即调整了kafka的原生start脚本kafka-server-start.sh加入如下参数:
exportKAFKA_HEAP_OPTS="-Xmx4G –Xms4G"
重启后发现还是报大量内存溢出,以为是设置过小,就改到了6G,错误依旧,ps检查了一下kakfka进程,发下启动内存写的是默认的1G!这里遇上了一个坑,kafka的start脚本其实是调用bin目录下的/kafka-run-class.sh脚本,而该脚本也设置了启动内存,所以内存参数一直未生效。

最后注释该参数,在kafka-server-start.sh加入该参数重启后恢复正常(附上设置参数如下)
export KAFKA_HEAP_OPTS="-Xmx6G -Xms6G -XX:MetaspaceSize=96m -XX:+UseG1GC -XX:MaxGCPauseMillis=20 -XX:InitiatingHeapOccupancyPercent=35 -XX:G1HeapRegionSize=16M -XX:MinMetaspaceFreeRatio=50 -XX:MaxMetaspaceFreeRatio=80"
回想整个事故原因,是kafka异常导致数据采集进程异常而出现大量错误日志,以至于撑爆MySQL主机存储。而kafaka在最近以来也未做变更,随即想到最近新增大量数据作处理,新建的topic在每分钟有大量数据消费,但分区数量也有12个,请教长研的景书大师后,了解到这种情况可以调整topic数据保留时间,缓解数据量过大导致内存溢出的问题,而默认topic的数据保留时间为24h。最后修改了topic保留时间为12小时(网上有大量的修改方法,就不附上在此了)、启动内存以及调整socket.request.max.bytes参数后,算是给kakfa上了双保险,集群故障解除。


