




1
背景
2020年这场疫情,对陶瓷行业影响极大,一方面加剧了行业间的竞争,另一方面也加速推进了行业升级变更,从传统零售业到新零售业的转型。不少陶瓷企业开启了线上旗舰店的升级改造、举办了很多优惠活动、实现线上线下联动、在线直播等等。


2
获取数据
数据来源淘宝网,关键词为瓷砖,共100页,4404条数据。由于考虑到淘宝是通过Ajax加载,参数加密的,并且有诸多的反爬机制(验证码,滑块等等),本文使用的是selenium+xpath获取数据,并且在进行淘宝登陆界面时需手动扫码登陆,当然也可以改写为模拟登陆代码(输入账号密码+动作链即可)。
1、销量 2、店铺名 3、价格 4、标题 5、地区
数据保存为csv文件

from selenium import webdriver
from lxml import etree
import time
import pandas as pd
import csv
def login_taobao():
'''定义登陆函数'''
global browser #定义全局变量
browser = webdriver.Chrome()
browser.get('https://www.taobao.com')
keyword = input('请输入爬取的标签:')
input_keyword = browser.find_element_by_xpath('//input[@id="q"]')
input_keyword.send_keys(keyword)
button = browser.find_element_by_xpath('//*[@id="J_TSearchForm"]/div[1]/button')
button.click() #需扫码登陆
def get_one_page():
'''定义爬取单页数函数,并保存至product.csv文件'''
one_page = pd.DataFrame()
response = browser.page_source
html = etree.HTML(response)
one_page['price'] = html.xpath('//*[@id="mainsrp-itemlist"]/div/div/div[1]/div/div[2]/div[1]/div[1]/strong/text()') #价格
one_page['deal'] = html.xpath('//*[@id="mainsrp-itemlist"]/div/div/div[1]/div/div[2]/div[1]/div[2]/text()') #销量
one_page['shop'] = html.xpath('//*[@id="mainsrp-itemlist"]/div/div/div[1]/div/div[2]/div[3]/div[1]/a/span[2]/text()') #店名
one_page['location'] = html.xpath('//*[@id="mainsrp-itemlist"]/div/div/div[1]/div/div[2]/div[3]/div[2]/text()') #地址
#one_page['image'] = html.xpath('//div[@class="pic"]/a/img/@data-src') #图片
one_page['title'] = html.xpath('//div[@class="pic"]/a/img/@alt') #标题
for data in range(one_page.shape[0]):
with open(r'C:\Users\Administrator\Desktop\cizhuanproduct.csv', 'a', encoding='utf-8') as f:
writer = csv.writer(f)
writer.writerow([one_page.iloc[data,0],one_page.iloc[data,1],one_page.iloc[data,2],one_page.iloc[data,3],one_page.iloc[data,4]])
return one_page
def get_all_page():
'''定义翻页函数'''
for page in range(1,101):
input = browser.find_element_by_xpath('//*[@id="mainsrp-pager"]/div/div/div/div[2]/input')
input.clear()
print('正在爬取{}页'.format(page))
input.send_keys(page)
subimt = browser.find_element_by_xpath('//*[@id="mainsrp-pager"]/div/div/div/div[2]/span[3]')
subimt.click()
time.sleep(15)
all_page = get_one_page()
print(all_page)
if __name__ == '__main__':
login_taobao()
time.sleep(20)
get_all_page()
3
数据处理与清洗
数据预处理主要针对的是销量deal_cut列、地区address两列。
Step1:deal_cut中提取数字,并转化为int类型;
Step2:address列进行省份、城市的分割。
数据展示:
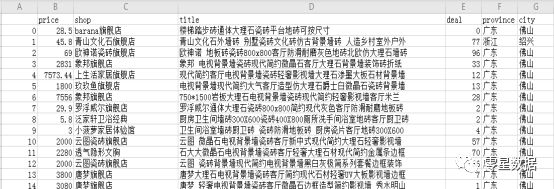
(注:下面所进行的数据分析和中文分词都是基于这份数据来进行的)
import pandas as pd
data = pd.read_csv(r'C:\Users\Administrator\Desktop\cizhuanproduct.csv',encoding = 'gbk')
data['deal_num'] = data.deal_cut.apply(lambda x:x.split("人")[0])
data['deal'] = data['deal_num'].astype('int')
data['province'] = data.address.apply(lambda x:x.split()[0])
data['city'] = data.address.apply(lambda x:x.split()[0] if len(x)<4 else x.split()[1])
data.drop(['deal_cut','deal_num','address'],axis=1,inplace=True)
print(data)
pd.DataFrame.to_csv(data,r'C:\Users\Administrator\Desktop\new_product.csv',',')
4
市场分析
市场分析主要从卖方店家的倾向(标题的中文分词)和买方顾客的倾向(销量统计),两个方面进行的。

从上图中可以大致把主要的关键词分为四个指标:
(1)规格:可以看到800x800,300x600,600x600,300x600这些规格的瓷砖适用于客厅、卫生间、内墙、房间等等,都是商家所关注的规格,在图中我们并没有发现900x900规格的,取代它的是800x800。
(2)风格:在淘宝商品中、简约,北欧、欧式、现代风格占主导。在现代市场趋势下,更多人会喜欢黑、白、灰这种现代简约、欧式风格的,像中式、复古等等较为传统的风格,人们对之喜好性也在降低。
(3)性能:瓷砖性能主要是防滑和耐磨,商家更看重的是防滑性能。
(4)砖种:在市场需要下,在价格和性能等多方面下,商家更倾向的是以大理石、仿古砖、微晶石为主导,马赛克、通体砖、大板、木纹砖次之的商品结构。
程序代码:
import matplotlib.pyplot as plt
from wordcloud import WordCloud
import pandas as pd
import jieba
shop = pd.read_csv(r'C:\Users\Administrator\Desktop\new_product.csv',usecols = [3],encoding = 'utf-8') #此处提取第四列title列进行中文分词
shop = shop.values.tolist() # DataFrame转化为list
add_words_list = ['mm','釉面','通体'] #添加词
for w in add_words_list:
jieba.add_word(w,freq=1000)
stopwords = ['瓷砖','KTV','鱼骨','影视','ins','面包','六角','凹凸','院了','乡村','电视','文化','小白','无限','mm'] #停用词
shop_s = [] #jieba分词
for line in shop:
for w in line:
shop_cut = jieba.lcut(w)
shop_s.append(shop_cut)
shop_clean = [] #过滤停用词
for line in shop_s:
line_clean = []
for word in line:
if word not in stopwords:
line_clean.append(word)
shop_clean.append(line_clean)
shop_clean_dist = [] #去重
for line in shop_clean:
line_dict = []
for word in line:
if word not in line_dict:
line_dict.append(word)
shop_clean_dist.append(line_dict)
all_words = []
for line in shop_clean_dist:
for word in line:
all_words.append(word) #转化为一维列表
text = " ".join(all_words)
print(text)
wc = WordCloud(
font_path='data/simhei.ttf', #设置字体
background_color='white', #词云图背景颜色
max_words=1000, #显示的最大词组数
max_font_size=60, #最大字体
min_font_size=5, #最小字体
scale=32, #设置图片清晰度
collocations=False, #避免重复词组
)
wc.generate(text)
plt.imshow(wc)
plt.axis("off") #关闭坐标轴
plt.show()
2、买方顾客的倾向
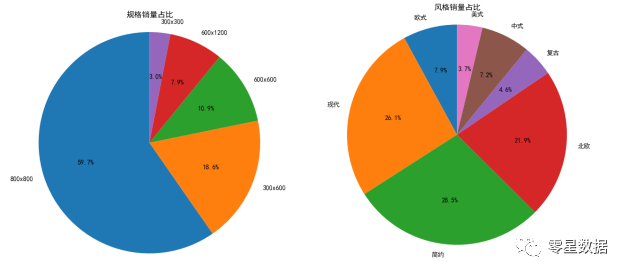
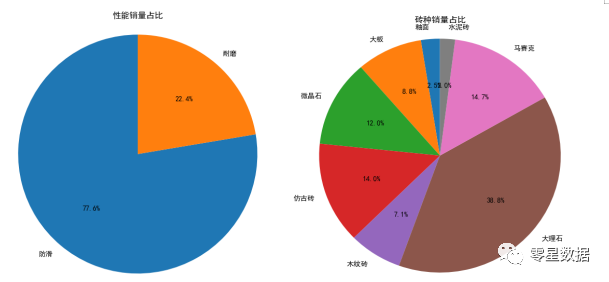
分析:
分析1:在顾客的消费倾向上,800x800销量占59.7%,占据主导,而300x600和600x600次之,顾客购买倾向和卖家倾向基本相同。
分析2:分析卖家倾向时候提到过,现在当今社会下,年轻人为购房和装修的主要人群,他们则更倾向的是黑、白、灰三色的简约、现代、北欧风格,同时也是瓷砖行业的发展趋势和走势。
分析3:防滑性能同时都是卖方店家和买方顾客,最看重的性能要素。
分析4:在砖种情况上,前面所分析的卖家倾向中大理石、微晶石和马赛克占主要,但是顾客消费倾向中,仿古砖也纳入其中,销量较高。同时大板也是最近几年才火起来的,价格也相对较高,相信以后聚集了美观、质量等各种优势的大板,也是瓷砖行业发展趋势之一。
import matplotlib.pyplot as plt
import pandas as pd
#正常显示中文字体
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
#读取标题数据
shop = pd.read_csv(r'C:\Users\Administrator\Desktop\new_product.csv',usecols = [3],encoding = 'utf-8')
# DataFrame转化为list
shop = shop.values.tolist()
#一维列表
shop_list = []
for line in shop:
for word in line:
shop_list.append(word)
#读取销量数据
deal = pd.read_csv(r'C:\Users\Administrator\Desktop\new_product.csv',usecols = [4],encoding = 'utf-8')
performs = ['防滑','耐磨']
index2 = 0
t = 0
t1 = 0
for perform in performs:
index2 = index2 + 1
for i in range(len(shop_list)):
if (perform in shop_list[i]) and (index2 == 1):
t = t + deal.iloc[i]
elif (perform in shop_list[i]) and (index2 == 2):
t1 = t1 + deal.iloc[i]
performs = ['防滑','耐磨']
sizes = [t,t1]
explode = [0,0]
plt.pie(sizes,explode=explode,labels=performs,autopct='%1.1f%%',startangle = 90)
plt.axis('equal')
plt.title('性能销量占比')
plt.show()
#(其余三个指标代码类似,此处省略)
5
店名分析

可以看到的是在淘宝网中,具有旗舰店关键词是最多的。无论是在淘宝、天猫或是京东,甚至其他电商平台,一般来说,旗舰店、专卖店、专营店等等具有较为官方关键字的店铺,都会给我们一种信赖、信得过的感觉,但是是不是就是这几类店的销量就高呢?
通过对这几类门店进行销量统计得到
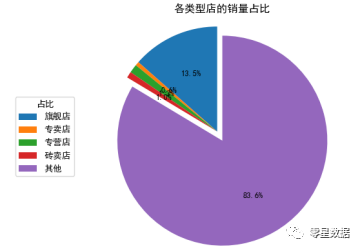
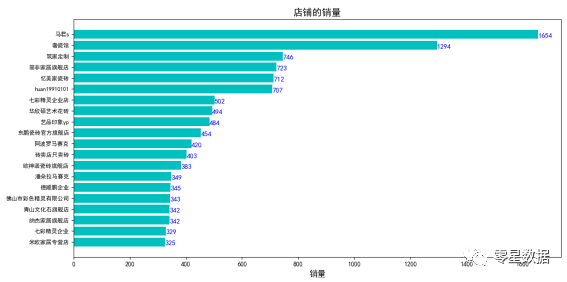
旗舰店占总销量的13.5%,而专卖店、专营店和砖卖店的销量占比也很低。接着统计各个店铺的销量(TOP20),绘制条形图。
分析:
分析1:在淘宝网上,旗舰店数量最多,但是像旗舰店、专营店、专卖店等较为官方的店铺销量并不高,其中旗舰店销量占比为13.5%,专营店、专卖店等销量不超过2%。
分析2:在店铺销量上看,马君s和奢瓷馆的销量最高,都超过1000,个人门店(经销商门店)由于受到价格、便捷的原因,更受到顾客的亲睐。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
#统计店铺销量
shop_deal = pd.read_csv(r'C:\Users\Administrator\Desktop\new_product.csv',usecols = [2,4],encoding = 'utf_8')
#正常显示中文字体
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
df_shop = pd.DataFrame(shop_deal.groupby(['shop'],as_index = False)['deal'].sum())
df_shop.sort_values(by=['deal'],ascending=True,inplace=True)
df_shop = df_shop.tail(20)
#绘图
index = np.arange(df_shop.shop.size)
plt.barh(index,df_shop.deal,align='center',color = "c")
plt.yticks(index,df_shop.shop,fontsize=9)
plt.xlabel('销量',fontsize = 13)
plt.title('店铺的销量',fontsize = 15)
for i,v in enumerate(df_shop.deal):
plt.text(v+0.6, i-0.3, str(v), color='blue', fontweight='bold',fontsize = 11)
plt.show()
