




表分区是几个数据库支持的一个非常方便的功能,包括PostgreSQL、MySQL、Oracle和YugabyteDB。当需要将大型表拆分为更小的独立部分(称为分区表或分区)时,此功能非常有用。如果您还不熟悉此功能,请考虑以下简单示例。
让我们假设您开发了一个应用程序,可以自动化大型比萨饼连锁店的运营。您的数据库模式有一个PizzaOrders表,用于跟踪订单的进度。
表分区是几个数据库支持的一个非常方便的功能,包括PostgreSQL、MySQL、Oracle和YugabyteDB。当需要将大型表拆分为更小的独立部分(称为分区表或分区)时,此功能非常有用。如果您还不熟悉此功能,请考虑以下简单示例。
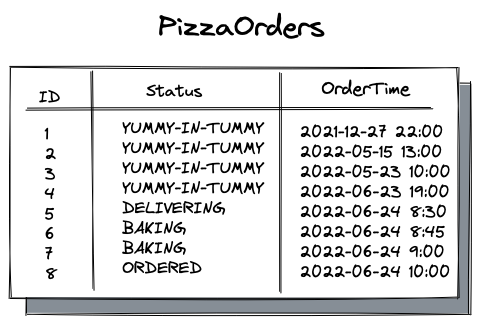
表中的每一行表示具有唯一标识符(ID)、客户下订单的时间(OrderTime)和当前订单的状态的客户订单。状态范围从订购到美味-美味-在我的肚子里。后一种状态意味着一个比萨饼已经送到顾客家门口,并且有望被消费掉。
作为一家大型披萨连锁店,该应用程序每天需要处理数千份订单。这意味着PizzaOrders表的大小正在失控。最后,利用表分区特性,将表拆分为几个较小的独立表,称为分区。
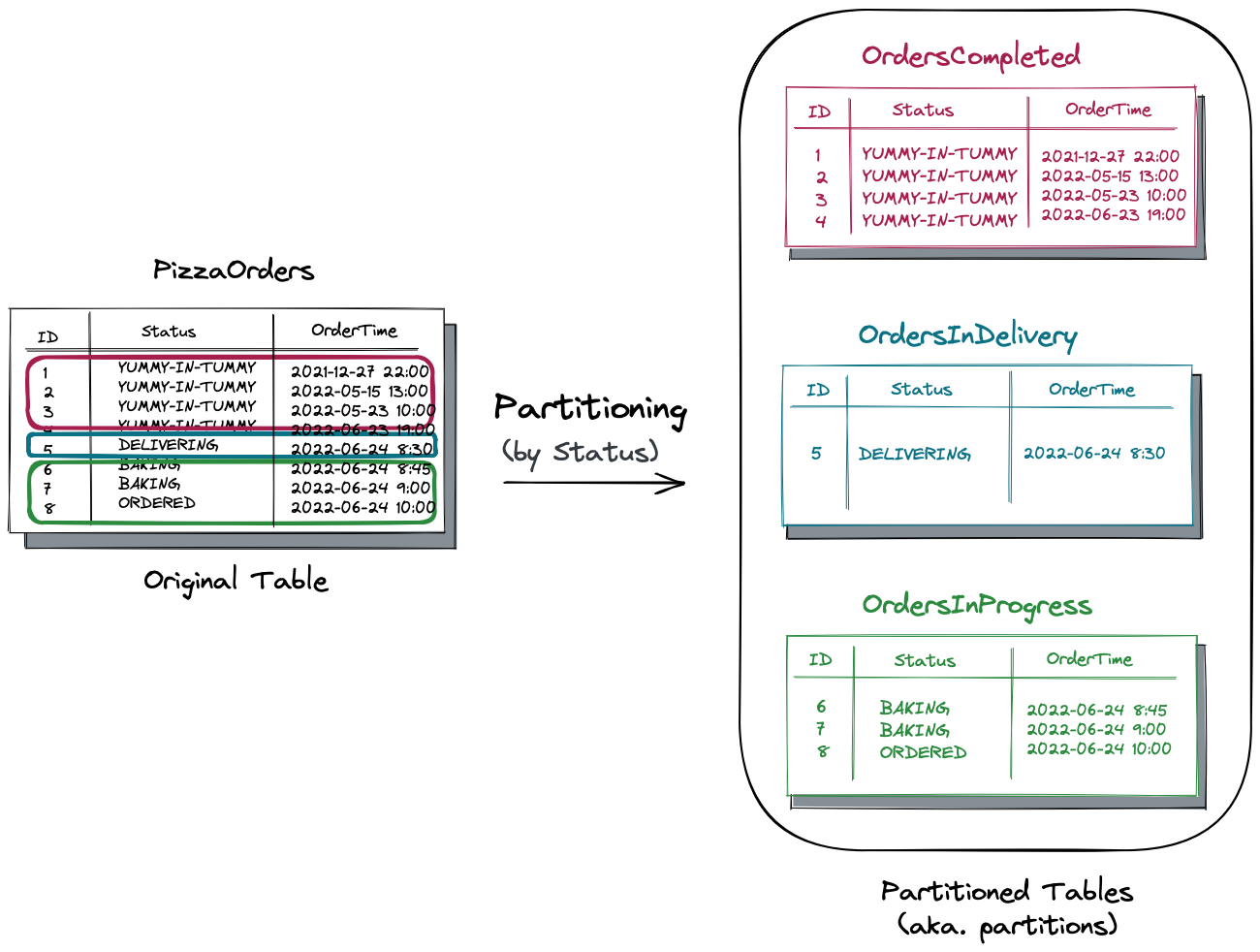
原始表由状态列拆分为三个分区表:
-
OrdersCompleted表存储移交给客户的所有订单。
-
OrdersInDelivery跟踪到客户所在地的路上的订单。
-
订单sinprogress针对的是尚未烘焙的披萨。
美好的作为一个快速的胜利,现在您可以独立管理每个分区的大小和状态,并控制成本,例如,通过使用更便宜的历史数据存储介质(OrdersCompleted)。此外,对于仅请求具有特定状态的比萨饼的查询,您可能会在拆分后立即看到性能提升。例如,如果应用程序请求所有正在进行的订单,那么请求将绕过其他分区转到OrdersInProgress表。
好了,现在您对表分区有了基本的了解。接下来,让我们深入了解一下表分区如何提高应用程序的速度、可管理性和设计。在本文中,我们从分区剪枝功能开始。
分区剪枝
在PostgreSQL中,分区修剪是一种优化技术,允许SQL引擎从执行中排除不必要的分区。因此,查询将在较小的数据集上运行,绕过排除的分区。查询的数据集越小,性能越好。
让我们看看当计划者和执行者应用这种优化技术时会发生什么。
创建分区
前面,我们讨论了如何使用状态列将PizzaOrders表划分为三个表:OrdersInProgress、OrdersInDelivery和OrdersCompleted。以下是DDL命令:
CREATE TABLE PizzaOrders
(
id int,
status status_t,
ordertime timestamp,
PRIMARY KEY (id, status)
) PARTITION BY LIST (status);
CREATE TABLE OrdersInProgress PARTITION OF PizzaOrders
FOR VALUES IN('ordered','baking');
CREATE TABLE OrdersInDelivery PARTITION OF PizzaOrders
FOR VALUES IN('delivering');
CREATE TABLE OrdersCompleted PARTITION OF PizzaOrders
FOR VALUES IN('yummy-in-my-tummy');
PARTITION BY LIST(status)子句请求使用列表分区方法拆分表。使用这种方法,通过明确列出每个分区中出现的值来对表进行分区。PostgreSQL还支持哈希、范围和多级分区方法,您可以稍后查看。
拆分后,您可以使用以下命令查看有关表及其分区的信息:
\d+ PizzaOrders;
Partitioned table "public.pizzaorders"
Column | Type | Collation | Nullable | Default | Storage | Compression | Stats target | Description
-----------+-----------------------------+-----------+----------+---------+---------+-------------+--------------+-------------
id | integer | | not null | | plain | | |
status | status_t | | not null | | plain | | |
ordertime | timestamp without time zone | | | | plain | | |
Partition key: LIST (status)
Indexes:
"pizzaorders_pkey" PRIMARY KEY, btree (id, status)
Partitions: orderscompleted FOR VALUES IN ('yummy-in-my-tummy'),
ordersindelivery FOR VALUES IN ('delivering'),
ordersinprogress FOR VALUES IN ('ordered', 'baking')
接下来,我们插入示例数据:
INSERT INTO PizzaOrders VALUES
(1, 'yummy-in-my-tummy', '2021-12-27 22:00:00'),
(2, 'yummy-in-my-tummy', '2022-05-15 13:00:00'),
(3, 'yummy-in-my-tummy', '2022-05-23 10:00:00'),
(4, 'yummy-in-my-tummy', '2022-06-23 19:00:00'),
(5, 'delivering', '2022-06-24 8:30:00'),
(6, 'baking', '2022-06-24 8:45:00'),
(7, 'baking', '2022-06-24 9:00:00'),
(8, 'ordered', '2022-06-24 10:00:00');
然后运行下面的查询,查看每条记录存储在哪个分区中:
SELECT tableoid::regclass,* from PizzaOrders
ORDER BY id;
tableoid | id | status | ordertime
------------------+----+-------------------+---------------------
orderscompleted | 1 | yummy-in-my-tummy | 2021-12-27 22:00:00
orderscompleted | 2 | yummy-in-my-tummy | 2022-05-15 13:00:00
orderscompleted | 3 | yummy-in-my-tummy | 2022-05-23 10:00:00
orderscompleted | 4 | yummy-in-my-tummy | 2022-06-23 19:00:00
ordersindelivery | 5 | delivering | 2022-06-24 08:30:00
ordersinprogress | 6 | baking | 2022-06-24 08:45:00
ordersinprogress | 7 | baking | 2022-06-24 09:00:00
ordersinprogress | 8 | ordered | 2022-06-24 10:00:00
tableoid列显示存储相应记录的表的名称。如您所见,所有记录都根据其状态列的值在分区表中正确排列。
分区剪枝的作用
最后,假设您希望获得所有交付给客户的订单,并希望被客户消费:
EXPLAIN ANALYZE SELECT * FROM PizzaOrders
WHERE status = 'yummy-in-my-tummy';
QUERY PLAN
--------------------------------------------------------------------------------------------------------------------------------
Bitmap Heap Scan on orderscompleted pizzaorders (cost=22.03..32.57 rows=9 width=16) (actual time=0.019..0.020 rows=4 loops=1)
Recheck Cond: (status = 'yummy-in-my-tummy'::status_t)
Heap Blocks: exact=1
-> Bitmap Index Scan on orderscompleted_pkey (cost=0.00..22.03 rows=9 width=0) (actual time=0.012..0.013 rows=4 loops=1)
Index Cond: (status = 'yummy-in-my-tummy'::status_t)
Planning Time: 0.321 ms
Execution Time: 0.052 ms
执行计划显示查询是在单个分区(OrdersCompleted)上执行的,绕过了其他分区。这就是分区剪枝的实际功能!它在PostgreSQL中默认启用。
分区剪枝和函数
只有当查询通过应用常量值或外部提供的参数过滤数据时,分区修剪才有效。如果您试图在WHERE子句部分中使用非不变函数,规划器将跳过此优化,而是扫描整个表。如果您看到以下执行计划,请不要感到惊讶:
EXPLAIN ANALYZE SELECT * FROM PizzaOrders
WHERE status::text = lower('yummy-in-my-tummy');
QUERY PLAN
--------------------------------------------------------------------------------------------------------------------------------
Append (cost=0.00..127.26 rows=27 width=16) (actual time=0.074..0.076 rows=4 loops=1)
-> Seq Scan on ordersinprogress pizzaorders_1 (cost=0.00..42.38 rows=9 width=16) (actual time=0.040..0.040 rows=0 loops=1)
Filter: ((status)::text = 'yummy-in-my-tummy'::text)
Rows Removed by Filter: 3
-> Seq Scan on ordersindelivery pizzaorders_2 (cost=0.00..42.38 rows=9 width=16) (actual time=0.019..0.019 rows=0 loops=1)
Filter: ((status)::text = 'yummy-in-my-tummy'::text)
Rows Removed by Filter: 1
-> Seq Scan on orderscompleted pizzaorders_3 (cost=0.00..42.38 rows=9 width=16) (actual time=0.014..0.015 rows=4 loops=1)
Filter: ((status)::text = 'yummy-in-my-tummy'::text)
Planning Time: 11.435 ms
Execution Time: 0.222 ms
规划师不喜欢猜测执行函数可能需要的时间。因此,它查询所有分区,这可能要快得多。
待续…
好的,这足以理解表分区的基本知识,以及如果数据库应用分区修剪优化技术,应用程序如何更快地执行。修剪的好处在于,作为开发人员,您只需定义表和各自的分区,然后数据库引擎就会负责优化。
在以下文章中,您将了解分区管理如何简化和改进事件驱动和流应用程序的体系结构。您还将发现如何使用地理分区技术将用户数据固定到特定的地理位置。当应用程序必须遵守数据监管要求或以低延迟服务用户请求时,无论用户位于何处,后一种方法都很方便。
原文标题:What Developers Need to Know About Table Partition Pruning
原文作者:Denis Magda
原文链接:https://dzone.com/articles/what-developers-need-to-know-about-table-partition
