




由于我们经常将关系数据库用于非常简单的数据管理任务,因此往往忽视了关系数据库的绝对聪明。
将对象序列化为行,使用唯一键存储。
搜索唯一键,将行反序列化为对象。
关系数据库的真正功能是大量处理“关系”(也称为表),并在运行中找出过滤行并找到答案的最有效方法。
PostgreSQL有一个无可否认的智能查询规划系统,可以根据系统中的数据自动调整。它对表进行采样以获得有关数据分布的统计信息,并使用这些统计信息选择应用于数据的连接和过滤器的顺序,以实现最高效的查询执行。
更令人惊讶的是,查询规划系统的模块化程度足以集成用户定义的数据类型,如PostGIS中的几何和地理类型。因此,涉及空间过滤器的复杂查询也可以在运行中正确规划。
统计数据目标
大多数情况下,这只是神奇的工作。该系统大致了解任何给定过滤器或连接条件的选择性,并可以使用该估计来选择最有效的操作顺序,以在复杂的关系表集合上执行多表和多过滤器查询。
但是当事情出了问题怎么办?

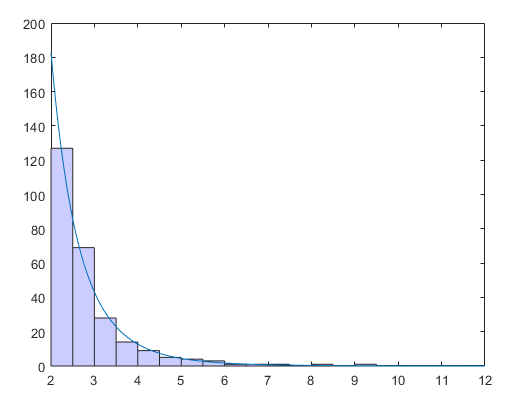
默认情况下,PostgreSQL数据附带的默认统计目标为100。这意味着要填充列的统计信息,数据库将抽取300*默认统计目标=30000行的样本。
然后,系统将使用该数据填充“公共值列表”和列柱状图,其中包含大致默认的_statistics_target。
排列在帕累托分布中的一个大键表可能会给统计系统带来困难。可能有比“公共值列表”更容易容纳的公共键,因此连接规划得很糟糕。
幸运的是,您可以转动一些特定于表的旋钮。
可以单独更改每个表和列上的统计信息目标,以便对更多数据进行采样,并收集更细粒度的统计信息。
ALTER TABLE people ALTER COLUMN age SET STATISTICS 200;
收集更多统计数据通常足以纠正规划行为。然而,在特殊情况下(例如当一个查询在强相关列上使用多个过滤器时),可能需要提取“扩展统计信息”以收集更多数据进行规划。
索引使(某些)事情更快
神奇的事情是,在下面通常有一些复杂的机器,使它透明地工作。
几乎每个数据库用户都知道有一种叫做“索引”的东西,向列中添加“索引”将加快对该列的搜索。
对于大多数应用来说,这条经验法则是正确的:索引使对少量项目的随机访问更快,但对表的插入和更新速度稍慢。
但是,如果从表中访问大量项,会发生什么?
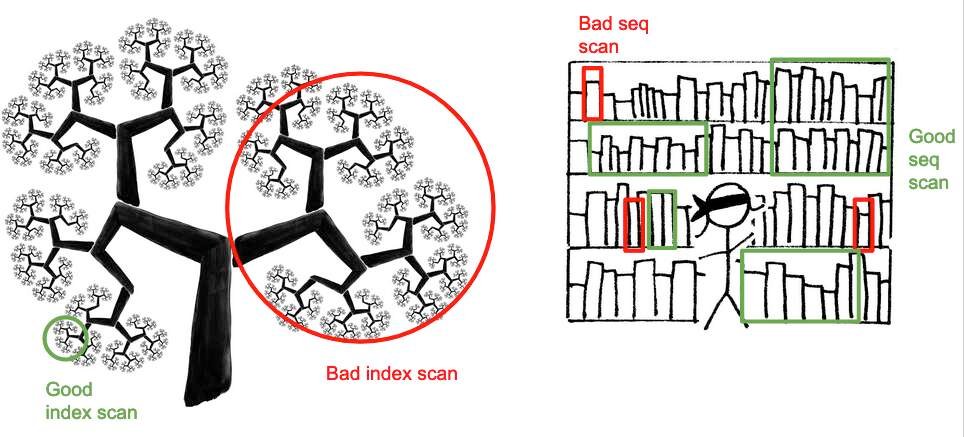
索引是一棵树。在树中快速找到一个项目,这称为“索引扫描”。但是要找到很多项目,需要在树上一遍又一遍地运行。索引扫描树中的所有记录很慢。
高效的索引扫描查询将具有窄过滤器:
SELECT * FROM people WHERE age = 4;
相反,如果您对大多数记录感兴趣,那么从前到后读取表格可能会非常快。这称为“序列扫描”。
高效的序列扫描查询将具有广泛的过滤器:
SELECT * FROM people WHERE age BETWEEN 45 AND 95;
对于任何给定的过滤器,关系数据库将确定过滤器是作为索引扫描还是序列扫描运行最有效。但是怎么做?
选择性
过滤器的“选择性”是衡量过滤器返回的记录比例的指标。只返回1%记录的过滤器是“非常有选择性的”,反之亦然。
数字、字符串或日期的普通过滤器可能会将等式或范围定义为过滤器。地理对象上的空间过滤器将边界框定义为过滤器。过滤器只是一个真/假测试,列中的每个对象都可以进行该测试。
这里有两个空间滤波器,你认为哪一个更具选择性?
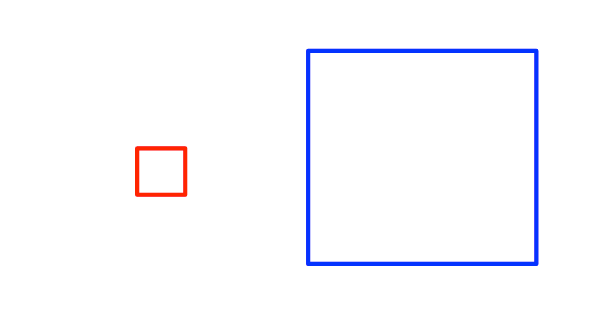
红色的那个,对吗?就像上面关于AGE的SQL示例一样,较小的矩形必须返回较少的记录。但不一定。假设我们的数据表是这样的。
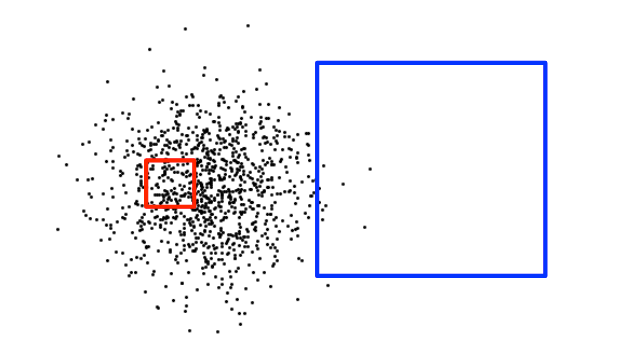
因此,蓝色框是选择性的,应该使用索引扫描,红色框应该使用序列扫描。
但是等等,数据库如何知道哪个框是选择性的,而不运行查询并实际对数据应用过滤器?
统计数字
当运行ANALYZE命令时,数据库将为每个有索引的列收集“统计信息”。(在每个PostgreSQL集群的后台运行的“autovacuum”系统也是一个“autoanalyze”,在进行表维护的同时收集统计数据。)
对于整数、实数、文本和日期等数据类型,系统将收集表中经常出现的值的“通用值列表”,以及不同范围内值的频率直方图。
对于空间数据类型,系统构建了发生频率的空间直方图。因此,对于我们的示例数据集,类似这样的内容。
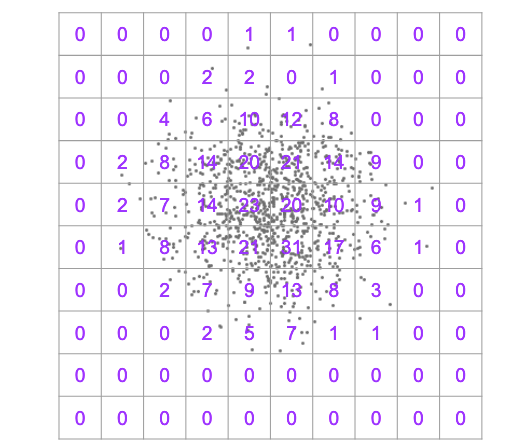
数据库不再是可能包含数百万个空间对象的潜在无约束集合,现在只需快速汇总直方图中的几个单元格,以估计给定查询过滤器将返回多少特征。
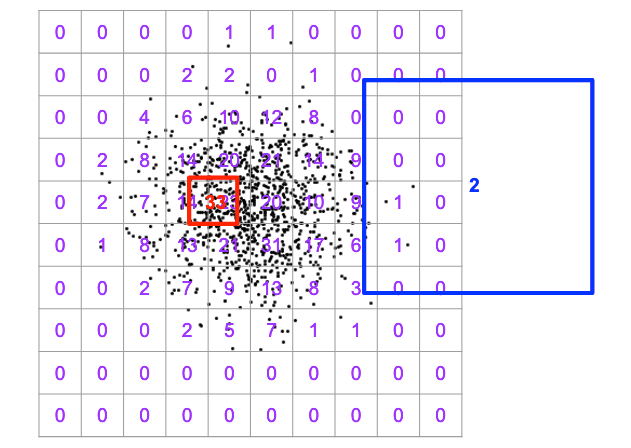
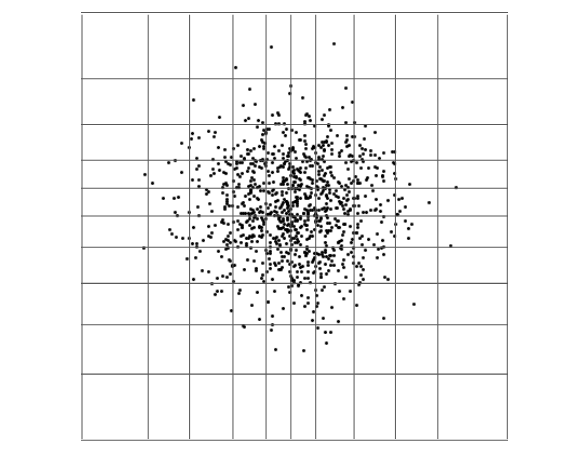
PostGIS中的空间统计分析器实际上要复杂一些:在填写直方图之前,它会调整每个维度的单元格宽度,以尝试在数据更密集的地方获得更高的分辨率。
所有这些统计数据都是有代价的。增加统计目标将使ANALYZE命令运行稍慢,因为它会采集更多数据。这还将使查询的规划阶段变慢,因为需要通读更大的统计数据集,并与SQL中的过滤器和连接进行比较。然而,对于复杂的BI查询,更多的统计信息几乎总是值得的,以便为复杂查询获得更好的计划。
结论
PostgreSQL有一个不可否认的智能查询规划系统,可以根据系统中的数据自动调整。
PostGIS直接插入到这个聪明的系统中,并提供空间选择性估计,以确保良好的空间查询计划。
对于更复杂的情况,例如高度相关列的选择性估计,PostgreSQL还包括一个“扩展统计”系统来捕获这些情况。
喜欢这样的文章吗?
原文标题:Postgres Indexes, Selectivity, and Statistics
原文作者:Paul Ramsey
原文链接:https://www.crunchydata.com/blog/indexes-selectivity-and-statistics
