崔鹏,任职于海能达通信股份有限公司哈尔滨平台中心,数据库开发高级工程师,致力于PostgreSQL数据库在专网通信领域、公共安全领域的应用与推广,个人兴趣主要集中在:分布式数据库系统设计、高并发高可用数据库架构设计与开源数据库的源码研究。
朱君鹏,博士研究生。主要研究方向为数据库管理系统,尤其是内存数据库、事务处理系统、软硬件协同设计、日志系统。
数据中心中ARM处理器的预期增长一直是讨论的热门话题,我们很好奇它在PostgreSQL中的表现。用于测试和评估的基于ARM的服务器普遍可用性是一个主要问题。2018年,AWS宣布在其云服务中提供基于ARM的处理器。但我们并没有立即看到太多令人兴奋的东西,因为许多人认为这是一种“实验性”的东西。我们对于将其用于关键用途也持谨慎态度,并且从未付出足够的努力来评估它。但是,当基于Graviton2的第二代实例于2020年5月发布时,我们想要认真思考。我们从运行PostgreSQL的角度来独立研究新实例的价格/性能。重要提示:注意虽然把PostgreSQL在x86上和arm上做对比很吸引人,但这是不正确的。这些测试将PostgreSQL在两个虚拟云实例上进行了比较,其中包含了比CPU更多的移动组件。我们主要关注基于两种不同架构的两个特定AWS EC2实例的性价比。测试设置
对于此测试,我们选择了两个类似的实例。一种是较旧的 m5d.8xlarge,另一个是基于Graviton2的新 m6gd.8xlarge。这两个实例都带有本地 “临时”存储,我们将在这里使用它们。使用速度快的本地驱动器有助于暴露系统其他部分的差异,并避免测试云存储。这些实例并不完全相同,如下所示,但它们非常接近,足以被认为是相同的等级。我们使用了来自pgdg repo的Ubuntu 20.04 AMI和PostgreSQL 13.1。我们使用的是Ubuntu 20.04 AMI和pgdg repo的PostgreSQL 13.1。我们使用较小(内存)和较大(IO密集型)的数据库大小进行了测试。例子
根据AWS在北弗吉尼亚州的Linux定价信息,对实例进行规范和按需定价。以目前列出的价格,m6gd.8xlarge要便宜25%。
Graviton2(arm)实例
Storage : 1 x 1900 NVMe SSD (1.9 TiB)常规(x86)实例
Storage : 2 x 600 NVMe SSD (1.2 TiB)OS和PostgreSQL设置
我们选择了Ubuntu 20.04.1 LTS AMIs作为实例,并且在操作系统段做任何改变。m5d.8xlarge实例中,两个本地NVMe驱动器组成raid0设备中。PostgreSQL是使用PGDG存储库中可用的.deb包安装的。使用PostgreSQL版本查询函数version()确认操作系统架构postgres=# select version();
version
-------------------------------------------------------------------------------
PostgreSQL 13.1 (Ubuntu 13.1-1.pgdg20.04+1) on aarch64-unknown-linux-gnu, compiled by gcc (Ubuntu 9.3.0-17ubuntu1~20.04) 9.3.0, 64-bit
(1 row)
checkpoint_timeout = '1h'checkpoint_completion_target = '0.9'archive_command = '/bin/true'effective_cache_size = '80GB'maintenance_work_mem = '2GB'autovacuum_vacuum_scale_factor = '0.4'bgwriter_lru_maxpages = '1000'bgwriter_lru_multiplier = '10.0'log_autovacuum_min_duration = '0'pgbench测试
首先,使用pgbench进行初步测试,pgbench是PostgreSQL提供的微基准测试(micro-benchmarking)工具。这使我们能够使用多种客户端和作业的不同组合进行测试,例如:pgbench -c 16 -j 16 -T 600 -r其中使用16个客户端连接和16个提供客户端连接的pgbench作业。不启用校验和的读写测试
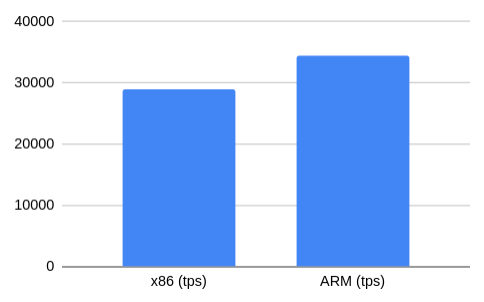
pgbench创建的默认负载是类似tpcb的读写负载。我们在未启用校验和的PostgreSQL实例上使用了相同的命令。我们可以看到ARM的性能提高了19%。启用校验和的读写
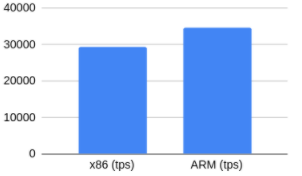
我们很好奇校验和计算是否会因为架构的不同而对性能产生影响。如果启用了PostgreSQL级别校验和。PostgreSQL 12以后,可以使用pg_checksum工具来启用校验和,如下所示:pg_checksums -e -D $PGDATA令我们惊讶的是,结果稍微好一点!由于差异只有1.7%左右,我们认为这是一个噪音。至少我们觉得可以得出这样的结论:在这些处理器上启用校验和不会有任何明显的性能下降。不带校验和的只读
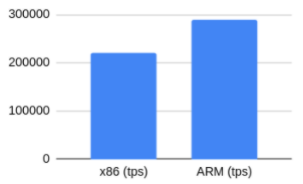
只读负载以cpu为中心。因为我们选择了一个完全适合内存大小的数据库,所以我们可以消除IO相关的开销。结果表明,与x86架构上的PG实例相比,ARM的tps增长了30%。带有校验和的只读
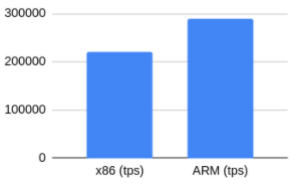
在pgbench测试中,我们观察到随着负载集中在CPU上,性能差异会增加。我们无法通过校验和观察到任何性能下降。当页面被写出并在缓冲池中读取时,PostgreSQL计算并写入页面的校验和。此外,启用校验和时,总是记录Hint Bits,从而增加了预写式日志的输入输出(WAL IO)压力。为了正确地验证总的校验和开销,我们需要更长和更大量的测试,类似于使用sysbench-tpcc时所做的测试。使用sysbench-tpcc进行测试
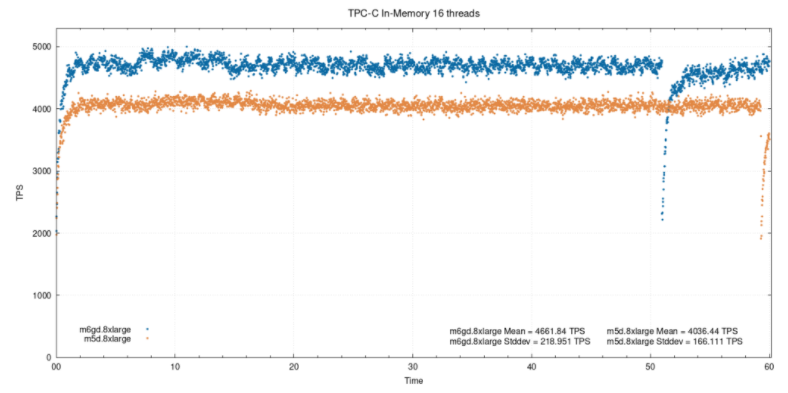
我们决定使用sysbench-tpcc执行更详细的测试。我们主要感兴趣的是数据库能够装入内存的情况。另一方面,虽然在arm服务器上的PostgreSQL没有问题,但sysbench比x86要挑剔得多。2.使用与大型测试相同的参数运行10分钟的预热测试。内存中的16个线程:
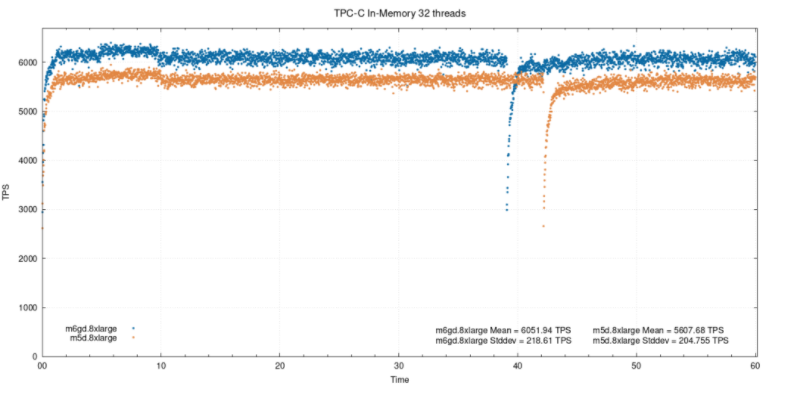
在中等负载下,ARM实例的性能比x86实例高出约15.5%。在此前后,百分比差异是基于平均tps值。您可能想知道为什么在测试结束时性能突然下降。它与使用full_page_writes的检查点有关 。即使在内存测试中我们使用了pareto分布,每个检查点之后也会写出相当多的页面。在这种情况下,在本例中,实例显示了更多由WAL引发的检查点的性能问题。这些下降将在所有执行的测试中出现。内存中的32个线程:
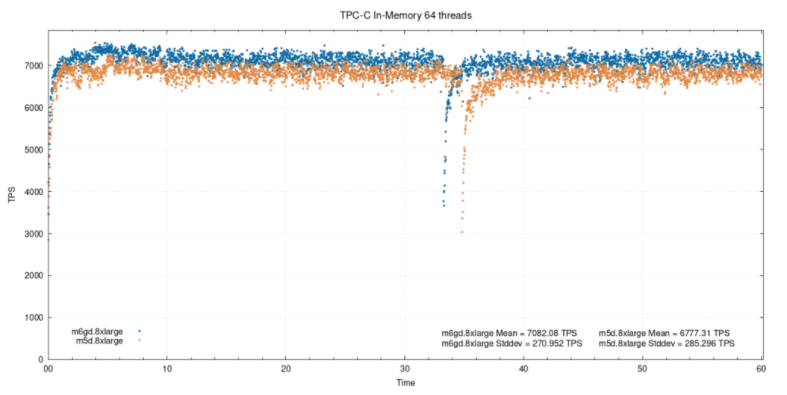
内存中有64个线程:
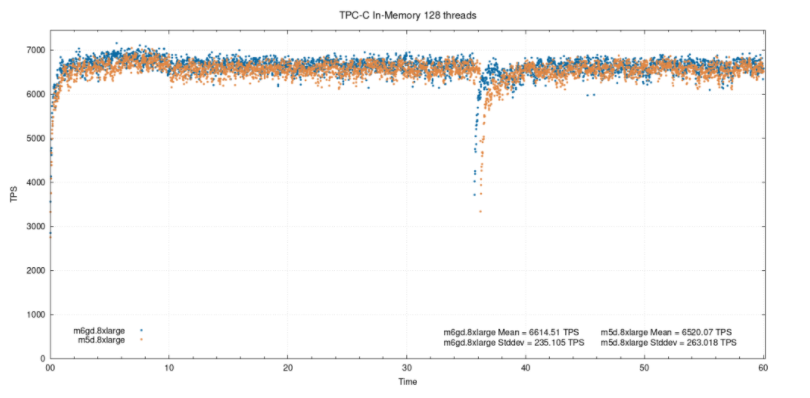
将实例逼近性能临界点(记住,两个实例均为32 cpu),我们发现差异进一步降低到4.5%。内存中128个线程:
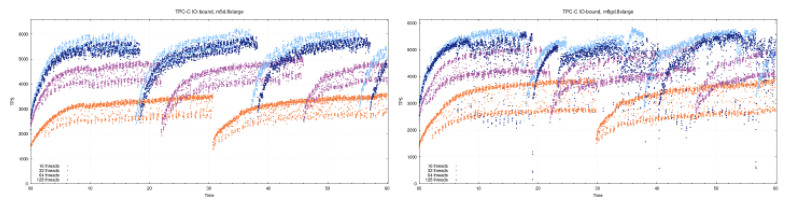
当两个实例都超过其临界点时,性能的差异可以忽略不计,尽管仍然有1.4%的差异。此外,当并发时,我们可以观察到ARM的吞吐量(tps)下降了6-7%,而在这32台vCPU机器上,当并发从64增加到128时,x86的吞吐量下降了4%。并非我们所测量的所有内容都适合基于Graviton2的实例。在IO密集型(约200G数据集,200个仓库,均匀分布)的场景中,我们看到两个实例之间的差异较小,并且在64和128个线程下,常规m5d实例的性能更好。可以在下面的组合图中看到这一点。造成这种情况的一个可能原因,尤其是对于m6gd.8xlarge在128个线程处发生的严重崩溃是因为它缺少m5d.8xlarge那样的第二个驱动器。目前尚无完全可比的实例,因此我们认为这是一个合理的比较。每种实例类型都有其优点。因为我们预期本地驱动器对测试的影响可以忽略,为了正确识别原因,需要进行更多的测试和分析。可以执行EBS的IO密集型测试,以尝试从中删除本地驱动器。可从此GitHub存储库中获取测试相关内容,测试结果,使用的脚本以及测试期间生成的数据的更多详细信息。总结
在我们执行的测试中,很少有ARM实例比x86实例慢的情况。在过去几天的整个测试过程中,测试结果均保持一致。尽管基于ARM的实例便宜25%,但在大多数测试中,与基于x86的实例相比,它可以显示15-20%的性能提升。因此,基于ARM的实例在所有方面具有更好的性价比。我们应该期望将来有越来越多的云提供商提供基于ARM的实例。如果您希望查看任何其他类型的基准测试,请告诉我们。