| 作者 | 时间 | QQ技术交流群 |
|---|---|---|
| perrynzhou@gmail.com | 2022/02/17 | 672152841 |
1.lustre架构
1.1 lustre是什么?
lustre 基于GNU GPL‘协议开源的分布式并行文件系统,目前主要是DDN维护。lustre由于非常容易扩展和极致的性能,常被用在超算、AI领域、视频存储等领域。lustre是通过内核的lustre客户端来访问文件对象。lustre的官网参考
https://www.lustre.org/
.lustre的官方的代码仓库git clone git://git.whamcloud.com/fs/lustre-release.git
1.2 lustre提供哪些功能?
lustre设计中最重要的是扩展性和性能。提高lustre的容量和文件系统带宽可以通过扩展更多的服务器到文件系统,通过增加lustre客户端增加并行访问lustre文件系统的性能。
lustre文件系统提供如下的功能:
标准的POSIX语义实现,lustre文件系统实现了标准的POSI语义
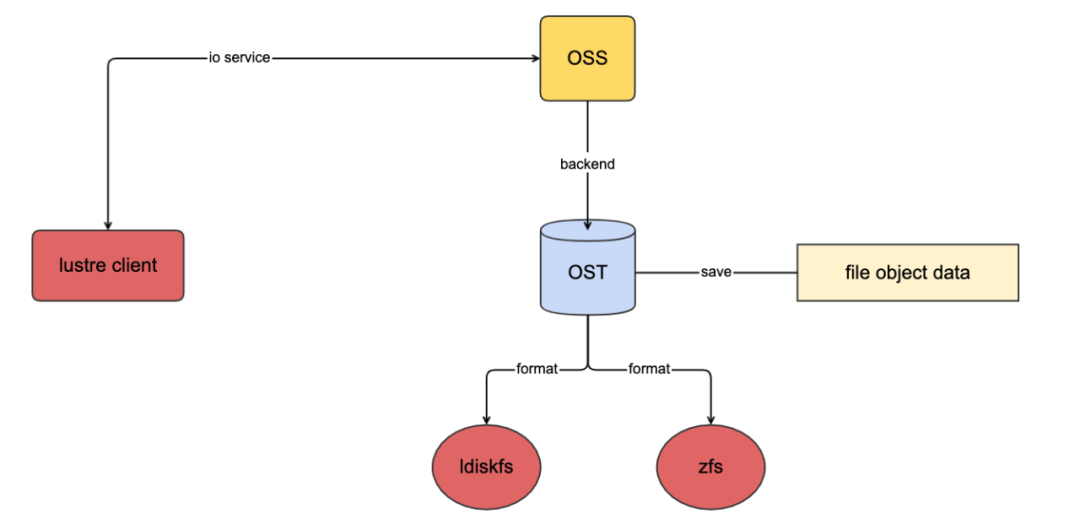
支持多个后端文件系统,目前lustre分布式文件系统支持ldiskfs和zfs两种文件系统,ldiskfs是基于ext4文件系统定制优化而来;zfs则是采用openzfs的项目。
在线文件系统检查,基于ldiskfs的后端存储的lustre文件系统提供lfsck检查和修复文件系统不一致的情况,lfsck可以在正在运行的lustre文件系统运行;如果基于zfs的后端存储的lustre文件系统,借助zfs的特性就不要类似于ldiskfs的lsck了,zfs自身会保证文件系统的一致性。
自定义文件布局控制,文件系统布局决定了数据放到哪些lustre的后端服务器,文件布局可以通过
lfs setstripe
来进行设置,默认的情况数据会在单个lustre后端服务器上,如果设置stripe大于1的情况,数据会被分片到多个lustre后端服务器上。支持高性能和大规模网络,lustre可以借助于RDMA、IB、OmniPath技术在TCP纸上提供低时延的高质量网络。

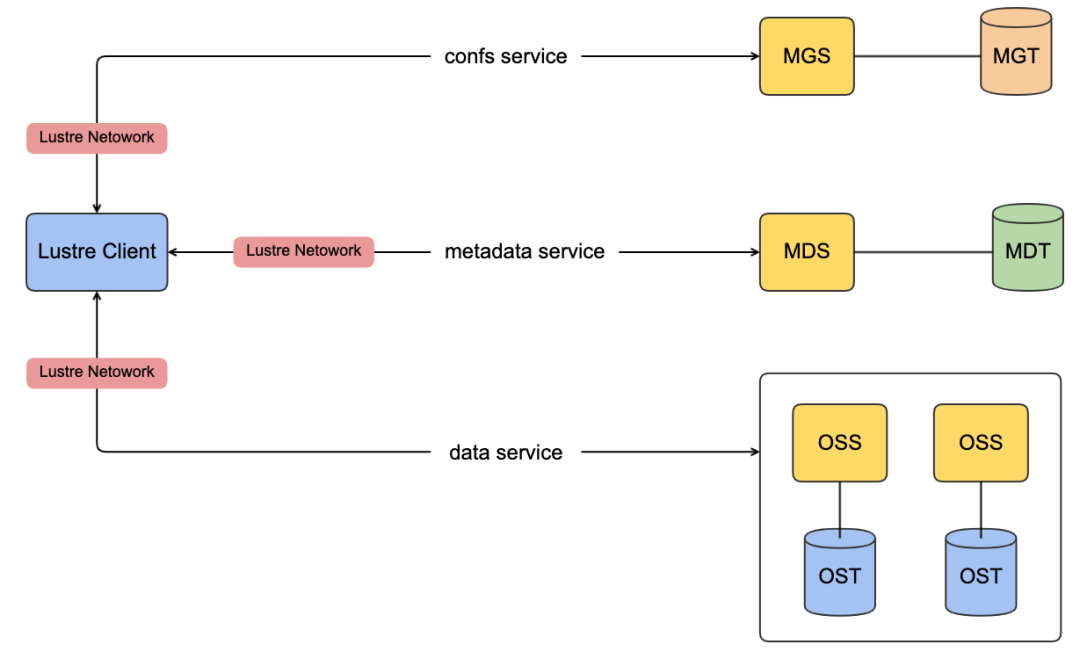
1.3 lustre核心组件
MGS(Management Server) :提供整个文件系统的配置信息,当mount文件系统的时候,lustre客户端联系MGS接收lustre文件系统的配置信息(这些信息包括当前lustre文件系统有哪些server),客户端获取到信息后完成初始化。其次MGS会通知lustre客户端整个集群的变化(osd宕机失联、参数调整),最后在lustre文件系统崩溃恢复中扮演重要角色。

MGT(Management Target):MGT是MGS用于存储lustre文件系统配置信息的块设备,MGT的容量最大需要100MB。

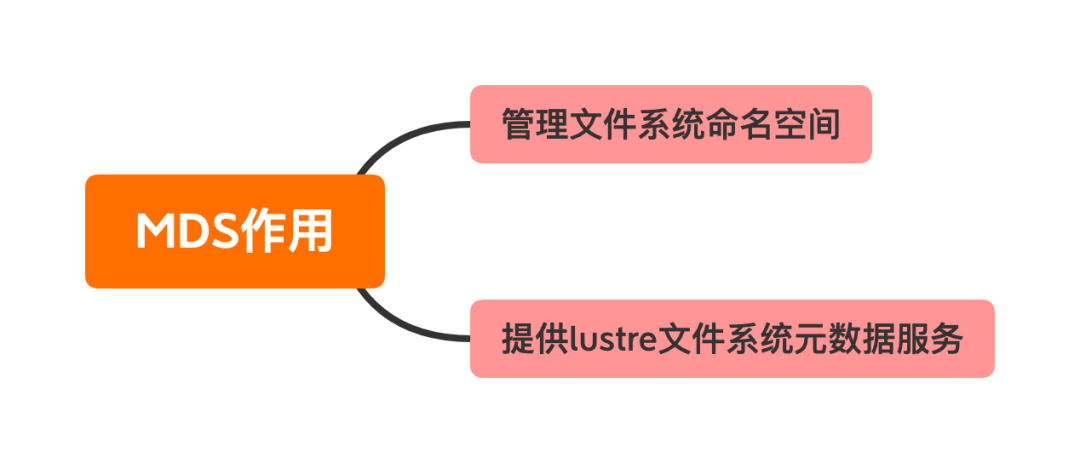
MDS(Meta Server):MDS负责管理文件系统统一的命名空间,同时提供文件系统的元数据访问服务,比如客户端的根据名称名称进行查找文件,目录,文件布局,访问权限等。lustre文件系统至少需要配置一个MDS,在硬件条件允许,可以配置多个MDS来分摊整个文件系统元数据的服务的压力
MDT(Metadata Target):MDS存储元数据信息的后端块设备。lustre文件系统至少需要一个MDT来存储文件系统的元数据。每个MDS至少需要一个MDT,同时MDT可以被多个MDS共享防止MDS服务宕机,但是在任何一个时刻MDT仅仅只能被一个MDS挂载

OSS(Object Storage Server):OSS负责管理文件对象数据,对lustre客户端提供完整文件数据的访问。lustre文件系统可以配置很多OSS服务提供更高的存储容量和更大的网络带宽。

OST(Object Storage Target):OSS使用的存储文件对象数据的块设备。一个OSS服务可以配置多个OST(一般情况一个OSS服务对应一个OST设备),这些OST可以在不同节点进行共享,特性和MDT一样,任意时刻只能被一个OSS使用(当出现某个OSS1服务挂掉,OSS1对应OST1;如果其他OSS2配置OST2,那么这个OSS2可以继续服务).整个lustre文件系统的总容量就是所有OST之和
Lustre Client:负责挂载lustre文件系统,提供统一的命名空间视图给用户。用户的所有操作都是通过lustre client来进行。如果访问元数据则去访问MDS,如果访问数据则去访问OSS
Lustre Network:lustre的网络协议,用于lustre客户端和服务端(MGS/MDS/OSS)之间的通信。目前支持低延迟的RDMA协议(支持IB/RoCE v2)
MGS,MDS,OSS节点是在lustre中可以成为前端,MDT和IST被ldiskfs或者zfs格式化来存储元数据和数据对象的成为后端
1.4 文件布局
lustre 是通过把一个文件分割为多个文件对象,然后存储在多个OST上的方式存储数据。文件的分割在lustre中叫做
stripe
,通过lfs setstripe
和lfs getstripe
设置和获取单个文件的stripe
信息.
// 环境是: lustre 2.14版本,一个server部署3个ost和1个mgs/mds
// 创建2个目录,一个目录设置stripe=3(3个ost),另外一个目录采用默认stripe=1
[root@CentOS-Lustre-Client ~]$ mkdir mnt/lustre/stripe_1_data
[root@CentOS-Lustre-Client ~]$ mkdir mnt/lustre/stripe_3_data
// 采用默认的stripe布局
[root@CentOS-Lustre-Client ~]$ lfs getstripe mnt/lustre/stripe_1_data/
/mnt/lustre/stripe_1_data/
stripe_count: 1 stripe_size: 1048576 pattern: 0 stripe_offset: -1
// 设置stripe=3,每个stripe的大小为1MB
[root@CentOS-Lustre-Client ~]$ lfs setstripe -S 1M -c 3 mnt/lustre/stripe_3_data/
[root@CentOS-Lustre-Client ~]$ lfs getstripe mnt/lustre/stripe_3_data/
/mnt/lustre/stripe_3_data/
stripe_count: 3 stripe_size: 1048576 pattern: raid0 stripe_offset: -1
// 拷贝3.6M文件到stripe_1_data和stripe_3_data目录
[root@CentOS-Lustre-Client ~]$ ls -l -1h go.tar.gz
-rw-r--r--. 1 root root 3.6M Jan 17 10:48 go.tar.gz
[root@CentOS-Lustre-Client ~]$ cp go.tar.gz mnt/lustre/stripe_1_data/
[root@CentOS-Lustre-Client ~]$ cp go.tar.gz mnt/lustre/stripe_3_data/
// 获取stripe_1_data的中go.tar.gz的布局,默认的情况下stripe=1,会把单个文件持续写入到单个ost上,不会跨ost写入。因此从布局信息上来看,文件仅仅只有一个文件对象。
[root@CentOS-Lustre-Client ~]$ lfs getstripe mnt/lustre/stripe_1_data/go.tar.gz
/mnt/lustre/stripe_1_data/go.tar.gz
// lmm_stripe_count表示文件被stripe的个数
lmm_stripe_count: 1
// lmm_stripe_size表示每次文件stripe后,文件stripe的大小,默认是1MB
lmm_stripe_size: 1048576
// lmm_pattern表示布局模式
lmm_pattern: raid0
lmm_layout_gen: 0
lmm_stripe_offset: 0
// obdidx:表示所在的那个index={obdidx}的ost上,objid是对象分片,根据这个可以找到对应ost上的数据
obdidx objid objid group
0 2 0x2 0
// 当前的stripe_3_data是设置了stripe=3,每个文件的stripe大小设置为1M,所以从布局信息来看,这个文件应该有3个分片,没别在ost1,ost0,ost2上。
[root@CentOS-Lustre-Client ~]$ lfs getstripe mnt/lustre/stripe_3_data/go.tar.gz
/mnt/lustre/stripe_3_data/go.tar.gz
lmm_stripe_count: 3
lmm_stripe_size: 1048576
lmm_pattern: raid0
lmm_layout_gen: 0
lmm_stripe_offset: 2
obdidx objid objid group
2 2 0x2 0
0 3 0x3 0
1 2 0x2 0
// lfs 命令使用
// [--stripe-count|-c <stripe_count>] [--stripe-size|-S <stripe_size>
$ lfs getstripe [--stripe-size] [--stripe-count] [--stripe-index] <directory|filename>
// lfs setstripe -c 3 -S 1M file-or-directory
$ lfs setstripe --stripe-size _stripe_size_ --stripe-count _stripe_count_ file-or-directory
lustre中有两种类型的布局,第一类是默认的正常(normal)文件布局;第二类是复合(composite)文件布局.先聊聊默认不,默认布局如下图所示.采用默认的布局时候,文件的每个stripe按照round-robin方式轮询当前集群中每个ost来放置数据分片对象。正常的文件布局是由stripe count和stripe size决定。stripe count决定使用多少个ost存储这些文件分片(stripe),stripe size决定往下一个ost开始写之前应该往当前ost写入的数据量.之前测试环境中一共有3个OST,如果我们写入7M数据写入到集群的stripe_3_data,数据会分3次来做,第一次是ost0会写入1M(chunk 1),ost1写1M(chhunk 2),ost2写入1M(chunk 3);第二次,回头又从ost0开始写入1M(chunk 4),ost1写入1M(chunk 5),ost2再次写入1M(chunk 6);第三次,最好还剩下1M数据,再次选择ost0写入1M数据(chunk 7).按照这个例子中的模型,这个7M的文件在lustre集群中一共有3个对象,ost0上有一个文件对象数据包括(chunk 1,chunk 4,chunk7);ost1有一个文件对象数据包括(chunk2,chunk5);ost2上游一个文件对象数据包括(chunk3,chunk6).一个文件在单个ost上的所有的文件chunks都被放到到一个文件文件对象上的。

lustre中的第二种复合布局,简单理解下就是假设一个2055MB文件,会有一些列的子布局数组组成,每个布局的stripe count和stripe size不同,这2055MB文件被分割为3个component,第一个component的stripe size=1M,stripe count=1;第二个component中stripe count=4, stripe size=1M;第三个component中stripe count=32,stripe size=4M.设置复合文件布局的例子参照如下
// 使用复合文件布局的命令
lfs setstripe [--component-end|-E end1] [STRIPE_OPTIONS] [--component-end|-E end2] [STRIPE_OPTIONS] ... filename
// 在stripe_component_data里面每个文件的创建都是采用复合文件布局,每个文件有3个componnent,第一个component中stripe count=1,stripe size在[0M,4M];第二个component中stripe count=4(-c 4),stripe size 在[4M,64M](-E 64M);最后一个component中stripe中指定了从ost4开始(-i 4),跨所有的ost(-c -1),stripe size在[64M,EOF].
$ lfs setstripe -E 4M -c 1 -E 64M -c 4 -E -1 -c -1 -i 4 mnt/lustre/stripe_component_data


默认的情况下lustre的整个metadata是存储在住的MDT上。没有任何的配置更改的情况下,lustre文件系统的整个元数据是存储在单个MDT上。在lustre的最近发布的版本中引入了
DNE(Distribute Namespace)
,整个DNE的特性允许lustre使用多个MDS,同时均衡元数据操作的压力。在lustre的DNE特性的实现上分为多个阶段,第一个阶段是实现Remote Directories(远程目录)
,远程目录允许lustre管理员设置父目录在主的MDT上,子目录可以设置到其他的非主的MDT上,在这个非主MDT上进行文件和目录的创建,元数据都会存在设置远程目录的的这个MDT上;第二个阶段是Striped Directories(目录条带化)
,针对已经设置目录条带化的目录,这个目录的所有的文件和子目录的metadata存储都是在lustre的多个MDT上(across multiple MDTs).文件stripe有对应的stripe count,目录stripe对应的也会有stripe count来决定目录条带华分布到多少个MDT上,但是目录条带华不像是文件条带化一样基于OSTd的round-robin方式,目录条带化市基于哈希函数计算该目录的元数据应该放置到哪个MDT上。第三个阶段是auto-striped directories
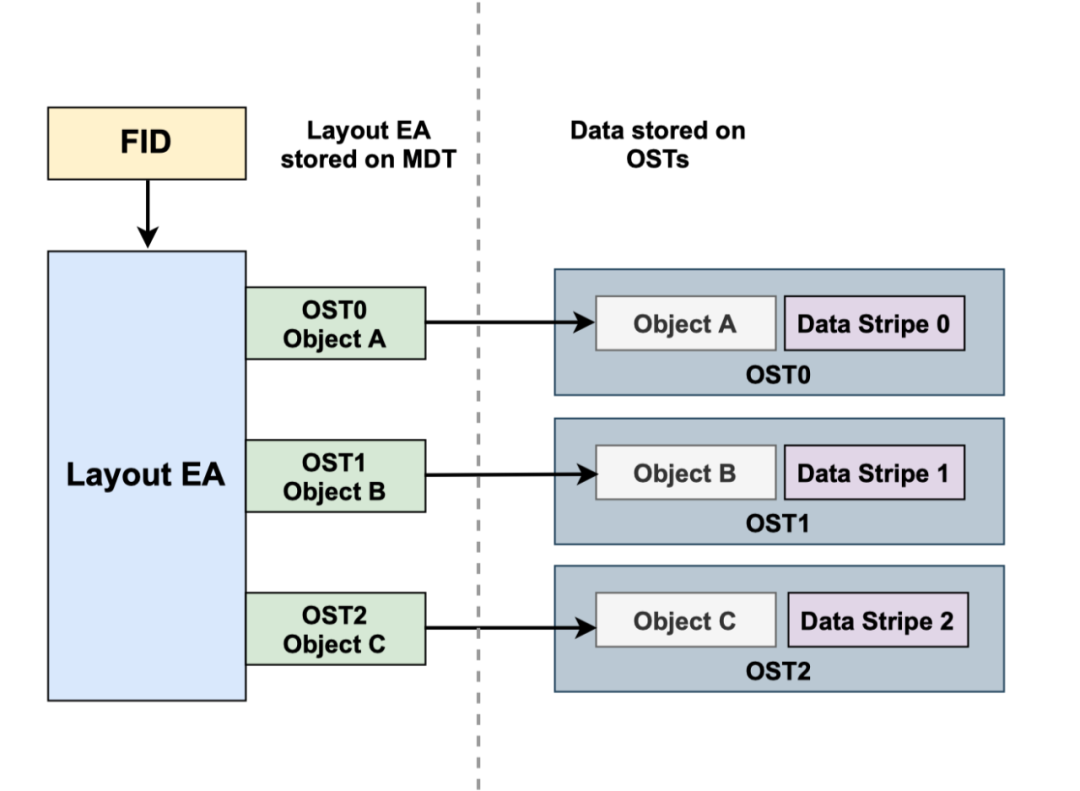
,设置自动条带化的目录从stripe count=1开始,随着该目录里的子目录和文件数不断增加,动态的增加stripe count。lustre中每个文件对象都有一个唯一的
fid(File Identifiers)
.FID是128位的字节长度去表示一个文件的对象。当访问一个文件时候,文件名称被lookup
在MDT上查找目录项时候,这个文件会以MDT对象中的FID来对应这个访问的文件。每个MDT的对象包含了一系列的扩展属性,其中的一个属性叫做Layout EA(Layout Extended Attribute)
,这个Layout EA
对于lustre客户端访问文件时候的映射表,这个映射表粗出了文件数据实际存储的位置信息,Layout EA
包含了ost的列表和访问文件的对象的FID.
// lustre中针对文件对象的fid
struct lu_fid {
// 序列号
__u64 f_seq;
// object id
__u32 f_oid;
// 版本号
__u32 f_ver;
} __attribute__((packed));
// 通过fid计算出对应的inode
static inline __u64 fid_flatten(const struct lu_fid *fid)
{
__u64 ino;
__u64 seq;
if (fid_is_igif(fid)) {
ino = lu_igif_ino(fid);
return ino;
}
seq = fid_seq(fid);
ino = (seq << 24) + ((seq >> 24) & 0xffffff0000ULL) + fid_oid(fid);
return ino ?: fid_oid(fid);
}
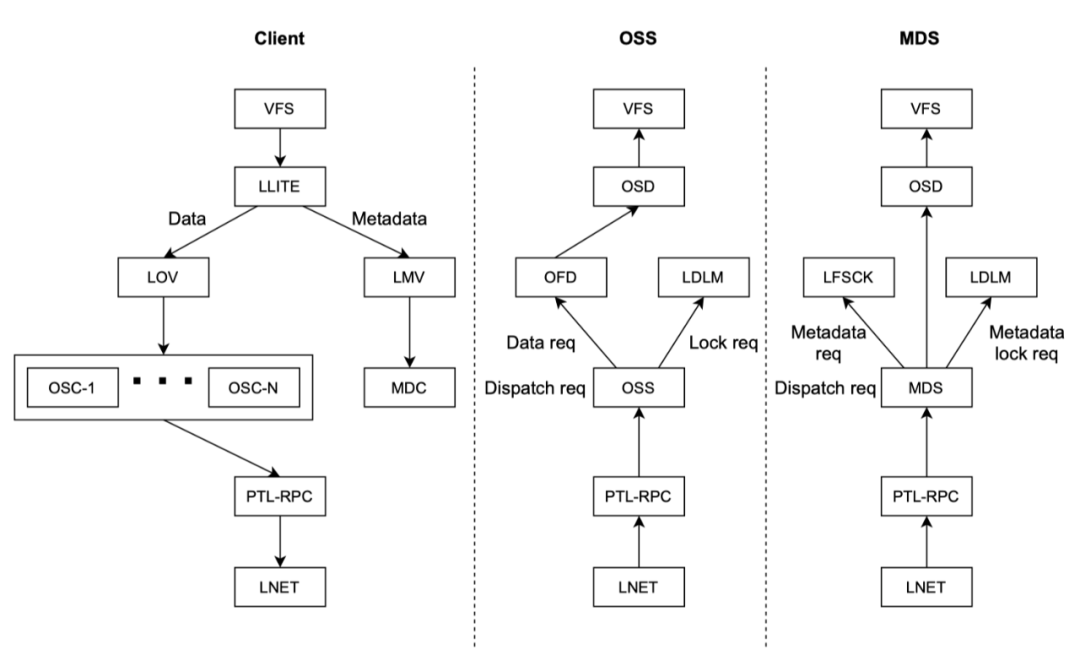
lutre的软件栈是由一些列分层的的组件组成,用户态进程发起read或者write,通过linux内核的虚拟文件系统(vfs)到lustre 的
llite
层(llite层实现了虚拟文件系统的POSIX的语义)。如果请求的是文件元数据,则路由到LMV(Logical Metadata Voliume
,LMV
是访问MDC(Metadata client)
的抽象层,对于每个MDT
都会有一个MDC
。如果访问的是数据,则路由到LOV(Logical Object Volume)
,LOV
是针对OSC(Object Storage Client)
抽象的访问层,对于lustre后端的每个OST都会有一个OSC
组件对应。lustre客户端和服务端是通过RPC(PTL-RPC)
子系统进行通信,而RPC
是运行在LNet(Lustre Networking)
子系统之上。当客户端进行IO访问的时候,发RPC请求到MDC,MDC和MDS进行交互然后打开文件,MDS响应客户端发送该文件的Layout EA
给到客户端,客户端拿到这些信息就知道文件有哪些对象和对象存储在哪些ost上,然后通过LOV/OSC
层发送请求OSS请求访问的数据,这个就lustre访问的基本流程