




一、Spark SQL 架构简介

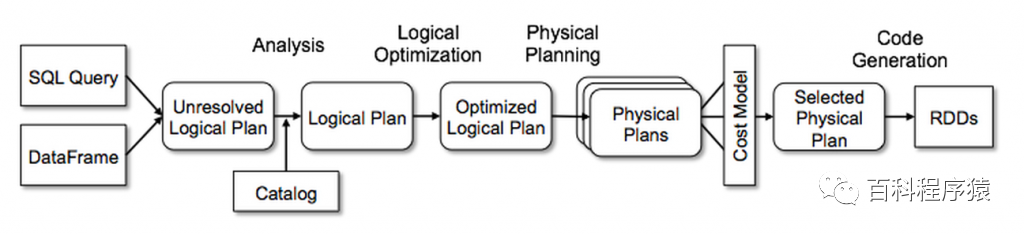
Sql语句经过Antlr4解析,生成Unresolved Logical Plan。 analyzer与catalog进行绑定(catlog存储元数据),生成Logical Plan。 optimizer对Logical Plan优化,生成Optimized LogicalPlan。 SparkPlan将Optimized LogicalPlan转换成 Physical Plan。 prepareForExecution()将 Physical Plan 转换成 executed Physical Plan。 execute()执行可执行物理计划,得到RDD。
三、Spark Catalyst扩展点
injectOptimizerRule – 添加optimizer自定义规则,optimizer负责逻辑执行计划的优化。
injectParser – 添加parser自定义规则,parser负责SQL解析。
injectPlannerStrategy – 添加planner strategy自定义规则,planner负责物理执行计划的生成。
injectResolutionRule – 添加Analyzer自定义规则到Resolution阶段,analyzer负责逻辑执行计划生成。
injectPostHocResolutionRule – 添加Analyzer自定义规则到Post Resolution阶段。
injectCheckRule – 添加Analyzer自定义Check规则。
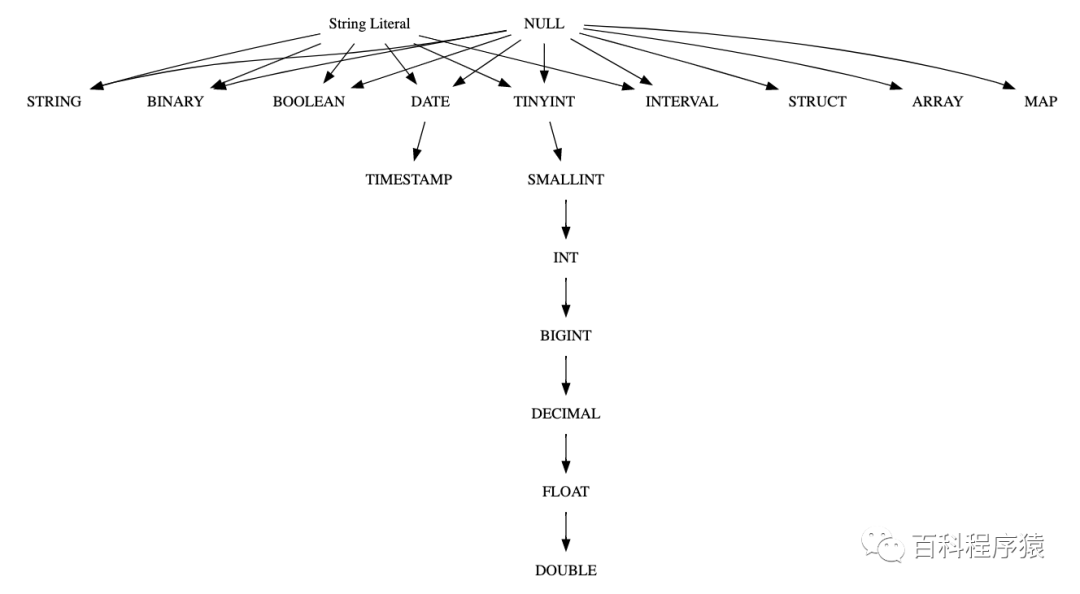

从以上的类型提升优先级可以看出,spark对字符串类型转数字类型的默认提升是不一致的,spark最低优先级为int类型,而hive的最低优先级类型为double类型,下面我们使用一个实际的例子来展示。
| id [string] | f1 [string] | f2 [double] |
| kn0001 | 1.5 | 1.4 |
| kn0002 | 2.5 | 2.4 |
| kn0003 | 3.5 | 3.4 |
| kn0004 | 4.5 | 4.4 |
| kn0005 | 5.5 | 5.4 |
== Physical Plan ==*(1) Project [id#10, f1#11, f2#12]+- *(1) Filter (isnotnull(f1#11) && (cast(f1#11 as int) > 3))
过滤得到的结果为:
| id | f1 | f2 |
| kn0004 | 4.5 | 4.4 |
| kn0005 | 5.5 | 5.4 |
== Physical Plan ==*(1) Project [id#10, f1#11, f2#12]+- *(1) Filter (isnotnull(f1#11) && (cast(f1#11 as double) > 3.0))
过滤得到的结构为:
| id | f1 | f2 |
| kn0003 | 3.5 | 3.4 |
| kn0004 | 4.5 | 4.4 |
| kn0005 | 5.5 | 5.4 |
TableScanalias: upload_20211228102754filterExpr: (f1 > 3) (type: boolean)Statistics: Num rows: 1 Data size: 80 Basic stats: COMPLETE Column stats: NONEFilter Operatorpredicate: (f1 > 3) (type: boolean)Statistics: Num rows: 1 Data size: 80 Basic stats: COMPLETE Column stats: NONESelect Operatorexpressions: id (type: string), f1 (type: string), f2 (type: double)outputColumnNames: _col0, _col1, _col2Statistics: Num rows: 1 Data size: 80 Basic stats: COMPLETE Column stats: NONE
查询得到的结果:
| id | f1 | f2 |
| kn0003 | 3.5 | 3.4 |
| kn0004 | 4.5 | 4.4 |
| kn0005 | 5.5 | 5.4 |
TableScanalias: upload_20211228102754filterExpr: (f1 > 3.0) (type: boolean)Statistics: Num rows: 1 Data size: 80 Basic stats: COMPLETE Column stats: NONEFilter Operatorpredicate: (f1 > 3.0) (type: boolean)Statistics: Num rows: 1 Data size: 80 Basic stats: COMPLETE Column stats: NONESelect Operatorexpressions: id (type: string), f1 (type: string), f2 (type: double)outputColumnNames: _col0, _col1, _col2Statistics: Num rows: 1 Data size: 80 Basic stats: COMPLETE Column stats: NONE
查询得到的结果:
| id | f1 | f2 |
| kn0003 | 3.5 | 3.4 |
| kn0004 | 4.5 | 4.4 |
| kn0005 | 5.5 | 5.4 |
五、利用Catalyst解决SPARK在默认类型提升上与HIVE的不一致
首先我们知道Spark支持catalyst的扩展点,以下是通过rule对执行计划进行特定的修改,目前存在类型提升的运算符组要有四个:>、>=、<、<=。我们在程序中需要去捕获这四类运算符,并且运算符的的左支的类型被强制转换为LongType或IntegerType,右支为数字类型为LongType或IntegerType,我们需要强制将右支的类型修改为DoubleType,这样就能保持和HIVE的一致性。
import org.apache.spark.internal.Loggingimport org.apache.spark.sql.types.DataTypesimport org.apache.spark.sql.catalyst.rules.Ruleimport org.apache.spark.sql.catalyst.plans.logical.LogicalPlanimport org.apache.spark.sql.types.DataTypes.{IntegerType, LongType}import org.apache.spark.sql.catalyst.expressions.{Cast, Expression, Literal}import org.apache.spark.sql.catalyst.expressions.{GreaterThan, GreaterThanOrEqual, LessThan, LessThanOrEqual}/**** 解决当字段为字符串,但数据为数字类型时,sql中若使用比较符号时,存在类型提升不足的问题。* 例如:字段f1为浮点型数据,但是条件给定为:f1>5,spark默认会解析为:cast(cast(f1 as string) as int) > 3* 这样就会损失精度,f1=3.3将不会满足条件,被过滤掉*/object CastTypeOptimization extends Rule[LogicalPlan] with Logging{/*** 检查当前节点是否符合强制转换类型的规则节点* @param left 左节点* @param right 右节点* @return 是否满足条件*/def checkRule(left: Expression, right: Expression): Boolean = {var flag = falseif((left.isInstanceOf[Cast] && left.dataType==LongType && right.isInstanceOf[Literal] && right.dataType==LongType)||(left.isInstanceOf[Cast] && left.dataType==IntegerType && right.isInstanceOf[Literal] && right.dataType==IntegerType)){flag = true}flag}/*** 修改强制转换的类型为DoubleType* @param plan 执行计划* @return 新的执行计划*/override def apply(plan: LogicalPlan): LogicalPlan = {plan transformAllExpressions {case GreaterThan(left, right) if(checkRule(left, right)) => {val leftCastExp = Cast(left.children.head, DataTypes.DoubleType)GreaterThan(leftCastExp, right)}case LessThan(left, right) if(checkRule(left, right)) => {val leftCastExp = Cast(left.children.head, DataTypes.DoubleType)LessThan(leftCastExp, right)}case GreaterThanOrEqual(left, right) if(checkRule(left, right)) => {val leftCastExp = Cast(left.children.head, DataTypes.DoubleType)GreaterThanOrEqual(leftCastExp, right)}case LessThanOrEqual(left, right) if(checkRule(left, right)) => {val leftCastExp = Cast(left.children.head, DataTypes.DoubleType)LessThanOrEqual(leftCastExp, right)}}}}
//添加Cast优化器sparkSession.experimental.extraOptimizations = Seq(CastTypeOptimization)
现在使用spark再次执行分析语句:"select * from table where f1 > 3":
== Physical Plan ==*(1) Project [id#10, f1#11, f2#12]+- *(1) Filter (isnotnull(f1#11) && (cast(f1#11 as double) > 3.0))
过滤得到的结构为:
| id | f1 | f2 |
| kn0003 | 3.5 | 3.4 |
| kn0004 | 4.5 | 4.4 |
| kn0005 | 5.5 | 5.4 |
从结果可以看出,通过自定义的优化器,且在不变更程序的条件下,就可以让执行保持和hive的一致。

