




前言 准备工作 部署扩展 创建 Hive Catalog 使用 Hive Dialect 总结 未来 交流
 GitHub 地址
GitHub 地址 一、前言
最近有很多小伙伴问,dlink 如何连接 Hive 进行数据开发?
关于 dlink 连接 Hive 的步骤同 Flink 的 sql-client
,只不过它没有默认加载的配置文件。下文将详细讲述对 Hive 操作的全过程。
二、准备工作
由于搭建 Hive 的开发环境会涉及到众多组件和插件,那其版本对应问题也是至关重要,它能帮我们避免很多不必要的问题,当然小版本号之间具备一定的兼容性。
我们先来梳理下本教程的各个组件版本:
| 组件 | 版本 |
| Dlink | 0.3.2 |
| Flink | 1.12.4 |
| Hadoop | 2.7.7 |
| Hive | 2.3.6 |
| Mysql | 8.0.15 |
| 所属组件 | 插件 | 版本 |
| Dlink | dlink-client | 1.12 |
| Dlink & Flink | flink-sql-connector-hive | 2.3.6_2.11-1.12.3 |
| Dlink & Flink | flink-shaded-hadoop-3-uber | 3.1.1.7.2.8.0-224-9.0 |
三、部署扩展
flink-sql-connector-hive-2.3.6_2.11-1.12.3.jar和
flink-shaded-hadoop-3-uber-3.1.1.7.2.8.0-224-9.0.jar两个插件分别加入到 Dlink 的 plugins 目录与 Flink 的 lib 目录下即可,然后重启二者。当然,还需要放置
hive-site.xml,位置自定义,Dlink 可以访问到即可。
四、创建 Hive Catalog
已知,Hive 已经新建了一个数据库实例 hdb
,创建了一张表 htest
,列为 name
和 age
,存储位置默认为 hdfs:///usr/local/hadoop/hive-2.3.9/warehouse/hdb.db
。(此处为何 2.3.9 呢,因为 flink-sql-connector-hive-2.3.6_2.11-1.12.3.jar
只支持到最高版本 2.3.6,小编先装了个 2.3.9 后装了个 2.3.6,尴尬 > _ < ~)
CREATE CATALOG myhive WITH (
'type' = 'hive',
'default-database' = 'hdb',
'hive-conf-dir' = '/usr/local/dlink/hive-conf'
);
-- set the HiveCatalog as the current catalog of the session
USE CATALOG myhive;
select * from htest
在 Dlink 编辑器中输入以上 sql ,创建 Hive Catalog,并查询一张表。
其中,hive-conf-dir
需要指定 hive-site.xml
的路径,其他同 Flink 官方解释。
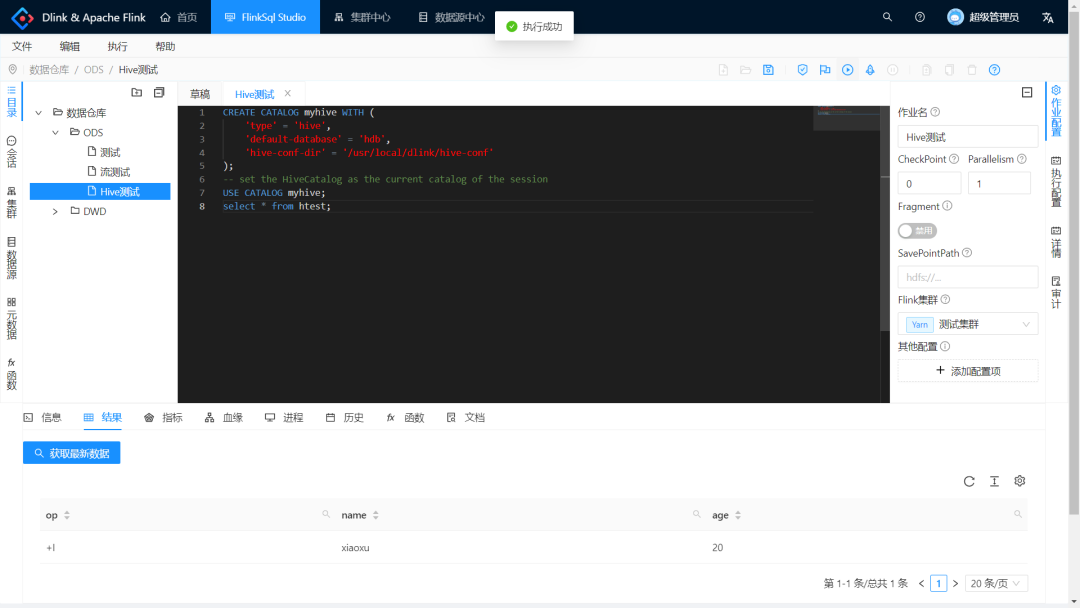
执行查询后(记得选中执行配置的预览结果),可以从查询结果中查看到 htest 表中只有一条数据。(这是正确的,因为小编太懒了,只随手模拟了一条数据)
此时可以使用 FlinkSQL 愉快地操作 Hive 的数据了。
五、使用 Hive Dialect
很熟悉 Hive 的语法以及需要对 Hive 执行其自身特性的语句怎么办?
同 Flink 官方解释一样,只需要使用 SET table.sql-dialect=hive
来启用方言即可。注意有两种方言 default
和 hive
,它们的使用可以随意切换哦~
CREATE CATALOG myhive WITH (
'type' = 'hive',
'default-database' = 'hdb',
'hive-conf-dir' = '/usr/local/dlink/hive-conf'
);
-- set the HiveCatalog as the current catalog of the session
USE CATALOG myhive;
-- set hive dialect
SET table.sql-dialect=hive;
-- alter table location
alter table htest set location 'hdfs:///usr/htest';
-- set default dialect
SET table.sql-dialect=default;
select * from htest;
上述 sql 中添加了 Hive Dialect 的使用,FlinkSQL 本身不支持 alter table .. set location ..
的语法,使用 Hive Dialect 则可以实现语法的切换。本 sql 内容对 htest 表进行存储位置的改变,将其更改为一个新的路径,然后再执行查询。
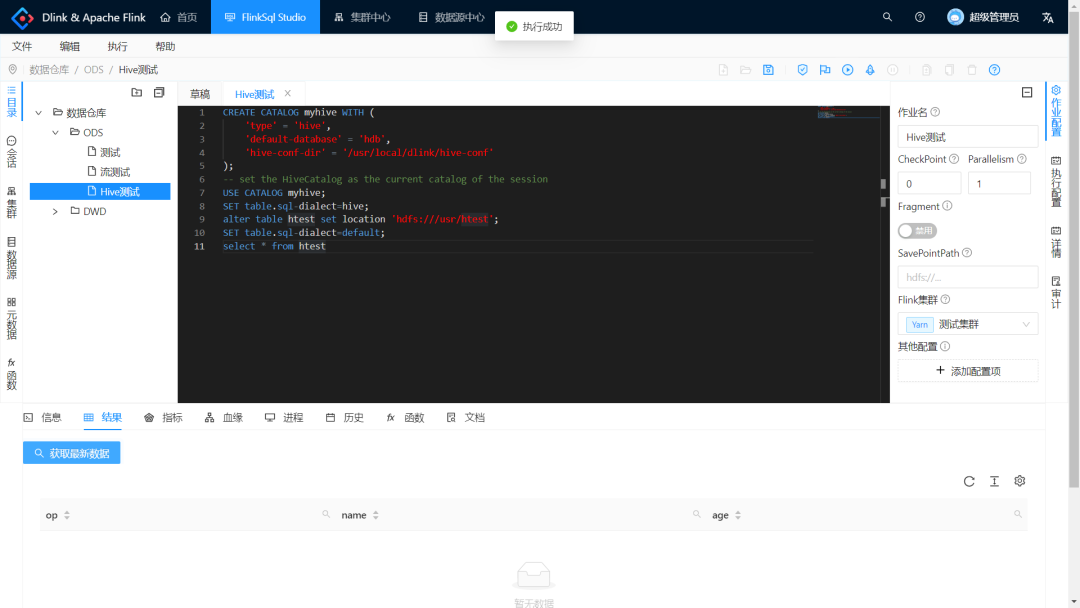
由上图可见,被更改过 location 的 htest 此时查询没有数据,是正确的。
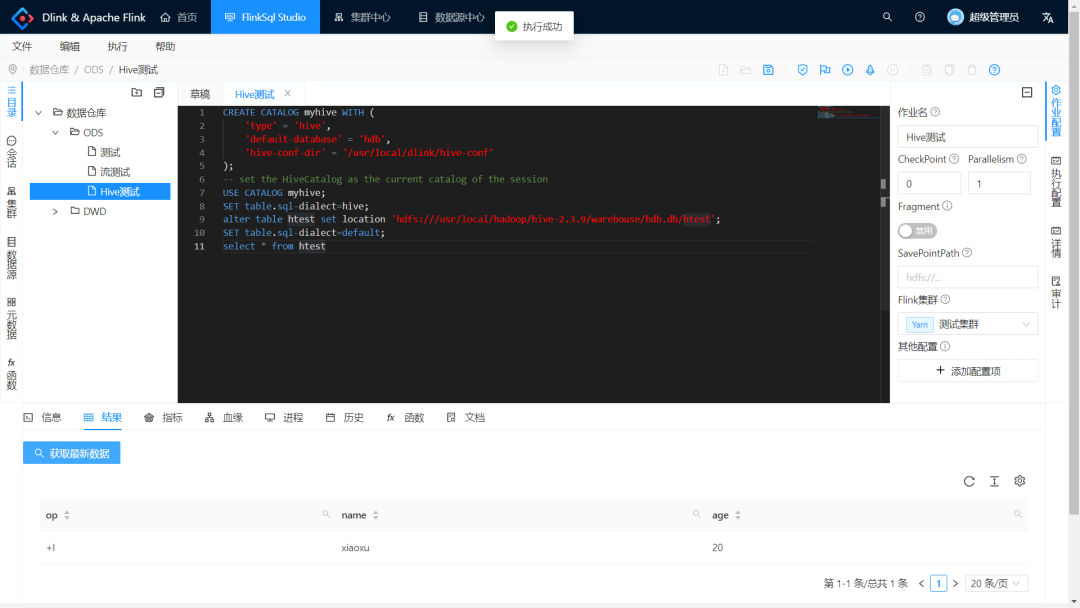
然后将 location 更改为之前的路径,再执行查询,则可见原来的那条数据,如下图所示。
六、总结
由上所知,Dlink 以更加友好的交互方式展现了 Flink 集成 Hive 的部分功能,当然其他更多的 Hive 功能需要您自己在使用的过程中去体验与挖掘。
目前,Dlink 支持 Flink 绝大多数特性与功能,集成与拓展方式与 Flink 官方文档描述一致,只需要在 Dlink 的 plugins 目录下添加依赖即可。
需要注意的是,由于 Dlink 是一个基于 SpringBoot 的 B/S 应用,难免存在依赖冲突问题,可以通过 Nginx 前后端分离部署来避免一部分问题;而对于 mysql-cdc 等包,由于内部依赖冲突问题,会导致 Dlink 自身无法正常启动,(da lao 可以自行排查依赖冲突问题并重新打包)该问题目前有相应的解决方案,需要等待后续版本的发布。
七、未来
Dlink 预计十一月中下旬带来 0.4.0 版本,新增核心功能为 yarn-application 等的 FlinkSQL 提交与用户自定义 Jar 提交管理、定时任务调度接口开放等,并对多种任务提交的方式进行交互合并改进。
此外,《Dlink 实时计算平台——功能篇》将在主要核心功能稳定后发布。
Dlink 将紧跟 Flink 官方社区发展,为推广及发展 Flink 的应用而奋斗,打造 FlinkSQL 的最佳搭档的形象。
八、交流
欢迎您加入社区交流分享与批评,也欢迎您为社区贡献自己的力量。
QQ社区群:543709668,申请备注 “ Dlink ”,不写不批
微信社区群(强烈推荐):添加小编微信 wenmo_ai ,邀请您进群。


扫描二维码获取
更多精彩
DataLink
数据中台

