





jps
top -Hp 1
printf "%x" 355
jstack 1 | grep 163

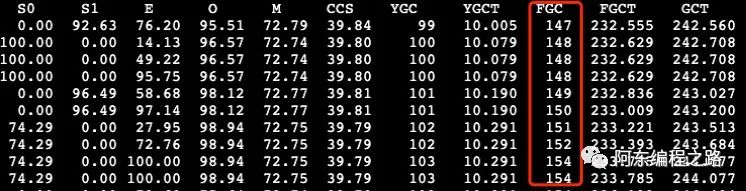
jstat -gcutil 1 2000
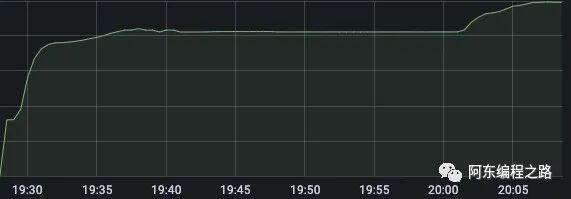
jmap -heap 1
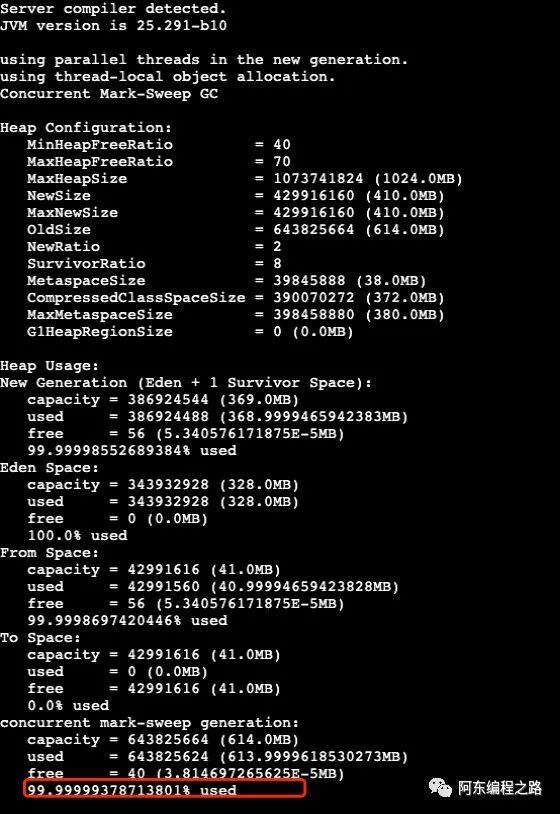
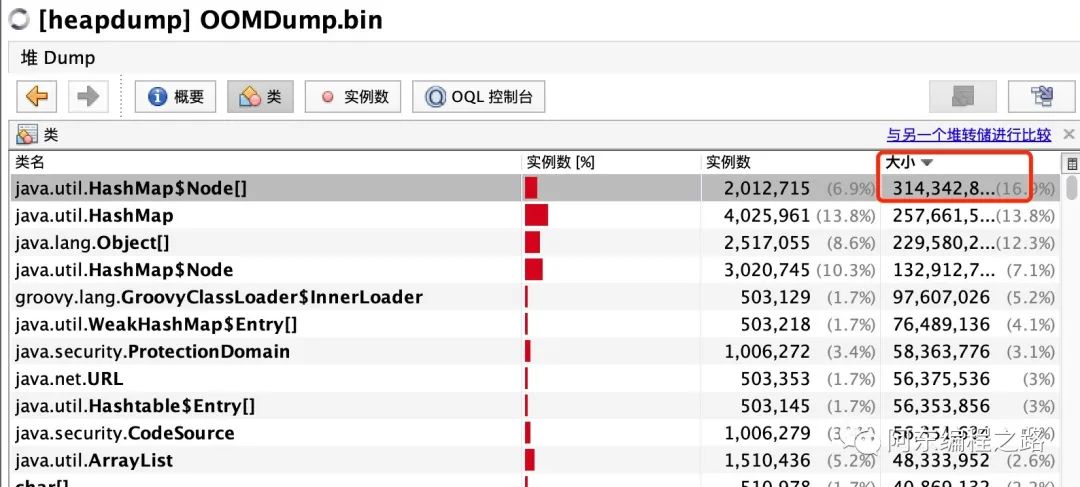
jmap -dump:live,format=b,file=OOMDump.bin 1
jvisualvm
/*** 执行脚本* @param script 脚本,例如:"return '1'.equals(a)"* @param params 脚本变量,例如:"'a':'1'"* @return 执行结果*/public static Boolean executeGroovy(String script, Map<String, String> params) {// 使用 groovyClassLoader 将脚本加载成 Groovy 对象Class groovyClass = groovyClassLoader.parseClass(script);if (groovyClass == null) {return false;}Binding binding = new Binding();// 绑定变量params.entrySet().stream().forEach(e -> {binding.setVariable(e.getKey(), e.getValue());});// 创建 Groovy 脚本对象Script scriptObj = InvokerHelper.createScript(groovyClass, binding);try {// 执行脚本return (Boolean) scriptObj.run();} catch (Exception e) {log.error("脚本执行出错,script:{}, error:{}", script, e.getMessage(), e);return false;}}
public Class parseClass(String text) throws CompilationFailedException {// 默认以时间戳+脚本的hash值作为groovy的名称return parseClass(text, "script" + System.currentTimeMillis() +Math.abs(text.hashCode()) + ".groovy");}public Class parseClass(final String text, final String fileName) throws CompilationFailedException {GroovyCodeSource gcs = AccessController.doPrivileged(new PrivilegedAction<GroovyCodeSource>() {public GroovyCodeSource run() {return new GroovyCodeSource(text, fileName, "/groovy/script");}});gcs.setCachable(false);// 加载return parseClass(gcs);}
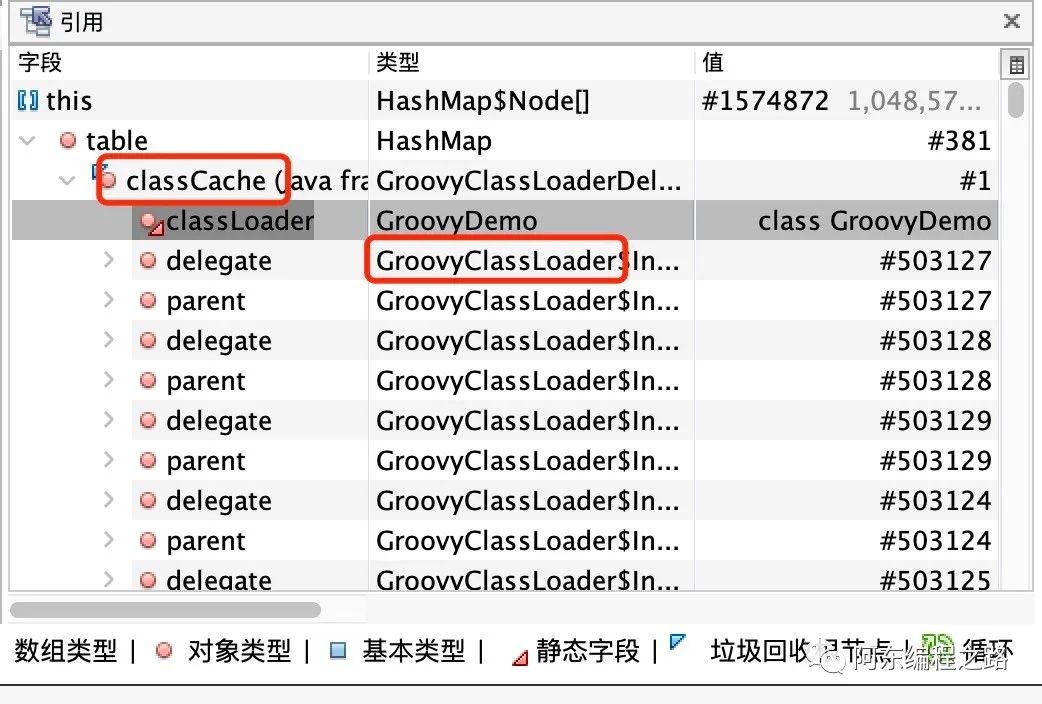
protected final Map<String, Class> classCache = new HashMap<String, Class>();private Class doParseClass(GroovyCodeSource codeSource) {......for (Object o : collector.getLoadedClasses()) {Class clazz = (Class) o;String clazzName = clazz.getName();definePackageInternal(clazzName);// 重点在这里,会将Groovy脚本类放进classCache里setClassCacheEntry(clazz);if (clazzName.equals(mainClass)) answer = clazz;}return answer;}protected void setClassCacheEntry(Class cls) {// 吐槽一下这里的锁真大!synchronized (classCache) {// 以刚才默认生成名称为key,Groovy class对象为value放进classCacheclassCache.put(cls.getName(), cls);}}
// GroovyClassLoader#parseClass()源码public Class parseClass(GroovyCodeSource codeSource, boolean shouldCacheSource) throws CompilationFailedException {synchronized (sourceCache) {// 从缓存中获取Class answer = sourceCache.get(codeSource.getName());if (answer != null) return answer;answer = doParseClass(codeSource);// 是否使用缓存if (shouldCacheSource) sourceCache.put(codeSource.getName(), answer);return answer;}}
// 本地缓存private static Map<String, SoftReference<Class>> scriptCache = new ConcurrentHashMap<>();public static Boolean executeGroovy(String script, Map<String, String> params) {// 先从本地缓存取,没有再去使用groovyClassLoader加载SoftReference<Class> softReference = scriptCache.get(script);Class groovyClass;if (softReference == null || softReference.get() == null) {groovyClass = compiledScript(script);} else {groovyClass = softReference.get();}......}// 解析private static Class compiledScript(String script) {try {Class gvClz = groovyClassLoader.parseClass(script);// 解析完放进缓存scriptCache.put(script, new SoftReference<>(gvClz));return gvClz;} catch (Exception e) {log.error("编译脚本出错,script:{}, error:{}", script, e.getMessage(), e);return null;}}
 。
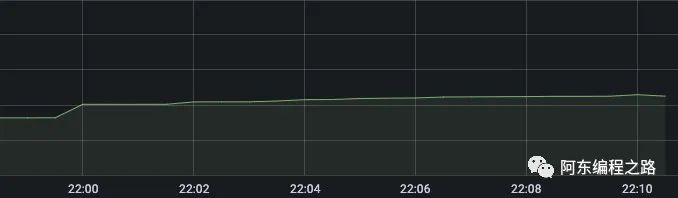
。

 !
!
文章转载自阿东编程之路,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
