





平时ogg数据同步的案例中,遇到最多就是常见RDBMS之间的同步,源端和目标端分别找合适安装包,按照经典的抽取、传输、复制3个进程进行实施,例如oracle到oracle,oracle到mysql,sqlserver到oracle等等场景。早就知道ogg也可以同步数据到Hahoop等BigData平台及Kafka等消息中间件进行同步,今天终于遇到这样的实际需求了。
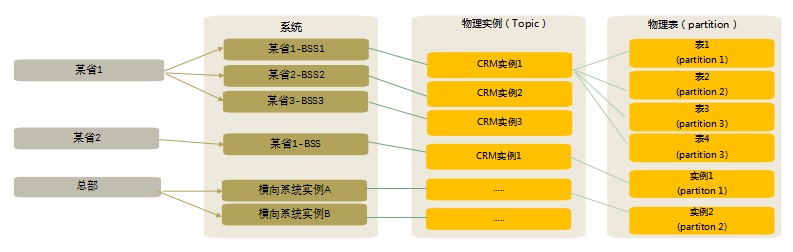
需求:某系统需要原生实时数据采集到大数据平台。根据统一的实现方案,kafka规划原则:
省分topic隔离。不同省分,不共用相同的topic;
依据省份生产库实例建设情况,按实例划分对接topic,要求kafka一个topic对应一个物理数据库实例;
为保证每张表数据在kafka中保证“有序”,要求每张表对应topic的一个partition;
具体省分kafka规划方案如下:

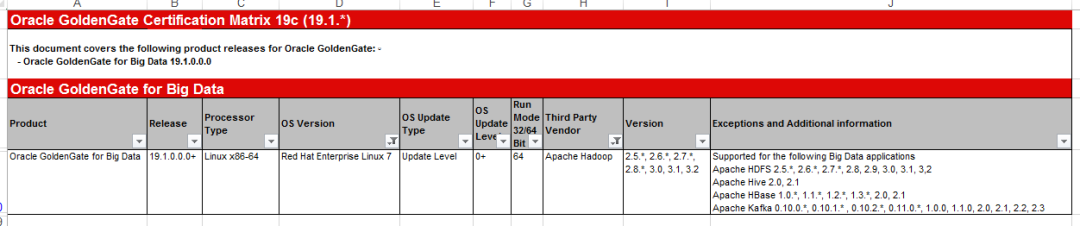
针对本次环境源端是oracle12c数据库,目标端是Kafka2.11-1.0.2集群。源端使用ogg12cfor oracle即可,目标端我们需要使用OGG_BigData的软件包来实现的。根据官方的版本适配文档,确定使用19c19.1来搭建。
源端软件包
123014_fbo_ggs_Linux_x64_shiphome.zip
(12.3.0.1.4OGGCORE_12.3.0.1.0_PLATFORMS_180415.0359_FBO)
目标端软件包
OGG_BigData_Linux_x64_19.1.0.0.1.zip
(19.1.0.0.2OGGCORE_OGGADP.19.1.0.0.2_PLATFORMS_190916.0039)
对于kafka集群来说,ogg的目标端程序实际上是作为kafka的生产者客户端,把解析trail文件得到的数据推送到kafka中。
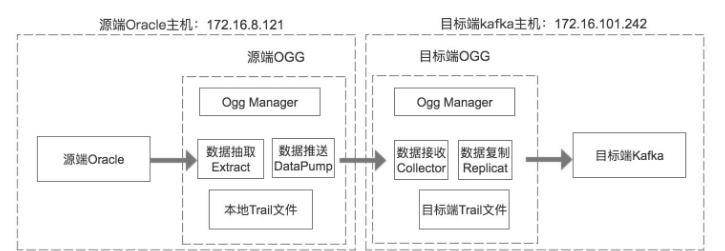
源端数据库12cRAC的多租户模式,使用ogg12c12.3的集成模式,按常规配置ex_kaf、dp_kaf进程即可。
抽取进程EX_KAF参数
##view param EX_KAF EXTRACT ex_kaf SETENV (NLS_LANG='AMERICAN_AMERICA.ZHS16GBK') setenv (ORACLE_HOME='/u01/app/oracle/product/12.2.0.1/db_1') SETENV (ORACLE_SID='db2') USERID c##ggs@db, PASSWORD XXXX EXTTRAIL ./dirdat/ha --DISCARDFILE ./dirrpt/ex_kaf.DSC, APPEND,MEGABYTES 100 -- report info REPORTCOUNT EVERY 10 MINUTES, RATE WARNLONGTRANS 2h,CHECKINTERVAL 30m dboptions allowunusedcolumn fetchoptions nousesnapshot LOGALLSUPCOLS //加入前镜像(12c新版本特有参数,遇到josn格式不固定,新老参数同时加) getupdatebefores // 加入前镜像(老版本参数) nocompressdeletes 加入前镜像(老版本参数) nocompressupdates 加入前镜像(老版本参数) --crm3hj 208 tables TABLE crm3hj.CUST.TAB; |
##view param DP_KAF EXTRACT dp_kaf PASSTHRU 传输进程透传,不做任何处理 rmthost 192.168.100.100, mgrport 7809 , TCPBUFSIZE 300000, TCPFLUSHBYTES 300000//目标端地址 rmttrail ./dirdat/hk EOFDELAYCSECS 10 --gettruncates --crm3hj 8 tables TABLE crm3hj.CUST.TAB; |
解压ogg压缩包
tar xvfOGG_BigData_Linux_x64_19.1.0.0.1.tar -C oggdata/ggv191adp
因为要登录到kafka集群,需要引用对应jar包,故需部署
tar -zxvfkafka_2.11-1.0.2.tgz -C oggdata/kafka
kafka的lib目录为 /oggdata/kafka/kafka_2.11-1.0.2/libs
参数文件配置,这里除了rp_kaf进程参数文件外,还有kafka属性参数文件、生产者属性配置参数文件。

rp_kaf.prm参数文件
[oracle@server003 dirprm]$ cat rp_kaf.prm REPLICAT rp_kaf //定义进程名称 sourcedefs ./dirdef/o2kaf_jt.def //指定使用源和目标的表映射文件,高版本可省略 TARGETDB LIBFILE libggjava.so SET property=dirprm/kafka_crm_ha.props //定义kafka一些适配性的库文件以及配置文件,配置文件指定属性文件 --reperror default, abend reperror default, discard //错误处理,这里将错误信息记录DSC文件 DISCARDFILE ./dirrpt/rp_kaf.DSC, APPEND, MEGABYTES 4096 对DSC文件的属性定义 REPORTCOUNT EVERY 10 MINUTES, RATE 报告指定10min统计一次报告 --grouptransops 10000 //组提交,以事务传输时,事务合并的单位,减少IO操作 MAP CRM3HJ.CUST.TAB, TARGET CUST. TAB; //具体表的映射配置 |
kafka_crm_ha.props参数文件
[oracle@server003 dirprm]$ cat kafka_crm_ha.props gg.handlerlist=kafkahandler //handler类型 gg.handler.kafkahandler.type=kafka gg.handler.kafkahandler.topicMappingTemplate=tp_share_crm //指定kafka的topic gg.handler.kafkahandler.KafkaProducerConfigFile=custom_kafka_producer_JT.properties 指定kafka生产者配置文件 gg.handler.kafkahandler.ProducerRecordClass=oracle.goldengate.handler.kafka.MyCreateProducerRecordHa//生产者方法 gg.handler.kafkahandler.BlockingSend=false gg.handler.kafkahandler.includeTokens=false gg.handler.kafkahandler.mode=op //OGG for BigData中传输模式,即op为一次SQL传输一次,tx为一次事务传输一次 gg.handler.kafkahandler.format=json #传输的消息最终解析的格式,格式相关 gg.handler.kafkahandler.format.includePrimaryKeys=true gg.handler.kafkahandler.format.insertOpKey=I gg.handler.kafkahandler.format.updateOpKey=U gg.handler.kafkahandler.format.deleteOpKey=D gg.handler.kafkahandler.authType=kerberos //kerberos安全认证相关 gg.handler.kafkahandler.kerberosKeytabFile=/home/oracle/KDC/kafka_XXXX.keytab gg.handler.kafkahandler.kerberosPrincipal=kafka_XXXX@HADOOP.XXXX.CN goldengate.userexit.timestamp=utc+8 goldengate.userexit.writers=javawriter javawriter.stats.display=true javawriter.stats.full=true javawriter.bootoptions=-Xmx512m -Xms32m -Djava.class.path=ggjava/ggjava.jar -Djava.security.krb5.conf=/etc/krb5.conf -Djava.security.auth.login.config=/home/oracle/kafka_jass.conf //JVM设置 gg.log=log4j //日志记录 gg.log.level=INFO gg.report.time=30sec gg.classpath=dirprm/:/oggdata/kafka/kafka_2.11-1.0.2/libs/*:/oggdata/ggv191adp/:/oggdata/ggv191adp/lib/* #Kafka的lib目录 |
核心参数说明:
custom_kafka_producer.properties参数文件
[oracle@server003 dirprm]$ cat custom_kafka_producer_JT.properties bootstrap.servers=XXXX.COM //kafka集群的broker的地址 acks=1 //参考KAFKA的acks参数 compression.type=gzip //压缩类型 reconnect.backoff.ms=1000 //重连延时 max.request.size=5024000 //请求发送设置 send.buffer.bytes=5024000 value.serializer=org.apache.kafka.common.serialization.ByteArraySerializer key.serializer=org.apache.kafka.common.serialization.ByteArraySerializer batch.size=102400 linger.ms=10000 security.protocol=SASL_PLAINTEXT sasl.kerberos.service.name=kafka // kerberos安全认证相关 saal.machanism=GSSAPI |
测试实践过程中,遇到最大的问题就是默认情况下,ogg会把所有表都放在同一topic下,而根据规范文档,不同的表要对应同一topic下的不同分区。
实际需求是每个表对应一个partition,例如

我们在kafka属性参数文件中,可以指定自定义生产者方法,继承ogg自带的生产者父类,编写自己的生产者方法这样就能实现表与分区的对应关系。
gg.handler.kafkahandler.ProducerRecordClass=MyCreateProducerRecordXX.java
第1步:编写MyCreateProducerRecordXX.java文件
新建MyCreateProducerRecordXX类,实现ogg预定义好的接口方法CreateProducerRecord,编写自定义createProducerRecord方法。
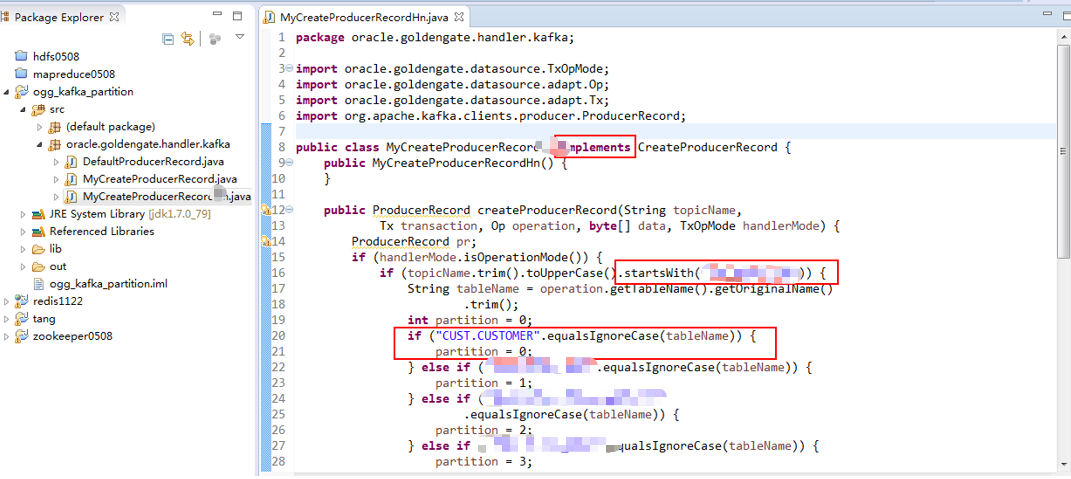
第2步:编译jar包
第3步:替换jar包
[oracle@server003 lib]$ls -rtlh ggkafka-19.1.0.0.1.003.jar
-rwxr-xr-x 1 oracleoinstall 27K Sep 26 03:37 ggkafka-19.1.0.0.1.003.jar
[oracle@server003 lib]$pwd
/oggdata/ggv191adp/ggjava/resources/lib

第4步:指定使用的自定义方法

rp_kaf进程同步的数据,也就是生产的消息其实是json格式的DML操作数据,我们可以使用消费者命令检查查看数据内容:表名、操作类型、更新时间、主键信息、数据行before镜像,数据行after镜像。
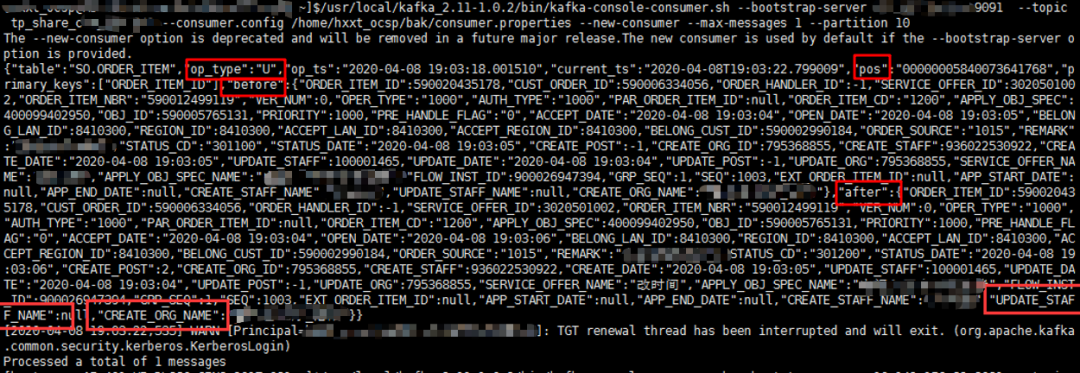
1) ogg往kafka传数据大体上还是之前的套路,区别点就在于怎么把复制进程当做客户端,当做生产者去往kafka对应的topic上生产数据。
2) Kafka作为高吞吐量、低延迟、高并发的消息中间件产品,我们的同步进程甚至不需要考虑目标端的性能问题,只要往kafka上推送数据,最终的数据使用则是另一端的消费者程序怎么使用数据的问题。
3) 既然是BigData的adapter软件包,还可以实现往HDFS、Hive、Hbase、ApacheCassandra、MongoDB、Greenplum等多种开源产品中同步数据,基本与kafka的配置类似,自定义类的实现为数据同步提供了更多的可能性,有待尝试。
4) 实际生产中的配置,还涉及到安全认证的问题,KDC的认证在这里省略。
5) 扩展联想一下,如果kafka消费者程序可以连接到不同的数据库、不同的大数据开源组件进行数据的消费,那么就可以形成一个统一的模式,ogg_for_XXDB ogg_for Big DataKAFKA任意数据库。
6) 再联想一下,在kafka上看到json格式里有数据变化的前后镜像,是不是可以结合这个做一个基于ogg的数据操作闪回功能?


