




Oracle11g体系-课堂笔记
第一部分 体系架构
第一章:实例与数据库
1.1 Oracle 基础架构及应用环境
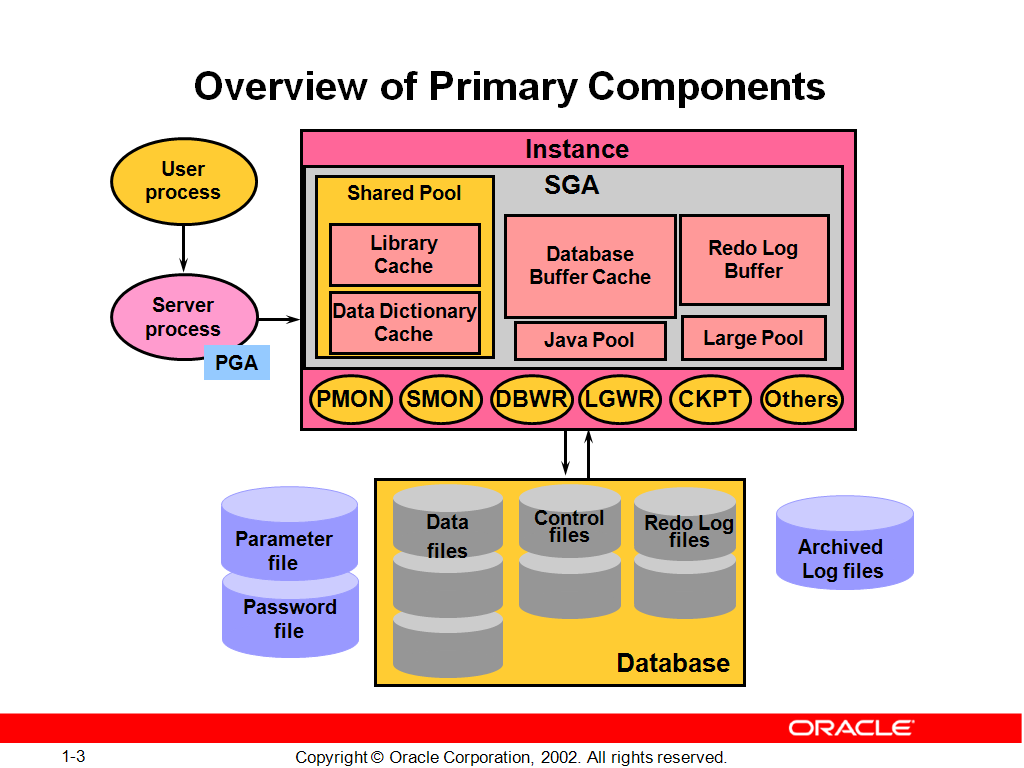
1.1.1 Oracle Server的基本结构
1)oracle server:database + instance
2)database:data file、control file、redolog file
3)instance: an instance access a database
4)oracle memory: sga + pga
5)instance:sga + backgroud process
1.1.2 系统全局区SGA:
1)在一个instance只有一个sga
2)sga为所有session共享,随着instance启动而分配
3)instance down ,sga被释放
1.2 SGA的基本组件:
1)shared pool
共享池是对SQL、PL/SQL程序进行语法分析、编译、执行的内存区域。
共享池由库缓存(library cache),和数据字典缓存(data dictionary cache)以及结果缓存(result cache)等组成。
共享池的大小直接影响数据库的性能。
关于shared pool中的几个概念
①library cache:
sql和plsql的解析场所,存放着所有编译过的sql语句代码,以备所有用户共享
②data dictionary cache:
存放重要的数据字典信息,以备数数据库使用
③server result cache:
存放服务器端的SQL结果集及PL/SQL函数返回值
④User Global Area (UGA):
共享服务器连接模式下如果没有配置large pool,则UGA属于SGA的shared pool, 专用连接模式时UGA属于PGA
2)database buffer cache(PPT-II-328)
用于存储从磁盘数据文件中读入的数据,为所有用户共享。
服务器进程(server process)负责将数据文件的数据从磁盘读入到数据缓冲区中,当后续的请求需要这些数据时如果在内存中找到,则不需要再从磁盘读取。
数据缓冲区中被修改的数据块(脏块)由后台进程DBWR将其写入磁盘。
数据缓冲区的大小对数据库的读取速度有直接的影响。
要弄明白Database Buffer Cache中的几个cache概念:
① Buffer pool=(default pool)+(nodefault pool)
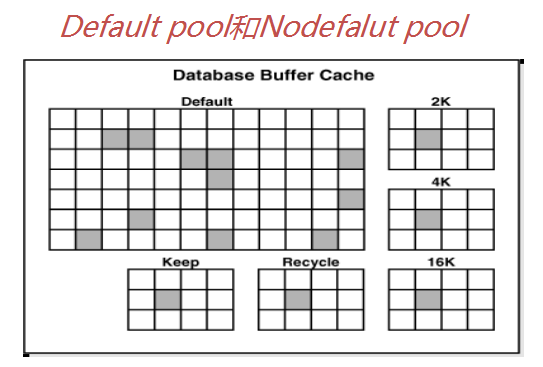
其中:
default pool(参数db_cache_size)是标准块存放的内存空间大小,SGA自动管理时此参数不用设置。使用LRU算法清理空间
nodefault pool:对应的参数有
db_nk_cache_size 指定非标准块大小内存空间,比如2k、4k、16k、32k。
db_keep_cache_size 存放经常访问的小表或索引等。
db_recycle_cache_size 与keep相反,存放偶尔做全表扫描的大表的数据。
①如何指定使用某个表调入nodefault pool
SQL> alter table scott.emp1 storage(buffer_pool keep);
SQL>
select segment_name,buffer_pool from dba_segments where segment_name='EMP1';
②default pool对应的参数是db_cache_size与标准块default block是配套的,如果default block是8k, db_cache_size这个参数将代替db_8k_cache_size。
③如果要建立非标准块的表空间,先前要设定db buffer中的与之对应的db_nk_cache_size参数。
第一步,先指定db buffer里的16k cache空间大小。
SQL> alter system set db_16k_cache_size=8m;
第二步,建立非标准块表空间
SQL> create tablespace tbs_16k datafile '/u01/oradata/prod/tbs16k01.dbf' size 10m blocksize 16k;
SQL> select TABLESPACE_NAME,block_size from dba_tablespaces;
3)redo log buffer
日志条目(redo entries)记录了数据库的所有修改信息(包括DML和DDL),目的是为数据库恢复,日志条目首先产生于日志缓冲区,日志缓冲区较小,一般缺省值在3M-15M之间,它是以字节为单位的。

日志缓冲区的大小启动后就是固定不变的,如要调整只能通过修改参数文件后重新启动生效。不能动态修改!不能由SGA自动管理!
4)large pool(可选)
为了进行大的后台进程操作而分配的内存空间,主要用于共享服务器的session memory(UGA),RMAN备份恢复以及并行查询等操作。有助于降低shared pool碎片。
5)java pool(可选)
为了java虚拟机及应用而分配的内存空间,包含所有session指定的JAVA代码和数据。
6)stream pool(可选)
为了stream process而分配的内存空间。stream技术是为了在不同数据库之间共享数据,因此,它只对使用了stream数据库特性的系统是重要的。
1.3 Oracle的进程:
- user process:
客户端的process,访问数据库分为三种形式,①sql*plus, ②应用程序,③web方式(EM)
①sql*plus可以执行sql和plsql请求,是典型的客户端进程。
linux作为客户端:可以使用ps看到sqlplus关键字:
$ ps -ef |grep sqlplus
windows作为客户端:可以通过查看任务管理器看到sqlplus用户进程:
C:\Documents and Settings\prod>sqlplus sys/system@ as sysdba
②应用程序
例如:通过java程序直接嵌套sql语句,或调用Oracle存储过程。
③web方式
例如:使用OEM登录、管理数据库。
$emctl start dbconsole
- server process:
服务器端的进程,user process不能直接访问Oracle,必须通过相应的server process访问实例,进而访问数据库。
[oracle@prod ~]$ ps -ef |grep LOCAL
在linux下看到的server process, (LOCAL=YES)是本地连接,(LOCAL=NO)是远程连接。
可以在oracle查看V$process视图,它包括了当前所有的后台进程和服务器进程。
SQL> select pid,program,background from v$process;
background字段为1是background process,其余都是server process
3)background process
基本的后台进程有
1)smon:系统监控进程
①当实例崩溃之后,Oracle会自动恢复实例。②释放不再使用的临时段。
2)pmon:进程监控
①当user process失败时,清理出现故障的进程。 释放所有当前挂起的锁定。释放服务器端使用的资源
②监控空闲会话是否到达阈值
③动态注册监听
- dbwn: 数据写入进程
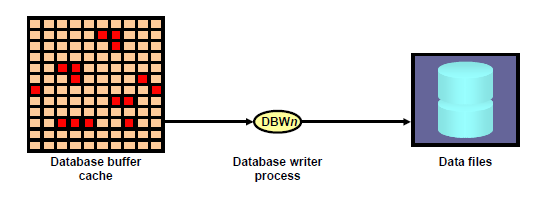
1、将变更的数据缓冲区的脏buffer写入数据文件中。
2、释放数据缓冲区空间。
3、触发条件:
①ckpt发生
②脏块太多时(阈值)
③db_buffer自由空间不够时
④3秒
⑤表空间read only/offline/backup模式等
以上5个状况之一发生时,dbwn都会被触发
- lgwr:写日志条目
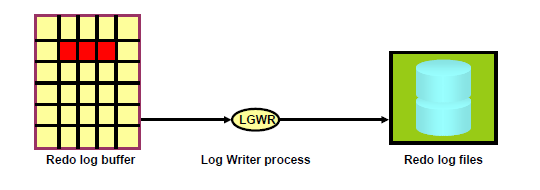
1、将日志缓冲区中的日志条目写入日志文件。
2、不像DBWR可以有多个进程并行工作,LGWR只有一个工作进程
3、触发条件:
①commit
②三分之一满(或1M满)
③先于dbwr写(先记后写,必须在dbwr写脏块之前写入日志,保证未提交数据都能回滚)
④3秒(因为有③,则由DBWR的3秒传导而来)
以上4个状况之一发生时, lgwr都会记日志
- ckpt:生成检查点
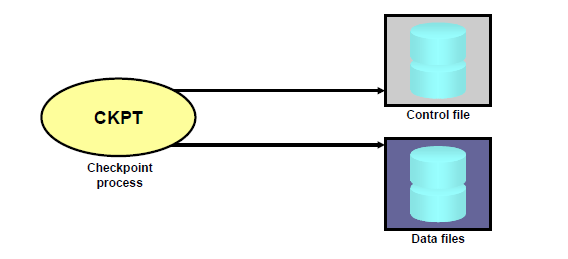
作用:通知或督促dbwr写脏块
1、完全检查点:保证数据库的一致性。
2、增量检查点:不断更新控制文件中的检查点位置,当发生实例崩溃时,可以尽量缩短实例恢复的时间。
3、局部检查点:特定的操作下,针对某个表空间的
- arcn:归档当前日志
归档模式下,发生日志切换时,把当前日志组中的内容写入归档日志,作为备份历史日志提供数据库的recovery、
1,4 PGA的基本组件
1)程序全局区(Program Global Area)的作用
①缓存来自服务器进程和后台进程的数据和控制信息。
②提供排序、hash连接
③不提供session之间的共享,
④PGA在进程创建时被分配,进程终止时被释放。所有进程的PGA之和构成了PGA的大小。
PGA的管理是比较复杂的,10g后,Oracle推荐使用PGA自动管理,屏蔽了PGA的复杂性。
2)PGA的结构:
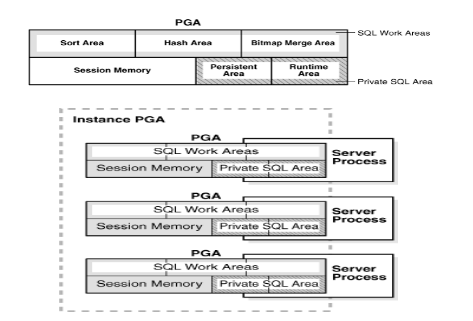
①SQL工作区(SQL Work Area): 有几个子区 1、Sort Area, 2、Harh Area 3、Bitmap Merge Area
作用:排序操作(order by/group by/distinct/union等),多表hash连接,位图连接,创建位图
②会话空间(Session Memory)
作用:存放logon信息等会话相关的控制信息
③私有SQL区域(Private SQL Area)
作用:存储server process执行SQL所需要的私有数据和控制结构,如绑定变量,它包括固定区域和运行时区域
④游标区域(Cursor Area):PLSQL游标使用的就是这块区域
1.5连接方式
1)专用连接模式(dedicated)
对于客户端的每个user process,服务器端都会出现一个server process,会话与专用服务器之间存在一对一的映射(一根绳上的两个蚂蚱)。
专用连接的PGA的管理方式是私有的。Oracle缺省采用专用连接模式。
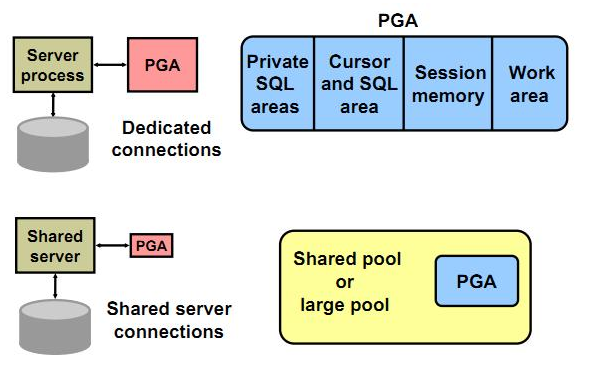
2)共享连接模式(shared)
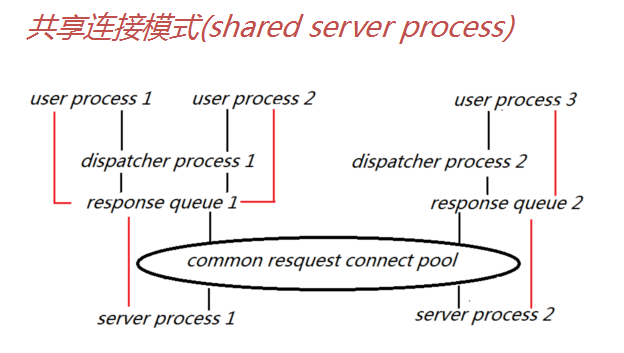
多个user process共享一个server process。
①,共享服务器实际上就是一种连接池机制(connectionpooling),连接池可以重用已有的超时连接,服务于其它活动会话。但容易产生锁等待。此种连接方式现在已经很少见了(具体配置方法见第十五章Oracle 网络)。
②所有调度进程(dispatcher)共享一个公共的请求队列(resquest queue),但是每个调度进程都有与自己响应的队列(response queue)。
③在共享服务器中会话的(UGA)存储信息是在SGA中的,而不像专用连接那样在PGA中存储信息,这时的PGA的存储结构为堆栈空间。
3)驻留连接池模式(database resident connection pooling,简称DRCP):
适用于必须维持数据库的永久连接。结合了专用服务器模式和共享服务器模式的特点。它使用连接代理(而不是专用服务器)连接客户机到数据库,优点是可以用很少的内存处理大量并发连接(11g新特性,特别适用于Apache的PHP应用环境)。
第二章:实例管理及数据库的启动/关闭
2.1 参数文件
2.1.1概念
1)instance在启动阶段读取初始化参数文件(init parameter files)。该文件管理实例相关启动参数 。
基本初始化参数:大约10-20个左右(见联机文档)
初始化参数:300个左右
隐含参数:Oracle不推荐使用
2)两种形式
①动态参数:可以直接在内存中修改,并对当前instance立即生效,
②静态参数。必须修改参数文件,下次启动后生效
SQL> select distinct issys_modifiable from v$parameter;
ISSYS_MODIFIABLE
----------------
IMMEDIATE 动态参数
FALSE 静态参数
DEFERRED 延迟参数,session下次连接有效
2.1.2两种参数文件
1)pfile(parameter file)
特点:
①必须通过文本编辑器修改参数,便于一次修改多个参数。
②缺省的路径及命名方式:$ORACLE_HOME/dbs/initSID.ora
2)spfile(system parameter file)
特点:
①二进制文件,不可以通过编辑器修改。通过Linux命令strings可以查看内容。
②路径及命名方式: $ORACLE_HOME/dbs/spfileSID.ora
③修改spfile文件的方法:
alter system set 参数=值 [scope=memory|spfile|both]
①scope=memory 参数修改立刻生效,但不修改spfile文件。
②scope=spfile 修改了spfile文件,重启后生效。
③scope=both 前两种都要满足。要求spfile参数文件存在
④不写scope限定词,缺省③。但不如③严格,即spfile如果不存在,仅仅修改内存中参数。
如果不修改spfile,将无法更改静态参数。
SQL> select name,ISSES_MODIFIABLE,ISSYS_MODIFIABLE from v$parameter where name='sql_trace';
NAME ISSES ISSYS_MOD
-------------------------------------------------------------------------------- ----- ---------
sql_trace TRUE IMMEDIATE
这个结果表示 sql_trace参数在session级别可以改,在system级也可以both修改(动态参数)。
- 读取参数文件的顺序及相互生成
优先spfile,其次pfile。
pfile和spfile可以相互生成:
SQL>create pfile from spfile
SQL>create spfile from pfile
SQL>create pfile from memory;
SQL>create spfile from memory;
注意:使用spfile启动后不能重写spfile
尽可能使用spfile,pfile一般留做备用,特殊情况也可以使用pfile启动:
SQL> startup pfile=$ORACLE_HOME/dbs/initprod.ora
如果pfile不是缺省命名或放在其他路径,则指定命令路径和文件名即可。
SQL> startup pfile=/home/oracle/mypfile
怎样知道实例是spfile启动还是pfile启动的
SQL> show parameter spfile
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
spfile string /u01/oracle/dbs/spfile.ora
如果value有值,说明数据库启动时读的是spfile
另一个办法是看v$spparameter(spfile参数视图)中的参数memory_target的isspecified字段值,如果是TRUE 说明是spfile启动的(考点)
SQL> select name,value,isspecified from v$spparameter where name like 'memory_target';
NAME VALUE ISSPECIFIED
-------------------------------------- -------------------------------------------
memory_target 423624704 TRUE
2.2 数据库启动与关闭
2.2.1启动分为三个阶段
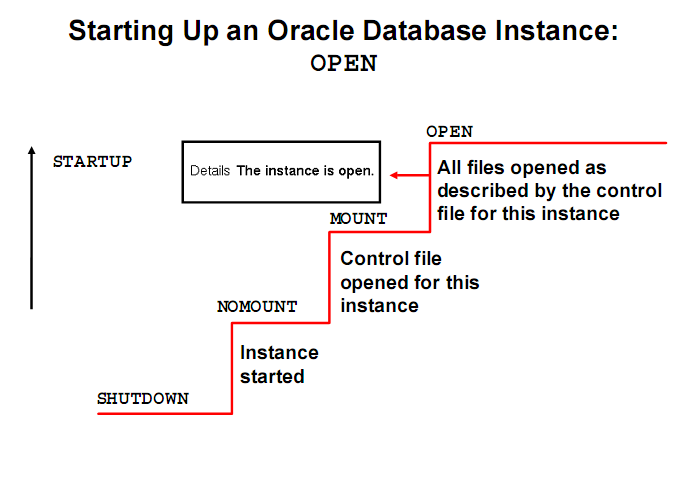
1)nomount阶段:读取init parameter
SQL> select status from v$instance;
STATUS
------------
STARTED
2)mount阶段:读取控制文件
SQL> select status from v$instance;
STATUS
------------
MOUNTED
3)open阶段:
1、检查所有的datafile、redo log、 group 、password file正常
2、检查数据库的一致性(controlfile、datafile、redo file的检查点是否一致)
SQL> select file#,checkpoint_change#,last_change# from v$datafile; 从控制文件读出
SQL> select file#,checkpoint_change# from v$datafile_header; 从数据文件读出
注意:启动时last_change#不为空说明之前是干净的关闭数据库
SQL> select status from v$instance;
STATUS
------------
OPEN
2.2.2 启动数据库时的一些特殊选项
startup force; 相当于shutdown abort后再接startup
startup upgrade 只有sysdba能连接
startup restrict 有restrict session权限才可登录,sys不受限制
alter system enable restricted session; open后再限制
alter database open read only; scn不会增长
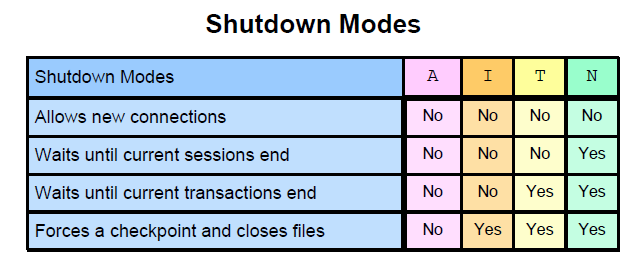
2.2.3 实例关闭:
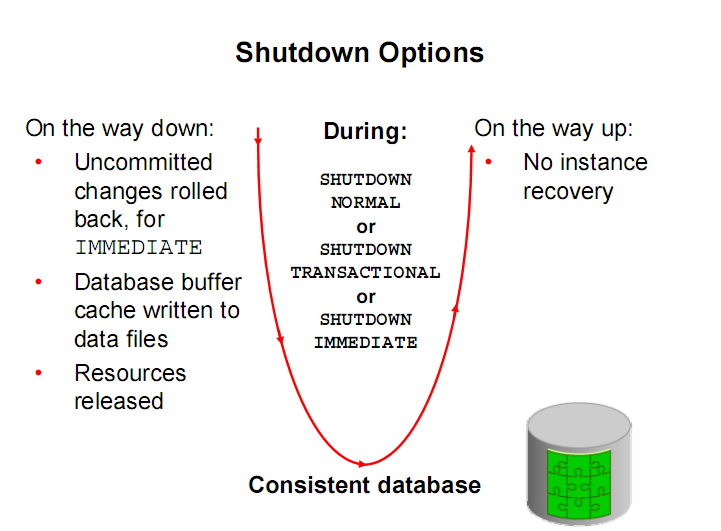
①shutdown normal 拒绝新的连接,等待当前会话结束,生成检查点
②shutdown transactional 拒绝新的连接,等待当前事务结束,生成检查点
③shutdown immediate 拒绝新的连接,未提交的事务回滚,生成检查点
④shutdown abort 事务回滚,不生成检查点,下次启动需要做instance recovery
2.3 自动诊断信息库ADR
ADR(Automatic Diagnostic Repository)是11g新特性
存储在操作系统下的一个目录(树)结构
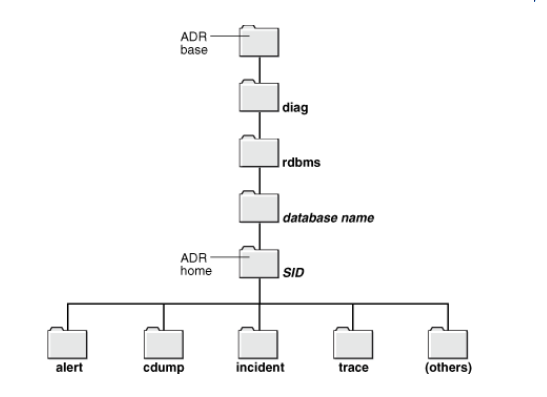
包括:①告警日志文件,②跟踪文件,③健康记录,④DUMP转储文件等
SQL> show parameter diagnostic_dest
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
diagnostic_dest string /u01
$ORACLE_BASE=/u01,它也是ADR的基目录,如果你没有设置ORACLE_BASE环境变量,Oracle给你设置的ADR基目录是$ORALE_HOME/log
SQL> show parameter dump
在oracle 11g中,故障诊断及跟踪的文件路径改变较大,告警文件分别xml的文件格式和普通文本格式两种形式存在。这两份文件的位置分别是V$DIAG_INFO中的Diag Alert 和Diag Trace 对应的目录。
2.3.1跟踪文件:
1)后台进程的跟踪文件(Bdump)
SID_processname_PID.trc 如:_lgwr_5616.trc
2)服务器进程的跟踪文件(Udump)
SID_ora_PID.trc 如:_ora_10744.trc
另外增加.trm(trace map)文件,记录trc文件的结构信息。
SQL> select * from v$diag_info;
2.3.2告警日志
以文本格式保存告警日志。命名是:alter_SID.log,它包含通知性的消息,如数据库启动或关闭,以及有关数据库物理结构变化的信息,也包括一些内部错误信息等。
告警日志会不断增长,定期清理是必要的
$cat /dev/null > alert_prod.log 将文件清空
直接删掉也没有关系,下次启动会自动创建
$ tail -f /u01/diag/rdbms/prod/prod/trace/alert_prod.log
2.4 口令文件
2.4.1 登录认证方式
主要有以下三种
- OS认证:
特点:①Oracle用户以本地登录。②Oracle用户必须属于DBA组,③Oracle的sysdba身份不验证密码。
如:sqlplua / as sysdba
- 口令文件认证:
是一种通过网络的远程认证方式,只有sysdba权限的用户可以使用口令文件,登录时必须输入密码和网络连接符。
如:sqlplus sys/oracle@ as sysdba
3)口令密码认证方式
普通用户是指没有sysdba权限的用户,比如system 、scott,或者是tim什么的,不管是本地还是远程,普通用户登录时必须在数据库open下输入口令,它们的口令密码保管在数据字典里。
2.4.2 口令文件
是sysdba身份的用户的远程认证密码文件,主要用于sys用户(严格来说是具有sysdba系统权限的用户)的远程登录认证。
1)位置:$ORACLE_HOME/dbs/orapwSID,
2)可以通过remote_login_passwordfile参数控制是否生效
3)使用orapwd命令创建新的sys口令文件:
[oracle@cuug ~]$ cd $ORACLE_HOME/dbs
[oracle@cuug dbs]$ $orapwd file=orapwprod password=system entries=5 force=y
file=orapw+sid的写法,不能拼错 entries的含义是表示口令文件中可包含的SYSDBA/SYSOPER权限登录的最大用户数。Force强制覆盖原文件
第三章:控制文件
3.1 功能和特点:
1)记录数据库当前物理状态
2)维护数据库的一致性
3)是一个二进制小文件
4)在mount阶段被读取
5)记录RMAN备份的元数据
查看database控制文件位置:
SQL> show parameter control_file
SQL> select name from v$controlfile;
NAME
----------------------------------------------
/u01/oradata/prod/control01.ctl
/u01/oradata/prod/control02.ctl
/u01/oradata/prod/control03.ctl
3.2 实时更新机制
①当增加、重命名、删除一个数据文件或者一个联机日志文件时,Oracle服务器进程(Server Process)会立即更新控制文件以反映数据库结构的变化。
②日志写进程LGWR负责把当前日志序列号记录到控制文件中。
③检查点进程CKPT负责把校验点的信息记录到控制文件中。
④归档进程ARCN负责把归档日志的信息记录到控制文件中。
通过视图v$controlfile_record_section可以了解到控制文件中记录了大量的数据库当前状态信息
3.3 多元化
- 配置多个control_files,控制文件最好是3个(最多8个)。多路复用是相互镜像,
一般配置方法
①修改spfile中的control_files参数(最好将spfile先备份一份)
②shutdown immediate
③复制控制文件,Oracle建议分配在不同的物理磁盘上。
- 三个control文件要一致(同一版本,scn相同),本来就是镜像关系
3.4 备份与重建
3.4.1备份
指对控制文件的实时备份,用于恢复数据文件。
SQL> alter database backup controlfile to '/u01/oradata/prod/con.bak';
数据库打开时是不能cp控制文件的。
3.4.2重建
可以在mount或open模式生成一个trace文件,方便重建控制文件:
①文件内容在Default Trace File中
SQL> alter database backup controlfile to trace;
②或者 存到自己起的文件名里
SQL>alter database backup controlfile to trace as '/u01/oradata/prod/con.trace';
3.5 恢复与重建
3.5.1恢复控制文件方法
控制文件一旦损坏,系统将不能正常工作。受损的控制文件会记录在告警日志中,恢复或重建控制文件必须使系统在NOMOUNT下
1)单个文件损坏了:参照多元化章节,通过简单复制解决。
2)所有的控制文件丢失:
①如果有binary控制文件备份,利用备份恢复控制文件,
②如果没有备份,利用trace脚本文件重新创建控制文件(代价:丢失归档记录信息和RMAN信息)
3.5.2重建控制文件示例
第一步、Mount或open下生成trace脚本
SQL>alter database backup controlfile to trace as '/u01/oradata/prod/con.trace';
第二步、启动到nomount 状态下准备执行trace脚本
SQL> startup force nomount
第三步、执行重建控制文件语句
SQL>CREATE CONTROLFILE REUSE DATABASE "prod" NORESETLOGS ARCHIVELOG
MAXLOGFILES 16
MAXLOGMEMBERS 3
MAXDATAFILES 100
MAXINSTANCES 8
MAXLOGHISTORY 292
LOGFILE
GROUP 1 '/u01/oradata/prod/redo01.log' SIZE 50M,
GROUP 2 '/u01/oradata/prod/redo02.log' SIZE 50M,①
GROUP 3 '/u01/oradata/prod/redo03.log' SIZE 50M
-- STANDBY LOGFILE
DATAFILE
'/u01/oradata/prod/system01.dbf',
'/u01/oradata/prod/sysaux01.dbf',
'/u01/oradata/prod/users01.dbf',
'/u01/oradata/prod/example01.dbf',
'/u01/oradata/prod/test01.dbf',
'/u01/oradata/prod/undotbs01.dbf'
CHARACTER SET ZHS16GBK
然后 recover database;
;
可以看到执行后三个控制文件又重新建立了。这时数据库已在mount下
说明:这个重建控制文件的过程主要有两大部分内容:
第一部分是脚本中的可见信息:
- 定义db_name,
- 指定几个参数限定控制文件的最大值,
- 在线日志的物理信息,
- 数据文件的物理信息,
- 使用的字符集。
第二部分是隐含的不可见信息,比如SCN信息,重建复制了当前所有数据文件头部的最新SCN信息复制到了控制文件中。以便接下来打开数据库。
SQL> select file#,checkpoint_change# from v$datafile;
SQL> select file#,checkpoint_change# from v$datafile_header;
第四步、打开数据库
SQL> alter database open;
第五步、添加临时数据文件信息(脚本中的最后一行)
SQL> ALTER TABLESPACE TEMP ADD TEMPFILE '/u01/oradata/prod/temp01.dbf'
SIZE 30408704 REUSE AUTOEXTEND ON NEXT 655360 MAXSIZE 32767M;
第四章:redo 日志
4.1作用和特征
作用:数据recovery
特征:
1)记录数据库的变化(DML、DDL)
2)用于数据块的recover
3)以组的方式管理redo file,最少两组redo,循环使用
4)和数据文件存放到不同的磁盘上,需读写速度快的磁盘(比如采用RAID10)
5)日志的block和数据文件的block不是一回事
4.2日志组及切换
1)最少两组,最好每组有两个成员(多路复用),并存放到不同的磁盘上,大小形同,互相镜像
2)日志在组写满时将自动切换
①归档模式:将历史日志连续的进行保存。
②非归档:历史日志被覆盖
③切换产生checkpoint(考虑性能有延迟),通知dbwn写脏块 并且更新控制文件
- 在归档模式,日志进行归档,并把相关的信息写入controlfile
4.3 添加日志组和成员
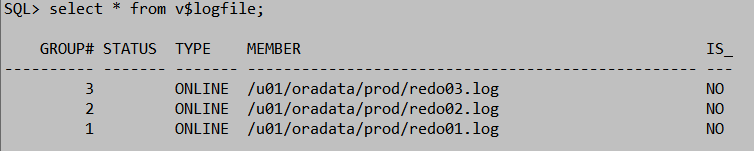
1)三个重要视图
SQL> select * from v$log;

SQL> select * from v$logfile;
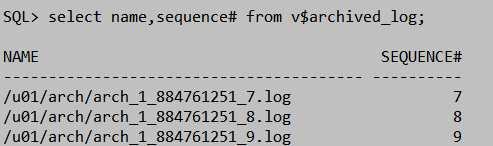
SQL> select name,sequence# from v$archived_log;(记录日志调控日志块的改变)
2)增加一个组group4,
SQL> alter database add logfile group 4 '/u01/oradata/prod/redo04.log' size 50m;
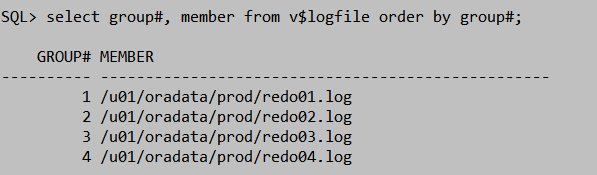
3)添加日志组的成员
为每个组增加一个member(一共是4个组)
先建好目录,准备放在/u01/disk2/prod/下
[oracle@cuug ~]$ mkdir -p /u01/disk2/prod
SQL>alter database add logfile member
'/u01/disk2/prod/redo01b.log' to group 1,
'/u01/disk2/prod/redo02b.log' to group 2,
'/u01/disk2/prod/redo03b.log' to group 3,
'/u01/disk2/prod/redo04b.log' to group 4;
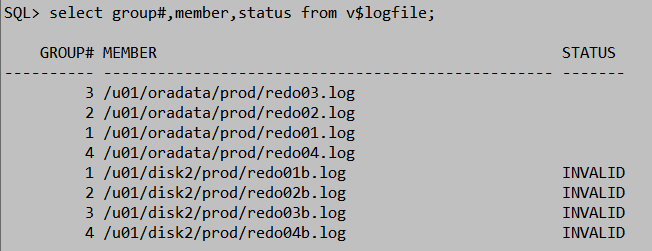
STATUS是INVALID,说明member还没有同步好。
SQL> alter system switch logfile; 至少做4次切换,消除invalid。这步很必要。
4.4 v$log视图的状态
STATUS列有四种状态:
①unused: 新添加的日志组,还没有使用
②inactive 日志组对应的脏块已经从data buffer写入到data file,可以覆盖
③active: 日志组对应的脏块还没有完全从data buffer写入到data file,含有实例恢复需要的信息,不能被覆盖
④current: 当前日志组对应的脏块还没有全部从data buffer写入到data file,含有实例恢复需要的信息,不能被覆盖
THREAD: 线程在单实例的环境下,thread# 永远是1
SEQUENCE# 日志序列号。在日志切换时会递增
FIRST_CHANGE# 在每个日志组对应一个sequence号,其中首条日志条目的第一个的scn。
4.5日志恢复(PPT-II-146-148)
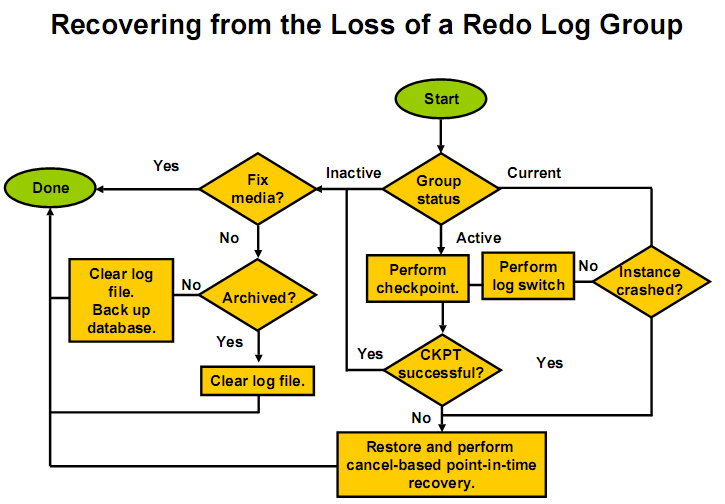
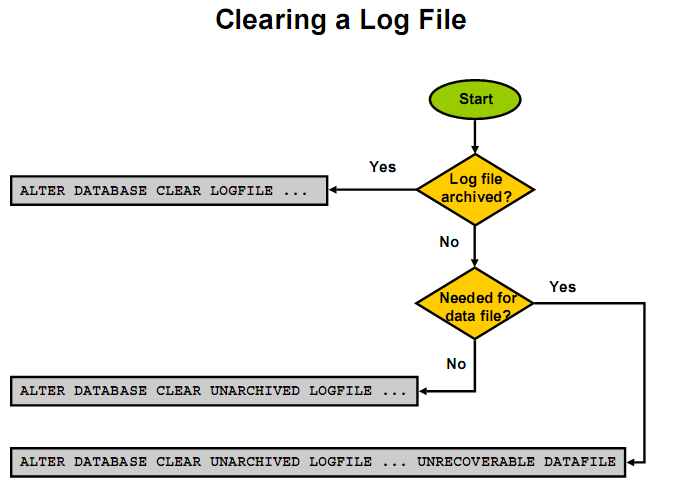
4.5.1 inactive日志组损坏,
假如日志组4损坏,状态inactive。解决很简单,重建日志组即可
SQL> alter database clear logfile group 4; 这里clear的意思是重建group4的文件。
4.5.2 current日志组丢失。
本例日志组1状态是CURRENT状态的,现在模拟当前日志组损坏
[oracle@prod]$ rm /u01/oradata/prod/redo01.log
[oracle@prod]$ rm /u01/disk2/prod/redo01b.log
SQL> alter system switch logfile; 切换几次,触动它一下。
告警日志会记录有关信息
暂时好像没有什么问题发生,继续切换,当current 又转会到group1时,session死!
当前日志损坏的问题比较复杂,见上图可以分以下几种情况讨论
1)数据库没有崩溃
第一步,可以做一个完全检查点,将db buffer中的所有dirty buffer全部刷新到磁盘上。
SQL> alter system checkpoint;
第二步,尝试数据库在打开状态下进行不做归档的强制清除。
SQL> alter database clear unarchived logfile group n;
数据库此时为打开状态,这步若能成功,一定要做一个新的数据库全备,因为当前日志无法归档,归档日志sequence已无法保持连续性。全备的目的就是甩掉之前的归档日志。
2)数据库已经崩溃,只能做传统的基于日志的不完全恢复或使用闪回数据库。
SQL> recover database until cancel;
SQL> alter database open resetlogs;
3)如果之前没有可用的备份,或问题严重到任何方法都不能resetlogs打开数据库,为了抢救数据,考虑最后一招使用Oracle的隐含参数:_allow_resetlogs_corruption=TRUE
Oracle不推荐使用这个隐含参数
该参数的含义是:允许数据库在不致性的情况下强制打开数据库。_
在不一致状态下强行打开了数据库后,建议做一个逻辑全备。
4.5.3 active日志组损坏
做检查点切换,如成功,按照inactive损坏处理。否则,按current损坏处理。
4.6 使日志恢复到原来的配置
- 删除日志组
SQL> alter database drop logfile group 4; 状态是current和active的组不能删除
- 删除成员
SQL> alter database drop logfile member '/u01/disk2/prod/redo01b.log'; 状态是current组不能删除成员,需要切换一下。
3)清理物理日志文件。 删除物理文件需要rm
第五章:归档日志 archivelog
5.1 归档和非归档的区别
1)归档会在日志切换时,备份历史日志,对于OLTP系统都应考虑归档模式,以便数据库能支持热备,并提供数据库完全恢复和不完全恢复(基于时间点)
2)归档会启用arcn的后台进程、也会占用磁盘空间
3)非归档适用某种静态库、测试库、或者可由远程提供数据恢复的数据库。非归档只能冷备,且仅能还原最后一次全备。
5.2 设置归档模式
1)SQL> shutdown immediate 一定要干净的关闭数据库
2)SQL> startup mount 启动到mount下
3)SQL> alter database archivelog; 设置归档方式
4)SQL> archive log list; 查看归档状态
5)SQL> alter database open; 打开数据库
5.3 路径及命名方法
1)Oracle判断归档目的地时按如下顺序优先择取
①log_archive_dest_n值或log_archive_dest值
②db_recover_file_dest参数指定的位置
③$ORACLE_HOME/dbs参数指定的位置
2)路径可以通过archive log list命令显示

Archive destination(存档终点)有两种情形
①缺省是USE_DB_RECOVERY_FILE_DEST,其含义是采用参数db_recovery_file_dest参数的定义,即闪回恢复区
②采用参数log_archive_dest_n或log_archive_dest指定的路径
SQL> show parameter archive
NAME TYPE VALUE
------------------------------------ ----------- --------------------------------------
archive_lag_target integer 0
log_archive_config string
log_archive_dest string
log_archive_dest_1 string location=/u01/arch/prod
log_archive_dest_10 string
log_archive_dest_2 string
log_archive_dest_3
...
log_archive_duplex_dest string
log_archive_format string arch_%t_%r_%s.log
SQL> show parameter db_recovery

3)首先来看这两个参数:
log_archive_dest_n
log_archive_format
log_archive_dest_n(n:1-10) 表示可以有10个目标路径存放归档日志(镜像关系),即可以多路复用10个归档日志的备份。如上显示我只使用了log_archive_dest_1,也就是说只有一套归档日志,没有做镜像。
参数设定的格式如下:
SQL> alter system set log_archive_dest_1='location=/u01/arch/prod';
把历史日志归档到本机目录下 (location 代表本机)
SQL> alter system set log_archive_dest_2='service=standby';
远程备份,把历史日志备份到网络连接符为standby的数据库上。(service 代表远程),配置DG时有用。
log_archive_format 是定义命名格式的,一般考虑使用下面三个内置符号(模板)
%t thread# 日志线程号
%s sequence 日志序列号
%r resetlog 代表数据库的周期
参数设定的格式如下:
SQL> alter system set log_archive_format ='arch_%t_%r_%s.log' scope=spfile;
4)再来看看这两个参数:
log_archive_dest
log_archive_duplex_dest
这两个参数已经弃用了,它们能完成两路复用(镜像)但只能指定本机location,无法指定远程。
一旦使用log_archive_dest_n,log_archive_dest参数就失效了。
5.4 归档进程和手动切换
1)归档进程
$ ps -ef |grep ora_arc
oracle 1215 2435 0 13:26 pts/2 00:00:00 grep ora_arc
oracle 31796 1 0 13:00 ? 00:00:00 ora_arc0_
oracle 31798 1 0 13:00 ? 00:00:00 ora_arc1_
ARCn就是归档进程,n最多可达30个,由log_archive_max_processes参数指定。
2)手动切换日志:
第一种:SQL> alter system switch logfile; 仅切换当前实例,适用归档和非归档。
第二种:SQL> alter system archive log current; 在RAC下切换所有实例,仅适用于归档模式。
第六章:日志挖掘 log miner
6.1 作用
Oracle LogMiner 是一个非常有用的分析工具
可以轻松获得Oracle在线/归档日志文件中的具体内容,
可以解析出所有对于数据库操作的DML和DDL语句。
特别适用于调试、审计或者回退某个特定的事务。
由一组PL/SQL包和一些动态视图组成
一个完全免费的工具。没有提供任何的图形用户界面(GUI)
6.2 方法
6.2.1 DML日志挖掘
1)添加database补充日志
SQL>ALTER DATABASE ADD SUPPLEMENTAL LOG DATA;
注意:为了避免日志遗漏,这步要先执行。
2)确定要分析的日志范围,添加日志,分析
SQL>execute dbms_logmnr.add_logfile(logfilename=>'日志',options=>dbms_logmnr.new);
提供第一个要加载的日志文件
SQL>execute dbms_logmnr.add_logfile(logfilename=>'追加日志',options=>dbms_logmnr.addfile);
可以反复添加补充多个日志文件
3)执行logmnr 分析
SQL>execute dbms_logmnr.start_logmnr(options=>dbms_logmnr.dict_from_online_catalog);
4)查询分析结果,
SQL>select username,scn,timestamp,sql_redo from v$logmnr_contents where seg_name='表名';
可以设置时间格式,也可以在显示方式里再确定格式.
5)关闭日志分析
SQL>execute dbms_logmnr.end_logmnr;
示例演示
6.2.2 DDL日志挖掘
1)建立一个存放dict.oral的目录,设置参数utl_file_dir指定该目录,
$ mkdir /home/oracle/logmnr
SQL> alter system set utl_file_dir='/home/oracle/logmnr' scope=spfile;
2)建立数据字典文件dict.ora
SQL> execute dbms_logmnr_d.build('dict.ora','/home/oracle/logmnr',dbms_logmnr_d.store_in_flat_file);
3)添加日志分析
SQL> execute dbms_logmnr.add_logfile(logfilename=>'日志文件',options=>dbms_logmnr.new);
SQL> execute dbms_logmnr.add_logfile(logfilename=>'追加日志',options=>dbms_logmnr.addfile);
4)执行分析
SQL>
execute dbms_logmnr.start_logmnr(dictfilename=>
'/home/oracle/logmnr/dict.ora',options=>dbms_logmnr.ddl_dict_tracking);
5)查看分析结果
SQL> select username,scn,to_char(timestamp,'yyyy-mm-dd hh24:mi:ss'),sql_redo from v$logmnr_contents WHERE USERNAME ='SCOTT' and lower(sql_redo) like '%table%';
6)关闭日志分析
SQL> execute dbms_logmnr.end_logmnr;
示例将在备份恢复课程中演示。
第七章:管理undo
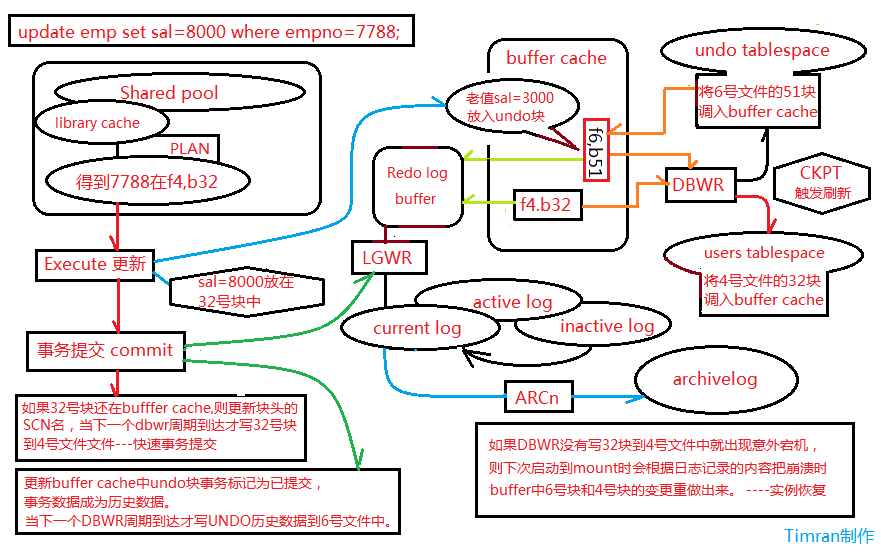
7.1 Undo作用
使用undo tablespace 存放从数据缓存区读出的数据块的前镜像
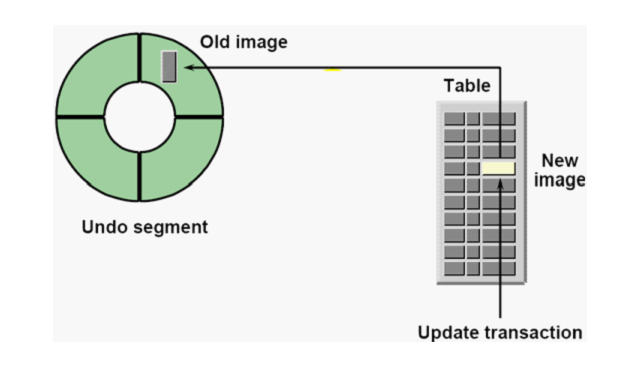
提供以下四种情况所需要的信息
1)回滚事务:rollback
2)读一致性:正在做DML操作的数据块,事务结束前,其他用户读undo里面的数据前镜像
3)实例的恢复:instance recover(undo -->rollback)
4)闪回技术 :flashback query、flashback table等
7.2 Undo的参数
7.2.1三个基本参数
SYS>show parameter undo
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
undo_management string AUTO
undo_retention integer 900
undo_tablespace string UNDOTBS1
7.2.2参数说明
1)undo_management
①manaual 仅在维护时使用
②auto 使用undo tablespace管理undo
2)undo_retention 指定保留期,希望在这个期间commit的undo数据不要覆盖
3)undo_tablespace 当前使用的Undo表空间
7.2.3 建立一个undo表空间
可以建立多个undo表空间,但只有一个是使用中的undo使用中的undo tablespace 不能offline 和 drop
建立一个新的undo表空间
SQL>
create undo tablespace undotbs2 datafile '/u01/oradata/prod/undotbs02.dbf' size 50m autoextend on;
查看undo tablespace
SQL> select tablespace_name,status,contents from dba_tablespaces;
查看当前正在使用的undo tablespace回滚段
SQL> select * from v$rollname;
USN NAME
---------- ------------------------------
0 SYSTEM
1 _SYSSMU1_1363316212$
2 _SYSSMU2_1363316212$
3 _SYSSMU3_1363316212$
4 _SYSSMU4_1363316212$
5 _SYSSMU5_1363316212$
6 _SYSSMU6_1363316212$
7 _SYSSMU7_1363316212$
8 _SYSSMU8_1363316212$
9 _SYSSMU9_1363316212$
10 _SYSSMU10_1363316212$
7.2.4切换undo
SQL> alter system set undo_tablespace=undotbs2; 动态参数,修改立即生效
SQL> select * from v$rollname;
USN NAME
---------- ------------------------------
0 SYSTEM
11 _SYSSMU11_1357956213$
12 _SYSSMU12_1357956213$
13 _SYSSMU13_1357956213$
14 _SYSSMU14_1357956213$
15 _SYSSMU15_1357956213$
16 _SYSSMU16_1357956213$
17 _SYSSMU17_1357956213$
18 _SYSSMU18_1357956213$
19 _SYSSMU19_1357956213$
20 _SYSSMU20_1357956213$
SQL> drop tablespace undotbs1 including contents and datafiles; 删除未激活undo
7.3 Undo空间重用机制
undo 数据的4种状态
①active:
表示transaction还没有commit,不可覆盖,
②unexpired:
由已经commit或rollback的数据转换而来的状态, 在保留期内,尽量不覆盖(非强制)
③expired:
由unexpired转换而来,其中的数据是超过undo保留期的,随时可以再分配(覆盖)。
④free:
分配了但未使用过。一般是undo最初创建和扩展时出现,它不是一个常态的。
undo的状态转换体现了undo空间的循环使用原理:分配---》冻结--->回收---》再分配
7.4关于AUM
- 什么是AUM
Oracle10gR2以后引入了一个新的自动调整undo retention的特性,
目的是尽量避免两个Undo错误
ora-30036错误---空间不足
ora-01555错误---快照太旧
11g缺省设置为AUM(Auto Undo Management)
AUM下current undo retention是自动调整的
SYS@ prod>select begin_time,tuned_undoretention from v$undostat;
BEGIN_TIME TUNED_UNDORETENTION
------------------- -------------------
2015-10-11 20:17:20 1784
2015-10-11 20:07:20 1723
2015-10-11 19:57:20 1119
2)AUM的两种工作方式
①autoextend off下, 忽略undo_retention参数,TUNED_UNDORETENTION参照undo表空间大小和undo统计信息,
缺点:空间给定不合理时,产生UNDO告警,不能完全避免ora-30036,ora-01555,若UNDO增加尺寸,又可能造成TUNED_UNDORETENTION增加。
②autoextend on下, 参考undo_retention作为下限值,TUNED_UNDORETENTION期内,以扩展空间代替覆盖unexpired,基本避免了ora-30036,ora-01555
缺点:表空间可能过度膨胀。
- 关闭AUT模式(Oracle不推荐)
如果要关闭undo自动调优,可以使用隐含参数
设置隐含参数_undo_autotune=false
- Undo的guarantee属性
通常情况下,unexpired数据并不绝对保证在retention期内不会覆盖,必要时可考虑设置在保留期强制不覆盖的guarantee属性,同时应该使undo autoextend on
SQL> select tablespace_name,status,contents,retention from dba_tablespaces;
缺省配置下undo retention是 noguarantee
guarantee属性可以修改
SQL> alter tablespace undotbs2 retention guarantee; 保证在retention 期间不允许被覆盖
SQL> alter tablespace undotbs2 retention noguarantee;
7.5 undo 信息的查询
1) v$session 查看用户建立的session
2) v$transaction 当前的事务
3) v$rollname undo段的名称
4) v$rollstat undo段的状态
5) v$undostat 查看每10分钟的统计数据
6) dba_undo_extents 查看undo段中不同状态的空间占用
7) dba_rollback_segs 数据字典里记录的undo段状态
第八章:检查点(checkpoint)
8.1什么是checkpoint
checkpoint是数据库的一个内部事件,检查点激活时会触发数据库写进程(DBWR),将数据缓冲区里的脏数据块写到数据文件中。其作用有两个方面:
1)保证数据库的一致性,这是指将脏数据从数据缓冲区写出到硬盘上,从而保证内存和硬盘上的数据是一致的。
2)缩短实例恢复的时间,实例恢复时,要把实例异常关闭前没有写到硬盘的脏数据通过日志进行恢复。如果脏块过多,实例恢复的时间也会过长,检查点的发生可以减少脏块的数量,从而减少实例恢复的时间。
8.2检查点分类
①完全检查点 full checkpoint
②增量检查点 incremental checkpoint
③局部检查点 partial checkpoint
8.2.1 完全检查点工作方式:
记下当前的scn, 将此scn之前所有的脏块一次性写完,再将该scn号同步更新控制文件和数据文件头。
触发完全检查点的四个操作
①正常关闭数据库:shutdown immediate
②手动检查点切换:alter system checkpoint;
③日志切换:alter system switch logfile;
④数据库热备模式:alter database begin backup;
示例1:
验证以上概念可以做一下alter system checkpoint,然后观察v$datafile和v$datafile_header中scn被更新。
示例2研究一下日志切换:alter system switch logfile;
设置(参数是刷新的频率)FAST_START_MTTR_TARGET<>0,查看v$log视图中的active状态几分钟后会变成inactive状态,说明了什么?确认该操作也更新了控制文件和日志文件头部的SCN。
8.2.2 增量检查点概念及相关参数:
8.2.2.1概念:
1)被修改过的块,在oracle中都被统称为脏块.脏块按照首次变脏的时间顺序被一个双向链表指针串联起来,这称做检查点队列。
2)当增量检查点发生时,DBWR就会被触发,沿着检查点队列的顺序将部分脏块刷新到磁盘上,每次刷新截止的那个块的位置就叫检查点位置,检查点位置之前的块,都是已经刷新到磁盘上的块。而检查点位置对应的日志地址(RBA)又总是被记录在控制文件中。如果发生系统崩溃,这个最后的检查点位置就是实例恢复运用日志的起点。
3)增量检查点使检查点位置前移。进而缩短实例恢复需要的日志起点和终点之间的距离,触发增量检查点越频繁,实例恢复的时间越短,但数据库性能受到频繁IO影响会降低。
4)增量检查点不会同步更新数据文件头和控制文件的SCN。
8.2.2.2 与增量检查点有关的几个知识点
1)FAST_START_MTTR_TARGET参数:
这个参数是考点。它给出了你希望多长时间完成恢复实例。
此参数单位为秒,缺省值0,范围0-3600秒,根据这个参数,Oracle计算出在内存中累积的dirty buffer所需的日志恢复时间,如果日志累计到达一定,则增量检查点进程被触发。该参数如果为0,ORACLE则会根据DBWN进程自身需要尽量减少写入量,这样虽然实现了性能最大化,但实例恢复时间可能会比较长。
早期还有几个有关增量检查点的参数,
①log_checkpoint_interval
规定了redo日志积累多少block后激活增量检查点,对用户来讲要给出这个参数不太方便,所谓block指的是os block,而不是oracle block。
②log_checkpoint_timeout 给一个触发增量检查点的间隔,单位是秒。
如果设置了FAST_START_MTTR_TARGET参数,就不要用早期的一些参数,容易引起冲突。
如果将fast_start_mttr_target设置为非0,1)将启用检查点自动调整机制。2)log_checkpoint_interval参数将被覆盖掉。
2)90% OF SMALLEST REDO LOG(内部机制)
从上次切换后算起,累计日志为一个日志组大小的90%时,做一次检查点切换。
- 每3s查看checkpoint队列脏块的写出进度
这个3秒是Oracle强调的增量检查点特性之一。注意,3s并不触发检查点,它只是记录当时的检查点位置,并将相关信息写入到controlfile。
8.2.3实例恢复有关的顾问
使能实例恢复顾问(MTTR Advisory)。需要设置两个参数
1)STATISTICS_LEVEL 置为typical(缺省) 或者all
2)FAST_START_MTTR_TARGET 置为非零值
为了合理的设置MTTR参数,可以参考视图 v$instance_recovery的估算值
SQL>select recovery_estimated_ios,actual_redo_blks,target_redo_blks,target_mttr,estimated_mttr from v$instance_recovery;
8.3局部检查点
对于仅限于局部影响的操作,可以触发局部检查点。
比如:表空间offline,数据文件offline,删除extent,表truncate,begin backup(将表空间置于备份模式)等。
第九章:实例恢复机制
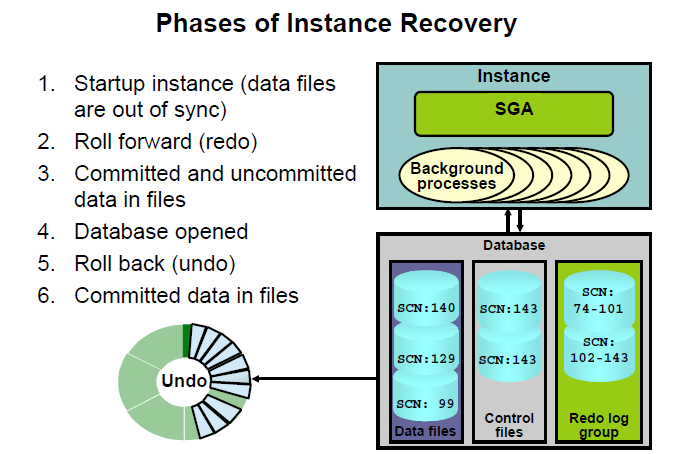
9.1什么是实例恢复
有了redo,undo和增量ckpt概念后,有助于更好的理解实例恢复
1)背景:当实例崩溃发生时,内存数据丢失,而当时的内存中db buffe和磁盘上的datafile内容不一致。
2)要解决两个问题:
①重新构成崩溃时内存中还没有保存到磁盘的已commit的变更块。
②回滚掉已被写至数据文件的uncommit的变更块。
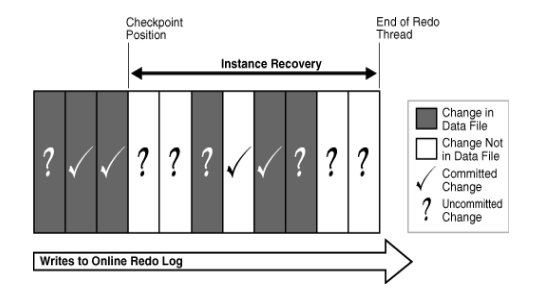
9.2增量检查点发挥的作用
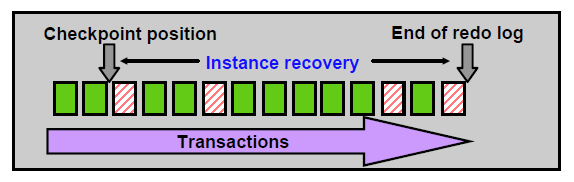
每当增量检查点触发时,一部分dirty buffer被刷新到磁盘,并记录了最后一次检查点位置。当实例恢复时,Oracle首先从控制文件里找到最后一次检查点位置,这个位置其实就是实例恢复时运用日志的起点(RBA)。然后是smon监控下的一系列动作:
- roll forward
利用redo,将检查点位置之后的变更,包括commit和uncommit的都前滚出来了,然后统统写到磁盘(datafile)里。
- open
用户可以连接进来,访问数据库。
- roll back
回滚掉数据文件中未提交的数据
- :手工创建数据库
要求:参考联机文档,建立一个基本的数据库,名称:emrep
第一步,编辑.bash_profile环境变量
$cp .bash_profile .bash_profile.prod
$vi .bash_profile
ORACLE_BASE=/u01
ORACLE_HOME=$ORACLE_BASE/oracle
ORACLE_SID=emrep
PATH=$ORACLE_HOME/bin:$PATH
export ORACLE_BASE ORACLE_HOME ORACLE_SID PATH
source
第二步,建立必要的目录
$mkdir -p /u01/admin/emrep/adump
$mkdir -p /u01/oradata/emrep
第三步,编辑pfile, 指定基本参数
$vi $ORACLE_HOME/dbs/initemrep.ora
db_name='EMREP'
memory_target=500m
control_files = ('/u01/oradata/emrep/control01.ctl','/u01/oradata/emrep/control02.ctl')
audit_file_dest='/u01/admin/emrep/adump'
db_block_size=8192
diagnostic_dest='/u01'
undo_tablespace='UNDOTBS1'
第四步, 建立口令文件、spfile
$orapwd file=$ORACLE_HOME/dbs/orapwemrep password=oracle entries=5
SQL> startup nomount pfile=/u01/oracle/dbs/initemrep.ora
SQL> create spfile from pfile;
SQL> startup force nomount;
第五步, 建立数据库
SQL> CREATE DATABASE emrep
USER SYS IDENTIFIED BY oracle
USER SYSTEM IDENTIFIED BY oracle
LOGFILE GROUP 1 '/u01/oradata/emrep/redo01.log' SIZE 30M,
GROUP 2 '/u01/oradata/emrep/redo02.log' SIZE 30M,
GROUP 3 '/u01/oradata/emrep/redo03.log' SIZE 30M
MAXLOGFILES 5
MAXLOGMEMBERS 5
MAXLOGHISTORY 1
MAXDATAFILES 100
CHARACTER SET AL32UTF8
NATIONAL CHARACTER SET AL16UTF16
EXTENT MANAGEMENT LOCAL
DATAFILE '/u01/oradata/emrep/system01.dbf' SIZE 325M REUSE
SYSAUX DATAFILE '/u01/oradata/emrep/sysaux01.dbf' SIZE 325M REUSE
DEFAULT TABLESPACE users
DATAFILE '/u01/oradata/emrep/users01.dbf'
SIZE 100M REUSE AUTOEXTEND ON MAXSIZE UNLIMITED
DEFAULT TEMPORARY TABLESPACE temp1
TEMPFILE '/u01/oradata/emrep/temp01.dbf'
SIZE 20M REUSE
UNDO TABLESPACE undotbs1
DATAFILE '/u01/oradata/emrep/undotbs01.dbf'
SIZE 100M REUSE AUTOEXTEND ON MAXSIZE UNLIMITED;
第六步,运行脚本,生成必要的数据字典和PLSQL包
[oracle@cuug emrep]$ sqlplus / as sysdba
SQL>startup
生成必要的数据字典(?代表oracle_home)
SQL> @?/rdbms/admin/catalog.sql
生成必要PLSQL包
SQL> @?/rdbms/admin/catproc.sql
SQL>conn system/oracle
必要的授权
SQL> @?/sqlplus/admin/pupbld.sql
至此,手工创建一个基本的数据库完毕
第七步,设定归档模式(可选)
SQL> archive log list;
数据库日志模式 非存档模式
自动存档 禁用
存档终点 /u01/oracle/dbs/arch
最早的联机日志序列 9
当前日志序列 11
$mkdir -p /u01/arch2
SQL> alter system set log_archive_dest_1='location=/u01/arch2';
SQL> alter system set log_archive_format='arch_%t_%r_%s.log' scope=spfile;
SQL> shutdown immediate;
SQL> startup mount
SQL> alter database archivelog;
SQL> alter database open;
检查emrep数据库工作正常
SQL>alter system switch logfile;
第八步,删除emrep(可选)
使用dbca,为了让dbca识别出emrep数据库,需要先编辑oratab配置文件
$vi /etc/oratab
最后一行添加如下信息
#
prod:/u01/oracle:N
emrep:/u01/oracle:N
注:dbca仅仅是删除emrep数据库,可能没有清除emrep相关的目录,需要再手工清理一下。
第二部分 存储架构
第十一章:数据字典
11.1什么是数据字典
1)Oracle提供了大量的内部表,它们记录了数据库对象的更改和修正。可以将这些内部表划分为两种主要类型:静态的数据字典表和动态的性能表。这些内部表是由oracle维护的,它们都是只读表。用户包括sys都不能修改,只能查看。
2)Oracle数据库字典通常是在创建和安装数据库时被创建的
11.2数据字典内容
1)数据库中所有模式对象的信息,如表、视图、簇、及索引等。
2)分配多少空间,当前使用了多少空间等。
3)列的缺省值。
4)约束信息的完整性。
5)Oracle用户的名字。
6)用户及角色被授予的权限。
7)用户访问或使用的审计信息。
8)其它产生的数据库信息
11.3数据字典组成
1)数据字典表:是Oracle存放系统数据的表。这些表属于SYS用户。用以存储表、索引、约束以及其他数据库结构信息,通常以$结尾,如tab$,obj$,ts$,aud$等。
2)数据字典视图:数据字典表上创建,通常分为三类dba_, all_, user_.
- 内部表(X$):Oracle的核心,官网不做说明, Oracle通过大量X$建立起大量视图,仅供用户select
4)动态性能表(V$):实时更新反应当前实例的状态,官网对V$视图有详尽的说明。
实际工作中最常用的是数据字典视图和动态性能表:
广义概念中:v$也属于数据字典范畴。因为v$的结构也是在创建数据库的时候通过执行脚本完成的。与数据字典视图不同的是:v$数据源不是来自system表空间,而是来自内存或控制文件,它在实例启动后被填充,在实例关闭后被清除。

11.4查询静态和动态视图
1)DICT表记录了所有静态视图和动态视图的名称
SQL> select * from dict where table_name='DBA_OBJECTS';
SQL> select count(*) from dict;
2)数据字典视图:静态(static)视图
在数据库open状态下访问,可以通过静态视图了解database的架构(记录database的架构
dba_:存储所有用户对象的信息(默认只能有sys/system 用户访问)
all_:存储当前用户能够访问的对象(包括用户所拥有的对象和别的用户授权访问的对象)的信息。
user_:存储当前用户所拥有的对象的相关信息。
3)动态性能视图(V$)
是维护当前实例信息的,由于不断的更新,所以也叫动态视图。其底层是一组虚拟的动态表称为X$表,Oracle不允许直接访问X$表,而是在这些表上创建视图,然后再创建这些视图的同义词。
基表(x$)-------------视图(v_$)--------------同义词v$-------用户访问
可以通过v$fixed_table 视图 查到所有的动态视图的名称;用于调优和数据库监控。
SQL> select count(*) from v$fixed_table;
从Oracle8开始, GV$视图开始被引入,其含义为Global V$,GV$的产生是为了满足OPS环境的需要,除了一些特例以外,每个V$视图都有一个GV$视图存在。
4)如何让普通用户访问dba_xxx的三种授权方法
第一种SQL>grant select on dba_objects to scott;
第二种SQL>grant select any dictionary to scott;
第三种
SQL>grant select any table to scott;
SQL>alter system set O7_DICTIONARY_ACCESSIBILITY=true scope=spfile;
5)如何让普通用户访问v$xxx
SQL>grant select on v_$log to scott; 授予Scott 用户v_$对象权限
第十二章:逻辑存储架构
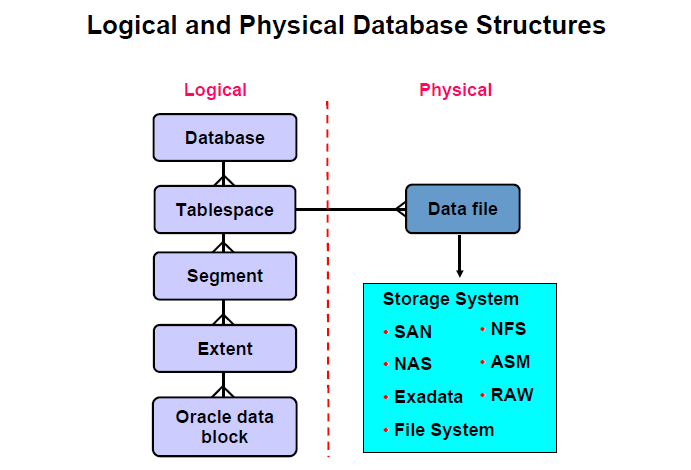
12.1 TABLESPACE(表空间)
12.1.1 类型
①PERMANENT 永久表空间
②UNDO 撤销表空间
③TEMPORARY 临时表空间
12.1.2 管理方式:
重点是段的管理方式和区的管理方式是在建立表空间时确定的。
段管理方式有AUTO和MANUAL两种,区管理方式有本地管理和字典管理(已淘汰)两种。
SQL> select tablespace_name,contents ,extent_management,segment_space_management from dba_tablespaces;
TABLESPACE_NAME CONTENTS EXTENT_MAN SEGMEN
------------------------------ --------- ---------- ------
SYSTEM PERMANENT DICTIONARY MANUAL
SYSAUX PERMANENT LOCAL AUTO
TEMP TEMPORARY LOCAL MANUAL
USERS PERMANENT LOCAL AUTO
EXAMPLE PERMANENT LOCAL AUTO
UNDO_TBS01 UNDO LOCAL MANUAL
TMP01 TEMPORARY LOCAL MANUAL
TEST PERMANENT DICTIONARY MANUAL
注意两点:
1)如果system表空间是数据字典管理,其他表空间可以是数据字典管理或local管理(默认)
2)字典管理可以转换成本地管理,但是对于系统表空间,要求执行一些附加步骤,比较麻烦。
SQL>execute dbms_space_admin.tablespace_migragte_to_local('tablespacename');
12.1.3 基本操作
1)建立表空间
SQL> create tablespace a datafile '/u01/oradata/prod/a01.dbf' size 10m;
利用oracle提供的dbms_metadata.get_ddl包看看缺省值都给的是什么?
SQL> set serverout on;
SQL>
declare
aa varchar2(2000);
begin
select dbms_metadata.get_ddl('TABLESPACE','A') into aa FROM dual;
dbms_output.put_line(aa);
end;
/
结果:
CREATE TABLESPACE "A" DATAFILE
'/u01/oradata/prod/a01.dbf' SIZE 10485760
LOGGING ONLINE PERMANENT BLOCKSIZE
8192
EXTENT MANAGEMENT LOCAL AUTOALLOCATE
SEGMENT SPACE MANAGEMENT AUTO
PL/SQL 过程已成功完成。
关注最后一行,两个重要信息是:(1)区本地管理且自动分配空间,(2)段自动管理。
dbms_metadata.get_ddl也可以查看表,('TABLE','EMP','SCOTT')替换('TABLESPACE','B')试试。
SQL>
create tablespace b datafile '/u01/oradata/prod/b01.dbf' size 10m
extent management local uniform size 128k
segment space management manual
同上,调dbms_metadata.get_ddl包看Oracle对该语句的ddl操作是:
CREATE TABLESPACE "B" DATAFILE
'/u01/oradata/prod/a01.dbf' SIZE 10485760
LOGGING ONLINE PERMANENT BLOCKSIZE
8192
EXTENT MANAGEMENT LOCAL UNIFORM SIZE 131072 SEGMENT SPACE MANAGEMENT MANUAL、
最后一行信息是:区本地管理且统一分配128K, 段手动管理。如果在建表时使用缺省说明,则该表将服从其表空间的这些定义,
2) 删除表空间
1、表空间的删除和offline
SQL>drop tablespace test including contents and datafiles;
contents包括控制文件和数据字典信息,datafiles是物理数据文件。
数据库OPEN下不能删除的表空间是
①system ②active undo tablespace ③default temporary tablespace ④default tablespace
数据库OPEN下不能offine的表空间是
①system ②active undo tablespace ③default temporary tablespace
- 查看表空间大小
SQL> select TABLESPACE_NAME,sum(bytes)/1024/1024 from dba_data_files group by tablespace_name;
4)查看表空间空闲大小
SQL> select TABLESPACE_NAME,sum(bytes)/1024/1024 from dba_free_space group by tablespace_name;
TABLESPACE_NAME SUM(BYTES)/1024/1024
------------------------------ --------------------
UNDOTBS1 98.4375
SYSAUX 14.625
USERS 48.1875
SYSTEM 1.875
EXAMPLE 31.25
- 查看表空间(数据文件)是否自动扩展
SQL> col file_name for a40;
SQL> select file_name,tablespace_name,bytes/1024/1024 mb,autoextensible from dba_data_files;
6)建立大文件(bigfile)的表空间
①small file,在一个表空间可以建立多个数据文件(默认)
②bigfile :在一个表空间只能建立一个数据文件 (必须是8k的block ,最大可达32T),简化对数据文件管理。
SQL> create bigfile tablespace big_tbs datafile '/u01/oradata/prod/bigtbs01.dbf' size 100m;
试图在该表空间下增加一个数据文件会报错
SQL> alter tablespace big_tbs add datafile '/u01/oradata/prod/bigtbs02.dbf' size 100m;
报错:ORA-32771: cannot add file to bigfile tablespace
查看大文件表空间:
SQL> select name,bigfile from v$tablespace;
12.2 SEGMENT(段)
12.2.1 特点:
1)表空间在逻辑上可以对应多个段,物理上可以对应多个数据文件,一个段比较大时可以跨多个数据文件。
2)创建一个表,ORACLE为表创建一个(或多个)段,在一个段中保存该表的所有表数据(表数据不能跨段)。
3)段中至少有一个初始区。当这个段数据增加使得区(extent)不够时,将为这个段分配新的后续区。
12.2.2段管理方式:
1)自动管理方式,简称ASSM(Auto Segment Space Management) 采用位图管理段的存储空间
原理:简单说就是每个段的段头都有一组位图(5个位图),位图描述每个块的满度,根据满度的不同将每个块登记到相应的位图上,位图自动跟踪每个块的使用空间(动态),5个位图的满度按如下定义:满度100%,75%、50%、25%和0%,比如块大小为8k,你要插入一行是3k的表行,那么oracle就给你在满度50%的位图上找个登记的可插入的块。
ASSM的前提是EXTENT MANAGEMENT LOCAL,在ORACLE9I以后,缺省状态为自动管理方式,ASSM废弃pctused属性。
2)手工管理方式,简称MSSM(Manual Segment Space Management) 采用FREELIST(空闲列表)管理段的存储空间
原理:这是传统的方法,现在仍然在使用,涉及三个概念 freelist、pctfree和pctused,
①freelist:空闲列表中登记了可以插入数据的可用块,位置在段头,插入表行数据时首先查找该列表。
②pctfree:用来为一个块保留的空间百分比,以防止在今后的更新操作中增加一列或多列值的长度。达到该值,从freelist清除该块信息。
③pctused:一个块的使用水位的百分比,这个水位将使该块返回到可用列表中去等待更多的插入操作。达到该值,该块信息登录到freelist。
这个参数在ASSM下不使用。ASSM使用位图状态位取代了pctused
12.2.3 表和段的关系
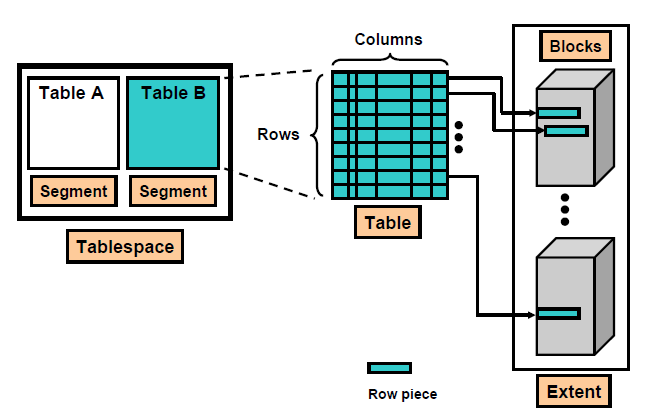
1)一般来讲,一个单纯的表就分配一个段,但往往表没那么单纯,比如表上经常会有主键约束,那么就会有索引,索引有索引段,还有分区表,每个分区会有独立的段,再有就是Oracle的大对象, 如果你的表里引用blob,clob,那么这个表就又被分出多个段来。
测试:
SQL> conn / as sysdba
SQL> grant connect,resource to tim identified by tim;
SQL> conn tim/tim
SQL> select * from user_segments;
SQL> create table t1 (id int);
SQL> select segment_name from user_segments;
SQL> create table t2 (id int constraint pk_t2 primary key, b blob, c clob);
SQL> select segment_name from user_segments;
- 延迟段。顾名思义,创建表的时候并不马上建立相应的段。
Oracle11gR2又增加了一个新的初始化参数DEFERRED_SEGMENT_CREATION(仅适用未分区的heap table), 此参数默认TRUE,当create table后并不马上分配segment, 仅当第一个insert语句后才开始分配segment。这对于应用程序的部署可能有些好处。(PPT-II-476-478)
也可以使局部设置改变这一功能(覆盖DEFERRED_SEGMENT_CREATION=TRUE),在create table语句时加上SEGMENT CREATION子句指定。如:
SQL>create table scott.t1(id int,name char(10)) SEGMENT CREATION IMMEDIATE TABLESPACE TB1;
12.3 EXTENT(区)
12.3.1 特点:
区是ORACLE进行存储空间分配的最小单位。一个区是由一系列逻辑上连续的Oracle数据块组成的逻辑存储结构。段中第一个区叫初始区,随后分配的区叫后续区。
12.3.2 管理方式:
1)字典管理:在数据字典中管理表空间的区空间分配。Oracle 8i以前只有通过uet$和fet$的字典管理。
缺点:某些在字典管理方式下的存储分配有时会产生递归操作,并且容易产生碎片,从而影响了系统的性能,现在已经淘汰了。
2)本地管理:在每个数据文件中使用位图管理空间的分配。表空间中所有区(extent)的分配信息都保存在该表空间对应的数据文件的头部。
优点:速度快,存储空间的分配和回收只是简单地改变数据文件中的位图,而不像字典管理方式还需要修改数据库。无碎片,更易于DBA维护。
12.3.3 表和区的关系:
当建立表的时候建立段,然后自动分配相应的extent(1个或者多个),亦可以手工提前分配extent(用于需大量插入数据的表)
实验:查看段的初始区分配情况
sys:
SQL> create tablespace test datafile '/u01/oradata/prod/test01.dbf' size 10m;
SQL> create table scott.t1 tablespace test as select * from scott.dept;
SQL> col segment_name for a20;
SQL> select segment_name,file_id,extent_id,blocks,block_id,bytes/1024/1024 mb from dba_extents where segment_name='T1';
SQL> commit;
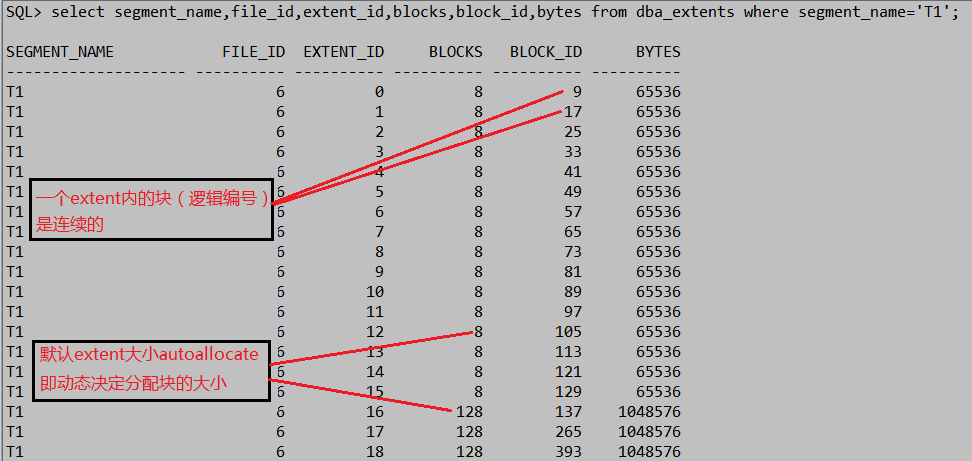
删除掉四分之三数据,看看extent是否收回
SQL> delete scott.t1 where deptno>15;
已删除98304行
SQL> commit;
重新插入一倍的数据,看看extent是否增加
SQL>insert into scott.t1 select * from scott.t1;
已创建32768行。
思考一下上面的步骤说明了什么?
12.3.4 预先分配空间
可以根据需要预先分配一些extent
SQL>alter table scott.t1 allocate extent (datafile '/u01/oradata/prod/test01.dbf' size 5m);
注意:预分配的空间一定是在表空间可达到的size范围内
回收free extent, 使用deallocate,
SQL> alter table scott.t1 deallocate unused;
注意:只能收回从未使用的extent
12.4 BLOCK(数据块)
12.4.1 OracleBlock的构成
BLOCK是Oracle进行存储空间IO操作的最小单位。构成上分为block header、free space、data
数据块头部:
①ITL:事务槽,可以有多个ITL以支持并发事务,每当一个事务要更新数据块里的数据时,必须先得到一个ITL槽,然后将当前事务ID,事务所用的undo数据块地址,SCN号,当前事务是否提交等信息写到ITL槽里。
②initrans :初始化事务槽的个数,表默认1, index 默认为2;
③maxtrans: 最大的事务槽个数 (默认255)
④ROW DIR: 行目录, 指向行片段行起始和结束的偏移量。
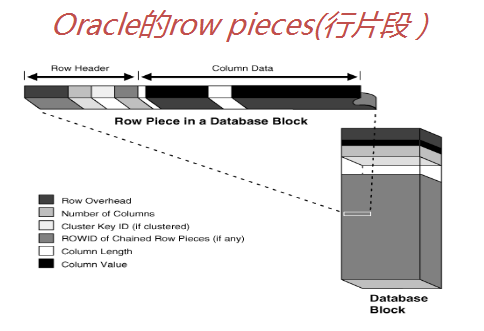
考点:使块头增加的可能情况是,row entries增加,增加更多的ITL空间。
12.4.2行链接和行迁移
1)什么是行链接和行迁移
①行链接:指一行存储在多个块中的情况,即行链接是跨越多块的行。
②行迁移:指一个数据行由于update语句导致当前行被重新定位到另一个块(那里有充足的空间)中,但在原始块中会保留一个指针。原始块中的指针是必需的,因为索引的ROWID项仍然指向原始位置。
行迁移是update语句当pctfree空间不足时引起的,它与insert和delete语句无关。
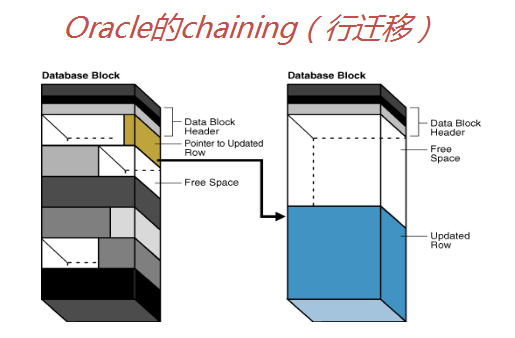
2)如何知道发生了行链接或行迁移
查看dba_tables的AVG_ROW_LEN列和CHAIN_CNT列。当CHAIN_CNT有值时,看AVG_ROW_LEN,它表示行的平均长度(byte),如果AVG_ROW_LEN<块大小,发生的是行迁移,否则可能有行链接。
测试:
SCOTT:
SQL> create table t1 (c1 varchar2(20));
SQL>
begin
for i in 1..1000 loop
insert into t1 values(null);
end loop;
end;
/
先分析一下t1表,确定无行迁移
SQL> analyze table t1 compute statistics;
SQL> select pct_free,pct_used,avg_row_len,chain_cnt,blocks from user_tables where table_name='T1';
PCT_FREE PCT_USED AVG_ROW_LEN CHAIN_CNT BLOCKS
---------- ---------- ----------- ---------- ----------
10 3 0 5
使用了5个块
SQL> select distinct file#,block# from v$bh a,user_objects b where a.objd=b.object_id order by 2;
v$bh视图可以显示出t1表一共分配了8个块,具体是那些块。
填充这些空列,再分析t1,有了行迁移
SQL> update t1 set c1='prod is my name';
SQL> commit;
SQL> analyze table t1 compute statistics;
SQL> select pct_free,pct_used,avg_row_len,chain_cnt,blocks from user_tables where table_name='T1';
PCT_FREE PCT_USED AVG_ROW_LEN CHAIN_CNT BLOCKS
---------- ---------- ----------- ---------- ----------
10 22 865 13
说明1000行中有865行发生了行迁移,使用的块也增加了。
3)怎样确定那些行发生了行迁移
$ sqlplus / as sysdba
SQL> @/u01/oracle/rdbms/admin/utlchain.sql
SQL> analyze table scott.t1 LIST CHAINED ROWS;
SQL> select count(*) from chained_rows;
COUNT(*)
----------
865
SQL> select table_name, HEAD_ROWID from chained_rows where rownum<=3;
TABLE_NAME HEAD_ROWID
------------------------------ ------------------
T1 AAASC4AAEAAAAIfABQ
T1 AAASC4AAEAAAAIfABR
T1 AAASC4AAEAAAAIfABS
SQL> Select dbms_rowid.ROWID_RELATIVE_FNO(rowid) fn,
dbms_rowid.rowid_block_number(rowid) bn, rowid,c1 from scott.t1 where rowid='AAASPhAAEAAAAIdABQ';
FN BN ROWID C1
---------- ---------- ------------------ --------------------
4 541 AAASPhAAEAAAAIdABQ prod is my name
4)解决行迁移有很多方法
可以根据上例chained_rows 表中提供的rowid,将t1表中的那些记录删除,然后在重新插入。
这里使用move解决,简单些:
SQL> alter table t1 move;
move表后,再分析t1,行迁移消失。
SQL> analyze table t1 compute statistics;
SQL> select pct_free,pct_used,avg_row_len,chain_cnt,blocks from user_tables where table_name='T1';
PCT_FREE PCT_USED AVG_ROW_LEN CHAIN_CNT BLOCKS
---------- ---------- ----------- ---------- ----------
10 19 0 6
12.4.3表和数据块的关系
1)什么是高水位线?
高水位线(high-water mark,HWM)
在数据库中,如果把表想象成从左到右依次排开的一系列块,高水位线就是曾经包含了数据的最右边的块。原则上HWM只会增大, 即使将表中的数据全部删除,HWM也不会降低。
2)HWM有利有弊,
优点:可以使HWM以下的块重复利用
缺点:使用全表扫描时要读取HWM以下的所有block,耗费更多的IO资源。
12.4.4如何降低HWM
多种方法可以降低HWM:①移动表,②收缩表,③导入导出表,④在线重定义表
- 移动表
move方法, 将表从一个表空间移动到另一个表空间(也可以在本表空间内move)。
语法:alter table t1 move [tablespace users];
优点:可以清除数据块中的碎片,降低高水位线。适用MSSM和ASSM
缺点:
①move需要额外(一倍)的空间。
②move过程中会锁表,其他用户不能在该表上做DML或DDL操作。
③move之后,相关索引都不可用了,表上的索引需要重建。
测试move后索引不可用
SCOTT:
SQL>create table emp1 as select * from emp;
SQL>create index emp1_idx on emp1(ename);
SQL>select table_name,index_name,status from user_indexes where table_name='EMP1';
TABLE_NAME INDEX_NAME STATUS
------------------------------ ------------------------------ --------
EMP1 EMP1_IDX VALID
SQL>alter table emp1 move;
SQL>select table_name,index_name,status from user_indexes where table_name='EMP1';
TABLE_NAME INDEX_NAME STATUS
------------------------------ ------------------------------ --------
EMP1 EMP1_IDX UNUSABLE
SQL>alter index EMP1_IDX rebuild;
SQL>select table_name,index_name,status from user_indexes where table_name='EMP1';
TABLE_NAME INDEX_NAME STATUS
------------------------------ ------------------------------ --------
EMP1 EMP1_IDX VALID
- 收缩表
Shrink方法,也叫段重组,表收缩的底层实现的是通过匹配的INSERT和DELETE操作。
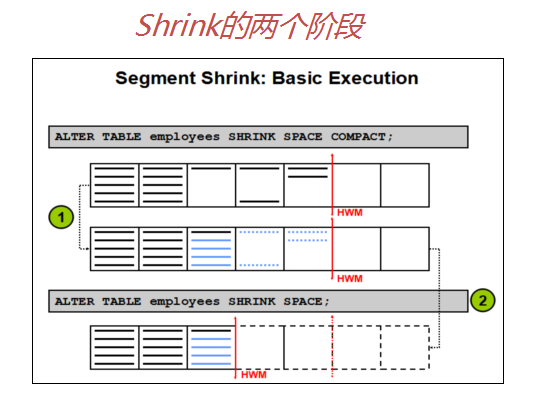
语法:alter table t2 shrink space [cascade][compact];
优点:使用位图管理技术,①降低热块,②更合理的重新利用空闲块
缺点:①要求段管理是ASSM方式,②表上启用row movement。
它分两个不同的阶段:压缩阶段和降低HWM阶段。(PPT-II-491)
第一阶段:发出alter table t2 shrink space compact命令;这是压缩阶段。在业务高峰时可以先完成这样步骤
第二阶段:再次alter table t2 shrink space; 因压缩阶段工作大部分已完成,将很快进入降低HWM阶段,DML操作会有短暂的锁等待发生。
测试:
SQL>create table scott.t2 as select * from dba_objects;
scott:
SQL>select max(rownum) from t2;
SQL> analyze table t2 compute statistics;
SQL> select table_name,blocks,empty_blocks,num_rows from user_tables where table_name='T2';
TABLE_NAME BLOCKS EMPTY_BLOCKS NUM_ROWS
------------------------------ ---------- ------------ ----------
T2 1039 113 68875
Blocks:表示使用过的块,即低于HWM的块数量。
empty_blocks:表示extent分配了,但从未使用过的块,即高于HWM的块数量
两厢之和1039+113=1152是这个段分配的块数
SQL> select segment_name,blocks from user_segments where segment_name='T2';
SEGMENT_NAME BLOCKS
-------------------- ----------
T2 1152
删除40000行
SQL>delete t2 where rownum<=40000;
SQL>commit;
SQL> analyze table t2 compute statistics;
SQL> select table_name,blocks,empty_blocks,num_rows from user_tables where table_name='T2';
TABLE_NAME BLOCKS EMPTY_BLOCKS NUM_ROWS
------------------------------ ---------- ------------ ----------
T2 1039 113 28875
num_rows已经减掉了40000条, 但 blocks 并没有减少, 说明HWM没有下降。
做shrink
SQL>alter table t2 enable row movement; 使能行移动
第一步:压缩阶段
SQL>alter table t2 enable row movement;;
SQL>analyze table t2 compute statistics for table;
SQL> select table_name, blocks, empty_blocks, num_rows from user_tables where table_name='T2'; HWM不会降低。
第二步:降低HWM阶段
SQL> alter table t2 shrink space;
SQL> analyze table t2 compute statistics;
SQL> select table_name,blocks,empty_blocks,num_rows from user_tables where table_name='T2';
TABLE_NAME BLOCKS EMPTY_BLOCKS NUM_ROWS
------------------------------ ---------- ------------ ----------
T2 426 22 28875
12.5 临时表空间
12.5.1用途:
用于缓存排序的数据(中间结果)
可以建立多个临时表空间,但默认的临时表空间只能有一个且不能offline和drop。temp表空间是nologing的(不记日志)。
SQL> select file_id,file_name,tablespace_name from dba_temp_files;
FILE_ID FILE_NAME TABLESPACE_NAME
---------- -------------------------------------------------- ------------------------------
1 /u01/oradata/prod/temp01.dbf TEMP
SQL> col name for a60;
SQL> select file#,name ,bytes/1024/1024 from v$tempfile;
FILE# NAME BYTES/1024/1024
---------- -------------------------------------------------- ---------------
1 /u01/oradata/prod/temp01.dbf 100
12.5.2 基本操作
1)建立临时表空间temp2。增加或删除tempfile。
SQL> create temporary tablespace temp2 tempfile '/u01/oradata/prod/temp02.dbf' size 10m;
SQL> alter tablespace temp2 add tempfile '/u01/oradata/prod/temp03.dbf' size 5m;
SQL> select file_id,file_name,tablespace_name from dba_temp_files;
FILE_ID FILE_NAME TABLESPACE_NAME
---------- -------------------------------------------------------------------------------- -----------------------
1 /u01/oradata/prod/temp01.dbf TEMP
2 /u01/oradata/prod/temp02.dbf TEMP2
3 /u01/oradata/prod/temp03.dbf TEMP2
将temp2里删掉一个tempfile。
SQL> alter tablespace temp2 drop tempfile '/u01/oradata/prod/temp03.dbf';
SQL> select file_id,file_name,tablespace_name from dba_temp_files;
2) 查看默认的临时表空间
SQL> select * from database_properties where rownum<=5;
3) 指定用户使用临时表空间
SQL> alter user scott temporary tablespace temp2;
4) 切换默认的临时表空间
SQL> alter database default temporary tablespace temp2;
12.5.3 临时表空间组 (10g新特性)
在很多情况下,会有多个session 使用同一个用户名去访问Oracle,而临时表空间又是基于用户的,那么可以建立一个临时表空间组,组中由若干临时表空间成员构成,从而可以提高单个用户多个会话使用临时表空间的效率。
1)临时表空间组无法显式创建,组是通过第一个临时表空间分配时自动创建。
SQL> alter tablespace temp1 tablespace group tmpgrp;
SQL> alter tablespace temp2 tablespace group tmpgrp;
SQL> select * from dba_tablespace_groups;
GROUP_NAME TABLESPACE_NAME
------------------------------ ------------------------------
TMPGRP TEMP1
TMPGRP TEMP2
2)将临时表空间组设成默认临时表空间,实现负载均衡。
SQL> alter database default temporary tablespace tmpgr;
3)要移除表空间组时,该组不能是缺省的临时表空间。
SQL> alter database default temporary tablespace temp;
SQL> alter tablespace temp1 tablespace group '';
SQL> alter tablespace temp2 tablespace group '';
4)当组内所有临时表空间被移除时,组也被自动删除。
SQL> select * from dba_tablespace_groups;
no rows selected
SQL> drop tablespace temp2 including contents and datafiles;
考点:某个tempfile坏掉使得default temporary tablespace不能正常工作,数据库不会crash, 解决的办法是add一个新的tempfile,然后
再drop掉坏的tempfile.(default temporary tablespace不能offline,但temporary file可以offline)
12.6 如何调整表空间的尺寸
表空间的大小等同它下的数据文件大小之和
当发生表空间不足的问题时常用的3个解决办法:
1)增加原有数据文件大小(resize)
2)增加一个数据文件(add datafile)
3)设置表空间自动增长(autoextend)
示例:
SQL> create tablespace prod datafile '/u01/oradata/prod/prod01.dbf' size 5m;
SQL> create table scott.test1 (id int) tablespace prod;
SQL> insert into scott.test1 values(1);
SQL> insert into scott.test1 select * from scott.test1;
SQL> /
SQL> /
报错:ORA-01653: unable to extend table SCOTT.TEST1 by 8 in tablespace prod
1)用第一种方法扩充表空间
SQL> alter database datafile '/u01/oradata/prod/prod01.dbf' resize 10m;
SQL> insert into scott.test1 select * from scott.test1;
SQL> /
SQL> /
报错:ORA-01653: unable to extend table SCOTT.TEST1 by 128 in tablespace prod
2)用第二种方法扩充表空间:
SQL> alter tablespace prod add datafile '/u01/oradata/prod/prod02.dbf' size 20m;
SQL> insert into scott.test1 select * from scott.test1;
SQL> /
SQL> /
报错:ORA-01653: unable to extend table SCOTT.TEST1 by 128 in tablespace prod
3)用第三种方法扩充表空间:
SQL> alter database datafile '/u01/oradata/prod/prod01.dbf' autoextend on next 10m maxsize 500m;
SQL> insert into scott.test1 select * from scott.test1;
SQL> drop tablespace prod including contents and datafiles;
12.7 可恢复空间分配Resumable
当我们往一个表里面插入大量数据时,如果某条insert语句因表空间的空间不足(没有开启自动扩展),会报 ORA-01653:无法扩展空间的错误,该条SQL语句会中断,浪费了时间及数据库资源。为防范这个问题,Oracle设计了resumable。
- 功能:
在resumable开启的情况下,如果Oracle执行某条SQL申请不到空间了,比如数据表空间,undo表空间,temporary空间等,则会将该事务的语句挂起(suspended),等
你把空间扩展后,Oracle又会使该insert语句继续进行。
- 设置方法
可以通过两个级别设置resumable
①system级别:初始化参数RESUMABLE_TIMEOUT非0,这将使数据库中所有session使用可恢复的空间分配
②session级别:alter session enable|disable resumable [TIMEOUT]; 这将为当前session设置可恢复的空间分配。因为resumable是有资源消耗代价的, 所以session级的resumable是比较实用的。
- 参数RESUMABLE_TIMEOUT的用法
单位为秒,
RESUMABLE_TIMEOUT=0, enable session时应该指定TIMEOUT。否则使用缺省值7200秒。
RESUMABLE_TIMEOUT<>0,enable session时可以省略TIMEOUT,此时指定TIMEOUT会覆盖掉参数RESUMABLE_TIMEOUT值。
示例:
session 1:
1)建个小表空间,固定2m大小,然后建个表属于这个表空间
SQL> create tablespace small datafile '/u01/oradata/prod/small01.dbf' size 2m;
SQL> create table scott.test(n1 char(1000)) tablespace small;
2)向这个表插入数据,表空间满了,使for语句没有完成循环,2000条语句整体失败。
SQL> begin
for i in 1..2000 loop
insert into scott.test values('this is test');
end loop;
commit;
end;
/
报错:ORA-01653: 表 SCOTT.TEST 无法通过 128 (在表空间 SMALL 中) 扩展
这个128是块数,表明最后一次需要1M的extent,没有成功.
SQL> select count(*) from scott.test;
COUNT(*)
----------
0
因为没有在循环体内commit,所以插入的记录全部回滚了。
3)使能 resumable功能
SQL> alter session enable resumable;
4)再重复第2)步,会话被挂起;
session 2:
5)查看视图的有关信息
SQL> select session_id,sql_text,error_number from dba_resumable;
SESSION_ID SQL_TEXT ERROR_NUMBER
---------- -------------------------------------------------- ------------
136 INSERT INTO SCOTT.TEST VALUES('this is test') 1653
SQL> select sid,event,seconds_in_wait from v$session_wait where sid=136;
SID EVENT SECONDS_IN_WAIT
---------- ---------------------------------------------------------------- ---------------
136 statement suspended, wait error to be cleared 1
6)加扩表空间,看到session1里挂起的会话得以继续并成功完成了2000条语句的插入。
SQL> alter tablespace small add datafile '/u01/oradata/prod/small02.dbf' size 4m;
SQL> select count(*) from scott.test;
COUNT(*)
----------
2000
7)查看EM告警日志报告了以上信息。验证结束后可以disable resumable, 并删除small表空间及数据文件。
session 1:
SQL> alter session disable resumable;
SQL> drop tablespace small including contents and datafiles;
第三部分 网络、审计、字符集
第十四章:Oracle网络
14.1 Oracle Net是什么
建立在通用的TCP和IPC之上的网络协议
1)服务器端的listener (监听器)负责注册的Oracle的服务
2)远程客户端通过Oracle Net访问Oracle服务器端的服务
3)以TCP协议为基础的OracleNet必须描述三个基本要素:
①协议是TCP、②服务器的IP地址或主机名、③端口号
14.2 配置文件
Oracle Net配置文件都是文本形式的,可以通过netca或netmgr实用程序生成和修改,也可以使用文本编辑器生成和修改。
1) Oracle Net配置文件的路径
$ORACLE_HOME/network/admin/
2) 三个Oracle Net配置文件
①listener.ora在服务器端的配置文件
②tnsnames.ora在客户端的配置文件
③sqlnet.ora描述连接方式的配置文件
14.3 轻松连接方式(ezconnect)
优点:不需要网络配置文件的描述。缺点:登录不方便
连接方法:只要服务器端启动默认的监听器listener,并数据库打开(动态注册)
远程登录语法为:$Sqlplus 用户/密码@IP地址:端口号/服务名
C:\Documents and Settings\prod>sqlplus scott/scott@192.168.3.88:1521/prod
14.4 动态注册
- 动态注册要点
①实例启动后,pmon每分钟自动将服务名(service_name)注册到监听器中
也可以通过alter system register命令通知pmon立刻注册
②系统有一个默认的监听器叫做LISTENER,端口号是1521,利用它可以不需要listener.ora配置文件
③动态注册要求实例至少启动到mounted状态,listener监听器才能注册成功
- 如果不想使用默认的listener监听器,可以自定义一个动态监听器。需要下面完成两步操作:
①在listener.ora配置文件描述自定义监听器。如:
LSN1=
(DESCRIPTION=
(ADDRESS_LIST=
(ADDRESS=(PROTOCOL=tcp)(HOST=192.168.3.88)(PORT=1555))))
②更改local_listener参数
SQL> alter system set local_listener='(ADDRESS=(PROTOCOL=tcp)(HOST=192.168.3.88)(PORT=1555))'
14.5 静态注册
1)静态注册要点
①静态注册必须在listener.ora中描述
②实例不必启动,静态监听器也能注册
③服务器启动静态监听后,可以通过远程启动数据库
2)静态注册的描述分为两部分内容
①网络三要素:①Protocal ②Host ③Port
②服务名描述:GLOBAL_DBNAME:全局数据库名(静态注册特征)
- listener.ora配置示例
LSN2 =
(DESCRIPTION_LIST =
(DESCRIPTION =
(ADDRESS = (PROTOCOL = TCP)(HOST = 192.168.3.88)(PORT = 1522))
)
)
SID_LIST_LSN2 =
(SID_LIST =
(SID_DESC =
(GLOBAL_DBNAME=prod )
(ORACLE_HOME = /u01/oracle)
(SID_NAME =prod)
)
)
14.6 客户端配置文件tnsnames.ora
- 可以描述登录多个服务器
- 示例
prod=
(DESCRIPTION =
(ADDRESS_LIST =
(ADDRESS = (PROTOCOL = TCP)(HOST = 192.168.3.88)(PORT = 1522))
)
(CONNECT_DATA =
(SERVICE_NAME =prod)
)
)
14.7 理解监听器
1) 实例以service的形式对外提供服务,监听器负责注册service 。
2) Service_name对外屏蔽了实例和数据库的复杂描述。
3) 客户端tnsnames.ora的SERVICE_NAME与服务器端listener.ora的GLOBAL_DBNAME等同。
4) listener.ora中监听器的SID_NAME与实例的SID等同。
5) 一个$ORACLE_HOME下只能对应一个listener.ora和tnsnames.ora
6) 一个linstener.ora 可以描述多个监听器。
7) 一个tnsnames.ora 可以描述多个网络连接符。
8) 一个listener.ora可以为多个数据库描述监听器。
9) 一个实例可以对应多个service_name。
14.8 共享连接配置:
14.8.1 sharded server mode的几个参数
①dispatchers 调度进程数,一个despatcher process理论上可以支持256个user process请求。
②max_dispatchers dispatcher process最大数量,dispatchers<=max_dispatchers
③shared_servers 共享服务器进程数,与dispatcher process数有关, 最大不超过max_shared_servers
④max_shared_servers 所有session可使用的共享进程的最大值。
14.8.2 示例
1)要求session登录总数限制在300个以内,其中专用连接100个,共享连接200个。
SQL> alter system set sessions=300 scope=spfile;
SQL> alter system set shared_server_sessions=200; 共享user process数量
SQL> alter system set processes=150 scope=spfile; 专用user process数量
注:processes=专用连接数+后台进程数+(100*10%)约=150
2)要求分配3个dispatcher,最大dispatchers能支持10个
SQL> alter system set dispatchers='(protocol=tcp)(dispatchers=3)';
SQL> alter system set max_dispatchers=10;
共享server为10,最大共享server能支持30个
SQL> alter system set shared_servers=10;
SQL> alter system set max_shared_servers=30;
SQL> startup force;
SQL> show parameter dispatcher
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
dispatchers string (protocol=tcp)(dispatchers=3)
max_dispatchers integer 10
SQL> show parameter shared_server
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
max_shared_servers integer 30
shared_server_sessions integer 200
shared_servers integer 10
查看状态:
[oracle@prod ~]$ ps -ef |grep ora_d0
[oracle@prod ~]$ ps -ef |grep ora_s0
3)配置并启动两个监听器,
listener: 端口1521,动态注册,支持共享连接模式(支持200个user process)
lsn2:端口1522,静态注册,支持专用连接模式(支持100 个user process)
配置listener.ora
LISTENER =
(DESCRIPTION =
(ADDRESS = (PROTOCOL = TCP)(HOST = 192.168.3.88)(PORT = 1521))
)
LSN2 =
(DESCRIPTION =
(ADDRESS = (PROTOCOL = TCP)(HOST = 192.168.3.88)(PORT = 1522))
)
SID_LIST_LSN2 =
(SID_LIST =
(SID_DESC =
(GLOBAL_DBNAME = prod)
(ORACLE_HOME = /u01/oracle)
(SID_NAME = prod)
)
)
配置tnsnames.ora如下:
prod_s=
(DESCRIPTION =
(ADDRESS_LIST =
(ADDRESS = (PROTOCOL = TCP)(HOST = 192.168.3.88)(PORT = 1522))
)
(CONNECT_DATA =
(SERVER = DEDICATED)
(SERVICE_NAME =prod)
)
)
prod_d=
(DESCRIPTION =
(ADDRESS_LIST =
(ADDRESS = (PROTOCOL = TCP)(HOST = 192.168.3.88)(PORT = 1521))
)
(CONNECT_DATA =
(SERVER = SHARED)
(SERVICE_NAME =prod )
)
)
注意:
①(SERVER = DEDICATED): 表示此连接使用DEDICATED SERVER MODE 缺省的配置。
②(SERVER = SHARED): 表示此连接使用SHARED SERVER MODE, 如果服务器端未配置dispatchers, 此连接失败
③ 不做任何说明: 如果服务器端配置了dispatchers,SHARED SERVER MODE优先。
4)启动listener监听器,并查看动态注册是否成功
$ lsnrctl start
$ lsnrctl status
启动lsn2监听器,并查看静态注册是否成功
$ lsnrctl start lsn2
$ lsnrctl status lsn2
5)远程连接, 依次以两个session登录,
验证走专用连接
Session1:
C:\Users\Administrator>sqlplus system/oracle@prod_s
SQL>select sid from v$mystat where rownum=1; 得到当前session的sid
SID
----------
46
SQL> select sid,server,status from v$session where sid=46;
SID SERVER STATUS
---------- --------- --------
46 DEDICATED ACTIVE
验证走共享连接
Session2:
C:\Users\Administrator>sqlplus system/oracle@prod_d
SQL>select sid from v$mystat where rownum=1; 得到当前session的sid
SID
----------
37
SYS>select sid,server,status from v$session where sid=37;
SID SERVER STATUS
---------- --------- --------
37 SHARED ACTIVE
SQL> select sid,server,status from v$session where sid in (46,37);
SID SERVER STATUS
---------- --------- --------
46 DEDICATED INACTIVE
37 NONE INACTIVE
注:11gR2的session处于空闲时,查看状态SERVER是none,但active状态的应该是SHARED
第十五章:数据库审计audit
15.1 功能和类别:
1)功能:监控特定用户在database 的action(操作)
2)审计种类:
⑴标准数据库审计(①语句审计、②权限审计、③对象审计)
⑵基于值的审计(Value-Based, 触发器审计)
⑶精细度审计(FGA)
15.2 启用审计(默认不启用)
- 有关参数
SQL> show parameter audit
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
audit_file_dest string /u01/admin/adump
audit_sys_operations boolean FALSE
audit_syslog_level string
audit_trail string DB
SQL>
audit_trail参数主要选项
1)none 不启用audit
2)db 将审计结果放在数据字典基表sys.aud$中,(一般用于审计非sys用户,也可以移出system表空间,在system表空间中的好处是方便检索)
还有一种db扩展,即db,extended,可以包括绑定变量,CLOB类型大对象等审计信息(考点)。
3)os 将审计结果存放到操作系统的文件里(由audit_file_dest指定的位置, 一般用于审计sys)
如何审计sys
1)Oracle强制审计sys用户的特权操作,如启动和关闭数据库,结果记录在参数audit_file_dest指向的.aud文件中。
2)指定参数audit_sys_operations = true 和 audit_trail = os
15.3 标准数据库审计的三个级别
查看标准审计结果可以通过视图dba_audit_taile, 该视图读取aud$内容。
1)语句审计
按语句来审计,比如audit table会审计数据库中所有的create table, drop table, truncate table语句,执行成功或不成功都可审计。
SQL> audit table;
2)权限审计
按权限来审计,当用户使用了该权限则被审计,如执行grant select any table to a; 当用户a访问了用户b的表时(如select * from b.t;)
会用到select any table权限,故会被审计。用户访问自己的表不会被审计。
SQL> audit select any table;
3)对象审计
按对象审计,只审计on关键字指定对象的相关操作,如:aduit alter,delete,drop,insert on cmy.t by scott; 这里会对cmy用户的t表进行审
计,但同时使用了by子句,所以只会对scott用户发起的操作进行审计。
SQL> audit update on scott.emp;
15.4 基于值的审计。
它拓展了标准数据库审计,不仅捕捉审计事件,还捕捉那些被insert,update和delete的值。由于基于值的审计是通过触发器来实现。所以你可以选择哪些信息进入审计记录,比如,只记录提交的信息,或不记录已改变的数据等。
15.5 精细审计Fine Grained Auditing (FGA)。
15.5.1特点:
拓展了标准数据库审计,捕捉准确的SQL语句。审计访问特定行或特定列。操作可以使用dbms_fga包。精细审计一般不包括sys用户,目前EM中只有标准数据库审计,还没有包括基于值的审计和精细审计。
15.5.2示例:
sys:
SQL> create table scott.emp1 as select * from scott.emp;
SQL> grant all on scott.emp1 to tim;
1)添加一个精细度审计策略
SQL>begin
dbms_fga.add_policy(
object_schema=>'scott',
object_name=>'emp1',
policy_name=>'chk_emp1',
audit_condition =>'deptno=20',
audit_column =>'sal',
statement_types =>'update,select');
end;
/
- 测试
scott:
SQL> select * from emp1 where deptno=20;
tim:
SQL>update scott.emp1 set sal=8000 where empno=7902;
SQL>select empno,ename from scott.emp1 where deptno=20; 缺少sal列,不审计
sys:
SQL> select empno,ename,sal from scott.emp1 where deptno=20; 虽然符合条件,但默认不审计sys
3)验证审计结果
SQL> conn /as sysdba
SQL>select db_user,to_char(timestamp,'yyyy-mm-dd hh24:mi:ss') "time" ,sql_text
from dba_fga_audit_trail;
DB_USER time SQL_TEXT
------------------------------ ------------------- -------------------------------------------------------------------------
SCOTT 2013-08-17 16:57:36 select * from emp1 where deptno=20
TIM 2013-08-17 16:57:52 update scott.emp1 set sal=8000 where empno=7902
可以看出,必须同时满足了所有审计条件(前面定义的)才能入选。另外没有审计SYS.
SQL> truncate table fga_log$; 清除审计记录
4)删除FGA策略
SQL>exec dbms_fga.drop_policy(object_schema=>'scott',object_name=>'emp1',policy_name=>'chk_emp1');
第十六章:全球化特性与字符集
数据库的全球化特性是数据库发展的必然结果,位于不同地区、不同国家、不用语言而使用同一数据库越来越普遍。Oracle数据库提供了对全球化数据库的支持,消除不同文字、语言环境、历法货币等所带来的差异、使得更容易、更方便来使用数据库。
16.1 全球化特性内容
Language support
Territory support
Character set support
Linguistic sorting
Message support
Date and time formats
Numeric formats
Monetary formats
16.2 字符集概念
在Oracle全球化特性中最重要的则是字符集。主要是讨论两个问题:
一是字符如何存储 服务器端
二是字符如何显示 客户端
比如单个英文字符、单个阿拉伯数据字,#、$等,美国ANSI使用的标准字符集则使用了一个单字节(7位)来表示。由于世界各国和各个地区使用的符号的多样性,仅有2的7次方(128)个单字节的码点是不够用的,因此就有需要多字节来表示各自不同的字符。
正是由于上述原因产生了不同的字符集的概念, 如美国使用的为US7ASCII,西欧则使用的是WE8ISO8859P1,中国则是ZHS16GBK。
为了统一世界各国字符编码,统一编码字符集的概念应运而生,这就是Unicode。
在Oracle中,几种常用的Unicode为UTF-8,AL16UTF16,AL32UTF8
16.3字符集及分类
Oracle支持两百多种字符集,包含了单字节、可变字节以及通用字符集等。
字符集通常根据使用的字节数来分类,主要分为以下几类
①单字节字符集,如US7ASCII(7bit),WE8ISO8859P1(8bit),WE8DEC(8bit)
②可变长多字节字符集,如JEUC,CGB2312-80
③固定长多字节字符集,AL16UTF16
16.4 Unicode字符集
1)数据库字符集和国家字符集特性
Database Character Sets
主要是用作描述字符如何保存。
可存储列的类型为CHAR,VARCHAR2,CLOB,LONG
National Character Set
主要是用于辅助Database Character Set。因为早期的数据库中很多使用了单字节字符集,但随着业务的发展,需要使用到诸如nchar,nvarchar等Unicode字符或者需要扩展到世界各地存储不同的字符,因此辅助字符集应运而生。
可存储的类型为NCHAR,NVARCHAR2,NCLOB
2)Oracle支持的Unicode字符集

3) 字符集影响的数据类型
对于二进制数据类型,字符集的设置不影响该类型数据的存储,如视频、音频等
受影响的数据类型为:char,varchar2,nchar,nvarchar2,blob,clob,long,nclob
16.5 NLS参数设定
1)服务器端:查看服务器中设定的NLS参数
SQL>select * from nls_database_parameters;
PARAMETER VALUE
---------------------------- -----------------------------------
NLS_LANGUAGE AMERICAN
NLS_TERRITORY AMERICA
NLS_CURRENCY $
NLS_ISO_CURRENCY AMERICA
NLS_NUMERIC_CHARACTERS .,
NLS_CHARACTERSET ZHS16GBK
NLS_CALENDAR GREGORIAN
NLS_DATE_FORMAT DD-MON-RR
NLS_DATE_LANGUAGE AMERICAN
NLS_SORT BINARY
NLS_TIME_FORMAT HH.MI.SSXFF AM
NLS_TIMESTAMP_FORMAT DD-MON-RR HH.MI.SSXFF AM
NLS_TIME_TZ_FORMAT HH.MI.SSXFF AM TZR
NLS_TIMESTAMP_TZ_FORMAT DD-MON-RR HH.MI.SSXFF AM TZR
NLS_DUAL_CURRENCY $
NLS_COMP BINARY
NLS_LENGTH_SEMANTICS BYTE
NLS_NCHAR_CONV_EXCP FALSE
NLS_NCHAR_CHARACTERSET AL16UTF16
NLS_RDBMS_VERSION 11.1.0.6.0
已选择20行。
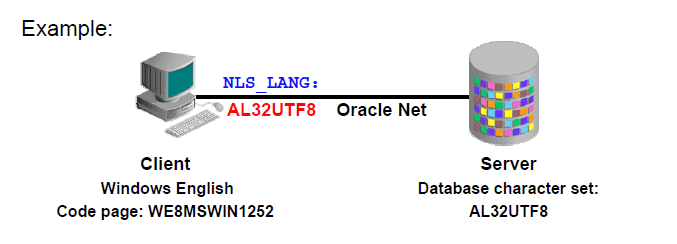
2)客户端:查看环境变量中的NLS_LANG变量
NLS_LANG变量为一个总控参数,控制了变量nls_language和nls_territory的行为,只要设定了该参数,则其它参数就相应确定了。
该参数的格式为:
NLS_LANG = language_territory.charset
在我们的虚机环境下,环境变量文件/home/oracle/.bash_profile中描述了作为客户端的NLS_LANG
NLS_LANG="simplified chinese"_china.ZHS16GBK,该参数分为几个部分来设定
第一部分为language,为simplified chinese。
第二部分为territory,为china。一二两部分必须用下划线连接。
第三部分为character set,为zhs16gbk 二三两部分必须用小数点连接。
其含义是语言是简体中文,区域是中国,数据库字符集是ZHS16GBK。
另外日期格式缺省的是DD-MON-RR,我们单独定义了适合中国人使用的格式'YYYY-MM-DD HH24:MI:SS'
注意:当设置客户端的NLS_LANG字符集时必须考虑客户端的操作系统字符集
如果它们不一致,可能会造成无效的数据进入SERVRE数据库。见下图。
3)几个重要的参数:
①语言参数,nls_language:
受影响的参数有:
NLS_DATE_LANGUAGE
NLS_SORT
②区域参数,nls_territory:
受影响的参数有:
NLS_CURRENCY
NLS_DUAL_CURRENCY
NLS_ISO_CURRENCY
NLS_NUMERIC_CHARACTERS
NLS_DATE_FORMAT
NLS_TIMESTAMP_FORMAT
NLS_TIMESTAMP_TZ_FORMAT
③排序参数: nls_sort:
Order by指定字段的排序方法,缺省的是Binary, 一般是支持单字节字符集 而多字节的字符集排序则引入Linguistic Sorting
基于Binary排序,根据encode的二进制代码排序。
基于语言排序,又分单一语言和多重语言
第四部分 数据仓库管理
数据仓库以OLAP类型操作为主,这有别于OLTP类型的操作。
OLTP体现的时实时的事务处理,OLAP可以看成是OLTP的历史数据“仓库”
操作上主要体现为:
1)select查询汇总为主,对事务性要求较少
2)对数据快速复制、移动的需求
3)分布式查询的需求。
数据仓库的概念并不抽象,而且可操作性强,所以第四部分我们将以实操为主。
第十七章:数据移动
17.1 概念
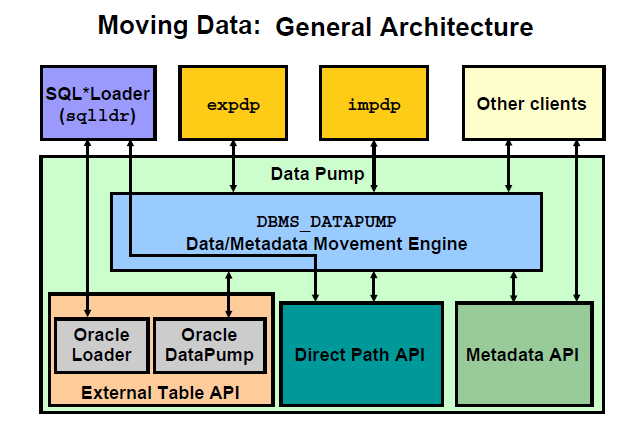
1)数据移动源于数据仓库,它是逻辑对象层面的数据复制, 数据移动有两种引擎:
①ORACLE_LOADER(Sqlload引擎)
②ORACLE_DATAPUMP(数据泵引擎)
两个引擎的区别是:ORACLE_DATAPUMP只能读取由它导出的文件,而ORACLE_LOADER可以读取任何它能解析的第三方文件格式。
2)数据移动主要包含两个方面内容
⑴创建外部表的方法,两种引擎都可以生成外部表数据。但用途和方法是不同的。
①Sqlload引擎生成的外部表是文本格式的,支持跨平台的不同数据库间的数据移动。
②Data pump引擎生成的外部表是二进制格式的。适用于Oracle 平台的数据库之间快速数据移动。
⑵数据泵技术(expdp/impdp)
作为替代传统逻辑备份的导入导出,实现数据在逻辑层面的快速复制与恢复
17.2 Directory(目录)
①创建外部表必须使用Directory指定外部表的目的地,目录是数据库对象,相当于把物理目录映射成一个逻辑目录名
②引入directory的好处是简化了在不同OS中对于物理目录路径的格式描述
③通过Sqlload和Data pump两种方法创建外部表时都必须使用指定的directory
17.3 sql*loader
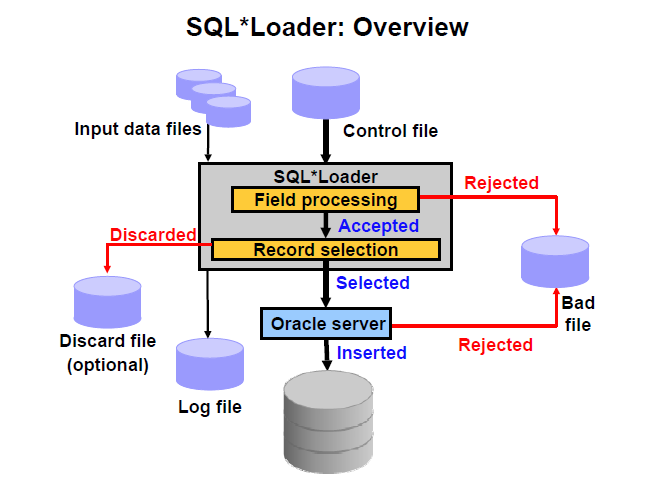
17.3.1 sql*loader 原理:
- 将外部数据(比如文本型)导入oracle database。(可用于不同类型数据库数据迁移)
本质是在段(segment 表)重新insert 记录
①conventional:将记录插入到segment的HWM(高水位线)以下的块,要首先访问bitmap ,来确定那些block 有free space
②direct path:将记录插入到segment的HWM(高水位线)以上的从未使用过的块,绕过db_buffer, 不检查约束。还可以关闭redo, 也支持并行操作,加快插入速度。
传统插入数据和直接插入数据:
SQL> create table emp1 as select * from emp where 1=2;
SQL> insert into emp1 select * from emp; conventional 传统方式数据
SQL> insert /*+ APPEND */ into emp1 select * from emp; 直接方式数据,必须commit后才能查看数据
17.3.3 sql*loader 用法:
SQLLDR keyword=value [,keyword=value,...]
可以看帮助信息$/u01/oracle/bin/sqlldr(回车)
17.4 外部表示例
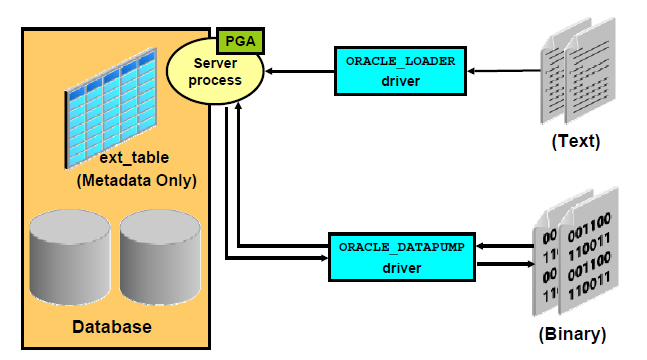
17.4.1 使用ORACLE_LOADER引擎建立外部表
步骤1,模拟生成数据源
SQL>select empno||','||ename||','||sal||','||deptno from scott.emp;
步骤2,建立目录,生成平面表(数据源)
$mkdir -p /home/oracle/dir1
$vi /home/oracle/dir1/emp1.dat 粘贴步骤1的查询结果
步骤3,建立directory
名称为dir1指向物理目录/home/oracle/dir1,
SQL>create directory dir1 as '/home/oracle/dir1';
将dir1的对象权限授予scott和tim用户。
SQL>grant read,write on directory dir1 to scott,tim;
步骤4,使用ORACLE_LOADER引擎创建外部表emp1_ext
scott:
CREATE TABLE emp1_ext
(EMPNO NUMBER(4),
ENAME VARCHAR2(10),
SAL NUMBER(7,2),
DEPTNO NUMBER(2))
ORGANIZATION EXTERNAL
(TYPE ORACLE_LOADER
DEFAULT DIRECTORY dir1
ACCESS PARAMETERS (FIELDS TERMINATED BY ",")
LOCATION ('emp1.dat')
) REJECT LIMIT UNLIMITED;
步骤5,验证外部表
SQL> select * from emp1_ext;
17.4.2 使用ORACLE_DATAPUMP引擎导出导入外部表
步骤1,为scott用户建立外部表emp2_ext
数据源是emp.dmp文件,逻辑目录是dir1。
SQL> CREATE TABLE emp2_ext
ORGANIZATION EXTERNAL
( TYPE ORACLE_DATAPUMP
DEFAULT DIRECTORY dir1
LOCATION ('emp.dmp'))
AS SELECT empno,ename,sal,deptno FROM scott.emp ;
步骤2,验证scott的外部表emp2_ext
SQL> select * from scott.emp2_ext
步骤3,为tim用户建立外部表emp3_ext, 同样读取数据源emp.dmp
tim:
SQL> CREATE TABLE emp3_ext
(EMPNO NUMBER(4),
ENAME VARCHAR2(10),
SAL NUMBER(7,2),
DEPTNO NUMBER(2))
ORGANIZATION EXTERNAL
(
TYPE ORACLE_DATAPUMP
DEFAULT DIRECTORY dir1
LOCATION ('emp.dmp')
) ;
步骤4,验证tim的外部表emp3_ext
SQL>select * from tim.emp3_ext
17.4.3 使用sqlldr将emp1.dat导入到scott下的emp1
步骤1,建立控制文件
$ vi /home/oracle/dir1/emp1.ctl
load data
infile '/home/oracle/dir1/emp1.dat'
insert --insert 插入表必须是空表,非空表用append
into table emp1
fields terminated by ','
optionally enclosed by '"'
(empno,ename,sal,deptno)
步骤2,在scott下建立emp1表(内部表),只要结构不要数据
SQL> create table scott.emp1 as select empno,ename,sal,deptno from scott.emp where 1=2;
步骤3,ORACLE_LOADER引擎导入(normal方式)
$ cd /home/oracle/dir1
$ sqlldr scott/scott control=emp1.ctl log=emp1.log
步骤4,验证结果
SQL> select * from scott.emp1;
上例的另一种形式是将数据源和控制文件合并在.ctl里描述
[oracle@work sqlldr]$ vi emp.ctl
load data
infile *
append
into table emp1
fields terminated by ','
optionally enclosed by '"'
(empno,ename,sal,deptno)
begindata
7369,SMITH,800,20
7499,ALLEN,1600,30
7521,WARD,1250,30
[oracle@prod sqlload]$ sqlldr scott/scott control=emp.ctl log=emp.log
第十八章:逻辑备份(导出)与恢复(导入)
18.1 传统的导入导出exp/imp:
18.1.1概述
传统的导出导入程序指的是exp/imp,用于实施数据库的逻辑备份和恢复。
导出程序exp将数据库中对象的定义和数据备份到一个操作系统二进制文件中。
导入程序imp读取二进制导出文件并将对象定义和数据载入数据库中
18.1.2 特点
传统的导出导入是基于客户端设计的。在$ORACLE_HOME/bin下
导出和导入实用程序的特点有:
1)可以按时间保存表结构和数据
2)允许导出指定的表,并重新导入到新的数据库中
3)可以把数据库迁移到另外一台异构服务器上
4)在两个不同版本的Oracle数据库之间传输数据(客户端版本不能高于服务器版本)
5)在联机状态下进行备份和恢复
6)可以重新组织表的存储结构,减少行链接及磁盘碎片
18.1.3 交互方式
使用以下三种方法调用导出和导入实用程序:
1,交互提示符:以交互的方式提示用户逐个输入参数的值。
2,命令行参数:在命令行指定执行程序的参数和参数值。
3,参数文件:允许用户将运行参数和参数值存储在参数文件中,以便重复使用参数
18.1.4 导入导出模式
导出和导入数据库对象的四种模式是:
1,数据库模式:导出和导入整个数据库中的所有对象
2,表空间模式:导出和导入一个或多个指定的表空间中的所有对象
3,用户模式:导出和导入一个用户模式中的所有对象
4,表模式:导出和导入一个或多个指定的表或表分区
18.2 导入导出示例
18.2.1导入导出表
1)scott导入导出自己的表,一般是从服务器导出到客户端(在cmd下操作)
SQL>create table emp1 as select * from emp;
SQL>create table dept1 as select * from dept;
C:\>exp scott/scott@prod file=d:empdept1.dmp tables=(emp1,dept1)
再导入server里
SQL> drop table emp1 purge;
SQL> drop table dept1 purge;
C:\>imp scott/scott@prod file=d:empdept1.dmp
2)sys导出scott表,
SYS用户可以exp/imp其他用户的object,是因为SYS含有EXP_FULL_DATABASE和IMP_FULL_DATABASE角色。
C:\>exp 'sys/system@prod as sysdba' file=d:sysscott.dmp tables=(scott.emp1,scott.dept1)
scott导入(报错)
C:\>imp scott/scott@ file=d:sysscott.dmp
报错:IMP-00013: 只有 DBA 才能导入由其他 DBA 导出的文件
IMP-00000: 未成功终止导入
C:\>imp 'sys/system@ as sysdba' file=d:sysscott.dmp fromuser=scott
18.2.2导入导出用户
当前用户scott导出自己的所有对象, 注意仅仅导出的是schema的object,也就是说这个导出不包括数据字典中的信息,比如用户账户,及原有的一些系统权限等等。
C:\>exp scott/scott@prod file=d:scott.dmp owner=scott 所有segment name的表才能导出,注意deferred_segment_creation问题
SQL> drop user scott cascade;
SQL> grant connect,resource to scott identified by scott;
C:\>imp scott/scott@prod file=d:scott.dmp
如果用sys来完成也可以使用如下命令:
C:\>imp 'sys/system@ as sysdba' file=d:scott.dmp fromuser=scott touser=scott
sys用户也可以将导出的scott的内容导入给其他用户
C:\>imp 'sys/system@ as sysdba' file=d:scott.dmp fromuser=scott touser=tim
18.2.3导入导出表空间
Oracle10g后,引入了导入导出可传输表空间技术,使表空间的迁移更加快速高效
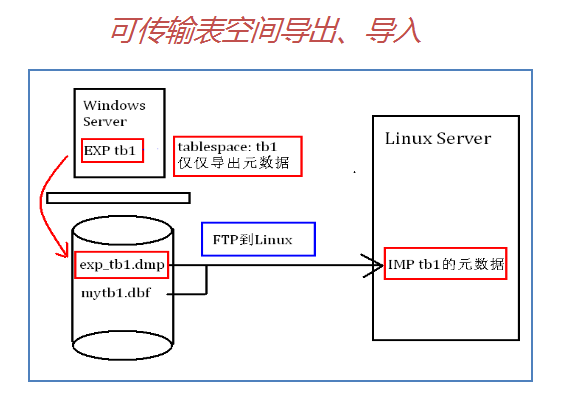
模拟场景:xp/orcl到linux/(中文字符集)可传输表空间的导入导出:
1)在xp/orcl上建立表空间
sys:
SQL>create tablespace tb1 datafile 'd:/mytb1.dbf' size 5m;
scott:
create table t1(year number(4),month number(2),amount number(2,1)) tablespace tb1;
insert into t1 values(1991,1,1.1);
insert into t1 values(1991,2,1.2);
insert into t1 values(1991,3,1.3);
insert into t1 values(1991,4,1.4);
commit;
2)导出tb1表空间,先设为只读;
sys:
SQL>alter tablespace tb1 read only;
xp:cmd下
C:\>exp \'sys/ as sysdba\' file=/home/../exp_tb1.dmp tablespaces=tb1 transport_tablespace=y
scp /home/../.dmp 192.168.3.99:/home/oracle/backup
scp /home/../abc.dbf 192.168.3.99:/home/oracle/backup
3)以xmanager把exp_tb1.dmp和MYTB1.DBF都上传到linux/prod里
目录如下:/u01/oradata/prod
4)在linux的$下执行导入
[oracle@prod ~]$ imp \'sys/oracle as sysdba\' file=/home/oracle/backup/exp_tb1.dmp datafiles=/home/oracle/backup/MYTB1.DBF tablespaces=tb1 transport_tablespace=y
5)进入linux/prod下验证
sys:
SQL>select tablespace_name,status from dba_tablespaces;
SQL>select * from scott.t1;
6)重设回读写方式
SQL>alter tablespace tb1 read write;
说明:可传输表空间需要满足几个前提条件:
①原库和目标库字符集要一致。
②字符序有大端(big endian)和小端(little endian)之分,通过v$transportable_platform查看,如果不一致可以使用rman转换。
③compatible 10.0.0.或更高。
④迁移的表空间要自包含 (self contained)。
什么叫自包含:
当前表空间中的对象不依赖该表空间之外的对象。
例如:有TEST表空间,里面有个表叫T1,如果在T1上建个索引叫T1_idx,而这个索引建在USERS表空间上,由于T1_idx索引是依赖T1表的,
那么,TEST表空间是自包含的,可以迁移,但会甩掉T1_idx索引,USERS表空间不是自包含的,不符合迁移条件。
检查表空间是否自包含可以使用程序包
create index test_index on scott.t1(id) tablespace users;
如上面的例子
SQL> execute dbms_tts.transport_set_check('USERS');
SQL> select * from TRANSPORT_SET_VIOLATIONS;
VIOLATIONS
------------------------------------------------------------------------------------------------------------------------
ORA-39907: 索引 SCOTT.EMP1_IDX (在表空间 TEST 中) 指向表 SCOTT.EMP1 (在表空间 USERS 中)。
解决:删除一个索引: drop index 索引名
把索引迁移到另一个表空间: alter index 索引名 rebulild tablespace 其他表空间
18.2.4导出整个数据库
C:\>exp 'sys/system@prod as sysdba' file=d:full.dmp full=y
18.3 数据泵技术
18.3.1 数据泵优点:
1)改进性能(较传统的exp/imp速度提高1-2个数量级)
2)重启作业能力
3)并行执行能力
4)关联运行作业能力
5)估算空间需求能力
6)操作网络方式
18.3.2 数据泵组成部分:
①数据泵核心部分程序包:DBMS_DATAPUMP
②提供元数据的程序包:DBMS_MATADATA
③命令行客户机(实用程序):EXPDP,IMPDP
18.3.3 数据泵文件:
①转储文件:此文件包含对象数据
②日志文件:记录操作信息和结果
③SQL文件: 将导入作业中的DDL语句写入SQLFILE指定的参数文件中
18.3.4 数据泵的目录及文件位置
以sys或system用户完成数据泵的导入导出时,可以使用缺省的目录 DATA_PUMP_DIR
SQL> select * from dba_directories;
如果设置了环境变量ORACLE_BASE,则DATA_PUMP_DIR缺省目录位置是:
$ORACLE_BASE/admin/database_name/dpdump
否则是:
$ORACLE_HOME/admin/database_name/dpdump
18.4 数据泵示例
18.4.1建立directory
①server端先建好一个存放MT表的物理目录
[oracle@prod ~]$mkdir -p /u01/oradata/prod/dir1
②server端用SYS建立目录对象:
SQL> create directory MY_DIR as '/u01/oradata/prod/dir1';
③为scott授予目录权限
SQL> grant read,write on directory MY_DIR to scott;
18.4.2数据泵导表
1)导出scott的emp dept表, 导出过程中在server端有MT表出现SYS_EXPORT_TABLE_01,导出完成后MT表自动消失
$expdp scott/scott directory=MY_DIR dumpfile=expdp_scott1.dmp tables=emp,dept
看看目录下的导出的文件
导入scott的表(导出的逆操作)
$impdp scott/scott directory=MY_DIR dumpfile=expdp_scott1.dmp
2)导出scott的emp1的数据,但不导出结构
$expdp scott/scott directory=MY_DIR dumpfile=expdp_scott1.dmp tables=emp1 content=data_only reuse_dumpfiles=y
导入Scott的表(导入的逆操作),只导入数据
SQL> truncate table emp1;
$impdp scott/scott directory=MY_DIR dumpfile=expdp_scott1.dmp content=data_only
18.4.3数据泵导用户
$ expdp system/oracle directory=MY_DIR dumpfile=scott.dmp schemas=scott
注意与exp的区别,schemas代替了owner的写法
然后将对象导入tim
$ impdp system/oracle directory=MY_DIR dumpfile=scott.dmp remap_schema=scott:tim
18.4.4数据泵可传输表空间
Win端需要directory 前面已经建立了dir1
C:\>expdp '/ as sysdba' directory=dir1 dumpfile=tb1.dmp transport_tablespaces=tb1
Linux端需要directory 前面已经建立了dir1
$impdp userid=\'/ as sysdba\' DIRECTORY=mydir DUMPFILE='TB1.DMP' TRANSPORT_DATAFILES='/u01/oradata/prod/MYTB1.DBF'
