




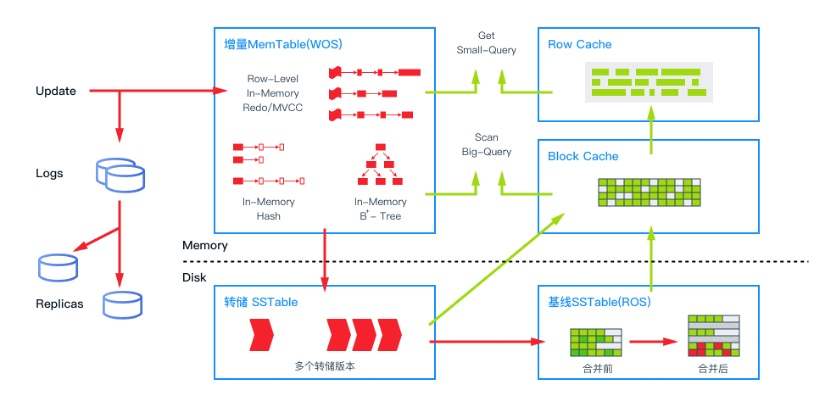
OceanBase 数据库的存储引擎基于 LSM Tree 架构, 将数据分为静态基线数据( 放在 SSTable 中) 和动态增量数据( 放在 MemTable 中) 两部分, 其中 SSTable 是只读的, 一旦生成就不再被修改, 存储于磁盘;MemTable 支持读写, 存储于内存。
数据库 DML 操作插入、更新、删除等首先写入 MemTable, 等到 MemTable达到一定大小时转储到磁盘成为 SSTable。
在进行查询时, 需要分别对 SSTable 和 MemTable 进行查询, 并将查询结果进行归并, 返回给 SQL 层归并后的查询结果。
同时在内存实现了 Block Cache 和 Row cache, 来避免对基线数据的随机读。
当内存的增量数据达到一定规模的时候, 会触发增量数据和基线数据的合并, 把增量数据落盘。 同时每天晚上的空闲时刻, 系统也会自动每日合并。
OceanBase 本质上是一个基线加增量的存储引擎, 跟关系数据库差别很大, 同时也借鉴了部分传统关系数据库存储引擎的优点。
传统数据库把数据分成很多页面, OceanBase 数据库也借鉴了传统数据库的思想, 把数据分成很多 2MB 为单位的宏块。 合并时采用增量合并的方式, OceanBase 数据库的合并代价相比 LevelDB 和 RocksDB 都会低很多。
另外, OceanBase 数据库通过轮转合并的机制把正常服务和合并时间错开, 使得合并操作对正常用户请求完全没有干扰。
由于 OceanBase 数据库采用基线加增量的设计, 一部分数据在基线, 一部分在增量, 原理上每次查询都是既要读基线, 也要读增量。 为此, OceanBase 数据库做了很多的优化, 尤其是针对单行的优化。 OceanBase 数据库内部除了对数据块进行缓存之外, 也会对行进行缓存, 行缓存会极大加速对单行的查询性能。 对于不存在行的“空查”, 我们会构建布隆过滤器, 并对布隆过滤器进行缓存。 OLTP 业务大部分操作为小查询, 通过小查询优化, OceanBase 数据库避免了传统数据库解析整个数据块的开销, 达到了接近内存数据库的性能。 另外, 由于基线是只读数据, 而且内部采用连续存储的方式, OceanBase 数据库可以采用比较激进的压缩算法, 既能做到高压缩比, 又不影响查询性能, 大大降低了成本。
