从大型数据库出现开始,为了从低速度的存储设备中高效的获得数据,就采用了DB CACHE的机制。DB CACHE可以缓冲数据文件中的数据,使之多次被使用。其基本原理就是一个数据块被一次读入内存后,所有的读写操作都在内存中进行而不需要再去操作磁盘了。内存的IO延时是磁盘的数百倍,所以这种数据文件的缓冲机制大大提高了数据库访问数据的效率。不过这种数据缓冲机制存在两个问题。第一个问题就是这些内存中的数据什么时候被回写到磁盘上,因为内存是易失性的,无法长期保留数据,因此所有在内存中缓冲的数据早晚都要回写到磁盘上才能长期保存。数据一旦被修改,就马上回写可能是最安全的,但是有可能刚刚被写回磁盘的数据马上又会被修改了,那么两次修改后,甚至十次修改后的数据再一次性写入磁盘,是不是更划算呢?如果等多个连续的数据块都写完一起存盘,把原本的离散写变成顺序写,不是效率更高吗?因此数据库总是希望延后脏数据被写入的时间。第二个问题是,我们的所有修改操作都是在内存中完成的,那么一旦数据库实例故障或者掉电了,怎么保证数据不丢失呢?确保交易数据不丢失的方法就是WRITE AHEAD LOG(WAL)机制,大型数据库,包括Oracle等著名的数据库都是采用WAL机制来确保系统故障的时候不丢失数据的。WAL机制的原理十分简单,把数据库的每一个变更操作都记录在一个WAL 日志里,这个日志在ORACLE和MYSQL INNODB引擎里叫REDO LOG,在DB2里叫事务日志,在PostgreSQL里叫WAL。当一个事务提交的时候,只要WAL日志完成写盘了,那么即使缓冲区里的脏数据丢失了,我们也可以根据WAL里的内容恢复丢失的事务。而WAL日志的写入是顺序写,这样就把昂贵的大量的离散写变成了相对成本较低的顺序写,从而大大提高了数据库写入的性能。基于数据库的WAL的原理,实际上一个数据库实例突然宕机或者突然被杀掉,以及Oracle数据库上我们执行一次shutdown abort操作,对于数据库的数据完整性来说,都是无害的,只要数据库实例重新启动,就能恢复在CACHE里还没来得及写盘的数据了。这个工作,在Oracle里叫redo recovery,在每次数据库启动的时候都会做一次。另外的问题来了,既然是有了WAL,那么无论多少脏数据没有及时写盘都不怕了,而且脏数据到底啥时候写盘比较好呢?怎么让数据库知道当前哪些数据已经确保写回盘上,哪些数据在下次REDO RECOVERY时需要恢复呢?回答前一个问题比较麻烦,因为如果我们写盘十分频繁,就会导致产生大量的不时完全必要的写IO,而如果写盘频率过低,会导致内存中存在太多的脏数据,数据库实例故障后重启的时候需要恢复更多的事务,这样重启的延时会太高,因此二者之间必须有一个平衡。每个数据库都有一套算法来实现这种较为平衡的脏块回写,既保证脏数据尽快写盘,又保证不导致存储性能无法支撑。由于数据库是十分复杂的,因此这个算法也十分复杂。要考虑写入IO的负载问题,以及变更操作的先后顺序,某些TRUNCATE,DROP表的操作,以及数据文件备份或者ONLINE/OFFLINE等复杂的情况。解决第二个问题的方法就是我们常说的CHECKPOINT(检查点),数据库检查点的含义是,某个检查点之前的所有脏数据都已经写盘了,检查点之后的脏数据可能已经写盘,也可能还没写盘。在这里大家可能注意到老白没有用脏块而是用脏数据,因此几乎所有的使用WAL机制的大型数据库都是采用的事务日志的方式,而回写数据是以数据块为单位的,再加上写操作往往会组织成批处理,在组织写批处理的时候会考虑顺序写的问题来进行优化。早期的数据库中,CHECKPOINT工作都是由数据库后台写进程来完成的,因为写进程随时掌握赃块回写的情况。随着数据库规模与负载的增加,在很多数据库里CHECKPOINT工作被独立出来了,比如Oracle里的CKPT进程就是这样的进程。不过不同数据库的CHECKPOINT进程的工作内容还是会有些不同。ORACLE的CKPT进程是完全不管脏数据的写入的,只负责和CHECKPOINT相关的工作,而有些数据库的CHECKPOINT进程可能还要负责一些脏数据写入的工作。CHECKPOINT是标识数据库写操作进度的,它的一个十分重要的作用就是标识哪些WAL是无关紧要的,哪些WAL还必须保留。记得十多年前经常遇到的一个DB2的故障是用户不小心删除了DB2的某些日志(当时的DBA以为只有当前的主日志才是不能删的,而切换过的日志都是可以删除的,于是在磁盘空间不足的情况下删除了一些日志,最后导致数据库故障后无法恢复)。数据库会将还存在CHECKPOINT之后的事务日志的日志文件为ACTIVE的,而那些不包含任何CHECKPOINT之后事务日志的日志文件为INACTIVE的。那些ACTIVE的日志文件,是无论如何都不能轻易删除的,因为这些日志中包含了数据库实例恢复中十分重要的信息。上星期老白做了一些实验来研究PostgreSQL数据库WAL优化的问题。在做benchmark压测的时候,WALWriteLock成为排名第一的等待事件。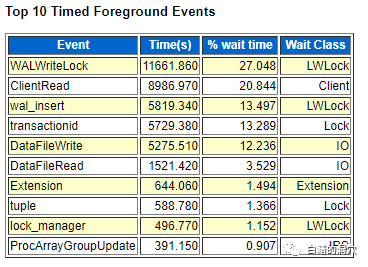
如何进一步提高PG数据库的Bechmark指标,可以考虑从优化WAL性能入手。除了降低WAL的产生量外,我们尝试了加大WAL BUFFER,使用WAL压缩,调整CHECKPOINT TIMEOUT参数等,效果均不明显。最后通过调整max_wal_size获得了5%以上的TPMC的提升。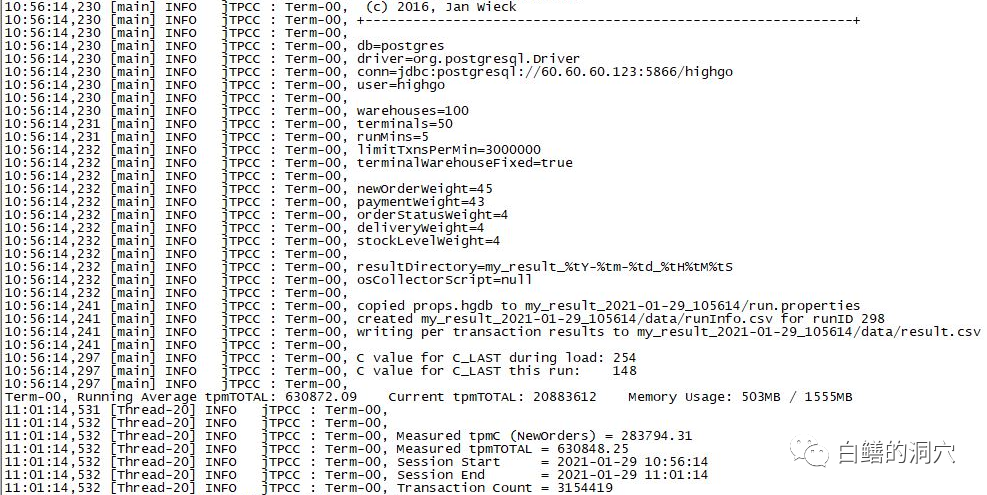
max_wal_size为5G的时候,TPMC为28.3万
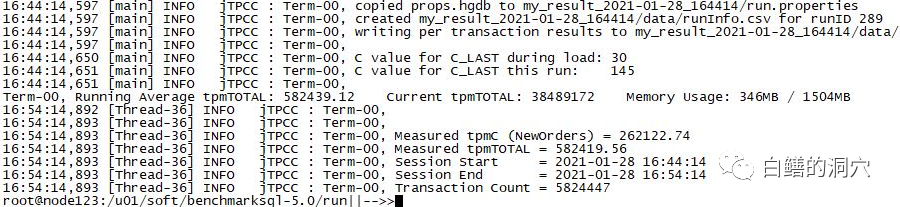
max_wal_size为1G的时候,TPMC为26.2万
实际上这个调整max_wal_size的方法调整的就是CHECKPOINT与WAL之间的平衡,让WAL回绕的时候确保所需覆盖的WAL文件已经是INACTIVE状态了。实际上这个原理和优化Oracle的REDO有些类似,只是Oracle的REDO LOG机制更为复杂,因此调整方式也更为复杂。和PG类似,当ORACLE的LOG BUFFER不是特别小的时候,再加大LOG BUFFER的效果不明显,而加大REDO LOG文件的大小,增加REDO LOG组的数量,也会有效的提升高并发写入时的数据库性能。我们在做Oracle数据库压测的时候,会发现一个现象,就是所有的REDO LOG都是ACTIVE的。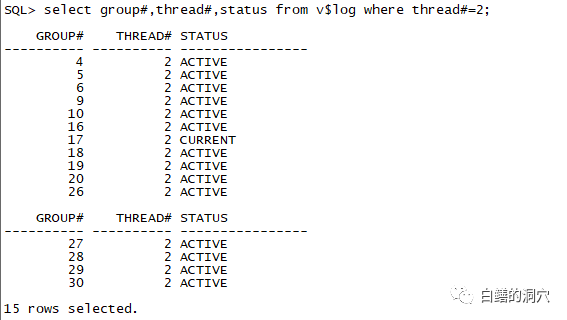
从上面的图可以看出,在这个正在做压测的实例上,除了当前的之外,几乎所有的REDO LOG组都是ACTIVE的。如果我们使用的是十多年前的硬件,出现这种情况意味着数据库性能已经出现了问题。因此如果看到这种情况,我们就必须加大REDO LOG文件的大小或者增加日志组的数量了。而实际上的情况更为复杂,如果你的硬件足够好,IO足够强,那么这种情况并不一定有太大的危害。如果你不经常看到大量会话等待Log file switch complete等待事件的时候,这种状态的风险并不大。比如下面:
当然如果出现大量Log file switch complete等待事件的时候,就说明你需要去优化REDO LOG了。这个原理是和调整PG的MAX WAL SIZE类似的。





