




导读
企业简介
映客,中国领先的互动社交平台,港交所直播第一股。旗下核心产品“映客APP”是中国移动直播行业的开拓者,多款语音社交产品在各自细分领域迅猛发展,覆盖在线相亲、语音交友、直播电商等领域。映客于2018年7月正式登陆港交所主板,主要产品MAU(每月活跃用户)4280万人。目前,集团总部位于北京,员工近1700人,其中50%为研发人员。

映客直播监控平台遇到痛点
映客之前使用的是 open-falcon,业务监控是内部自研基础框架上报的,随着各业务线的发展,监控项越来越多,open-falcon 的问题也越来越突出,主要包括以下几个方面:
机器资源消耗严重
open-falcon存储模块对 disk.io 要求很高,目前使用了 ssd 硬盘,disk.io.util 仍能达到 70%,且一致性哈希写流量不均,造成个别机器 disk.io 很高,数据堆积在内存中导致内存不足。每次有新项目上线,监控数据就会增多,如果内存不足就需要扩容。
新增需求无法满足
看图需求
查看历史原始数据,open-falcon存储会对历史数据归档,只能查看近几个小时的原始数据;
查询指标更灵活,open-falcon看图展示维度有限,不支持多指标计算;
查看图表大盘更流畅,open-falcon 的监控大盘打开慢,如果某个项目机器和series很多,经常会遇到打不开 screen 的情况,只能拆分 graph 到多个 screen 或者减少 counter 数量;
告警需求
更丰富的告警函数,open-falcon 告警函数少,无法配置多指标组合告警、不支持同环比告警; 更灵活的监控规则配置,open-falcon告警规则无法模糊匹配,只能通过tag筛选; 更灵活的监控屏蔽配置,open-falcon 无法根据tag对告警进行屏蔽,屏蔽只能按照机器粒度;
采集需求
监控采集更容易,open-falcon 不方便对接第三方系统,如 kafka、k8s 等指标采集只能自己开发对接;
调研选型
机器资源消耗 采集生态完善度 业务需求匹配度
落地方案
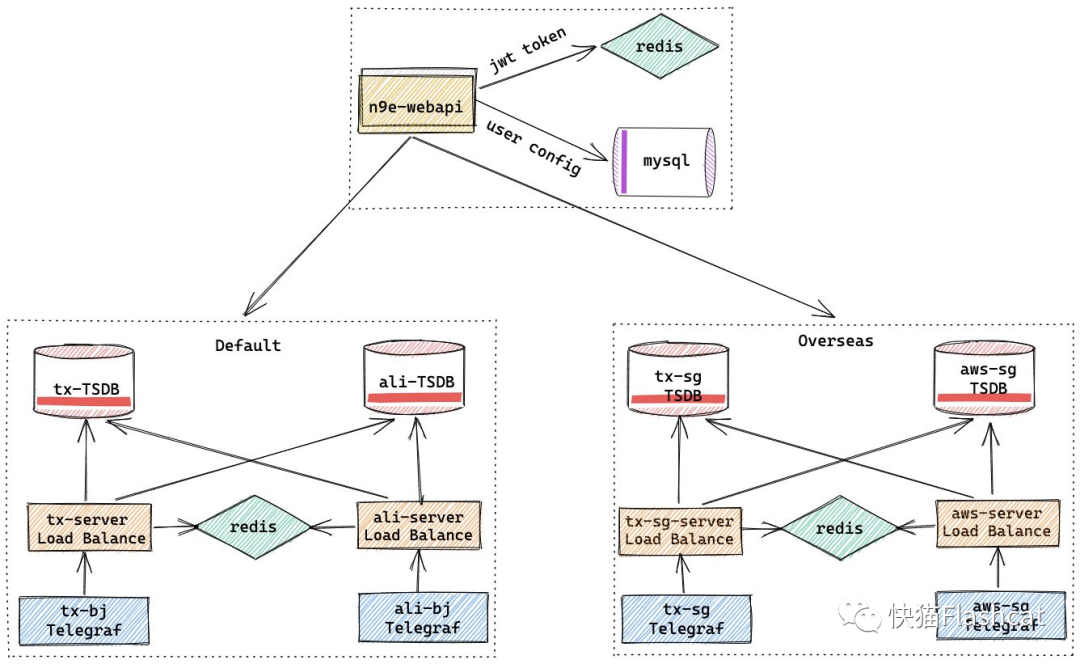
服务组件
n9e-webapi:夜莺的配置管理模块,对告警规则、屏蔽规则、订阅规则、自愈脚本、权限等相关配置进行管理; n9e-server: 图表中的 ts-server、ali-server、tx-sg-server、aws-server,夜莺的告警引擎,根据用户配置的 PromQL,查询时序库,判断是否应该触发告警并发送; thanos: 图中的 ali-TSDB,用的 receive 模式,保存3个月原始数据,历史数据会采样之后上传到 oss,压力主要在 receive 服务; victoriametrics:图中的 tx-TSDB,vm性能很好,5台8c64G2T机器部署storage cpu使用30%左右,内存使用60%,硬盘使用1.3T左右,3台8c*16G机器部署insert,select服务,目前没啥压力; prometheus:海外机房时序存储,如果监控项不多,用Prometheus挺好的,注意动态加载配置reload,重启会很慢;
采集实践
机器指标:采用 telegraf 采集,加壳部署为 n9e-agent 方便后期统一部署管理,每个机器都往各自机房 server 写数据; 业务指标:由 sdk 直接上报,通过 falcon 的 /v1/push 接口转发至夜莺监控; 中间件指标:通过各自机房部署的 prometheus 进行 exporter 抓取; k8s容器指标:通过已有的 k8s prometheus 进行抓取,远程写入到 n9e-server;
现状和收益
1
当前监控平台现状

2
使用夜莺监控后的收益
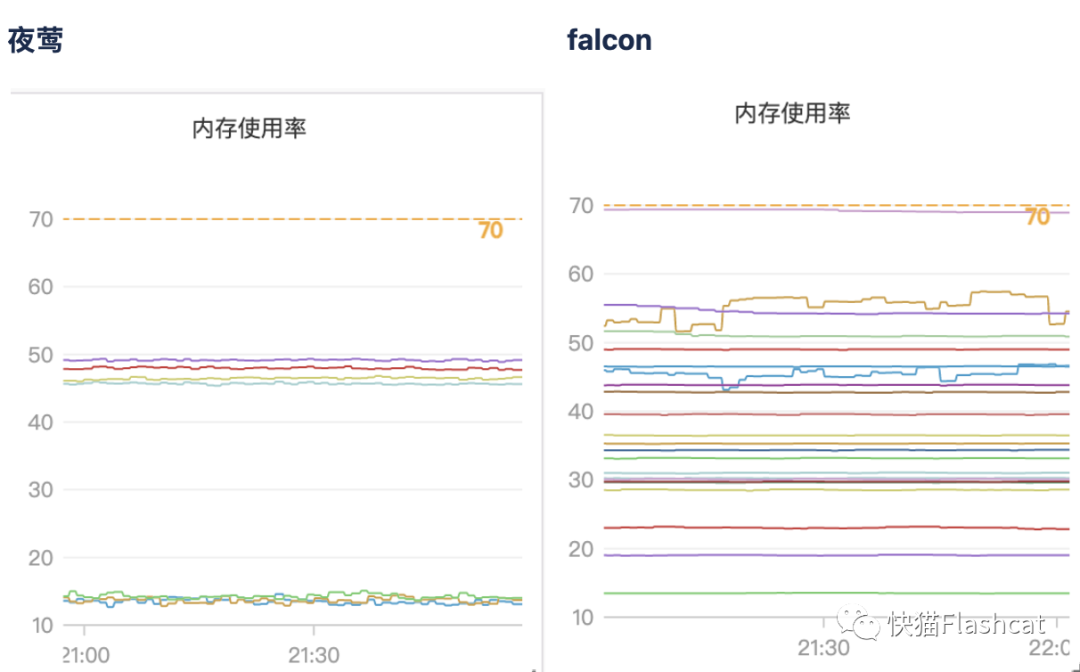
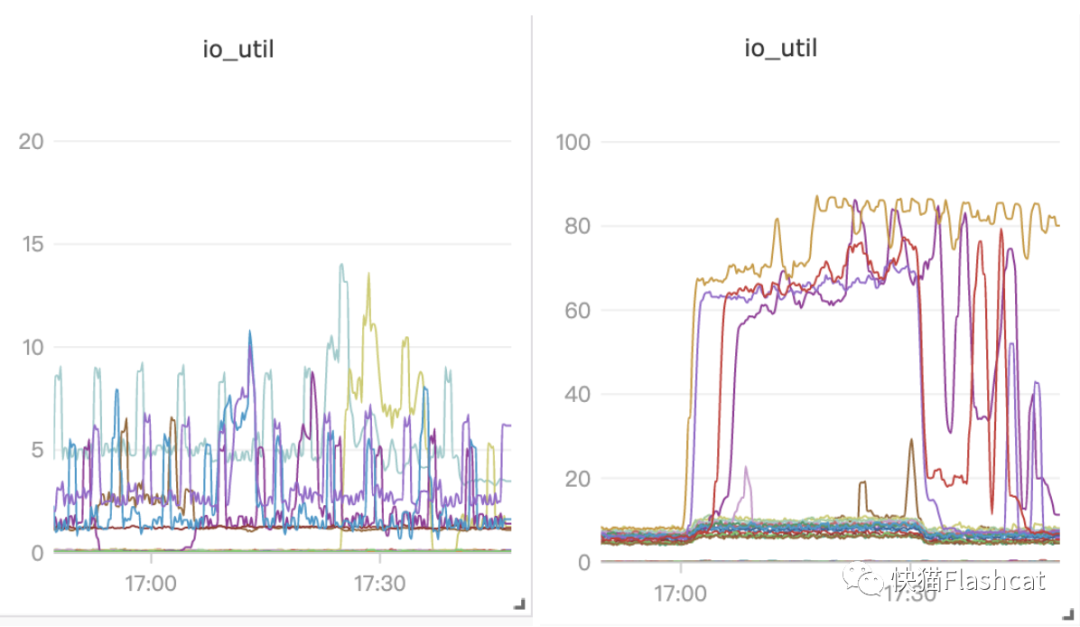
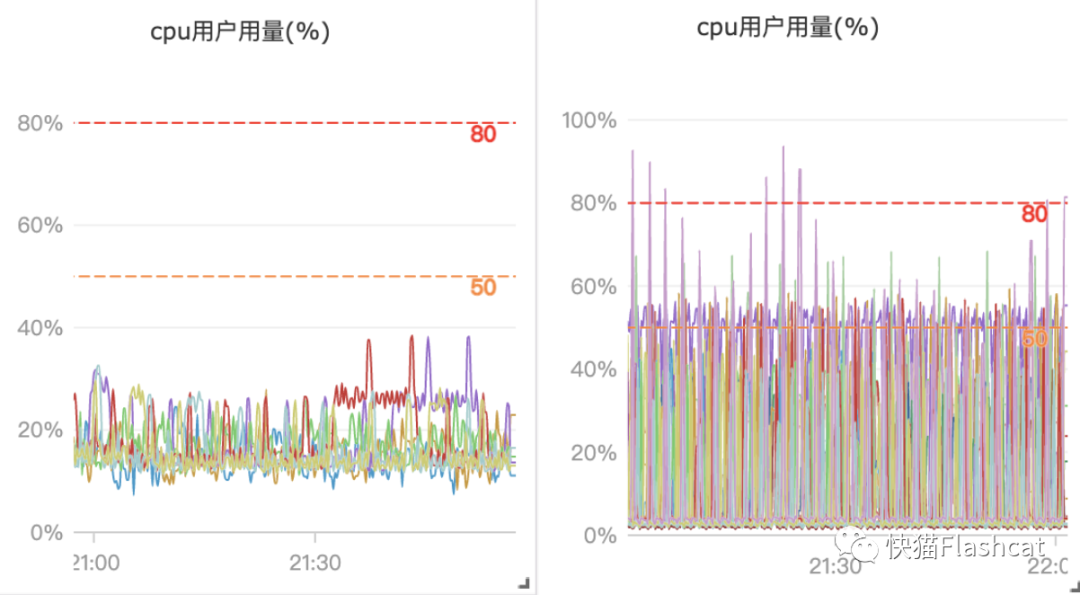
节约了大量机器成本,夜莺监控比 open-falcon 节约86%的成本,整个平台机器量由原来的80台降低为20+台; 采集成本降低,比如采集 kafka、zk、consul 等中间件,不再需要开发工具去抓取,直接用 prometheus 采集远程写入到 n9e-server; 更灵活的告警和看图功能,满足目前业务需求; 监控性能提升:
夜莺的victoriametrics使用普通云盘,配置为8c*64G
falcon的graph使用ESSD云盘,配置为16C*128G
落地适配经验分享
采集管理
对telegraf采集做了优化,对不同inputs采集间隔进行了调整,如cpu,disk.io是15s采集,disk是60s; telegraf启用inputs.exec功能,默认会去执行/plugin/*.sh脚本,方便自定义用户采集脚本; telegraf增加日志关键字监控,简单的日志监控使用自定义脚本,复杂的使用mtail监控;
自动按业务线添加基础监控,所有监控项都会带上busigroup,如mem_available_percent{busigroup="ops.xxx"},这样可以提高查询速度,且防止收到其他业务组告警;
所有自动添加的监控都会带上附加标签,方便后期针对性屏蔽监控;
根据业务需求配置多种规则模板,业务有需求自行导入;
用notify.py的方式增加了短信和电话告警;
自动按业务线导入基础和业务监控大盘,用户选择业务组就可以看到对应大盘。
资源管理
根据服务树关系自动创建业务组,自动绑定业务组,自动删除已下线机器。
用户管理
根据权限系统,自动同步用户,自动删除离职用户,自动创建3个团队,如ops.monitor.dev,ops.monitor.sre,ops.monitor是dev+sre所有用户; 做完以上工作大量简化了运维和研发工作量,运维只需要关注默认告警阈值是否合理即可;
写在最后
作者简介
关于夜莺监控
Github:github.com/ccfos/nightingale Proposal & Issues: github.com/ccfos/nightingale/issues Docs: n9e.github.io

