排行
数据库百科
核心案例
行业报告
月度解读
大事记
产业图谱
中国数据库
向量数据库
时序数据库
实时数据库
搜索引擎
空间数据库
图数据库
数据仓库
大调查
2021年报告
2022年报告
年度数据库
2020年openGauss
2021年TiDB
2022年PolarDB
2023年OceanBase
首页
资讯
活动
大会
学习
课程中心
推荐优质内容、热门课程
学习路径
预设学习计划、达成学习目标
知识图谱
综合了解技术体系知识点
课程库
快速筛选、搜索相关课程
视频学习
专业视频分享技术知识
电子文档
快速搜索阅览技术文档
文档
问答
服务
智能助手小墨
关于数据库相关的问题,您都可以问我
数据库巡检平台
脚本采集百余项,在线智能分析总结
SQLRUN
在线数据库即时SQL运行平台
数据库实训平台
实操环境、开箱即用、一键连接
数据库管理服务
汇聚顶级数据库专家,具备多数据库运维能力
数据库百科
核心案例
行业报告
月度解读
大事记
产业图谱
我的订单
登录后可立即获得以下权益
免费培训课程
收藏优质文章
疑难问题解答
下载专业文档
签到免费抽奖
提升成长等级
立即登录
登录
注册
登录
注册
首页
资讯
活动
大会
课程
文档
排行
问答
我的订单
首页
专家团队
智能助手
在线工具
SQLRUN
在线数据库即时SQL运行平台
数据库在线实训平台
实操环境、开箱即用、一键连接
AWR分析
上传AWR报告,查看分析结果
SQL格式化
快速格式化绝大多数SQL语句
SQL审核
审核编写规范,提升执行效率
PLSQL解密
解密超4000字符的PL/SQL语句
OraC函数
查询Oracle C 函数的详细描述
智能助手小墨
关于数据库相关的问题,您都可以问我
精选案例
新闻资讯
云市场
登录后可立即获得以下权益
免费培训课程
收藏优质文章
疑难问题解答
下载专业文档
签到免费抽奖
提升成长等级
立即登录
登录
注册
登录
注册
首页
专家团队
智能助手
精选案例
新闻资讯
云市场
微信扫码
复制链接
新浪微博
分享数说
采集到收藏夹
分享到数说
举报
首页
/
做好智能化运维从做好指标开始
做好智能化运维从做好指标开始
白鳝的洞穴
2021-02-04
1281
今天来聊聊指标,老白的题目是“做好智能化运维从做好指标开始”,没说指标采集而是说指标并不是为了省略,而是因为指标的工作十分庞杂,采集只是其中的一个环节。曾经和别人讨论智能化运维系统的整体方案,项目组搞了一个十分庞大的体系,什么智能化异常检测,智能化故障发现,一体化全链路展示,3D可视化,数字孪生,一应俱全。当时我就问他们,指标怎么考虑的?他们指了指偏居一隅的普罗米修斯说,那不就是指标吗?你想要啥,都可以让它帮你采集。我当时就有点发懵,继续说,要把指标搞好不容易,光靠普罗米修斯自带那点恐怕不够吧。当时那个负责人说,我知道,指标这玩意太复杂了,没人搞得好,暂时先不考虑了,我们先把平台做好。
这恐怕是大多数运维自动化系统建设过程中的常态,整个运维自动化的体系架构并不是运维专家主导设计的,而是一群软件开发方面的专家操刀的。于是整个技术架构十分优秀,但是我总觉得差了点什么。这种先不考虑指标就去设计总体架构的做法,和我们做应用系统,先不考虑数据的特点就去设计系统的部署架构如出一辙。没有打过地基的地上盖房子,总是盖不牢的,一场大风大雨可能就会让这些缺乏地基的华丽的地面建筑变成一片废墟。
以前的运维自动化系统十分简单,发现出现异常的系统,并且报警就可以了。这种运维自动化系统最早在国内被称为大网管,这个名字的来源主要是最早是运营商开始做的,当时运营商在这方面比较愿意花钱。做这种大网管式的运维自动化系统也不好做,那就是运维对象的指标集中式采集不太好搞,很多运维对象没有SNMP的支持,采集起来比较麻烦。所以,在那个阶段,哪怕都是买了openview这样的大网管平台的企业,做出了的运维自动化系统的水平也差距很大。从本质上说,这些差距是管理理念的差距与数据质量的差距的综合因素导致的。
而智能化运维要解决的问题比传统的运维自动化要解决的问题要复杂的多,而且智能化运维依赖的核心是数据。因此在建设智能化运维系统的过程中,指标的重要性就不言而喻了。
指标是十分复杂的,一个指标有当前值,最近几分钟的平均值,最大值,最小值,90分位值,同比、环比值,方差、标准差,变化趋势,异常指数等多个维度视角,我们仅仅使用一个当前值去做预警是远远不够的。我们该如何去表示这个指标呢?该如何存储这个指标的数据呢?如果这些都没考虑好,恐怕后面你设计的存储架构,设计的指标预警体系都是白搭。说到这儿,做智能化运维的专家恐怕会不同意老白的观点了,智能化运维里,这些都是最基本的算法都能解决的问题,怕啥。我想绝大多数做智能化运维系统的用户的最大的目的并不是从一堆数据里去找异常,而是在故障未发生的时候能够提前发现故障。很多场景都需要对指标做实时计算,通过这些去做预警,而不仅仅是对历史数据做问题发现。
再举个稍微复杂点的例子,文件系统使用率这个指标,你该如何考虑呢?你的系统中肯定有很多个文件系统,关键的文件系统也不少,你该如何设计这个指标呢?实际上很多互联网公司都遇到过这样的问题,后来都选择采用一些自己的独特表达方式解决了这个问题。有些采用了子指标的方式,有些采用了指标下标或者INAME的方式实现了对这些指标的采集,存储与使用问题。
除此之外,更为复杂的问题是我们该如何准确的获取到指标。去年有一个客户在做我们的D-SMART的POC,当时客户说他们遇到一个十分怪异的性能问题,如果我们的工具能够分析出来,那么就说明我们的工具还挺有用的,可以立即采购。能遇到实战考试是挺好的事情,于是在部署了D-SMART一周后,我们让用户把采集的数据发回我们的实验室,很快我们就定位了那个性能问题,主要还是一个每个小时跑一次的批量取数作业,每次都有8个并发,大量的扫描数据并输出到文件中,产生了大量的IO,后端存储有点撑不住,IO延时高达30多毫秒,这样就把整个数据库的性能都带慢了。我们把分析结果告诉客户后,客户笑着对我们说,你们分析出了定时作业导致了问题,但是原因没分析对,我们正在测试的另外一套运维自动化系统告诉了我们另外一个原因,而那个原因正是问题的根因,造成这个问题的根因是换页。
我们又仔细地看了看数据,这套系统内存很大,有1TB,ORACLE的SGA才分配了100G,平时最少的FREE内存都有500GB,怎么会有换页呢?于是我们指导客户在生产环境中监控vmstat等数据,从采集回来的数据上也没看到有换页的情况产生,而从另外那套运维自动化系统上确实看到大量的系统换页的告警。后来仔细比对了一下,才发现,原来那套系统把bi/bo都计算为换页了。而实际上PI/PO才是真正的换页,BI/BO则包含了文件系统的IO操作和换页操作。开发人员没有正确的采集到指标,才造出了这样的乌龙。
实际上要采集到准确的指标是需要大量的运维知识的,如果没有运维专家的介入,是很难做的很好的。举个大家最常用的指标做个例子,空间使用率的问题,简化一点,对ORACLE来说,表空间使用率该如何采集,如何使用?传统的做法是采集一个使用率,然后超过90%发一个警告,超过95%再发,达到99%发严重告警。这种告警有用吗?有时候,我们的数据文件是自动扩展的,那么100%的表空间使用率都不怕。有时候虽然数据文件是自动扩展的,100%的使用率我们不怕,但是如果数据文件的大小扩大到了32G了,这时候如果我们还不报警,那会不会出事?就算文件是BIGFILE,没有数据块的限制,如果文件所在的文件系统或者ASM磁盘组的容量不足了,我们不报警,是不是还会有事?哪怕表空间的使用率不到80%,但是这个表空间里的碎片很多,而且这个表空间里存在较多的大对象,那么还是很可能会出现无法分配空间的情况出现。是不是太难了?实际上这就是隐藏在指标里的运维经验。如果这部分的指标和预警由一个运维专家来做,和一个普通的DBA来做,甚至是一个开发人员来做,那么做出来的效果恐怕差距不是一点半点的了。
指标是运维自动化的基石,如果不能把指标体系建设好,后面强大的算法,完善的体系,漂亮的可视化,都是空中楼阁,就像老白告诫弟兄们的“不要做出一堆美丽的垃圾”。
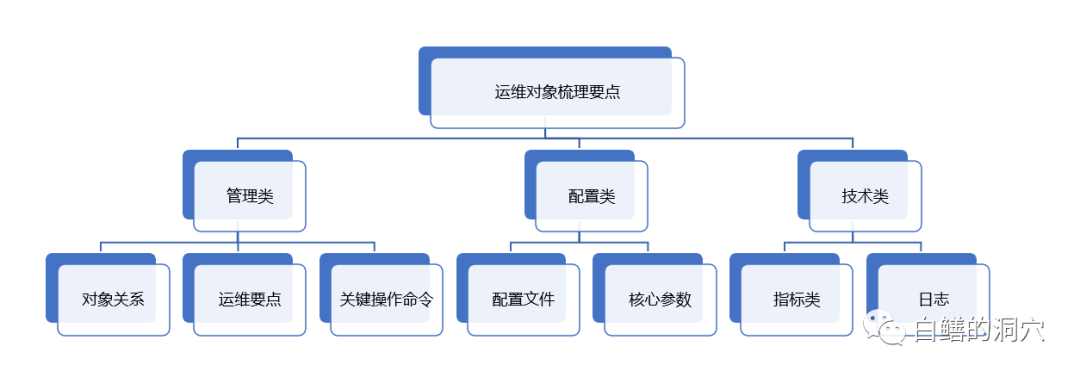
要做好智能化运维,首先需要由专家牵头,对我们的运维对象进行仔细地梳理。
通过这种梳理,找到运维地要点,通过运维要素去看我们需要如何看这个运维对象,如何在这个运维对象上积累运维自动化地能力,从而分析需要什么样地指标来支撑这样地运维自动化能力。唯有如此,才能真正地做出真正具有智能的智能化运维工具来。连指标都搞不清楚的智能化运维系统,鬼才信它真的有用呢。
如果有一天,有个做智能化运维的人和你说,你说你想分析啥,我都能帮你做,那个人一定是个骗子。而如果有人告诉你,目前我们能分析多少个运维场景,覆盖多少日常运维领域,那么这个人可能靠谱一些。
数据库
文章转载自
白鳝的洞穴
,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
评论
领墨值
有奖问卷
意见反馈
客服小墨