




本文主要介绍如何将 Parquet 文件读入 Dask DataFrame。Parquet 是一种列式二进制文件格式,与 CSV 等基于行的文件格式相比,它具有多种优势。详细介绍,参见什么是 Parquet 文件格式以及为什么要使用它。
Dask 可以轻松地将 Parquet 文件读入 Dask DataFrame, 但正确读取 Parquet 文件可以获得更优的性能。磁盘 I/O 可能是大型数据集上的分布式计算工作流的主要瓶颈。正确读取 Parquet 文件可以让您向计算集群发送更少的数据,因此您的分析可以运行得更快。
让我们先看一些关于小型数据集的示例,以更好地理解读取 Parquet 文件时的选项。然后,我们将查看具有数千个 Parquet 文件的更大数据集的示例,这些文件在云中的集群上进行处理。
Dask read_parquet:基本用法
让我们创建一个小的 DataFrame 并将其写成 Parquet 文件。
首先创建 DataFrame
import dask.dataframe as dd
import pandas as pd
df = pd.DataFrame(
{"nums": [1, 2, 3, 4, 5, 6],
"letters": ["a", "b", "c", "d", "e", "f"]
}
)
ddf = dd.from_pandas(df, npartitions=2)
使用 pyarrow 引擎将 DataFrame 写入 Parquet 文件
ddf.to_parquet("data/something", engine="pyarrow")
以下是输出到磁盘的文件
data/something/
_common_metadata
_metadata
part.0.parquet
part.1.parquet
将文件读入 Dask DataFrame
ddf = dd.read_parquet("data/something", engine="pyarrow")
检查 DataFrame 的内容以确保正确读取所有 Parquet 数据。
ddf.compute()

Dask read Parquet 支持两 种 Parquet 引擎,但大多数用户可以简单地使用 pyarrow,就像我们在前面的示例中所做的那样,无需深入研究此选项。
Dask read_parquet:pyarrow 与 fastparquet 引擎
您可以使用 fastparquet 或 pyarrow 引擎来读写 Parquet 文件。两个引擎大部分时间都可以正常工作。两种引擎之间的细微差别对于绝大多数用例来说都无关紧要。
通常最好避免混合和匹配 Parquet 引擎。例如,您通常不想使用 pyarrow 编写 Parquet 文件,然后尝试使用 fastparquet 读取它们。
这篇博文将只使用 pyarrow 引擎,不会深入探讨 pyarrow 和 fastparquet 之间的细微差别。您通常可以只使用 pyarrow,而不必考虑引擎之间的细微差别。
Dask read_parquet:云中的大量文件
我们之前的示例展示了如何在 localhost 上读取两个 Parquet 文件,但您通常需要读取存储在 Amazon S3 等基于云的文件系统中的数千个 Parquet 文件。
以下是如何将 6.62 亿行 Parquet 数据集读取到具有 5 节点计算集群的 Dask DataFrame 中。
import dask
import dask.dataframe as dd
from distributed import Client, LocalCluster
cluster = LocalCluster()
client = Client(cluster)
ddf = dd.read_parquet(
"s3://coiled-datasets/timeseries/20-years/parquet",
engine="pyarrow",
storage_options={"anon": True, "use_ssl": True},
)
查看此 DataFrame 的前 5 行以了解数据。
ddf.head()
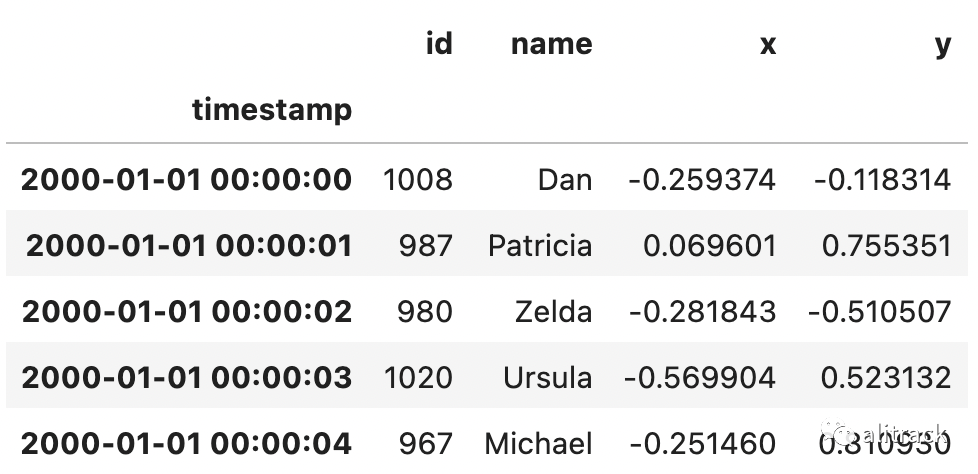
该数据集包含一个时间戳索引和四列数据。
让我们运行一个查询来计算 id 列中唯一值的数量。
ddf["id"].nunique().compute()
此查询需要 59 秒(coiled 服务器上) 才能执行。
请注意,此查询只需要 ID 列。但是,我们传输了 Parquet 文件所有列的数据以运行此查询。花时间将未使用的数据从文件系统传输到集群显然是低效的。
让我们看看 Parquet 如何让您只读取需要加快查询时间的列。
Dask read_parquet:列选择
Parquet 是一种列文件格式,允许您在读取文件时选择性地读取某些列。从 CSV 等基于行的文件格式读取时,您不能挑选某些列。Parquet 的 列式特性是一大优势。
让我们将上一节中的查询重构为只读取 ID 列到集群通过设置列参数
ddf = dd.read_parquet(
"s3://coiled-datasets/timeseries/20-years/parquet",
engine="pyarrow",
storage_options={"anon": True, "use_ssl": True},
columns=["id"],
)
现在让我们运行与之前相同的查询。
ddf["id"].nunique().compute()
此查询只需要 43 秒即可执行,速度提高了 27%。对于不同的数据集/查询,这种性能增强可能会大得多。
从文件中挑选单个列通常称为列修剪。您可以跳过的列越多,越多的列修剪将有助于加快查询速度。
当您使用 Dask 查询 Parquet 文件时,一定要确保利用列修剪。
Dask read_parquet:行组过滤器
Parquet 文件将数据存储在行组中。每个行组都包含元数据,包括行组中每列的最小值/最大值。对于某些过滤查询,您可以仅根据行组元数据跳过整个行组。
例如,假设 A 列在 row_group_3 最小值为 2,最大值为 34。如果您要查找所有行 A 列值大于 95,那么你知道 row_group_3 不会包含与您的查询相关的任何数据。您可以完全跳过该查询的行组。
让我们在没有任何行组过滤器的情况下运行查询,然后使用行组过滤器运行相同的查询,以查看性能手册谓词下推过滤可以提供的情况。
ddf = dd.read_parquet(
"s3://coiled-datasets/timeseries/20-years/parquet",
engine="pyarrow",
storage_options={"anon": True, "use_ssl": True},
)
len(ddf[ddf.id > 1170])
此查询需要 77 秒才能执行。
让我们使用行组过滤运行相同的查询。
ddf = dd.read_parquet(
"s3://coiled-datasets/timeseries/20-years/parquet",
engine="pyarrow",
storage_options={"anon": True, "use_ssl": True},
filters=[[("id", ">", 1170)]],
)
len(ddf[ddf.id > 1170])
此查询运行时间为 4.5 秒,速度明显更快。
行组过滤也称为谓词下推过滤,可以通过设置过滤器调用时的参数 read_parquet.
谓词下推过滤器可以提供巨大的性能提升或根本没有。这取决于 Dask 能够为特定查询跳过多少行组。您可以使用行组过滤器跳过的行组越多,您需要读取到集群的数据就越少,您的分析执行速度就越快。
Dask read_parquet:忽略元数据文件
当你用 Dask 写 Parquet 文件时,它会输出一个 _metadata
默认文件。该 _metadata
文件包含文件系统中所有文件的 Parquet 文件页脚信息,因此 Dask 不需要在每次读取 Parquet 湖时单独读取 Parquet 数据集中每个文件的文件页脚。
该 _metadata
文件对于较小的数据集来说是一个很好的性能优化,但它也有缺点。
_metadata
是单个文件,因此对于大型数据集不可扩展。对于大型数据湖,即使元数据也可以是“大数据”,具有与“常规数据”相同的扩展问题。
您可以通过设置让 Dask 读取 Parquet 忽略元数据文件 ignore_metadata_file
=True
ddf = dd.read_parquet(
"s3://coiled-datasets/timeseries/20-years/parquet",
engine="pyarrow",
storage_options={"anon": True, "use_ssl": True},
ignore_metadata_file=True,
)
Dask read_parquet:索引
您可能会惊讶地发现 Dask 在读取 Parquet 文件时可以智能地推断索引。Dask 能够从 Pandas parquet 文件元数据中确认索引。您也可以手动指定索引。
ddf = dd.read_parquet(
"s3://coiled-datasets/timeseries/20-years/parquet",
engine="pyarrow",
storage_options={"anon": True, "use_ssl": True},
index="timestamp",
)
您还可以在不指定索引的情况下将所有数据作为常规列读取。
ddf = dd.read_parquet(
"s3://coiled-datasets/timeseries/20-years/parquet",
engine="pyarrow",
storage_options={"anon": True, "use_ssl": True},
index=False,
)
ddf.head()
Dask read_parquet:分类参数
您可以通过设置分类选项将列作为分类列读取。
检查 dtypes 以确保这是作为一个分类读入的。
ddf.dtypes
id category
name object
x float64
y float64
dtype: object
原文:Dask Read Parquet Files into DataFrames with read_parquet
链接:https://coiled.io/blog/dask-read-parquet-into-dataframe/
下面在 deepnote 试试前文提到的大文件
我没有注册 AWS 、GCP 以及 Azure, 所以我选择在 deepnote 上做了测试,因为文件存储在 S3 上,访问肯定要慢很多, 但仍然可以可以看出读取全部列和部分列时计算时间的巨大差异
准备工作
注册好了 deepnote 账号
新建一个 project
安装 dask 和 s3fs
pip install dask ipython-autotime
#需指定安装user路径下,否则报错
pip install --user s3fs
#自动计时
%load_ext autotime
看看要读的远程数据有多少 parquet
import s3fs
fs = s3fs.S3FileSystem(anon=True)
files = fs.glob("s3://coiled-datasets/timeseries/20-years/parquet/*.parquet")
len(files)
#返回1095
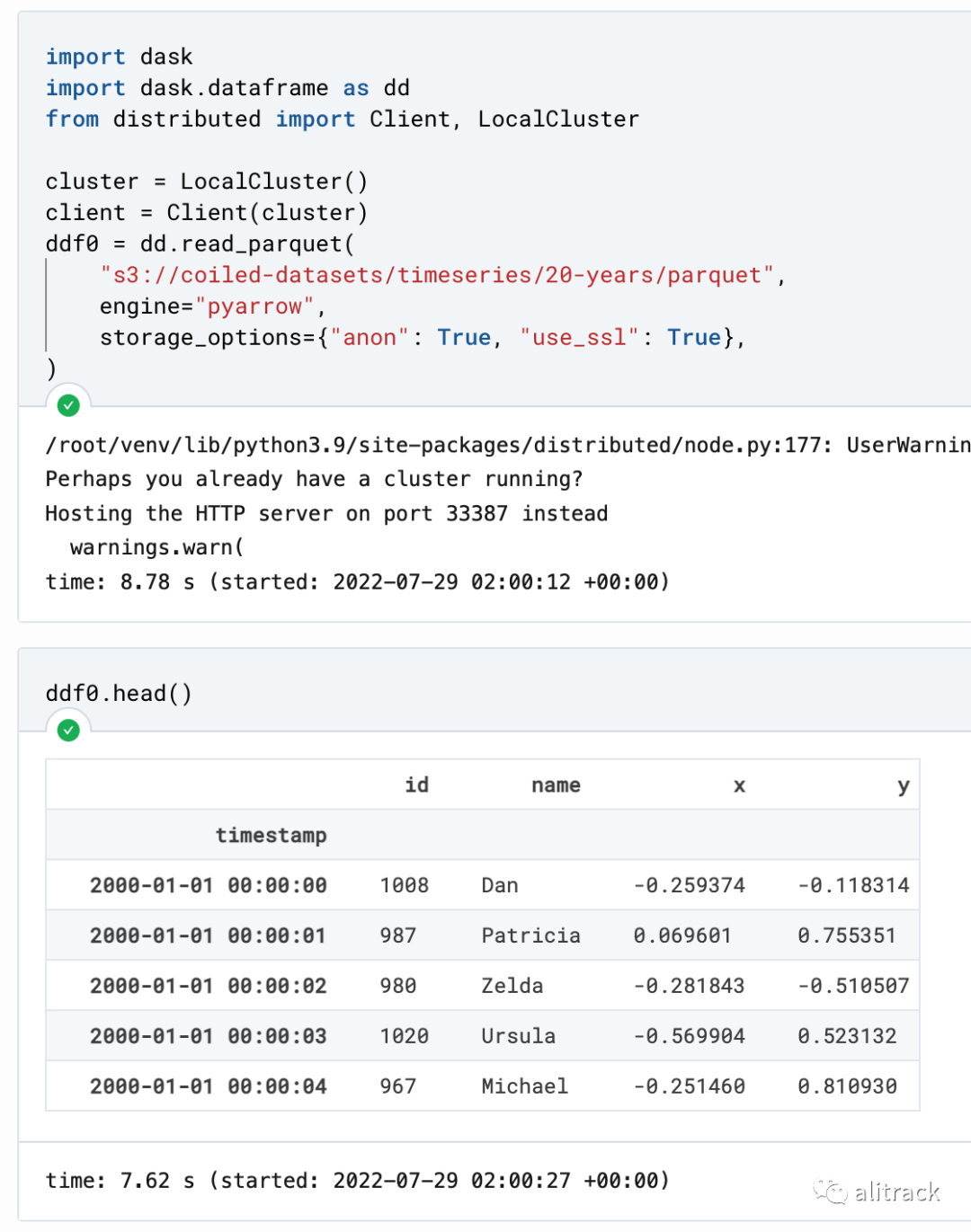
读取全部列, 查看前 5 行,用时 7s 多, 计算行数用时 超过 13 分钟
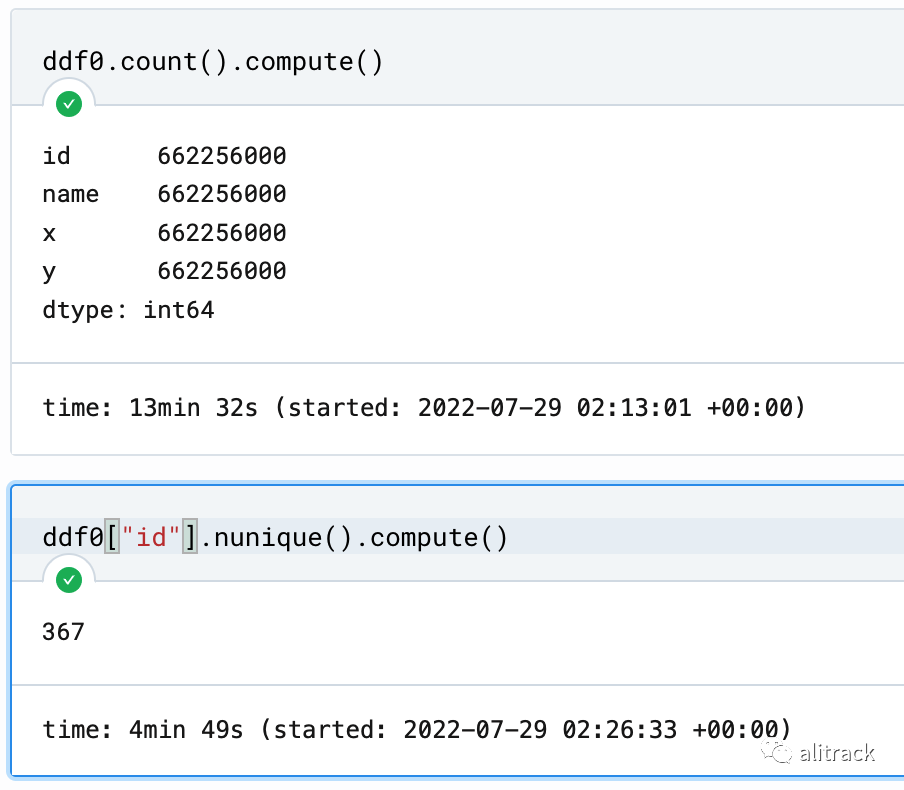
只读取一列, 计算行数用时 4 分钟
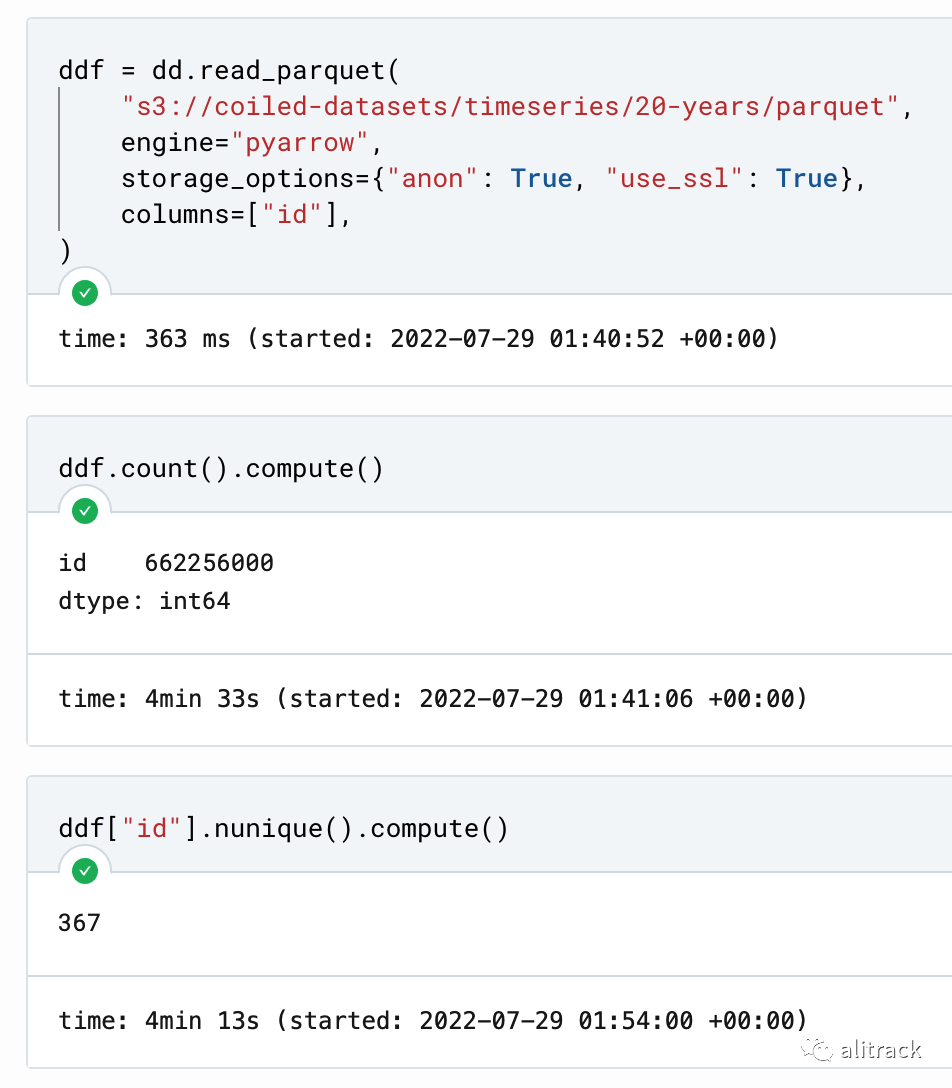
这里的主要瓶颈时 I/O,读取多列比读取一列肯定用时更多。
