




Table of Contents
一. 维基百科中文数据
1.1 数据下载
下载网址:
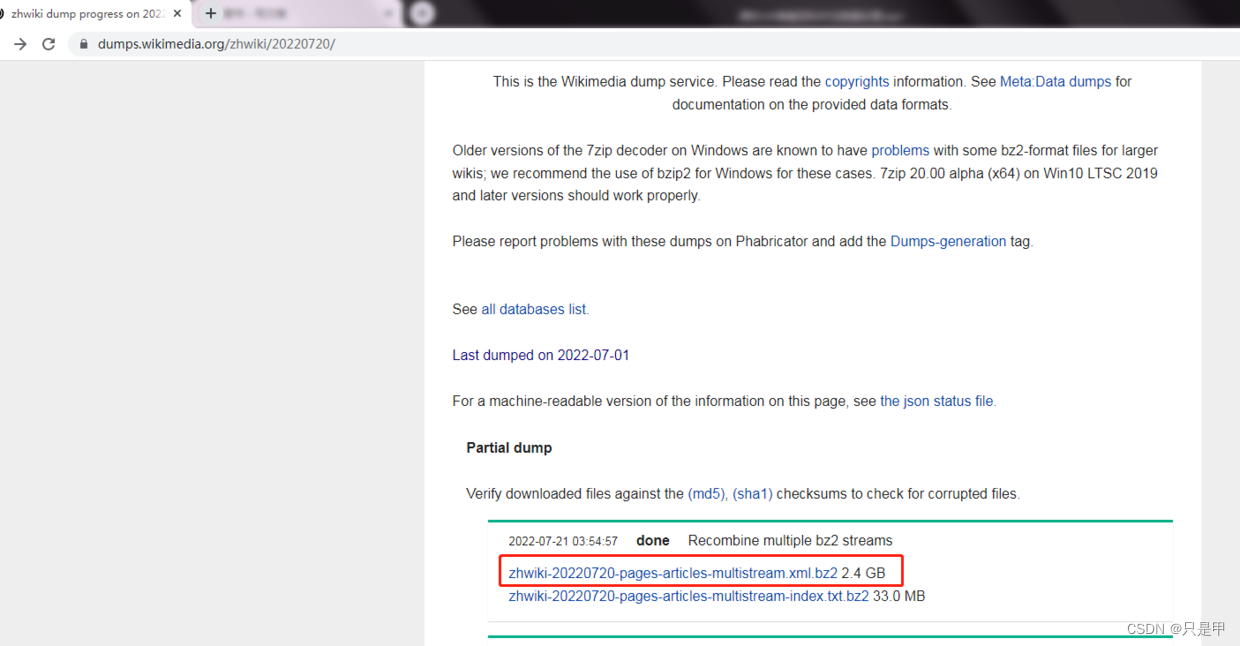
解压:
解压后数据集差不多10G
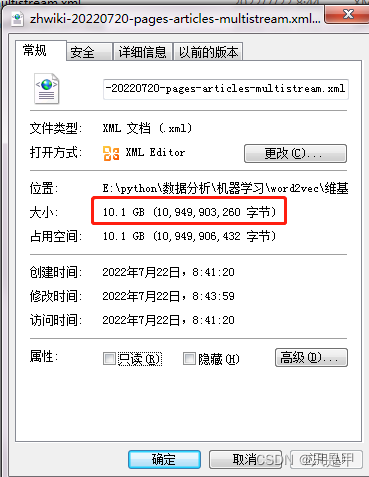
使用编辑器浏览数据格式:
1.2 数据预处理
将xml.bz2的数据,通过python程序转为text文档数据
代码:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# 修改后的代码如下:
import logging
import os.path
import sys
from gensim.corpora import WikiCorpus
if __name__ == '__main__':
program = os.path.basename(sys.argv[0])
logger = logging.getLogger(program)
logging.basicConfig(format='%(asctime)s: %(levelname)s: %(message)s')
logging.root.setLevel(level=logging.INFO)
logger.info("running %s" % ' '.join(sys.argv))
# check and process input arguments
if len(sys.argv) < 3:
#print(globals()['__doc__'] % locals())
sys.exit(1)
inp, outp = sys.argv[1:3]
space = ' '
i = 0
output = open(outp, 'w', encoding='utf-8')
# wiki = WikiCorpus(inp, lemmatize=False, dictionary={})
wiki = WikiCorpus(inp, dictionary={})
for text in wiki.get_texts():
s = space.join(text)
#s = s.decode('utf8') + "\n"
s = s + "\n"
output.write(s)
i = i + 1
if (i % 10000 == 0):
logger.info("Saved " + str(i) + " articles")
output.close()
logger.info("Finished Saved " + str(i) + " articles")
# python process.py zhwiki-latest-pages-articles.xml.bz2 wiki.zh.text
测试记录:
python process.py E:/python/数据分析/机器学习/word2vec/维基百科中文数据/zhwiki-20220720-pages-articles-multistream.xml.bz2 wiki.zh.text
2022-07-22 11:47:20,200: INFO: Saved 10000 articles
2022-07-22 11:47:49,804: INFO: Saved 20000 articles
2022-07-22 11:48:15,985: INFO: Saved 30000 articles
2022-07-22 11:48:41,948: INFO: Saved 40000 articles
2022-07-22 11:49:07,655: INFO: Saved 50000 articles
2022-07-22 11:49:32,707: INFO: Saved 60000 articles
2022-07-22 11:49:56,776: INFO: Saved 70000 articles
2022-07-22 11:50:20,577: INFO: Saved 80000 articles
2022-07-22 11:50:44,223: INFO: Saved 90000 articles
2022-07-22 11:51:07,352: INFO: Saved 100000 articles
2022-07-22 11:51:32,792: INFO: Saved 110000 articles
2022-07-22 11:52:02,830: INFO: Saved 120000 articles
2022-07-22 11:52:27,015: INFO: Saved 130000 articles
2022-07-22 11:52:55,681: INFO: Saved 140000 articles
2022-07-22 11:53:22,406: INFO: Saved 150000 articles
2022-07-22 11:53:51,108: INFO: Saved 160000 articles
2022-07-22 11:54:17,588: INFO: Saved 170000 articles
2022-07-22 11:54:44,145: INFO: Saved 180000 articles
2022-07-22 11:55:12,876: INFO: Saved 190000 articles
2022-07-22 11:57:02,681: INFO: Saved 200000 articles
2022-07-22 11:57:37,999: INFO: Saved 210000 articles
2022-07-22 11:58:24,656: INFO: Saved 220000 articles
2022-07-22 11:58:57,855: INFO: Saved 230000 articles
2022-07-22 11:59:30,406: INFO: Saved 240000 articles
2022-07-22 12:00:07,523: INFO: Saved 250000 articles
2022-07-22 12:00:39,435: INFO: Saved 260000 articles
2022-07-22 12:01:16,402: INFO: Saved 270000 articles
2022-07-22 12:01:50,524: INFO: Saved 280000 articles
2022-07-22 12:02:24,565: INFO: Saved 290000 articles
2022-07-22 12:02:56,571: INFO: Saved 300000 articles
2022-07-22 12:03:25,060: INFO: Saved 310000 articles
2022-07-22 12:03:58,827: INFO: Saved 320000 articles
2022-07-22 12:04:31,788: INFO: Saved 330000 articles
2022-07-22 12:05:09,589: INFO: Saved 340000 articles
2022-07-22 12:05:44,559: INFO: Saved 350000 articles
2022-07-22 12:06:22,483: INFO: Saved 360000 articles
2022-07-22 12:06:59,661: INFO: Saved 370000 articles
2022-07-22 12:07:35,899: INFO: Saved 380000 articles
2022-07-22 12:08:16,372: INFO: Saved 390000 articles
2022-07-22 12:08:50,098: INFO: Saved 400000 articles
2022-07-22 12:09:24,153: INFO: Saved 410000 articles
2022-07-22 12:09:59,611: INFO: Saved 420000 articles
2022-07-22 12:10:35,669: INFO: Saved 430000 articles
2022-07-22 12:10:45,356: INFO: finished iterating over Wikipedia corpus of 432882 documents with 100469267 positions (total 4078948 articles, 118486509 positions before pruning articles shorter than 50 words)
2022-07-22 12:10:45,554: INFO: Finished Saved 432882 articles
查看解析后的数据:
都是繁体字
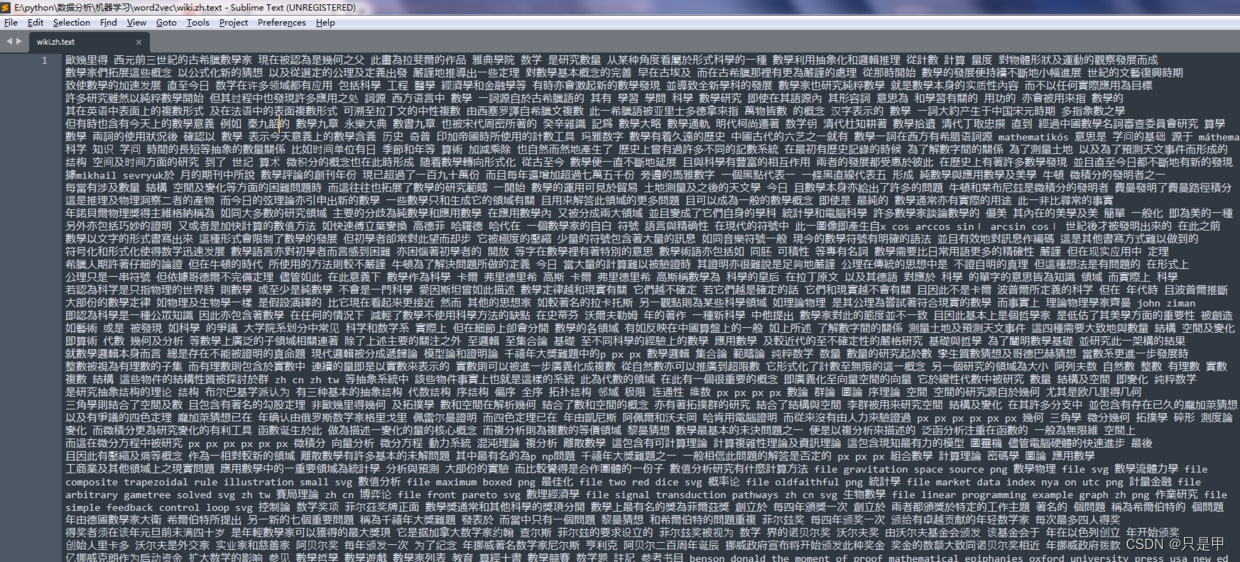
1.3 将繁体字转为简体字
1.3.1 opencc安装
1.3.1.1 pip安装
pip之间安装opencc报错

应该使用如下命令:
pip install opencc-python-reimplemented
参数解释:
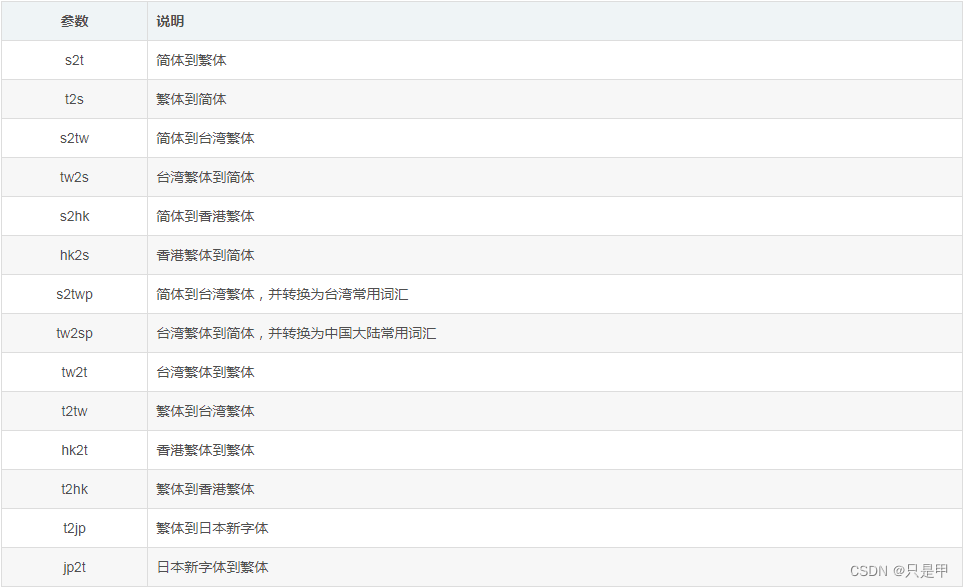
1.3.1.2 windows安装
下载地址:
https://github.com/BYVoid/OpenCC/wiki/Download
配置文件:

1.3.2 windows下opencc使用
拷贝文件到bin目录:
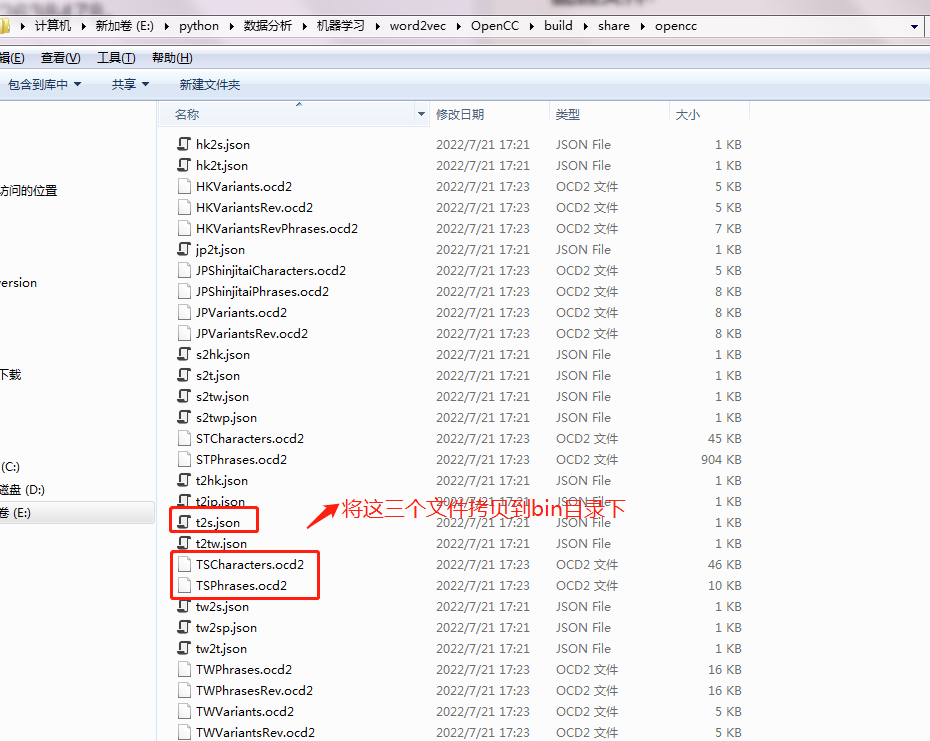
查看opcc的帮助命令:
E:\python\数据分析\机器学习\word2vec\OpenCC\build\bin>opencc --help
Open Chinese Convert (OpenCC) Command Line Tool
Author: Carbo Kuo <byvoid@byvoid.com>
Bug Report: http://github.com/BYVoid/OpenCC/issues
Usage:
opencc [--noflush <bool>] [-i <file>] [-o <file>] [-c <file>] [--]
[--version] [-h]
Options:
--noflush <bool>
Disable flush for every line
-i <file>, --input <file>
Read original text from <file>.
-o <file>, --output <file>
Write converted text to <file>.
-c <file>, --config <file>
Configuration file
--, --ignore_rest
Ignores the rest of the labeled arguments following this flag.
--version
Displays version information and exits.
-h, --help
Displays usage information and exits.
Open Chinese Convert (OpenCC) Command Line Tool
E:\python\数据分析\机器学习\word2vec\OpenCC\build\bin>
将繁体字转为简体字:
opencc -i E:\python\数据分析\机器学习\word2vec\wiki.zh.text -o E:\python\数据分析\机器学习\word2vec\wiki_简体.zh.text -c t2s.json

二. 使用jieba进行分词
代码:
import jieba
import jieba.analyse
import jieba.posseg as pseg
import codecs,sys
def cut_words(sentence):
#print sentence
return " ".join(jieba.cut(sentence)).encode('utf-8')
f=codecs.open('wiki_简体.zh.text','r',encoding="utf8")
target = codecs.open("wiki_简体.zh.分词.seg-1.3g.text", 'w',encoding="utf8")
print ('open files')
line_num=1
line = f.readline()
while line:
print('---- processing ', line_num, ' article----------------')
line_seg = " ".join(jieba.cut(line))
target.writelines(line_seg)
line_num = line_num + 1
line = f.readline()
f.close()
target.close()
exit()
while line:
curr = []
for oneline in line:
#print(oneline)
curr.append(oneline)
after_cut = map(cut_words, curr)
target.writelines(after_cut)
print ('saved',line_num,'articles')
exit()
line = f.readline1()
f.close()
target.close()
# python Testjieba.py
测试记录:
分词完成后的文本如下:
三. 生成词向量
python代码:
import logging
import os.path
import sys
import multiprocessing
from gensim.corpora import WikiCorpus
from gensim.models import Word2Vec
from gensim.models.word2vec import LineSentence
if __name__ == '__main__':
program = os.path.basename(sys.argv[0])
logger = logging.getLogger(program)
logging.basicConfig(format='%(asctime)s: %(levelname)s: %(message)s')
logging.root.setLevel(level=logging.INFO)
logger.info("running %s" % ' '.join(sys.argv))
# check and process input arguments
if len(sys.argv) < 4:
print (globals()['__doc__'] % locals())
sys.exit(1)
inp, outp1, outp2 = sys.argv[1:4]
model = Word2Vec(LineSentence(inp), window=5, min_count=5, workers=multiprocessing.cpu_count())
model.save(outp1)
model.wv.save_word2vec_format(outp2, binary=False)
#python word2vec_model.py zh.jian.wiki.seg.txt wiki.zh.text.model wiki.zh.text.vector
#opencc -i wiki_texts.txt -o test.txt -c t2s.json
运行python程序:
python word2vec_model.py wiki_简体.zh.分词.seg-1.3g.text wiki_简体.zh.分词.seg-1.3g.text.model wiki_简体.zh.分词.seg-1.3g.text.vector
测试记录:
新生成的文件:
model文件内容如下:
四. 测试
输出与我的测试词最接近的5个词
代码:
from gensim.models import Word2Vec
en_wiki_word2vec_model = Word2Vec.load('wiki_简体.zh.分词.seg-1.3g.text.model')
testwords = ['苹果','数学','学术','白痴','篮球']
for i in range(5):
res = en_wiki_word2vec_model.wv.most_similar(testwords[i])
print (testwords[i])
print (res)
测试记录:
苹果
[('洋葱', 0.6776813268661499), ('apple', 0.6557675004005432), ('黑莓', 0.6425948143005371), ('草莓', 0.6342688798904419), ('小米', 0.6270812153816223), ('坚果', 0.6188254952430725), ('苹果公司', 0.6164141893386841), ('果冻', 0.6137404441833496), ('咖啡', 0.604507327079773), ('籽', 0.597305178642273)]
数学
[('微积分', 0.8419661521911621), ('算术', 0.8334301710128784), ('数学分析', 0.7725528478622437), ('概率论', 0.7687932252883911), ('数论', 0.763685405254364), ('逻辑学', 0.7549666166305542), ('高等数学', 0.7526171803474426), ('物理', 0.7509859800338745), ('数理逻辑', 0.7463771104812622), ('拓扑学', 0.7362903952598572)]
学术
[('学术研究', 0.8562514781951904), ('社会科学', 0.7332450747489929), ('自然科学', 0.7266139388084412), ('学术界', 0.7095916867256165), ('法学', 0.7089691758155823), ('汉学', 0.7063266038894653), ('科学研究', 0.7001381516456604), ('跨学科', 0.6969149708747864), ('学术活动', 0.6920358538627625), ('史学', 0.6917674541473389)]
白痴
[('傻子', 0.764008641242981), ('书呆子', 0.709040105342865), ('疯子', 0.7005040049552917), ('笨蛋', 0.674527108669281), ('傻瓜', 0.6599918603897095), ('骗子', 0.6531063914299011), ('爱哭鬼', 0.650740921497345), ('天才', 0.6505906581878662), ('蠢', 0.6501168012619019), ('娘娘腔', 0.6492332816123962)]
篮球
[('棒球', 0.7790619730949402), ('美式足球', 0.7700984477996826), ('排球', 0.7593865990638733), ('橄榄球', 0.75135737657547), ('网球', 0.7470680475234985), ('冰球', 0.7441636323928833), ('足球', 0.7276999950408936), ('橄榄球队', 0.7252797484397888), ('男子篮球', 0.7197815179824829), ('曲棍球', 0.7128130793571472)]
参考:
- https://study.163.com/course/introduction.htm?courseId=1003590004#/courseDetail?tab=1
「喜欢这篇文章,您的关注和赞赏是给作者最好的鼓励」
关注作者
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文章的来源(墨天轮),文章链接,文章作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
