







贺祥
快手商业化团队数据架构高级工程师
主要负责商业化报表引擎
快手商业化报表引擎为外部广告主提供广告投放效果的实时多维分析报表在线查询服务,以及为商业化内部各系统提供多维分析报表查询服务。致力于解决多维分析报表场景的高性能、高并发、高稳定的查询问题。
1 业务场景介绍
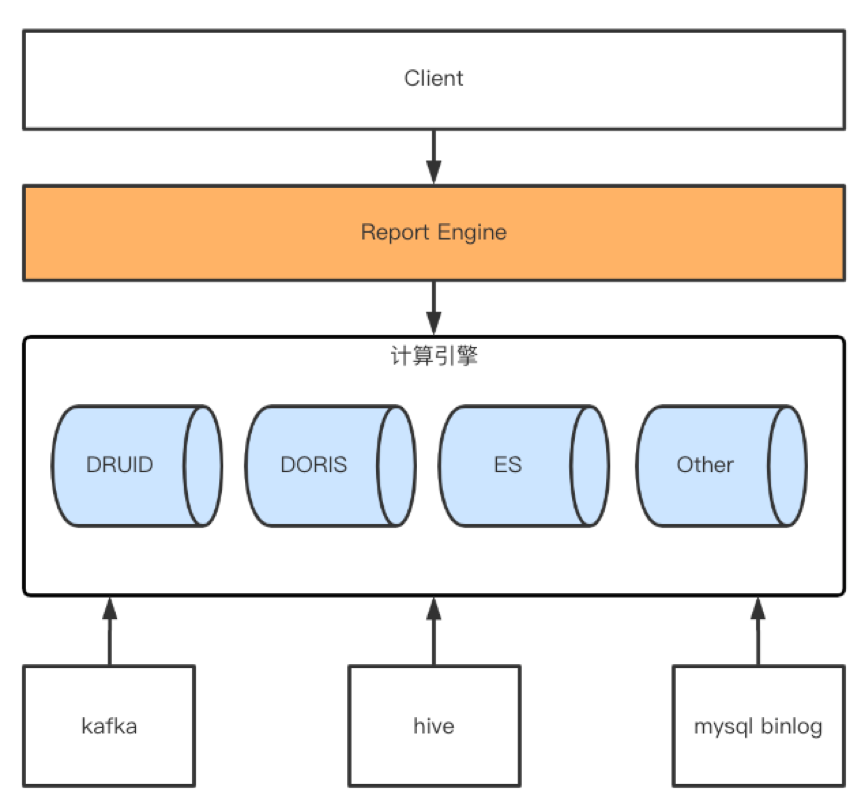
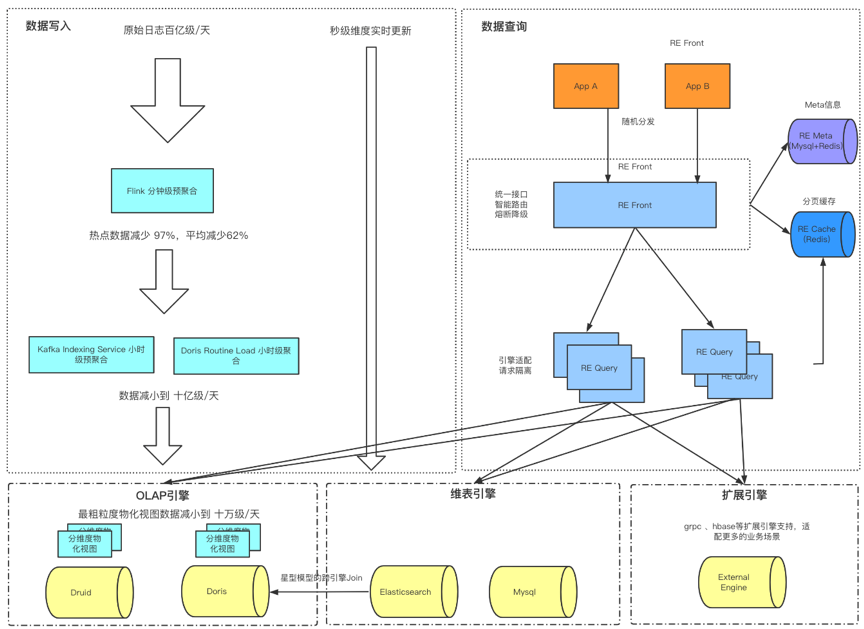
本文主要侧重介绍Doris on ES(DOE)在我们业务场景的实践,所以我们的数据架构在这里只做简单介绍,如上如图所示。
总体来说数据分为实时+离线两块事实数据写入,外加mysql binlong同步这一部分的维度数据写入。
实时主要是flink+kafka,离线部分基本各大公司都是统一解决方案-HIVE。数据最终导入计算引擎都是由各个引擎适配的工具或组件配合来完成的。如DRUID的KIS(kafka index service)+index_hadoop,Doris的routine load + broker load。这里就不一一详细展开了。
1.2.1 传统OLAP多维分析查询
selectf.key_1,f.key_2,d.key_3,d.key_4,AGGR_FUNC(f.value_1),AGGR_FUNC(f.value_2)fromf left join d on d.key = f.key_1 -- 维度表必须具有主键,与事实表进行关联wheref.dt in (xxx) andf.key_xx in (xxx) andd.col_2 in (xxx) and -- 可以基于维度表的col做filterd.key_3 match('xxx') -- match在这里表达的含义是分词模糊匹配场景group byf.key_1,f.key_2,d.key_3,d.key_4order byAGGR_FUNC(f.value_1) DESChaving AGGR_FUNC(f.value_2) > xxxlimit N
大宽表,数据以尽可能全的维度,先join好再写入引擎
星型模型关联查询,查询的时候才去做关联join
大宽表,空间换时间。理论上都是维表主键为唯一ID来填充所有维度,这样只是冗余存储了多条维度数据,但是在OLAP引擎里,不管是DRUID、KYLIN还是DORIS都不会造成数据量的基数膨胀。优势:应用层查询的时候非常方便,无需关联额外的维表,直接面向大而全的宽表查询。劣势:对应的弊端就是如果有维度数据update场景,支持的代价非常大。如果update非常频繁,这种方式就不可行了。
星型模型关联查询。优势:维度数据与事实数据完全分离,维度数据用专门的引擎存储(如mysql、elasticsearch等等),可以支持高频update操作,查询时通过主键关联查询维度数据。劣势:查询层逻辑相对复杂,且多表join会导致性能受损。
1.3 业务挑战
超大数据量:单表原始数据每天增量百亿
查询高QPS:平均QPS千级别
高稳定性要求:在线服务要求稳定性4个9
星型模型中,维表需要支持高频的UPDATE操作(update qps约1千),且维表需要支持模糊匹配、分词检索
2 架构实现
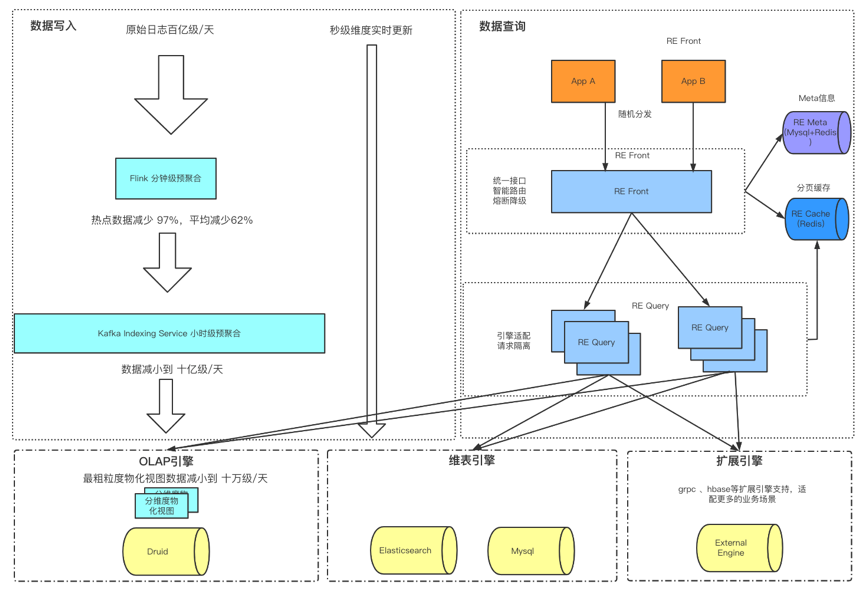
2.1.1 事实数据
2.1.2 维度数据
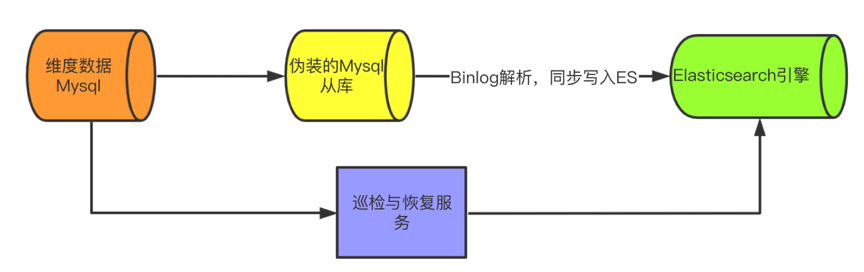
维表数据量级较高,Mysql存储需要做分库分表支持,但是性能无法满足需求
更新频率较高,update QPS约1000
业务侧需要支持分词模糊检索
REFront
REFront 为统一的查询入口层,特点是轻量级、高可用。
核心职能为:查询标记、业务逻辑处理、查询分发、流控、熔断降级。
REQuery
REQuery 为查询执行层,分组部署,为不同的业务场景提供物理隔离。核心职能为:多引擎适配、多集群路由调度、查询优化、MEM Join、结果分页cache等。
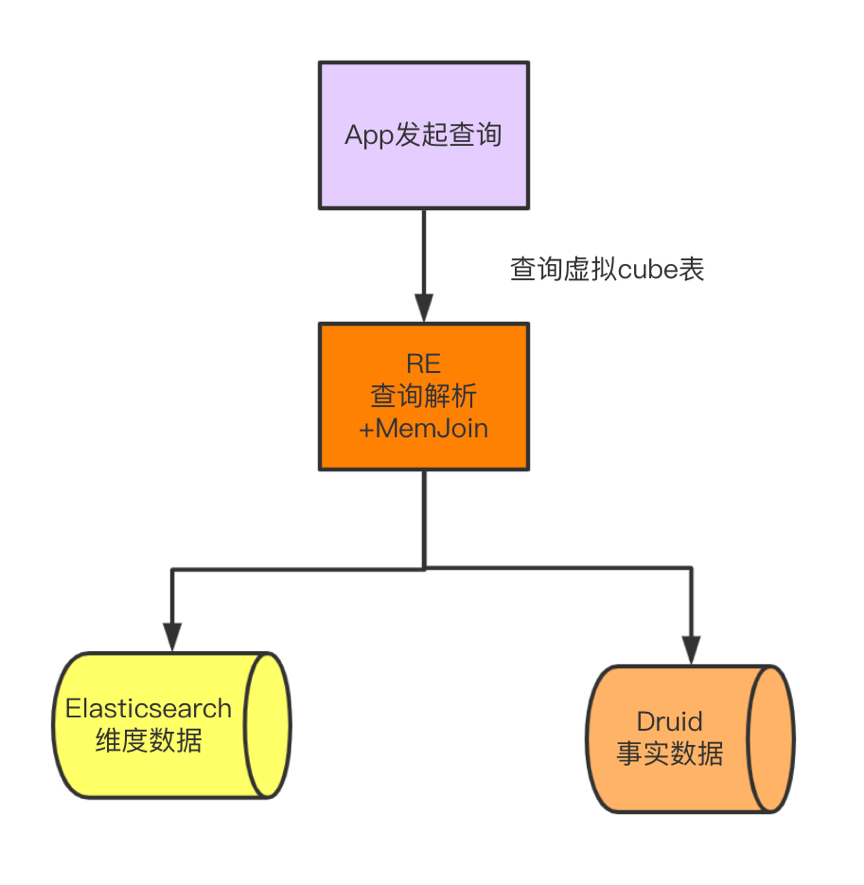
3 基于Doris on ES的架构实现
3.1 Mem Join架构遗留的核心问题
Shard级别并发
行列扫描自动适配,优先列式扫描
顺序读取,提前终止
两阶段查询变为一阶段查询
Join场景使用Broadcast Join,对于小批量数据Join特别友好
目前Doris on ES还不支持聚合下推,但是对于我们维度数据查询场景其实是用不到聚合操作。需要用到聚合操作的场景需要注意一下。不过目前社区也正在开发支持。
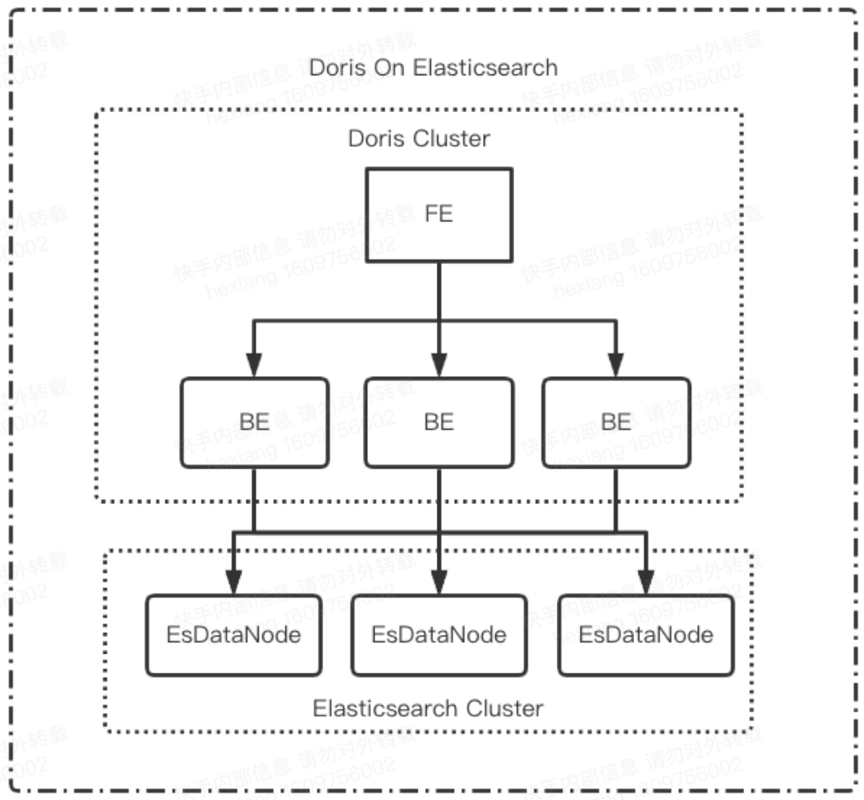
3.3.1 数据链路升级
Doris构建新的Olap表,配置好物化视图。
实时导入基于之前事实数据的kafka topic启动routine load。
离线校准通过broker load从hive中导入。
Doris创建on ES外表(社区正在开发自动同步建表)
3.4.1 贡献
动态分区小时支持: https://github.com/apache/incubator-doris/pull/4514 DOE解决查询路由异常: https://github.com/apache/incubator-doris/pull/4352 multi fields在多text类型情况下空指针异常:https://github.com/apache/incubator-doris/pull/4300
3.4.2 Tips
routine load参数问题,主要关注desired_concurrent_number并发数,max_batch_interval,max_batch_rows,max_batch_size,目的是增大单次导入的数据量,提高导入性能 compact参数问题,主要调整cumulative_compaction_num_threads_per_disk、base_compaction_num_threads_per_disk、min_compaction_failure_interval_sec并且在代码中对因为没拿到锁的异常进行过滤,目的是提高compact频率,加快compact速度,减少小文件的产生 高并发下的所有fe hang死问题,主要调整fragment_pool_thread_num_max, fragment_pool_thread_num_min,fragment_pool_queue_size,过小的fragment_pool_thread会导致fragment死锁 提高高并发查询性能,高并发下需要降低每个查询的资源使用,主要降低doris_scanner_queue_size、doris_scanner_thread_pool_thread_num,避免创建过多scanner线程
3.4.3 报表引擎适配升级
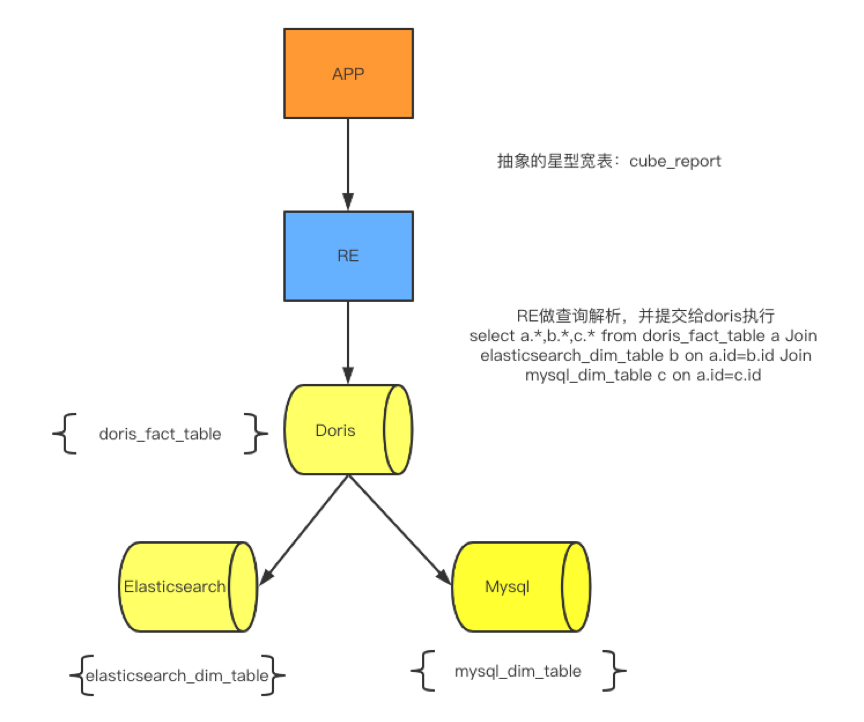
抽象基于Doris的星型模型虚拟cube表
适配cube表查询解析,智能下推
支持灰度上线
4 线上表现
4.1 查询响应时间
4.1.1 事实表查询表现对比
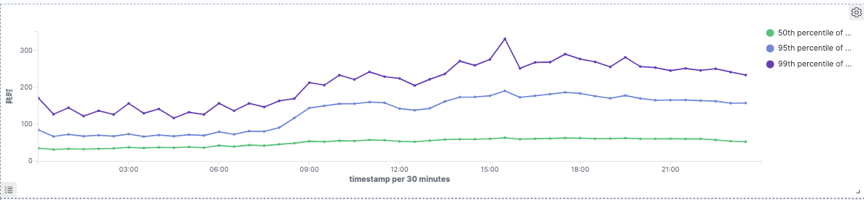
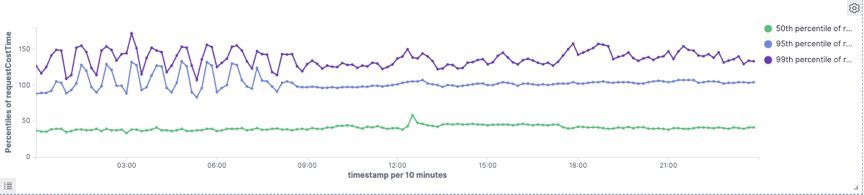
4.1.2 Join场景下cube表查询表现对比
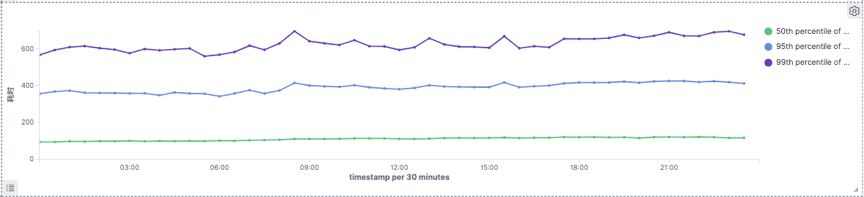
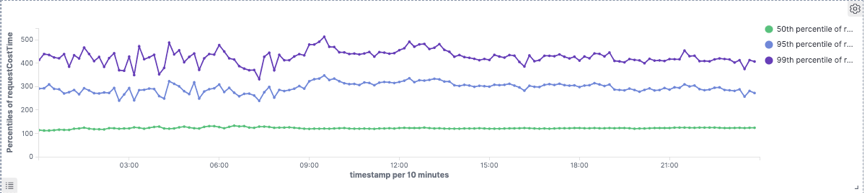
整体p99耗时下降35%左右
资源节省50%左右
去除报表引擎内部Mem Join的复杂逻辑,下沉至Doris通过DOE实现,在大查询场景下(维表结果超过10W,性能提升超过10倍,10s->1s)
更丰富的查询语义(原本Mem Join实现比较简单,不支持复杂的查询)
5 总结与未来规划

百度数据仓库Palo
基于 Apache Doris 的企业级数据仓库托管服务
全新UI支持,更有新用户0元试用3个月优惠活动
登陆百度智能云官网搜索Palo,马上试用!

📣百度 Palo/Doris 团队,诚邀对开源软件、分布式数据库感兴趣的小伙伴们
我们虚位以待!
简历发送至:talent-palo@baidu.com
欢迎扫码关注:

Apache Doris(incubating)官方公众号
相关链接:
Apache Doris官方网站:
http://doris.incubator.apache.org
Apache Doris Github:
https://github.com/apache/incubator-doris
Apache Doris 开发者邮件组:
dev@doris.apache.org

