




6月29日,Doris有幸得到中国信通院云大所、大数据技术标准推进委员会的支持,在中国信通院举行了0.11.0新版本预览线下沙龙。各位嘉宾都带来了干货满满的分享。关注Doris官方公众号,后台回复“0629”即可获取各位嘉宾分享PPT及现场录像。
今天是Doris的Contributor徐小冰同学代表搜狐带来的关于Apache Doris (incubating)Parquet文件读取的设计与实现。

所有需求的推动都基于真实的业务痛点。搜狐在Hadoop上的文件主要存储为Parquet。
Parquet有如下优势:
列式存储,压缩比高(RLE、字段编码等),查询效率高(列pruning,block filter)
Spark/Impala/Hive都支持(ORC Impala最新版本才支持)
而Doris只支持CSV格式。因此Parquet文件的读取流程就需要两步:
通过相关命令行或者工具将数据表导出到csv文件中
通过Doris load命令进行导入
这种方式的问题在于一方面CSV默认换行符是\n,如果数据中包含该\n会导致load失败。并且整体效率不高。因此,Doris支持Parquet读取,势在必行。
Load流程概览
首先来了解一下load流程。Doris的整体架构如图所示。
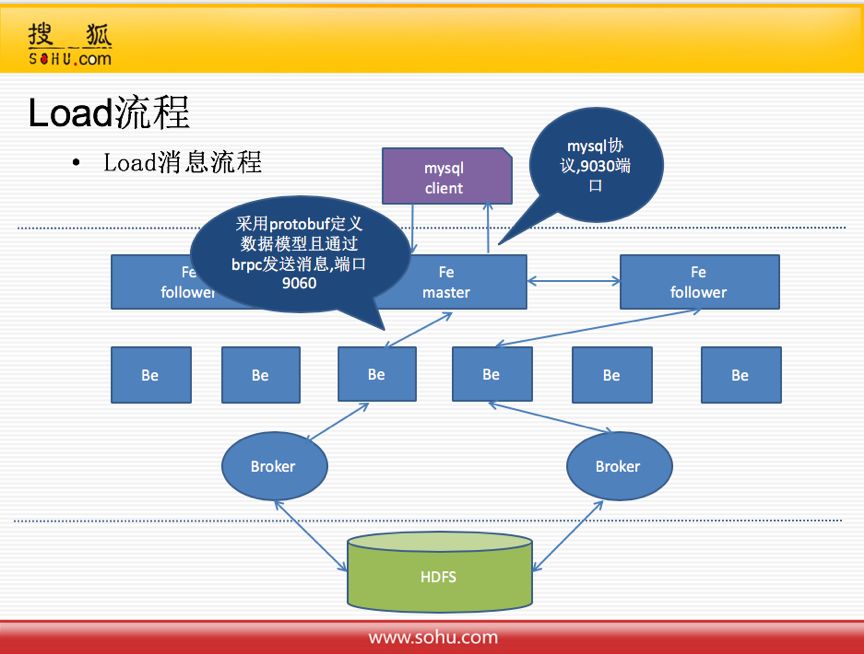
首先通过MySQL Client和MySQL协议,将load请求下发到FE master上。MySQL协议是异步的,执行完成后就会直接返回给MySQL client。
如果导入多个文件,可能会需要在FE进行负载均衡,即分发给其他的FE(FE follower),FE会从BE中选择来处理,BE会分别通过broker读取HDFS,由BE进行处理。
Load流程
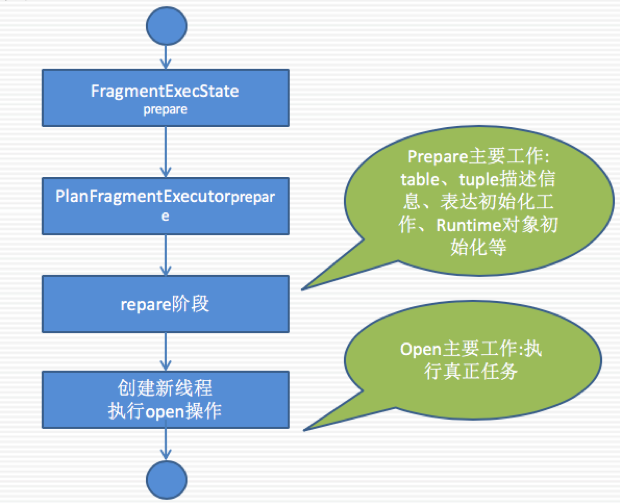
Load-Prepare流程
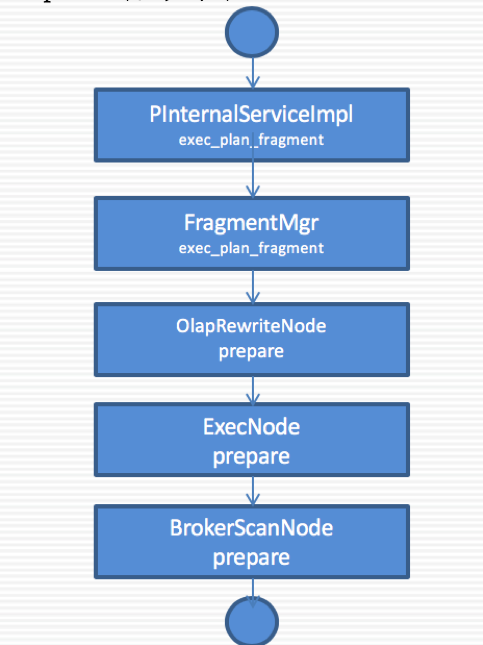
Load-Open流程
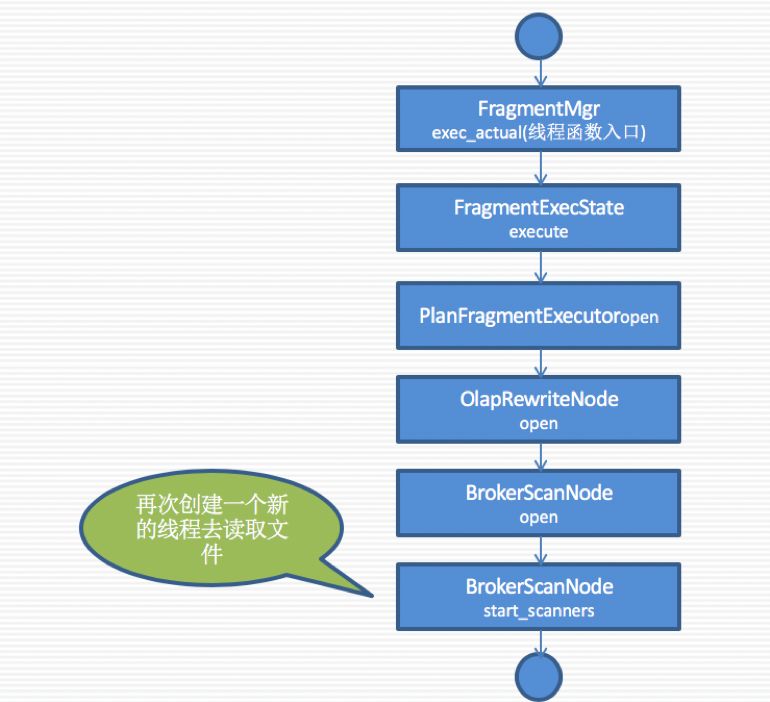
Load-Scanner流程
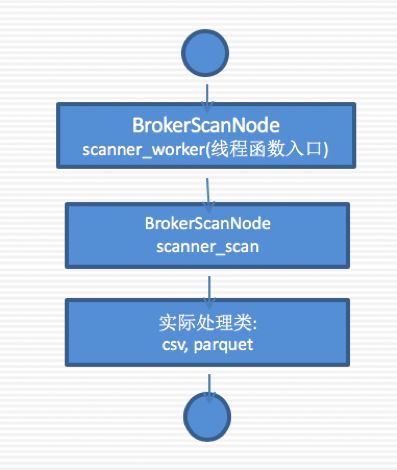
使用方式
导入指定文件
显示指定文件格式为:parquet,指定语句为:
FORMAT AS "parquet"
如若缺省则按照导入文件后缀名判断。
具体示例:
LOAD LABEL mydatabase.load_test1(DATA INFILE("hdfs://127.0.0.1:8020/tmp/xuxb/000444abc_0")INTO TABLE parquet_tableFORMAT AS "parquet"(col_a, col_b, col_c))WITH BROKER broker_parquet;
导入指定目录
同时也支持指定目录,指定语句同样为:
FORMAT AS "parquet"
通过DATA INFILE 后的/*来指定目录文件
DATA INFILE("hdfs://127.0.0.1:8020/tmp/xuxb/abc/*")
具体示例:
LOAD LABEL mydatabase.load_test1(DATA INFILE("hdfs://127.0.0.1:8020/tmp/xuxb/abc/*")INTO TABLE parquet_tableFORMAT AS "parquet"(col_a, col_b, col_c))WITH BROKER broker_parquet;
存在分区字段
对于分区字段,在Parquet文件中是不存在的,在这种情况下应该如何应用?
例如id,type是两个分区字段,在Parquet文件中不存在该列信息,首先创建Doris表如下,将id,type存在Doris表中:
CREATE TABLE demo_mem_infos(id INT, #分区字段 存在Doris表中type INT, #分区字段 存在Doris表中col_a VARCHAR(128),col_b VARCHAR(128),col_c VARCHAR(128))ENGINE=olapAGGREGATE KEY(`col_a`,`col_b`,`col_c`)DISTRIBUTED BY HASH(id) BUCKETS 25PROPERTIES ("storage_type"="column","replication_num" = "1");
Load的写法如下:
LOAD LABEL mydatabase.load_test1(DATA INFILE("hdfs://127.0.0.1:8020/tmp/id=100/type=10/*")INTO TABLE demo_mem_infosFORMAT AS "parquet"(col_a,col_b,col_c)set (id=default_value("100"),type=default_value("10")))WITH BROKER broker_parquet;
其中,在DATA INFILE中进行说明:
DATA INFILE("hdfs://127.0.0.1:8020/tmp/id=100/type=10/*")
并指定导入方式:
FORMAT AS "parquet"
并用set语句对这两个分区字段进行默认值的设置
set (
id=default_value("100"),
type=default_value("10")
)
即可完成导入。
导入状态
在导入过程中,通过show load查看状态, 因为Parquet压缩比比较高,可能会出现内存溢出问题:
报错:
type:ETL_RUN_FAIL; msg:Broker etl failed: Memory limit exceeded
可在执行load之前执行如下命令:
set exec_mem_limit = 64424509440; #单位为字节, 可根据实际情况进行设置。
可参考:FAQ
https://github.com/apache/incubator-doris/wiki/Doris-FAQ
Arrow库的引入
在实现读取Parquet文件的过程中引入了第三方库Arrow:
代码地址: https://github.com/apache/arrow
引入Arrow库的原因有几点:
Arrow接口抽象度非常高,只需要写少量代码就可读取parquet文件
开发周期短,不用自己维护相关数据结构以及内存
具体的代码展示如下:
对现有的scanner对象进行抽象,定义抽象类BaseScanner。
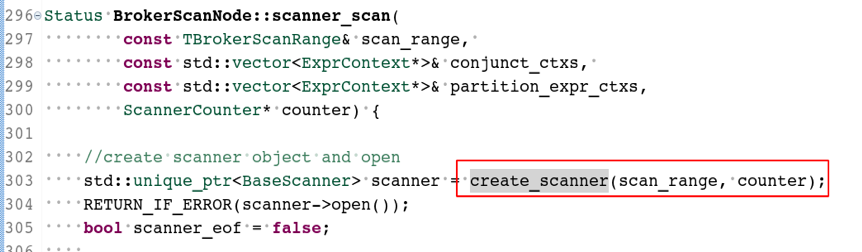
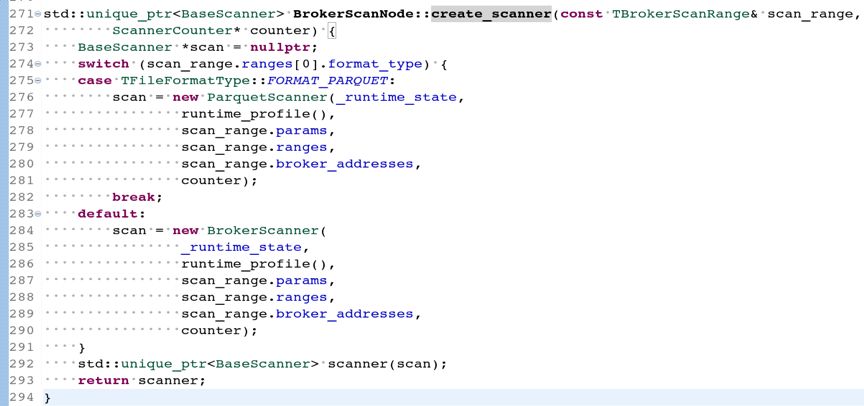
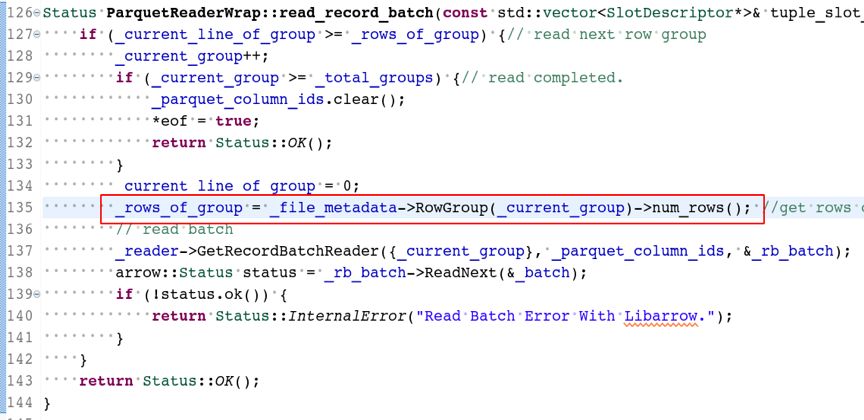
读取RowGroup效率提升的实现
在开发中总共有两个版本,第一个版本效率非常低。于是深入研究了Parquet文件的格式。Parquet由多个RowGroup组成, 优化后每次读取一个完整RowGroup,大大提升了效率。
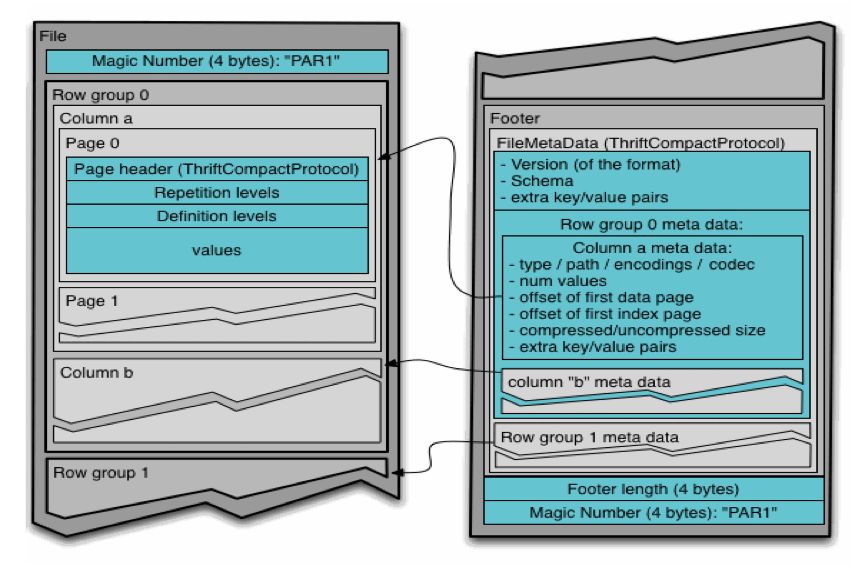
在实现上,先去调取文件含有多少个RowGroup,然后循环遍历,一次只读一个,提高了效率。
测试结果
导入27G的一张表,测试结果如下:

存在问题
内存过高
主要原因:由于Doris要做排序相关操作,目前版本(0.10.0)实现是把所有数据读到内存中,在做快排。
后续解决方案排序算法改为外排序。
varchar类型最大支持65535。如果存储一篇文章内容可能无法满足。
性能优化
Arrow接口不熟悉,第一版功能导入2G数据花费2个小时没有完成。通过BE log中profile信息发现网络io性能不佳,重新阅读Arrow源码+Arrow ut, 将实现方式改为每次读取一个完整RowGroup(主要优化点)
第二版完成后,性能任然不达标,通过ut+perf+火焰图,定位发现map find为性能瓶颈点,优化代码后显著提升。
代码贡献
将libarrow等相关第三方库编译加入到thirdparty中:
https://github.com/apache/incubator-doris/pull/114
将相关实现提交be/fe/fs_broker中
解决Doris两个小问题
内存泄露问题
https://github.com/apache/incubator-doris/pull/1244
Mysql8.0连接Fe失败
https://github.com/apache/incubator-doris/pull/1349
此次沙龙我们有幸邀请到了来自一点资讯、京东、搜狐、百度智能云的技术大牛带来他们的应用实践和开发分享。
其他嘉宾的分享会在近日放出,欢迎关注Apache Doris(incubating)官方公众号,后台回复“0629”即可获取各位嘉宾分享PPT及现场录像。
欢迎扫码关注:

Apache Doris(incubating)官方公众号
相关链接:
Apache Doris官方网站:
http://doris.incubator.apache.org
Apache Doris Github:
https://github.com/apache/incubator-doris
Apache Doris Wiki:
https://github.com/apache/incubator-doris/wiki
Apache Doris 开发者邮件组:
dev@doris.apache.org
