




1.前言
文本分词与词频统计是中文文本分析的重要内容,也是主题分析和情感分析的基础,因此如何分词以及改进分词效果是进行文本分析的关键。jiebaR包是R语言中进行文本分析一个十分方便的package,能够对中文文本进行有效处理,此外通过能够通过添加自定义词以及去停用词功能,能够进一步修改和完善分词效果,最后可以结合dplyr包进行词频统计,并且利用绘图函数进行词云图、柱状图、扇形图等图形绘制。
1.1当前网上相关教程存在的一些问题
多数教程以一个句子为例,但在做研究过程中,我们往往导入的是一个txt文本或者说是一个Excel文件; 对停用词、自定义词关注较少,分词结果的好坏在很大程度上取决于停用词和自定义词; 缺乏丰富的展示方法,往往只有一个词云图,除了词云图外还可以进一步绘制柱状图以及饼图等多种图形。
1.2本文主要解决的问题
以txt文本数据和Excel数据为例,利用jiebaR进行分词,并导出分词结果; 在初步分词结果的基础上,加载自定义词表与去停用词表,进一步优化分词结果; 利用dplyr中的arrange函数将分词结果进行排序,并以csv文件进行导出; 利用wordcloud2、RColorBrewer等多个包或绘图函数对分词结果进行可视化:包括词云图、柱状图、饼图。
1.3 开始前的准备
以福建省2020年政府工作报告为例,文本可在网上自行复制,保存到txt中,并另存为utf-8格式; 在R语言中安装以下运行过程中需要用到的包。
install.packages("jiebaR")
install.packages("dplyr")
install.packages("wordcloud2")
install.packages("RColorBrewer")
2 正文部分
2.1初步分词
设置工作路径、加载包及读取数据(注意文件要放在工作路径下)
setwd("C:\\Users\\Acer\\Desktop")
library(jiebaR)
library(dplyr)
data.txt <- scan("政府工作报告.txt", what = '', sep='\n', encoding = "UTF-8")
设置分词函数及进行初步分词
demo.engine1 <- worker()
#进行分词
demo.words <- segment(data.txt, demo.engine1)
#查看1~300个分词结果,如果不加[1:300]则为查看所有分词结果
demo.words[1:300]

对分词后的词频进行统计
#词频统计
demo.wordsfreq <- freq(demo.words)
#利用arrange函数对词频进行降序,并查看前30个分词结果
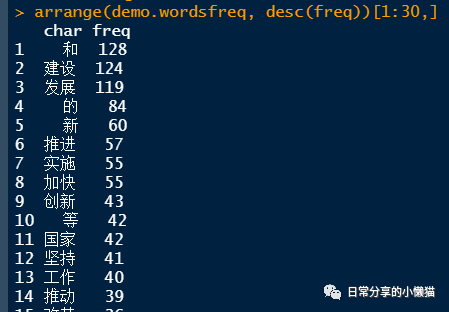
arrange(demo.wordsfreq, desc(freq))[1:30,]
小插曲:freq函数与arrange函数用法
demofreq <- freq(c("a","a","b", "c","c","d", "a"))#输入一个向量
demofreq #查看统计结果
arrange(demofreq, freq) #arrange函数第一个参数为数据,第二个参数为根据哪个变量进行排序,默认为升序
arrange(demofreq, -freq) #加个负号表示降序
arrange(demofreq, desc(freq)) #或者使用desc函数也表示降序
以txt格式导出分词文件
#options函数表示设置打印的最大行数
options(max.print=1000000)
capture.output(demo.words, file = "demo.words.txt")

以csv格式导出分词结果
demo.freqtop300 <- arrange(demo.wordsfreq, -freq)[1:300,]#[1:300,]表示提取排名前300位的词语
write.csv(demo.freqtop300, file = "demo.freqtop300.csv", row.names = FALSE)
| char | freq |
|---|---|
| 和 | 128 |
| 建设 | 124 |
| 发展 | 119 |
| 的 | 84 |
| 推进 | 57 |
| 加快 | 55 |
| 实施 | 55 |
| 新 | 54 |
| ..... | ...... |
2.2 对分词结果进行改进
通过对分词文件以及词频的查看,可以发现,存在一些如”和“、”的“等无意义的单个词,以及存在部分数字,此时,我们可以将这些需要去除的字或词加入到停用词表中;此外,也有一些词可能并没有分出来,如”一带一路“、”新时代“、”脱贫攻坚“等,此时需要我们将未分出来的词添加到自定义词表中,从而实现精确分词。首先需要在工作路径下建立两个txt文档,一个命名为user,一个命名为stopwords,并保存为utf-8格式,其中具体内容如下(另外也可以根据需要自己不断进行添加和优化)。
自定义词表与停用词表

通过去停用词以及自定义词对分词结果做进一步的优化
data.txt <- scan("政府工作报告.txt", what = '', sep='\n', encoding = "UTF-8")#导入数据
engine1 <- worker(user = "user.txt",stop_word ="stopwords.txt")#在工作路径下建立两个文件,一个为自定义词表,一个为停用词表
words <- segment(data.txt, engine1)
words[1:100]
words.freq <- freq(words)
arrange(words.freq, desc(freq))[1:30,]
#导出分词文件
options(max.print=1000000)
capture.output(words, file = "My file.txt")
#导出词频文件
words.freqtop300 <- arrange(words.freq, -freq)[1:300,]#[1:300,]表示提取排名前300位的词语
write.csv(words.freqtop300, file = "words.freqtop300.csv", row.names = FALSE)
| char | freq |
|---|---|
| 建设 | 124 |
| 发展 | 119 |
| 推进 | 57 |
| 加快 | 55 |
| 实施 | 55 |
| 新 | 54 |
| ..... | ...... |
2.3 对高频词进行可视化
1.利用wordcloud2包绘制词云图对高频词进行可视化
library(wordcloud2)
#选择前100个高频词进行词云图绘制
word.freq_new <- words.freqtop300[1:100, ]
wordcloud2(word.freq_new, size = 1, minRotation = -pi/6, maxRotation = -pi/6,rotateRatio = 1)

关于如何利用wordcloud2进行词云图绘制,可进一步参考之前的推文,R语言绘图|利用wordcloud2包绘制中文词云图
2.利用barplot函数绘制柱状图对高频词进行可视化
#绘制排名前20的高频词:其中barplot第一个参数为数据源,第二个参数为标签
barplot(word.freq_new$freq[1:20], names.arg = word.freq_new$char[1:20])
#对柱状图颜色进行修改,指定颜色
barplot(word.freq_new$freq[1:20], names.arg = word.freq_new$char[1:20], col = "lightblue")
#对柱状图颜色进行修改,生成彩虹色
barplot(word.freq_new$freq[1:20], names.arg = word.freq_new$char[1:20], col = rainbow(20))
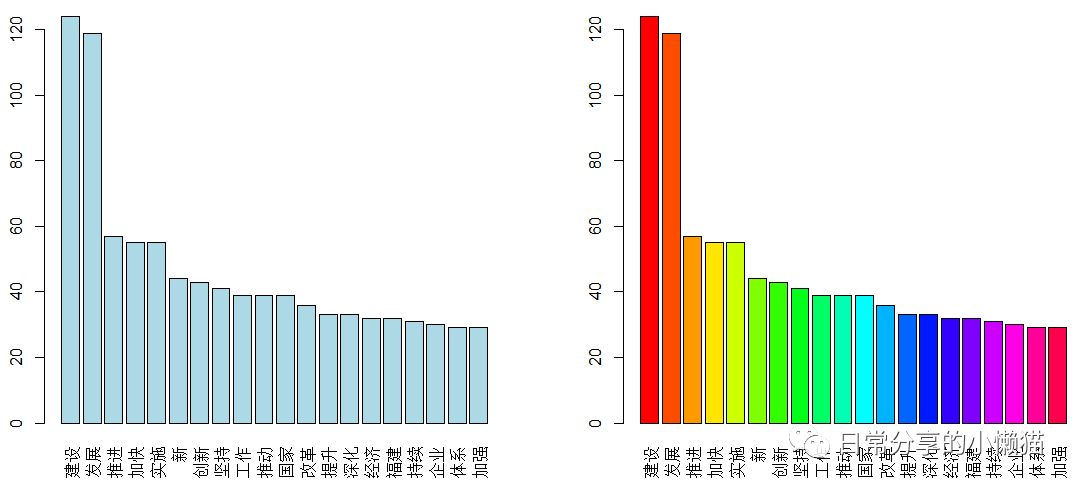
此外还可以利用RColorBrewer包对颜色进一步进行填充。关于RColorBrewer包的使用,可进一步参考之前的推文,R语言绘图|如何调用RColorBrewer包对图形颜色进行修改
library(RColorBrewer)
#生成颜色
newpalette1 <- colorRampPalette(brewer.pal(8,"YlGnBu"))(30)
newpalette2 <- colorRampPalette(brewer.pal(8,"Purples"))(30)
#进行颜色填充
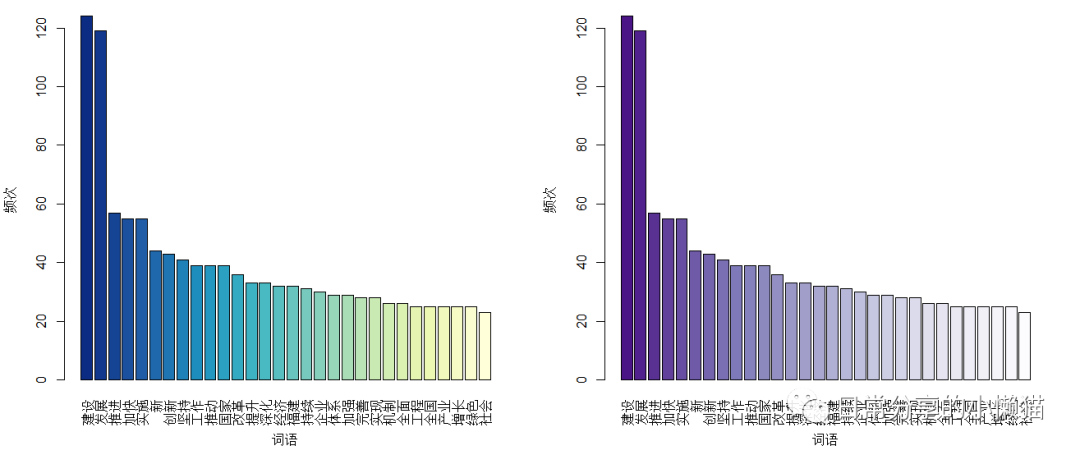
barplot(word.freq_new$freq[1:30], names.arg = word.freq_new$char[1:30],
xlab = "词语", ylab = "频次", las = 3,
col = rev(newpalette1))
barplot(word.freq_new$freq[1:30], names.arg = word.freq_new$char[1:30],
xlab = "词语", ylab = "频次", las = 3,
col = rev(newpalette2))
#部分参数含义:xlab表示y轴标题,ylab表示y轴标题,las表示标签垂直,col表示颜色,rev函数表示对颜色进行反转。
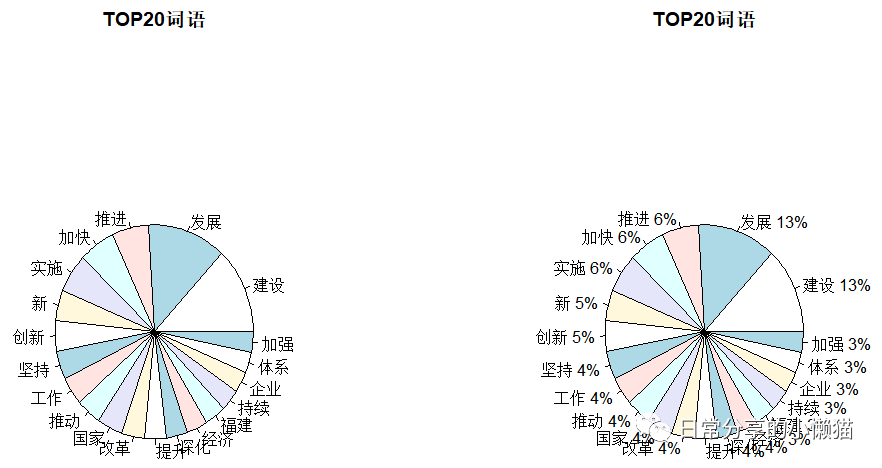
3.利用pie函数绘制饼图对高频词进行可视化
#饼图
number <- word.freq_new$freq[1:20]#提取数值,[1:20]表示提取前20个高频词数值
label <- word.freq_new$char[1:20]#提取标签,示提取前20个高频词标签
#不带比例的饼图
pie(number, label,main = "TOP20词语")
#绘制带比例的饼图
pie.pct <- round(number/sum(number)*100)#计算比例
pie.label <- paste(label," ",pie.pct,"%" , sep="")#标签设置
pie(number, pie.label, main = "TOP20词语")#绘制饼图,并添加图标题
3 其他
分词难点主要在于对数据的清洗,要去掉意义不大的词,以及建立适合当前文本所需要的词库。 相关的参数设置可进一步阅读jiebaR的官方帮助文档,特别是worker()函数中有许多参数定义,可以参考jiebaR官方帮助文档[1]结合网上的解读。
附 csv格式的数据导入
demo.csv <- read.csv("政府工作报告.csv", stringsAsFactors = FALSE)
demo.csv[1:5, ]#查看1到5行数据
demo.engine1.csv <- worker()#设置分词工作所需要的函数
words.csv <- segment(demo.csv$data, demo.engine1.csv)#进行分词
words.csv[1:100]#查看分词
words.csvfreq <- freq(words.csv)#对词频排序
arrange(words.csvfreq , desc(freq))[1:30,]#查看前30位词频
csv文件格式

参考资料
jiebaR: https://cran.r-project.org/web/packages/jiebaR/jiebaR.pdf
