




KNN(K Nearest Neighbors)算法是有监督机器学习算法的一种。该算法简单有效,训练速度快,是广泛使用的一种分类算法。KNN算法主要通过对距离的度量及选择合适的K值来对样本进行分类。下图是一个简单KNN算法的示意图,以食物的甜度(sweet)和脆度(crunchy)两个特征为基础,计算西红柿与其他水果在特征值上的距离,选择合适的K值,进而判断西红柿所属类别。本文主要内容参考Lantz的Machine Learning With R[1]。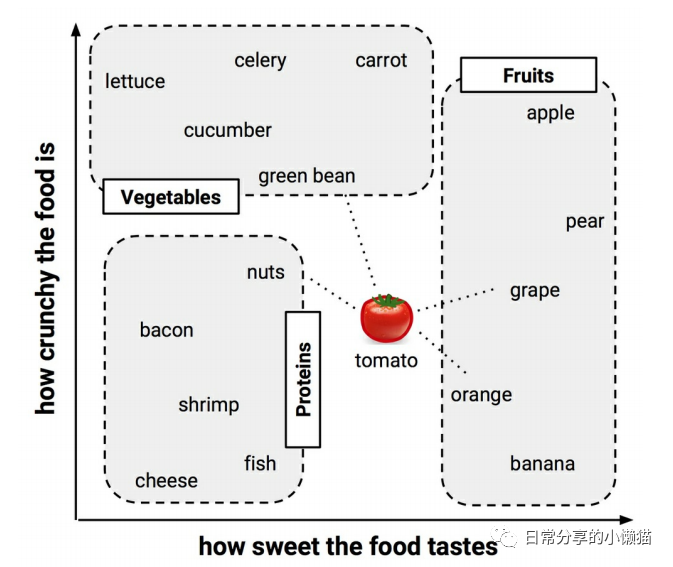
1、数据准备
使用书中提供的breast cancer的数据集。该数据集除去ID标识外,共包含31个特征,其中1个为breast cancer的诊断结果,分为Benign和Malignant两种类别,其余30个特征为对应的测量结果,为数值型变量。使用KNN算法来根据breast cancer各特征测量结果自动识别癌细胞。
library(class)
library(gmodels)
setwd("C://Users//Acer//Desktop")
wbcd <- read.csv("wisc_bc_data.csv")
2、数据探索
在进行KNN算法前,首先需要对数据进行基本探索。关于该部分内容详细介绍可参考R数据分析基础|理解数据。
View(wbcd) #查看完整表格
head(wbcd) #查看数据前几行
str(wbcd) #数据类型
summary(wbcd) #描述性概述
wbcd <- wbcd[-1] #去除首列(ID列)
table(wbcd$diagnosis) #结果变量频次
# B M
#357 212
round(prop.table(table(wbcd$diagnosis)) * 100, digits = 2) #结果变量频率
# B M
#62.74 37.26
wbcd$diagnosis <- factor(wbcd$diagnosis, levels = c("B", "M"), labels = c("Benign", "Malignant")) #标签因子化,并修改标签名称
round(prop.table(table(wbcd$diagnosis)) * 100, digits = 2) #结果变量频率
# Benign Malignant
# 62.74 37.26
summary(wbcd[c("radius_mean", "area_mean", "compactness_mean")]) #查看变量数值分布
# radius_mean area_mean compactness_mean
# Min. : 6.981 Min. : 143.5 Min. :0.01938
# 1st Qu.:11.700 1st Qu.: 420.3 1st Qu.:0.06492
# Median :13.370 Median : 551.1 Median :0.09263
# Mean :14.127 Mean : 654.9 Mean :0.10434
# 3rd Qu.:15.780 3rd Qu.: 782.7 3rd Qu.:0.13040
# Max. :28.110 Max. :2501.0 Max. :0.34540
3、数据标准化
数据探索发现,各特征之间数值差异较大,由于KNN算法在距离计算上很大程度依赖于属性特征的测量尺度,测量尺度不一最终会导致分类结果出现问题。因此需要对数据进行标准化或者规范化处理,首先以min-max规范化方法为例,对数据进行重新调整。关于数据处理可参考R数据分析|数据的标准化、规范化与对数化。
#定义min-max规范化函数
normalize <- function(x) {
return((x - min(x)) / (max(x) - min(x)))
}
wbcd_n <- as.data.frame(apply(wbcd[-1], 2, normalize))
summary(wbcd_n[c("radius_mean", "area_mean", "compactness_mean")]) #查看变量数值分布
# radius_mean area_mean compactness_mean
# Min. :0.0000 Min. :0.0000 Min. :0.0000
# 1st Qu.:0.2233 1st Qu.:0.1174 1st Qu.:0.1397
# Median :0.3024 Median :0.1729 Median :0.2247
# Mean :0.3382 Mean :0.2169 Mean :0.2606
# 3rd Qu.:0.4164 3rd Qu.:0.2711 3rd Qu.:0.3405
# Max. :1.0000 Max. :1.0000 Max. :1.0000
4、模型准备
通过规范化方法,使得所有数值都落在了0~1之间。接下来进行模型准备,创建测试集和测试集,以及对应的标签向量。由于该数据集在顺序上已被打乱,因此可按顺序选择数据,但如果数据是按照结果变量顺序排列,则需要进行随机抽样,可使用sample() 函数进行随机抽样。
#创建训练集与测试集
wbcd_train <- wbcd_n[1:469, ]
wbcd_test <- wbcd_n[470:569, ]
#训练集与测试集标签
wbcd_train_labels <- wbcd[1:469, 1]
wbcd_test_labels <- wbcd[470:569, 1]
5、模型训练
使用class包中的knn() 函数来实现KNN算法。同时,需要先指定具体的k值,k值一般从选取训练样本数的平方根开始。在本案例中,训练集中的样本数为469,则k约等于取21或者22。
sqrt(469) #训练集有469个样本,取平方根
#[1] 21.65641
wbcd_z_test_pred <- knn(train = wbcd_z_train, test = wbcd_z_test, cl = wbcd_z_train_labels, k =21)
wbcd_test_pred #返回一个向量因子,为预测集
str(wbcd_test_pred)
# Factor w/ 2 levels "Benign","Malignant": 1 1 1 1 2 1 2 1 2 1 ...
table(wbcd_test_pred)
#wbcd_test_pred
# Benign Malignant
# 63 37
6、模型评估
使用table() 函数或者CrossTable() 函数对模型的训练结果进行评估。
方法一:根据table() 函数返回的结果来看,有2个Malignant预测为了Benign,模型整体准确率为98%。
table(wbcd_test_labels,wbcd_test_pred)
# wbcd_test_pred
#wbcd_test_labels Benign Malignant
# Benign 61 0
# Malignant 2 37
方法二:使用CrossTable() 函数,关于CrossTable() 的使用可参考R数据分析基础|理解数据。
CrossTable(x = wbcd_test_labels, y = wbcd_test_pred,
prop.chisq = FALSE, prop.r = FALSE, prop.c = FALSE)
训练结果
Cell Contents
|-------------------------|
| N |
| N / Table Total |
|-------------------------|
Total Observations in Table: 100
| wbcd_test_pred
wbcd_test_labels | Benign | Malignant | Row Total |
-----------------|-----------|-----------|-----------|
Benign | 61 | 0 | 61 |
| 0.610 | 0.000 | |
-----------------|-----------|-----------|-----------|
Malignant | 2 | 37 | 39 |
| 0.020 | 0.370 | |
-----------------|-----------|-----------|-----------|
Column Total | 63 | 37 | 100 |
-----------------|-----------|-----------|-----------|
7、模型改进
方法一:使用z-score标准化
模型准备
wbcd_z <- as.data.frame(scale(wbcd[-1])) #数据标准化
wbcd_z_train <- wbcd_z[1:469, ] #训练集
wbcd_z_test <- wbcd_z[470:569, ] #测试集
wbcd_z_train_labels <- wbcd[1:469, 1] #训练集标签
wbcd_z_test_labels <- wbcd[470:569, 1] #测试集标签
wbcd_z_test_pred <- knn(train = wbcd_z_train, test = wbcd_z_test, cl = wbcd_z_train_labels, k =21) #模型训练
CrossTable(x = wbcd_z_test_labels, y = wbcd_z_test_pred,
prop.chisq = FALSE, prop.r = FALSE, prop.c = FALSE) #查看结果
训练结果。模型准确率为95%。
Cell Contents
|-------------------------|
| N |
| N / Table Total |
|-------------------------|
Total Observations in Table: 100
| wbcd_z_test_pred
wbcd_z_test_labels | Benign | Malignant | Row Total |
-------------------|-----------|-----------|-----------|
Benign | 61 | 0 | 61 |
| 0.610 | 0.000 | |
-------------------|-----------|-----------|-----------|
Malignant | 5 | 34 | 39 |
| 0.050 | 0.340 | |
-------------------|-----------|-----------|-----------|
Column Total | 66 | 34 | 100 |
-------------------|-----------|-----------|-----------|
方法二:使用不同的k值
模型准备。以min-max规范化的数据为例,替换K值。
wbcd_test_pred_15 <- knn(train = wbcd_train, test = wbcd_test, cl = wbcd_train_labels, k = 15)
CrossTable(x = wbcd_test_labels, y = wbcd_test_pred_15,
prop.chisq = FALSE, prop.r = FALSE, prop.c = FALSE)
训练结果。模型准确率为97%。
Cell Contents
|-------------------------|
| N |
| N / Table Total |
|-------------------------|
Total Observations in Table: 100
| wbcd_test_pred_15
wbcd_test_labels | Benign | Malignant | Row Total |
-----------------|-----------|-----------|-----------|
Benign | 61 | 0 | 61 |
| 0.610 | 0.000 | |
-----------------|-----------|-----------|-----------|
Malignant | 3 | 36 | 39 |
| 0.030 | 0.360 | |
-----------------|-----------|-----------|-----------|
Column Total | 64 | 36 | 100 |
-----------------|-----------|-----------|-----------|
其他
关于KNN算法的原理部分可进一步阅读Lantz的Machine Learning With R及相关文献资料。本文数据可在后台回复【20220226】获得。
如有帮助请多多点赞哦!
参考资料
Lantz B, Machine Learning With R: https://www.packtpub.com/product/machine-learning-with-r-third-edition/9781788295864.
