




首位度(Primacy Index)常用来反映地理要素的集中程度。本文主要以R语言为例,展示首位度的计算过程,公式和数据主要参考陈昆仑等(2022)在经济地理发表的 《中国马拉松网络关注的时空特征及影响因素》 一文。
1、公式
式中:P为某地理要素的首位度,X1和X2分别为规模最大和第二大要素的数值分布,通常,2 >首位度> 1,说明首位分布不显著;4 ≥首位度> 2,则为中度首位分布;首位度> 4,则为高度首位分布(张城铭等,2019)。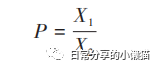
2、R语言计算
以该论文中31省(治区、直辖市)关于马拉松的网络关注度数值为例,展示首位度的计算过程:
setwd("C:/Users/Acer/Desktop")
demodata <- readxl::read_xlsx("HHI-demodata.xlsx")
head(demodata)
# A tibble: 6 x 7
# province y2014 y2015 y2016 y2017 y2018 y2019
# <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
#1 广东 125421 174045 189345 181965 198578 201363
#2 北京 121696 174023 164396 169348 183981 175878
#3 江苏 98009 135829 137919 154870 163862 167856
#4 浙江 92963 130357 129607 140803 144802 148361
#5 上海 91885 119256 122119 121987 134156 135656
#6 山东 83496 108875 111300 123794 135045 146472
P_value <- apply(demodata[2:7], MARGIN = 2, function(x)
sort(x, decreasing = TRUE)[1]/sort(x, decreasing =TRUE)[2]
) #计算
P_value #首位度
y2014 y2015 y2016 y2017 y2018 y2019
1.030609 1.000126 1.151762 1.074503 1.079340 1.144902
3、其他
演示数据可后台回复20220414获得。其他方法可参考如下文章:
文章转载自日常分享的小懒猫,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
