




Table of Contents
一. 消费者信心指数数据分析
1.1 数据源介绍
sentiment.csv
美国消费者信心指数
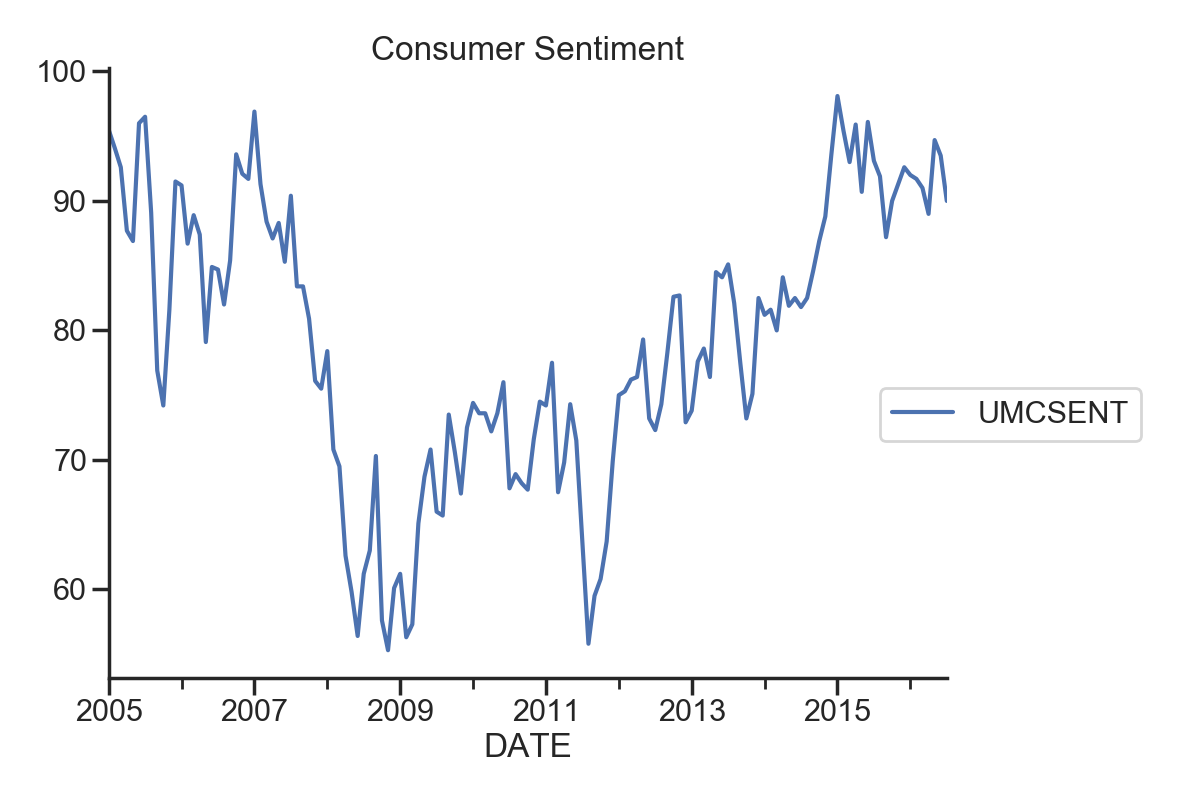
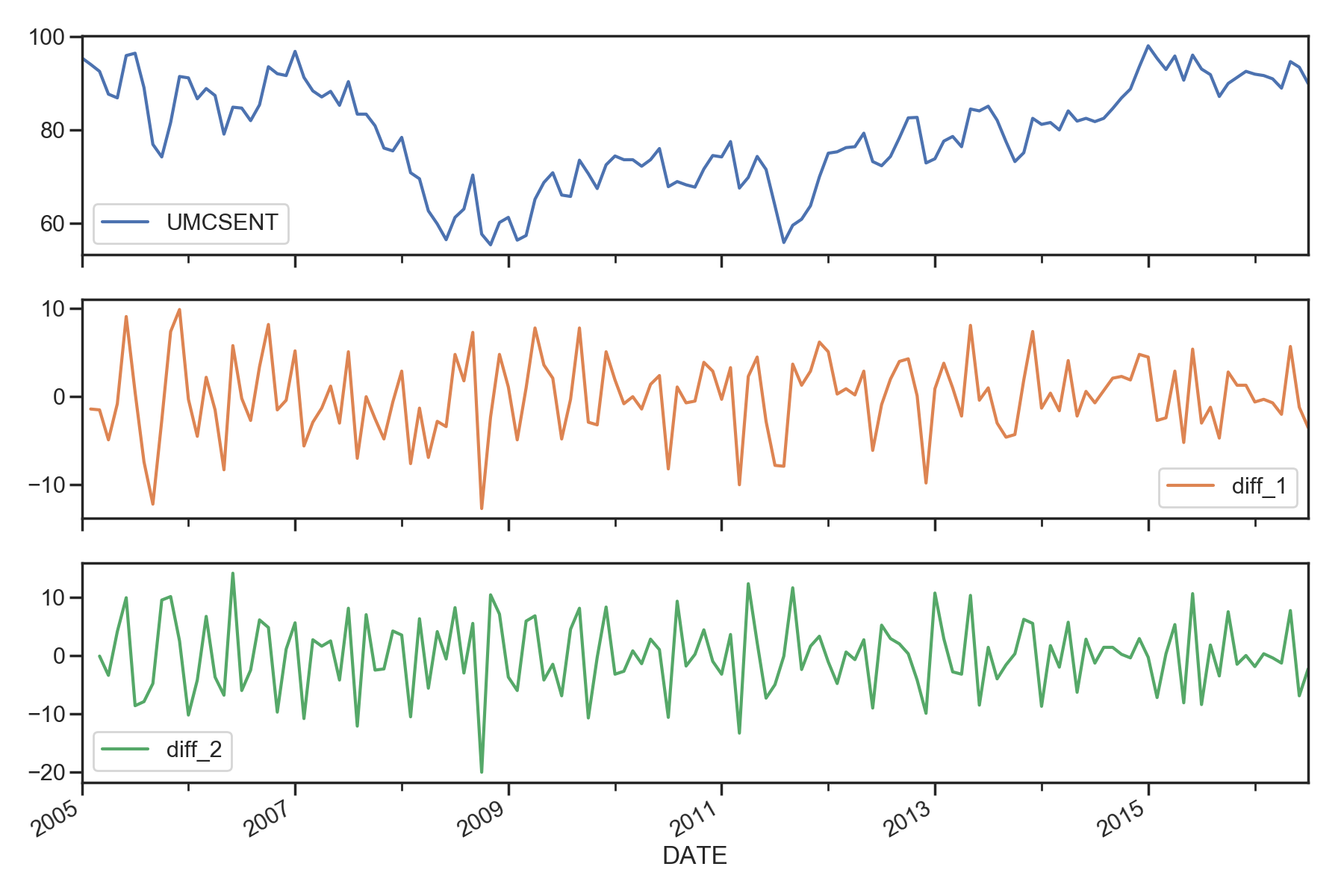
1.2 时间序列图及差分图
代码:
from __future__ import absolute_import, division, print_function
# http://www.lfd.uci.edu/~gohlke/pythonlibs/#xgboost
import sys
import os
import pandas as pd
import numpy as np
import statsmodels.api as sm
import statsmodels.formula.api as smf
import statsmodels.tsa.api as smt
import matplotlib.pylab as plt
import seaborn as sns
# 一些配置项
pd.set_option('display.float_format', lambda x: '%.5f' % x) # pandas
np.set_printoptions(precision=5, suppress=True) # numpy
pd.set_option('display.max_columns', 100)
pd.set_option('display.max_rows', 100)
sns.set(style='ticks', context='poster')
# 美国消费者信心指数
Sentiment = 'E:/file/sentiment.csv'
Sentiment = pd.read_csv(Sentiment, index_col=0, parse_dates=[0])
sentiment_short = Sentiment.loc['2005':'2016']
sentiment_short.plot(figsize=(12,8))
plt.legend(bbox_to_anchor=(1.25, 0.5))
plt.title("Consumer Sentiment")
sns.despine()
sentiment_short['diff_1'] = sentiment_short['UMCSENT'].diff(1)
sentiment_short['diff_2'] = sentiment_short['diff_1'].diff(1)
sentiment_short.plot(subplots=True, figsize=(18, 12))
del sentiment_short['diff_2']
del sentiment_short['diff_1']
fig = plt.figure(figsize=(12,8))
ax1 = fig.add_subplot(211)
fig = sm.graphics.tsa.plot_acf(sentiment_short, lags=20,ax=ax1)
ax1.xaxis.set_ticks_position('bottom')
fig.tight_layout();
ax2 = fig.add_subplot(212)
fig = sm.graphics.tsa.plot_pacf(sentiment_short, lags=20, ax=ax2)
ax2.xaxis.set_ticks_position('bottom')
fig.tight_layout();
# 散点图也可以表示
lags=9
ncols=3
nrows=int(np.ceil(lags/ncols))
fig, axes = plt.subplots(ncols=ncols, nrows=nrows, figsize=(4*ncols, 4*nrows))
for ax, lag in zip(axes.flat, np.arange(1,lags+1, 1)):
lag_str = 't-{}'.format(lag)
X = (pd.concat([sentiment_short, sentiment_short.shift(-lag)], axis=1,
keys=['y'] + [lag_str]).dropna())
X.plot(ax=ax, kind='scatter', y='y', x=lag_str);
corr = X.corr().iloc[:,:].values[0][1]
ax.set_ylabel('Original')
ax.set_title('Lag: {} (corr={:.2f})'.format(lag_str, corr));
ax.set_aspect('equal');
sns.despine();
fig.tight_layout();
# 更直观一些
def tsplot(y, lags=None, title='', figsize=(14, 8)):
fig = plt.figure(figsize=figsize)
layout = (2, 2)
ts_ax = plt.subplot2grid(layout, (0, 0))
hist_ax = plt.subplot2grid(layout, (0, 1))
acf_ax = plt.subplot2grid(layout, (1, 0))
pacf_ax = plt.subplot2grid(layout, (1, 1))
y.plot(ax=ts_ax)
ts_ax.set_title(title)
y.plot(ax=hist_ax, kind='hist', bins=25)
hist_ax.set_title('Histogram')
smt.graphics.plot_acf(y, lags=lags, ax=acf_ax)
smt.graphics.plot_pacf(y, lags=lags, ax=pacf_ax)
[ax.set_xlim(0) for ax in [acf_ax, pacf_ax]]
sns.despine()
plt.tight_layout()
return ts_ax, acf_ax, pacf_ax
tsplot(sentiment_short, title='Consumer Sentiment', lags=36);
plt.show()
测试记录:
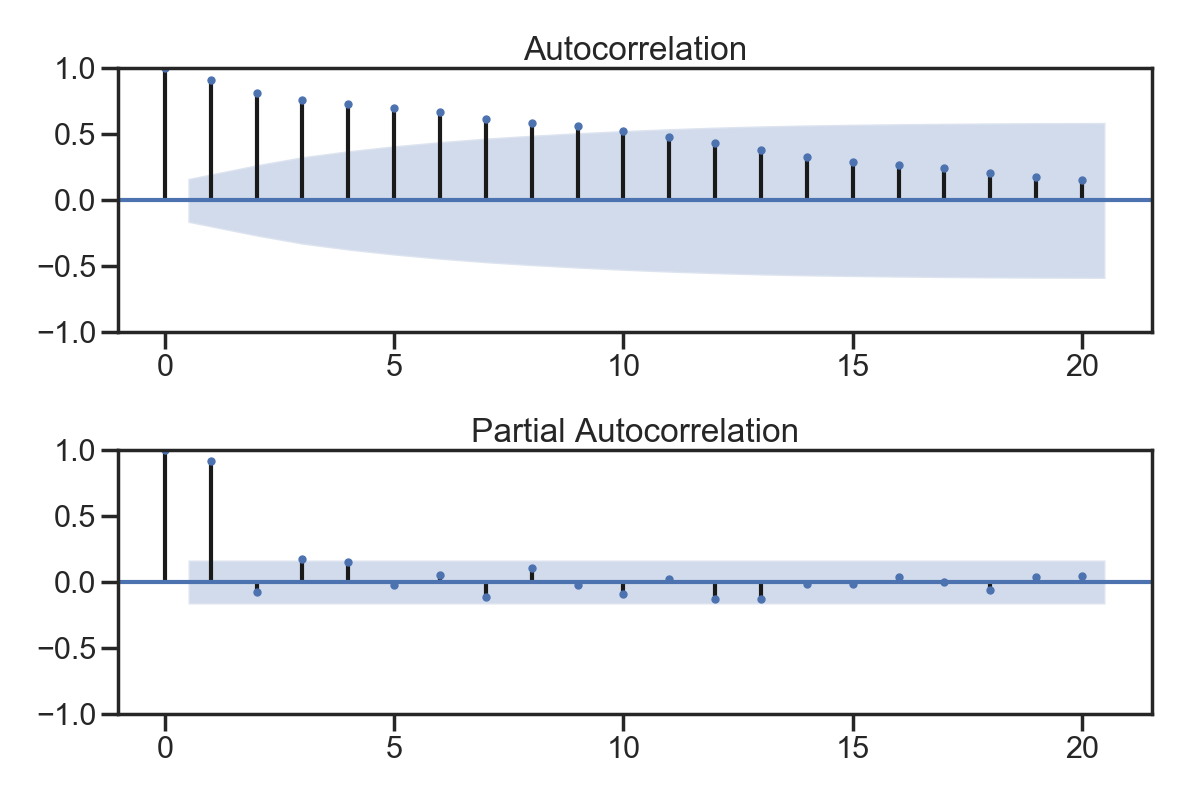
1.3 AR图
代码:
from __future__ import absolute_import, division, print_function
# http://www.lfd.uci.edu/~gohlke/pythonlibs/#xgboost
import sys
import os
import pandas as pd
import numpy as np
import statsmodels.api as sm
import statsmodels.formula.api as smf
import statsmodels.tsa.api as smt
import matplotlib.pylab as plt
import seaborn as sns
# 一些配置项
pd.set_option('display.float_format', lambda x: '%.5f' % x) # pandas
np.set_printoptions(precision=5, suppress=True) # numpy
pd.set_option('display.max_columns', 100)
pd.set_option('display.max_rows', 100)
sns.set(style='ticks', context='poster')
# 读取数据
Sentiment = 'E:/file/sentiment.csv'
Sentiment = pd.read_csv(Sentiment, index_col=0, parse_dates=[0])
sentiment_short = Sentiment.loc['2005':'2016']
# 自相关图
fig = plt.figure(figsize=(12,8))
ax1 = fig.add_subplot(211)
fig = sm.graphics.tsa.plot_acf(sentiment_short, lags=20,ax=ax1)
ax1.xaxis.set_ticks_position('bottom')
fig.tight_layout();
ax2 = fig.add_subplot(212)
fig = sm.graphics.tsa.plot_pacf(sentiment_short, lags=20, ax=ax2)
ax2.xaxis.set_ticks_position('bottom')
fig.tight_layout();
plt.show()
测试记录:
1.4 散点图
代码:
from __future__ import absolute_import, division, print_function
# http://www.lfd.uci.edu/~gohlke/pythonlibs/#xgboost
import sys
import os
import pandas as pd
import numpy as np
import statsmodels.api as sm
import statsmodels.formula.api as smf
import statsmodels.tsa.api as smt
import matplotlib.pylab as plt
import seaborn as sns
# 一些配置项
pd.set_option('display.float_format', lambda x: '%.5f' % x) # pandas
np.set_printoptions(precision=5, suppress=True) # numpy
pd.set_option('display.max_columns', 100)
pd.set_option('display.max_rows', 100)
sns.set(style='ticks', context='poster')
# 读取数据
Sentiment = 'E:/file/sentiment.csv'
Sentiment = pd.read_csv(Sentiment, index_col=0, parse_dates=[0])
sentiment_short = Sentiment.loc['2005':'2016']
# 散点图也可以表示
lags=9
ncols=3
nrows=int(np.ceil(lags/ncols))
fig, axes = plt.subplots(ncols=ncols, nrows=nrows, figsize=(4*ncols, 4*nrows))
for ax, lag in zip(axes.flat, np.arange(1,lags+1, 1)):
lag_str = 't-{}'.format(lag)
X = (pd.concat([sentiment_short, sentiment_short.shift(-lag)], axis=1,
keys=['y'] + [lag_str]).dropna())
X.plot(ax=ax, kind='scatter', y='y', x=lag_str);
corr = X.corr().iloc[:,:].values[0][1]
ax.set_ylabel('Original')
ax.set_title('Lag: {} (corr={:.2f})'.format(lag_str, corr));
ax.set_aspect('equal');
sns.despine();
fig.tight_layout();
plt.show()
测试记录:
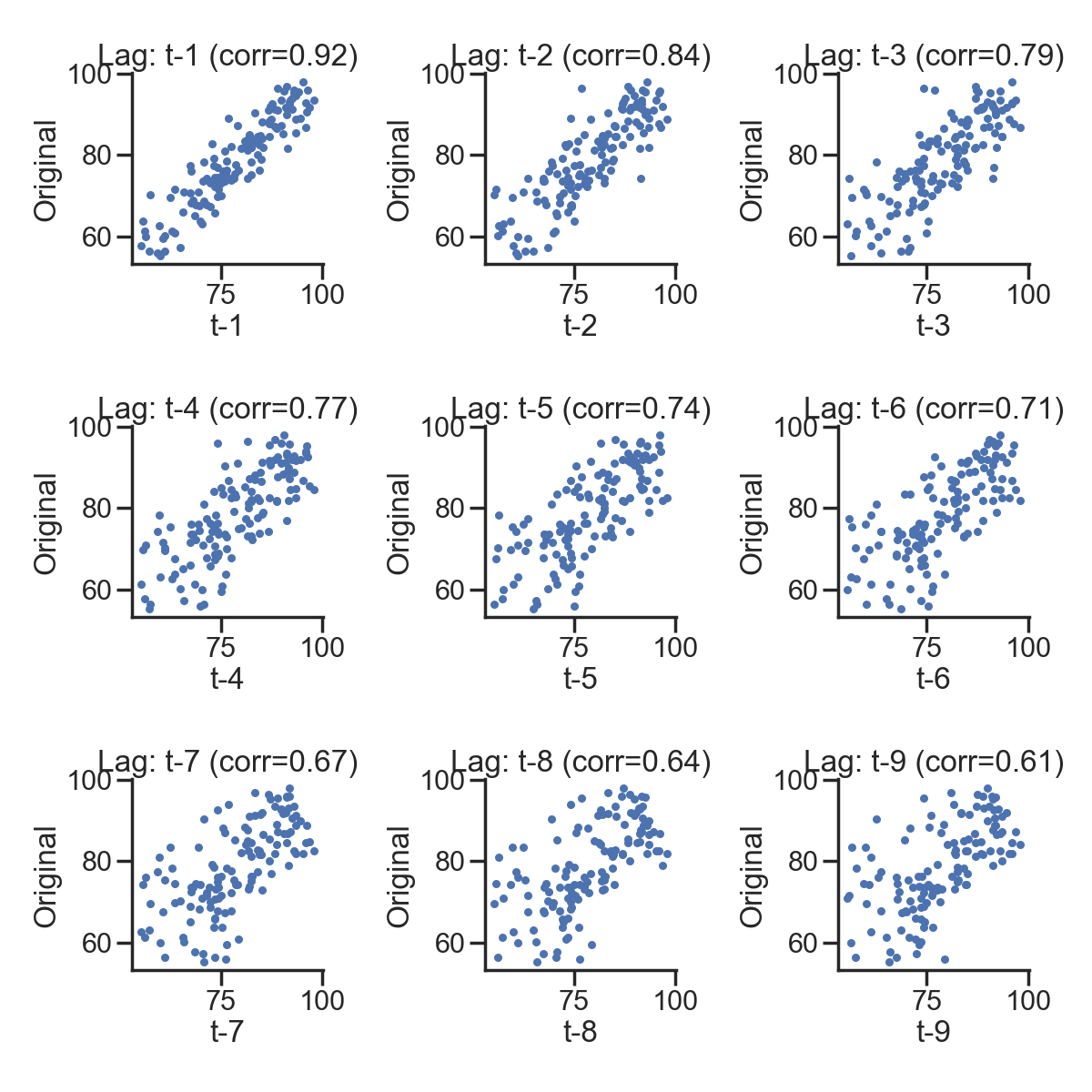
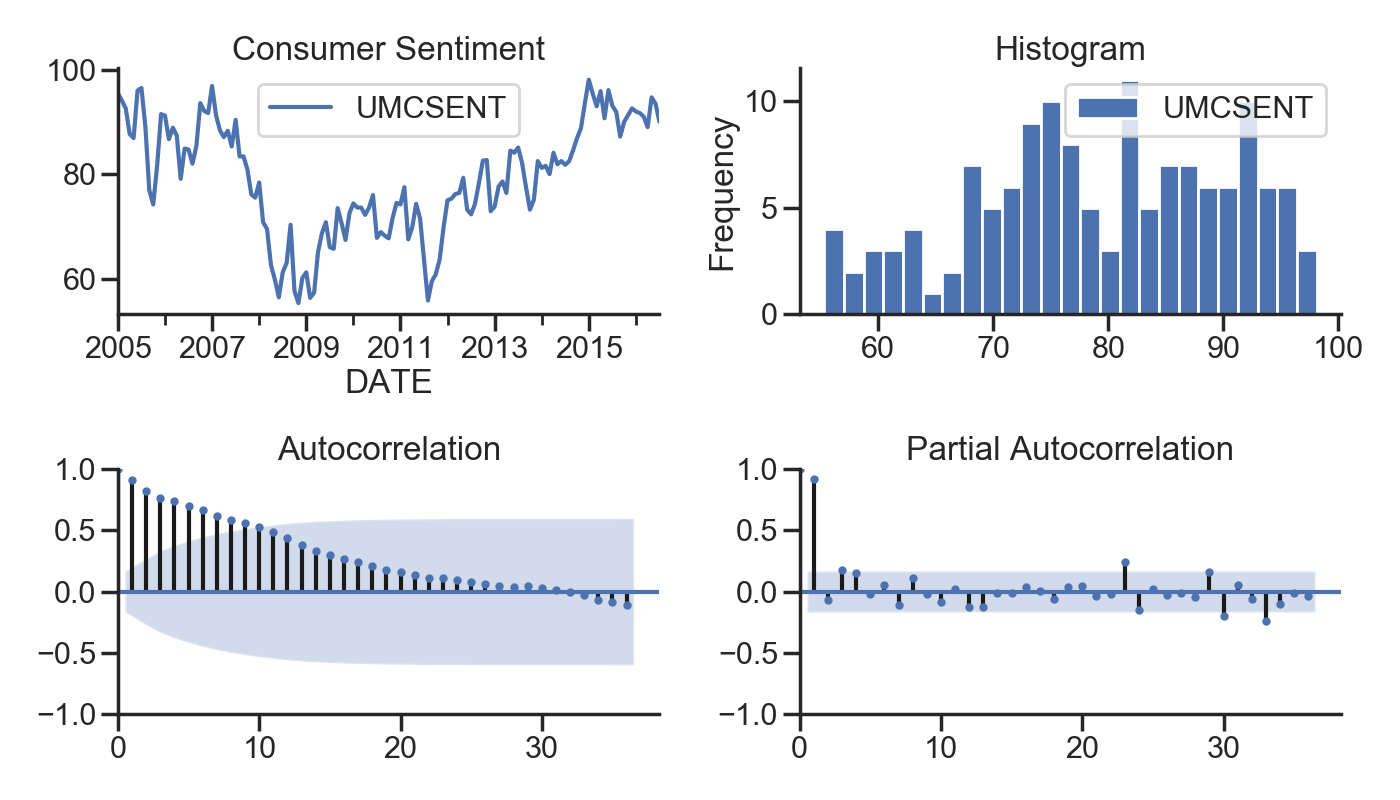
1.5 更直观的展示
代码:
from __future__ import absolute_import, division, print_function
# http://www.lfd.uci.edu/~gohlke/pythonlibs/#xgboost
import sys
import os
import pandas as pd
import numpy as np
import statsmodels.api as sm
import statsmodels.formula.api as smf
import statsmodels.tsa.api as smt
import matplotlib.pylab as plt
import seaborn as sns
# 一些配置项
pd.set_option('display.float_format', lambda x: '%.5f' % x) # pandas
np.set_printoptions(precision=5, suppress=True) # numpy
pd.set_option('display.max_columns', 100)
pd.set_option('display.max_rows', 100)
sns.set(style='ticks', context='poster')
# 读取数据
Sentiment = 'E:/file/sentiment.csv'
Sentiment = pd.read_csv(Sentiment, index_col=0, parse_dates=[0])
sentiment_short = Sentiment.loc['2005':'2016']
# 更直观一些
def tsplot(y, lags=None, title='', figsize=(14, 8)):
fig = plt.figure(figsize=figsize)
layout = (2, 2)
ts_ax = plt.subplot2grid(layout, (0, 0))
hist_ax = plt.subplot2grid(layout, (0, 1))
acf_ax = plt.subplot2grid(layout, (1, 0))
pacf_ax = plt.subplot2grid(layout, (1, 1))
y.plot(ax=ts_ax)
ts_ax.set_title(title)
y.plot(ax=hist_ax, kind='hist', bins=25)
hist_ax.set_title('Histogram')
smt.graphics.plot_acf(y, lags=lags, ax=acf_ax)
smt.graphics.plot_pacf(y, lags=lags, ax=pacf_ax)
[ax.set_xlim(0) for ax in [acf_ax, pacf_ax]]
sns.despine()
plt.tight_layout()
return ts_ax, acf_ax, pacf_ax
tsplot(sentiment_short, title='Consumer Sentiment', lags=36);
plt.show()
测试记录:
二. 参数选择
2.1 数据源介绍
series1.csv
一个标准的时间序列数据
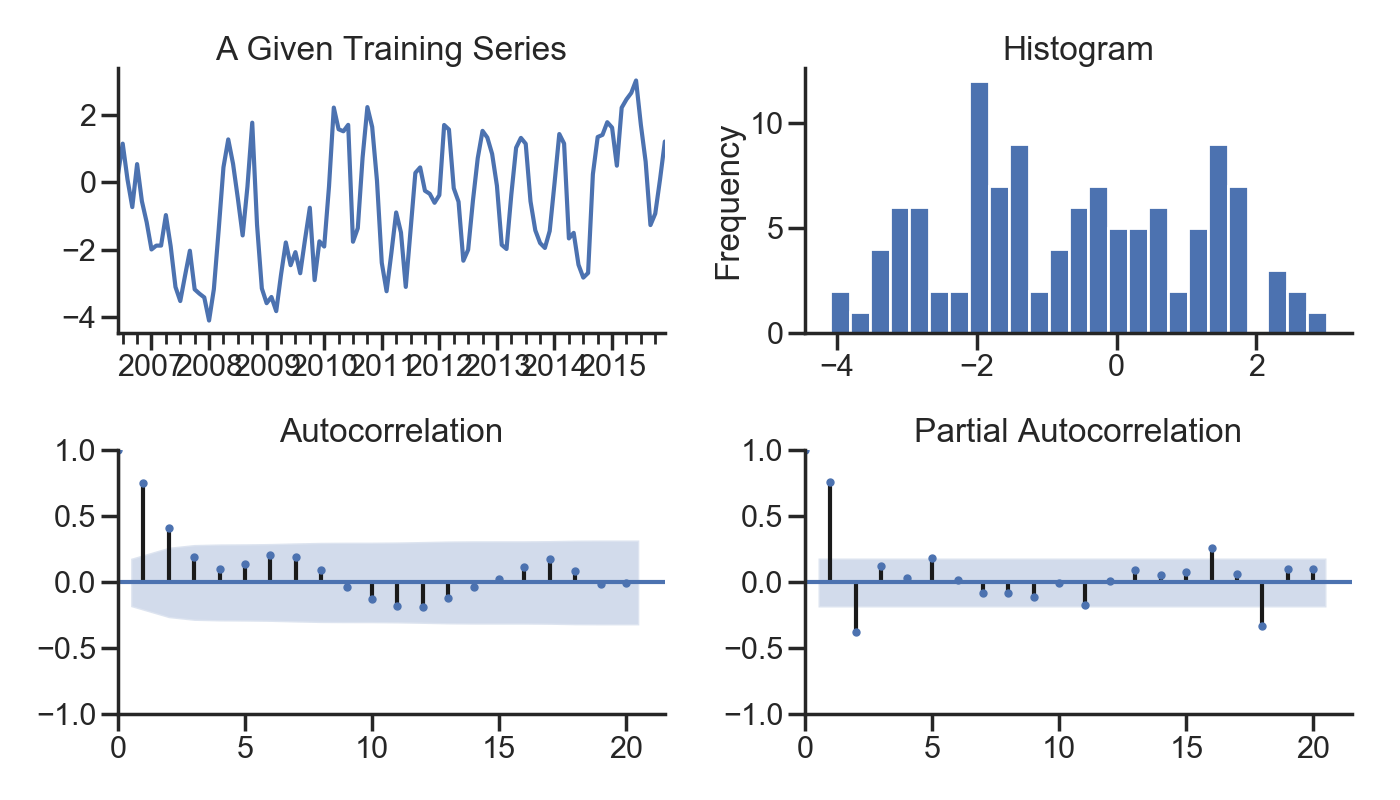
2.2 直观的图形化展示
代码:
from __future__ import absolute_import, division, print_function
# http://www.lfd.uci.edu/~gohlke/pythonlibs/#xgboost
import sys
import os
import pandas as pd
import numpy as np
import statsmodels.api as sm
import statsmodels.formula.api as smf
import statsmodels.tsa.api as smt
import matplotlib.pylab as plt
import seaborn as sns
# 一些配置项
pd.set_option('display.float_format', lambda x: '%.5f' % x) # pandas
np.set_printoptions(precision=5, suppress=True) # numpy
pd.set_option('display.max_columns', 100)
pd.set_option('display.max_rows', 100)
sns.set(style='ticks', context='poster')
# 美国消费者信心指数
filename_ts = 'E:/file/series1.csv'
ts_df = pd.read_csv(filename_ts, index_col=0, parse_dates=[0])
n_sample = ts_df.shape[0]
# 划分测试集和训练集
n_train=int(0.95*n_sample)+1
n_forecast=n_sample-n_train
#ts_df
ts_train = ts_df.iloc[:n_train]['value']
ts_test = ts_df.iloc[n_train:]['value']
#print(ts_train.shape)
#print(ts_test.shape)
#print("Training Series:", "\n", ts_train.tail(), "\n")
#print("Testing Series:", "\n", ts_test.head())
def tsplot(y, lags=None, title='', figsize=(14, 8)):
fig = plt.figure(figsize=figsize)
layout = (2, 2)
ts_ax = plt.subplot2grid(layout, (0, 0))
hist_ax = plt.subplot2grid(layout, (0, 1))
acf_ax = plt.subplot2grid(layout, (1, 0))
pacf_ax = plt.subplot2grid(layout, (1, 1))
y.plot(ax=ts_ax)
ts_ax.set_title(title)
y.plot(ax=hist_ax, kind='hist', bins=25)
hist_ax.set_title('Histogram')
smt.graphics.plot_acf(y, lags=lags, ax=acf_ax)
smt.graphics.plot_pacf(y, lags=lags, ax=pacf_ax)
[ax.set_xlim(0) for ax in [acf_ax, pacf_ax]]
sns.despine()
fig.tight_layout()
return ts_ax, acf_ax, pacf_ax
tsplot(ts_train, title='A Given Training Series', lags=20);
plt.show()
测试记录:
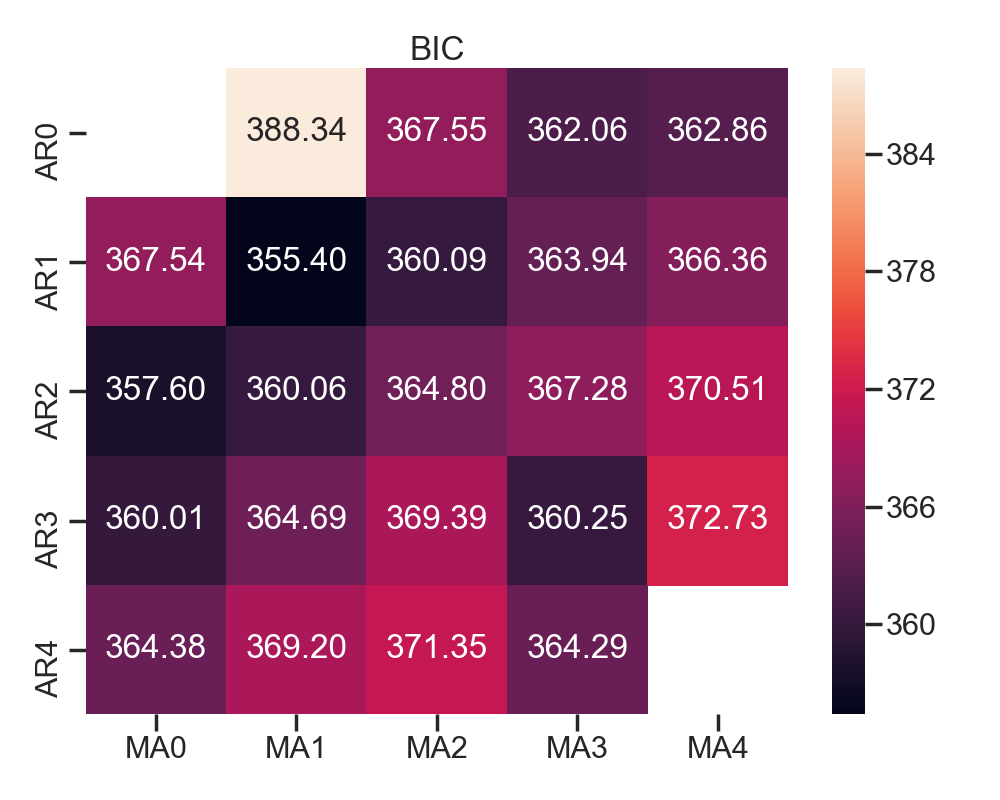
2.3 热力图
代码:
from __future__ import absolute_import, division, print_function
# http://www.lfd.uci.edu/~gohlke/pythonlibs/#xgboost
import sys
import os
import pandas as pd
import numpy as np
import statsmodels.api as sm
import statsmodels.formula.api as smf
import statsmodels.tsa.api as smt
import matplotlib.pylab as plt
import seaborn as sns
import itertools
# 一些配置项
pd.set_option('display.float_format', lambda x: '%.5f' % x) # pandas
np.set_printoptions(precision=5, suppress=True) # numpy
pd.set_option('display.max_columns', 100)
pd.set_option('display.max_rows', 100)
sns.set(style='ticks', context='poster')
# 美国消费者信心指数
filename_ts = 'E:/file/series1.csv'
ts_df = pd.read_csv(filename_ts, index_col=0, parse_dates=[0])
n_sample = ts_df.shape[0]
# 划分训练集和测试集
n_train=int(0.95*n_sample)+1
n_forecast=n_sample-n_train
#ts_df
ts_train = ts_df.iloc[:n_train]['value']
ts_test = ts_df.iloc[n_train:]['value']
# 训练模型
arima200 = sm.tsa.SARIMAX(ts_train, order=(2,0,0))
model_results = arima200.fit()
# 选择参数
p_min = 0
d_min = 0
q_min = 0
p_max = 4
d_max = 0
q_max = 4
# Initialize a DataFrame to store the results
results_bic = pd.DataFrame(index=['AR{}'.format(i) for i in range(p_min, p_max + 1)],
columns=['MA{}'.format(i) for i in range(q_min, q_max + 1)])
for p, d, q in itertools.product(range(p_min, p_max + 1),
range(d_min, d_max + 1),
range(q_min, q_max + 1)):
if p == 0 and d == 0 and q == 0:
results_bic.loc['AR{}'.format(p), 'MA{}'.format(q)] = np.nan
continue
try:
model = sm.tsa.SARIMAX(ts_train, order=(p, d, q),
# enforce_stationarity=False,
# enforce_invertibility=False,
)
results = model.fit()
results_bic.loc['AR{}'.format(p), 'MA{}'.format(q)] = results.bic
except:
continue
results_bic = results_bic[results_bic.columns].astype(float)
fig, ax = plt.subplots(figsize=(10, 8))
ax = sns.heatmap(results_bic,
mask=results_bic.isnull(),
ax=ax,
annot=True,
fmt='.2f',
);
ax.set_title('BIC');
plt.show()
测试记录:
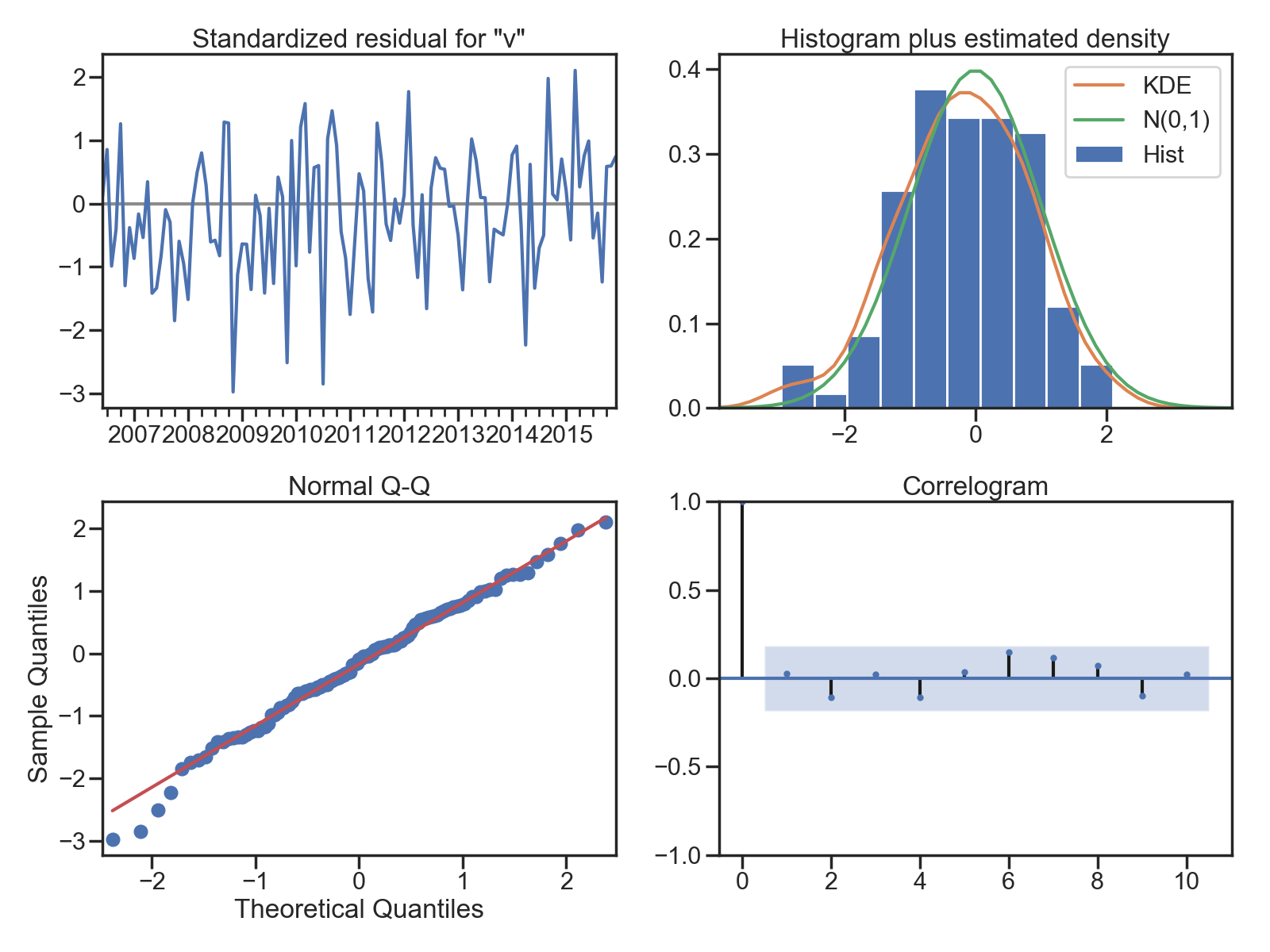
2.4 AIC/BIC以及残差分析 正态分布 QQ图线性
代码:
from __future__ import absolute_import, division, print_function
# http://www.lfd.uci.edu/~gohlke/pythonlibs/#xgboost
import sys
import os
import pandas as pd
import numpy as np
import statsmodels.api as sm
import statsmodels.formula.api as smf
import statsmodels.tsa.api as smt
import matplotlib.pylab as plt
import seaborn as sns
import itertools
# 一些配置项
pd.set_option('display.float_format', lambda x: '%.5f' % x) # pandas
np.set_printoptions(precision=5, suppress=True) # numpy
pd.set_option('display.max_columns', 100)
pd.set_option('display.max_rows', 100)
sns.set(style='ticks', context='poster')
# 美国消费者信心指数
filename_ts = 'E:/file/series1.csv'
ts_df = pd.read_csv(filename_ts, index_col=0, parse_dates=[0])
n_sample = ts_df.shape[0]
# 划分训练集和测试集
n_train=int(0.95*n_sample)+1
n_forecast=n_sample-n_train
#ts_df
ts_train = ts_df.iloc[:n_train]['value']
ts_test = ts_df.iloc[n_train:]['value']
# 训练模型
arima200 = sm.tsa.SARIMAX(ts_train, order=(2,0,0))
model_results = arima200.fit()
# AIC 和 BIC
#print(help(sm.tsa.arma_order_select_ic))
train_results = sm.tsa.arma_order_select_ic(ts_train, ic=['aic', 'bic'], trend='n', max_ar=4, max_ma=4)
print('AIC', train_results.aic_min_order)
print('BIC', train_results.bic_min_order)
#残差分析 正态分布 QQ图线性
model_results.plot_diagnostics(figsize=(16, 12));
plt.show()
测试记录:
AIC (3, 3)
BIC (1, 1)
参考:
- https://study.163.com/course/introduction.htm?courseId=1003590004#/courseDetail?tab=1
「喜欢这篇文章,您的关注和赞赏是给作者最好的鼓励」
关注作者
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文章的来源(墨天轮),文章链接,文章作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
