在日常工作中,数据清洗的第一步往往是去除重复值(以下简称去重)。因为客户多次登录亦或需要对不同阶段的客户分类,这样就会造成重复记录,所以重复值的出现几乎是不可避免的。如果获取的数据中有大量的重复值,那所统计出来的数值也就失去了可信度和意义。
传统的手法,一般是借助excel里数据栏的删除重复值,这样能快速的去除某一列或某几列的重复值,从而达到去重的目的。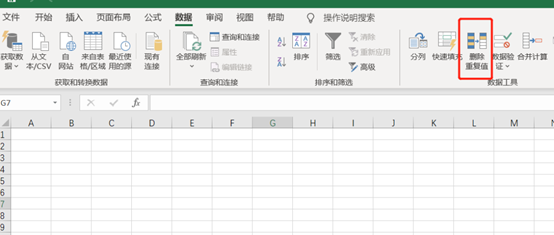
但是,随着需要存储的数据量越来越庞大,excel去重有些时候会显得力不从心。另外,一定规模的企业更愿意把自身的数据存储在易保存的数据库中,如此一来,直接在数据库中去重,再提取数据,可能是一种更加明智的选择。这里以excel为参照,主要介绍SQL里两个去重办法。第一个是使用函数distinct,但是行家都认为这个函数少用为妙,因为这个函数会降低运行速度。可是对于入门级选手而言,还是一个很友善的函数,意思好理解且使用方便。select distinct 字段 from 表名
就是这么一行,就能对整个字段进行去重。类比到excel里,就相当于选中某列,再点选“删除重复值”选项。可惜的是,现实业务永远不会这么简单粗暴。函数distinct 甚至不能对两个字段同时进行去重,所以在稍微复杂一点的情境下,这个函数就显得捉襟见肘了。这里同样以excel作为参照,假设要找出最近一次登录的客户(图片标黄的部分):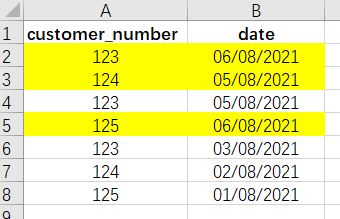
在excel里,我们会通过增加一列的方式,达到筛选的目的: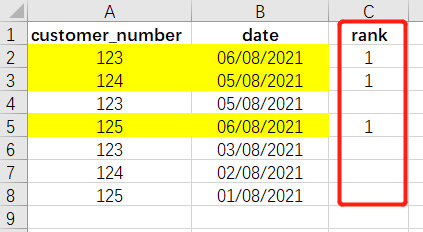
只要在想要的数据后面赋值,然后降序排列,就能筛选出最新一次登录的数值。这样的想法同样可以运用到SQL中。只不过,这里用row_number() over() 这个函数来实现。select customer_number
,row_number() over(partition by customer_number order by date)
from 表名
where rank=1
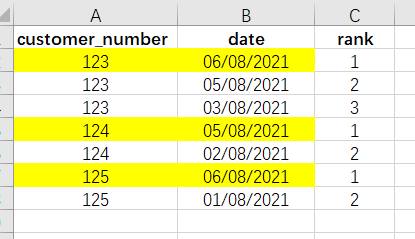
这样我们再加上限定条件rank=1,就可找到我们所想要的数据。整体来说,SQL和excel有很多类似的地方,甚至很多处理方式上简直就是一模一样,但是针对海量数据来说,SQL还是有其独到的优势的。





