




引子
在OLAP相关的资料里面经常有个词MPP,为了了解清楚自己提了几个问题并顺着这些问题进行深挖:
1.MPP是什么?为了解决什么问题提出MPP? (What+Why)
2.MPP技术应用领域及对标的是什么?各有什么优缺点?(Where+How)
在学习的时候我都习惯性提出这几个通用性问题,根据查阅的资料进行这几方面的总结,回答并不按顺序组织。
What+Why
MPP全称Massive Parallel Processing,在不少文章中会先拿SMP、NUMA来跟MPP进行对比,但前2者其实是硬件层面的系统架构。
SMP(SymmetricMulti-Processor)是用来扩展我们单个CPU(Single-Processor)情况,一般情况下我们的PC都是单个CPU(一个CPU可以有多核),CPU和内存之间由总线连接,为了扩展(服务器)硬件性能,在同一个系统总线上可以挂载多个CPU单元+多个内存,大家对称无差别的访问内存,访问内存的耗时是一样的。由于在对称访问内存的过程中必定会出现共享资源冲突的情况,比如CPU1要写内存变量a,CPU2要读或者写a,那就需要相应的同步机制,这也限制了CPU扩展能力,不能无限在上面扩展CPU,一般SMP服务器CPU利用率最好的情况是2-4个CPU。
NUMA(Non-UniformMemory Access)也是为了扩展机器性能,但同时也为了解决SMP扩展性问题。既然过多CPU们共享内存那么多问题,那就划分下,2-4个CPU组成一个CPU模块,一个CPU模块分配一块独立的内存,这个CPU模块内的CPU能像SMP机器一样高效的访问这块内存资源;同时这种CPU模块+独立内存的组合可以进行扩展,由于又是在同一个机器内,那必然会出现CPU模块A中的CPU想访问模块B中的内存,所以NUMA架构会在各个CPU模块直接建立互联模块(称为Crossbar Switch),但由于架构上以及把内存划分成2种类型:就近内存和远端内存,所以访问内存的速度也有所差异。一般NUMA架构的CPU能支持到几十到上百个,但由于内存访问速度有差异的缺陷,CPU增加无法带来性能线性增加,一般8倍的CPU只能带来3倍性能的提升。
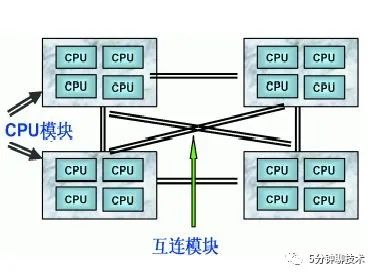
上面提到的2种都是硬件系统架构,为了解决SMP和NUMA扩展性缺陷的问题,提出了MPP的“服务”架构,注意这不是硬件架构,而是一种软件服务架构思想,是一种系统扩展方式。对外MPP呈现出来的是一个独立的服务形态。
前面提到SMP由于过多的CPU共享内存导致竞争,NUMA为了解决竞争引入了远近内存,那无共享是不是就没有这个问题呢?也就是Share Nothing架构,这也是MPP架构的出发点。MPP“服务”架构底层会有多个SMP机器(应该也支持NUMA,不关心具体的硬件架构),在这之上还需要有一个独立的任务切分和调度的服务,其主要是把服务的功能划分到各个下面的节点机器,下面的机器运行的代码逻辑是一样的,只不过是用本地计算资源(CPU)去处理的本地的数据(Memory+Disk),并且这些节点是并行运行的,所以运行的效率也是非常高的。
那MPP是否能无限扩展?答案是不能,由于MPP架构底层的数据是无共享的,所以如果一个任务被划分到各个节点执行,随着节点增加,慢节点出现的概率会变大,那必然整体的效率就受限于最慢的节点,也就是木桶效应,而且还无法像Spark那样进行推测执行,一个节点慢就换另外一个节点重跑数据(重点:数据无共享)。一般MPP上限是512个节点互联,数千CPU。
Where+How
下面我们看看MPP的应用领域,MPP是种软件服务架构,最先应用的就是数据库领域。这也是很好理解,一般服务的瓶颈最容易出现在DB,各种分库分表为了也是解决DB的扩展性问题。那来想个问题:
1.分库分表、MPP、分布式数据库有什么区别?
2.MPP跟Sql on Hadoop有什么区别?
分库分表主要是解决单机无法用一个库一张表来承载所有数据问题,需要将数据按照逻辑进行划分到不同的物理库表中,从业务视角形成一个很大的逻辑表。
分库分表是在业务层实现的一种分布式数据库,更广义的分布式数据库是将这些逻辑全部封装在数据库底层,包括数据如何分shard,节点数据如何备份容灾等能力。
MPP在数据库领域的应用应该归属于分布式数据库,而且不仅限于OLTP,更多场景应用于OLAP。
对比MPP和Sql on Hadoop的话其实是2个理念之间的对比:MPP和Batch
Batch其实是另外一种Share Nothing的实现(参考#2)
在存储层面,MPP是基于key去做划分,而Batch是基于Block去做划分,前者带有明显的业务含义,而后者则不带任何含义,拜托业务约束,扩展性上也就更好了。
在计算层面,Batch以批处理的形式,追求更大的吞吐率和数据规模,放弃实时性和延时性(属于另外一种trade-off)
以MR模型的Batch为例,由于底层数据存储在hdfs上,hdfs上的数据按partition进行划分成block,批处理任务可以线性扩展来读取block进行处理,同时当出现慢节点的时候在Spark上如果开启推测执行还是自动重算慢节点的数据,提高整体的性能。而MPP由于数据都独立存储在各种SMP机器的磁盘中,无法相互读取,所以扩展性上无法跟Batch比拟,但由于MPP的backend都是独立数据库,这块处理的是本地数据,速度上比Batch快很多。
More
疑问:
1.MPP和Batch能融合吗?Batch由于底层存储共享提供了较好的扩展性,那MPP是否可以借鉴?
参考:
http://www.hp.sh.cn/2019/05/28/news4/
https://zhuanlan.zhihu.com/p/293316484
