





当前,数字化转型正以历史上前所未有的进度推进,以前可能需要一年或更长时间上线的项目,现在只需几周甚至更多时间就能上线。为了保证这种极速迭代的敏捷开发节奏,企业正在大规模调整转变IT设计模式,越来越多地使用云计算、云原生、微服务等新技术。
随着这些新型环境的复杂性爆炸式增长,IT 团队越来越难以了解应用程序的质量、性能、健康度,无法在发生故障之前提前发现问题、定位问题、解决问题。
传统的监控( Monitoring )工具大多诞生于10年前、甚至更早,它们并不是为现代化的软件场景而设计,根本无法满足现代化应用的使用需求,可观测性 (Observability) 随之诞生。而 “全栈式” 的可观测性尤为重要,正在迅速成为企业IT团队的必备能力。
本文将主要围绕 “全栈”,展开对其概念的阐述,及其必要性的分析。
一、什么是全栈 Full Stack?
全栈:指的是IT环境中的全部技术堆栈,或者全部端点,包括但不限于云平台、主机、进程、容器、网络、Kubernetes、Serverless、数据库、中间件、服务,以及用户、会话、请求、访问等等,近乎所有软件堆栈。

全栈可观测性:即指的是基于遥测数据以确定IT环境中每个端点状态的能力。
全栈可观察性解决方案:使用遥测数据(如日志、指标、追踪、拓扑、代码)让 IT 团队深入了解应用程序、基础架构和 UX 性能。丰富的上下文信息能够帮助团队了解所有实体是如何连接的,包括但不限于基础设施、容器、微服务及代码之间的依赖关系。(这里涉及到 DataBuff 提出的 可观测性五大数据支柱 ,将在后续博文中阐述)
全栈可观测性不单单只是对软件堆栈本身,前端的数字体验(DEM)也是必不可少的。
二、为什么需要全栈可观测性?
当前越来越多的企业组织采用云计算,业务上云趋势明显,据Gartner统计,预计2024年超过60%的组织单位选择云计算构建自己的业务。云计算在带来便利的同时,也带来了前所未有的挑战。所有的底层硬件基础设施都将托管给运营者或电信服务商,而应用与服务成为了企业组织唯一需要关心的对象。企业组织不再需要为传统的机房管理、弱电管理、硬件监控、UPS配电等等资产类运维而烦恼,转而应用与服务成为了他们的重中之重,因此传统的设备运维也慢慢演变成Site Reliability 运维,对企业IT团队SRE的技能要求越来越高。传统的服务可用性简单监控,也将演进到服务质量、性能与健康度观测,对服务的敏感度要求越来越高。然而随着用户体验的简化,应用程序的复杂性却在爆炸式增长,越来越多的分布式、越来越多的依赖关系,越来越快的上线周期。
可以说,云环境提出了传统本地数据中心不存在的复杂性挑战,不论是对监控重心的改变,还是对企业IT团队技术能力的改变。企业组织的监控管理面将由大而全走向专而精,由发散走向纵深,企业的管理面将收缩到越来越多的软件堆栈上来。
面对当前复杂、庞大、动态、多样的软件环境,企业怎么办?
01)企业的IT工程师要么成为一名 六边形战士、拥有全栈 Skills;
02)要么拥有一套 六边形工具 、拥有全栈 Skills 能力的智能平台。
03)又或者,企业花钱组建一只 覆盖全栈 Skills 技能的团队,靠堆人头的方式运维操作一堆单点工具,组建 War Room 实时作战室。

而当前 国内的现状 普遍是采用第 03 种方案,企业组织以打补丁的方式不停地添加监控工具,这不但增加了云计算的复杂性,同时也减慢了对问题的及时响应。企业诞生大量竖井式团队、竖井式工具的矛盾问题,他们缺乏软件活动的全貌观察能力。团队之间会经常发生Argue,找不到答案, 甚至无法就影响业务收入的紧急问题的根本原因达成一致。
全栈式,刻不容缓
全栈式可观察性的出现非常必要,使用一个平台提供对应用程序基础架构每一层的洞察,能够简化这种监控工具的蔓延扩展。团队之间可以避免使用多点解决方案所带来的成本浪费和管理混乱,并使多团队实现目标的统一平衡。
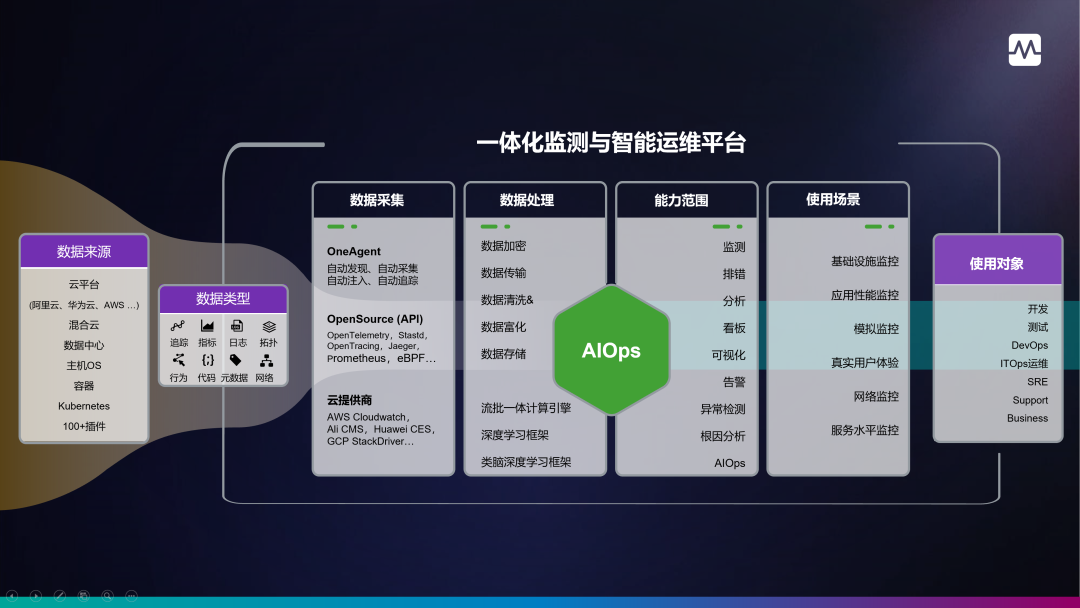
ITOps 或DevOps团队也可以从全栈可观察性中受益,可以更快地解决用户体验问题和应用程序性能挑战。借助改进的诊断和分析功能,ITOps或DevOps 团队可以花费更少的时间进行故障排除。
三、如何助力 ITOps 和 DevOps ?
获得整个多云环境的态势感知如果没有对整个多云环境的完全可观察性,企业最多只能了解应用层的问题。全栈式可观察性能够提供整个应用程序环境的水平栈、垂直栈的端到端全链路可见性,消除围绕应用程序性能、运行状况和行为的盲点。
查明精确的根本原因并确定问题的优先级
ITOps 和 DevOps 团队经常陷入“狼来了”的告警困境,浪费大量时间在筛选噪音、甚至直接麻木不再处理告警数据。通过全栈式可观测性可以快速识别根本原因,并根据用户和业务影响确定问题的优先级。
加速和自动化 CI/CD 管道
全栈可观察性可帮助 DevOps 团队快速识别CI/CD 管道中的潜在问题,以更快的速度和信心解决问题。这有助于加速和自动化软件开发和交付,使组织能够更快地创新并保持竞争力。
通过精确分析改进业务决策
当 IT 和业务团队不一致时,组织很难做出重要决策。可观察性为每个人提供了共享参考框架并就业务优先级达成一致所需的透明度。
消除运营孤岛并改善跨职能协作
借助单一事实来源进行根本原因分析,IT 和 DevOps 团队可以快速达成共识,了解需要做什么以及由谁负责。这减少了相互指责并消除了作战室,改善了协作和跨职能的工作关系。
四、全栈可观察性的自动化智能化方法 ?
DataBuff 内生AIOps 引擎,使用AI开展智能分析,不仅可以帮助企业消除 IT 运营中的噪音,还可以提高 IT 效率并加快创新速度。
内生AIOps 引擎可以提供自动化的根本原因分析(仅需3次Click即可定位问题根因的方案),IT 团队可以将注意力集中在更高级别的任务上。
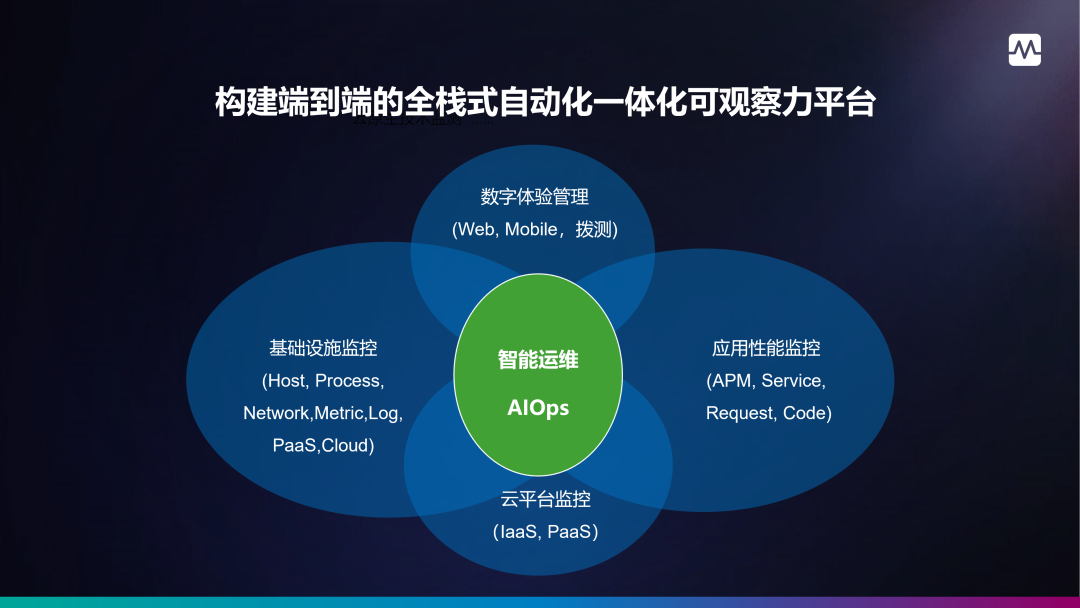
DataBuff 全栈可观察性提供从上到下、从前到后的观察能力,从最终用户体验到基础设施健康状况的所有内容。可以帮助您了解一切是如何连接的 —— 包括任何层、组件或代码片段之间的所有关系和相互依赖关系。这些功能可以帮助您的企业更快、更轻松、更智能地进行数字化转型——即使在云复杂性增加的情况下也是如此。
