




目录
1. PostgreSQL Database Monitoring 201:准备存储数据快照
2. 查询pg_stat_statements快照数据
3. 压缩、连续聚合和数据保留
4. 通过pg_stat_statements实现更好的自助查询监控
数据库监控是有效数据管理和构建高性能应用程序的关键部分。在之前的博客文章中,我们讨论了如何启用(以及它是所有 Timescale Cloud 实例的标准配置)、它提供的数据,并演示了一些查询,您可以运行这些查询来从指标中收集有用的信息,以帮助查明问题查询。
我们还讨论了为数不多的陷阱之一:它提供的所有数据都是自上次服务器重新启动(或超级用户重置统计信息)以来累积的。
虽然可以作为首选信息源,以确定当服务器未按预期运行时可能发生初始问题的位置,但当所述服务器难以跟上负载时,它提供的累积数据也可能带来问题。
数据可能显示特定应用程序查询已被频繁调用,并从磁盘读取大量数据以返回结果,但这只能说明部分情况。使用累积数据,无法回答有关集群状态的特定问题,例如:
-
在一天中的这个时候,它通常会与资源作斗争吗?
-
是否存在比其他查询速度慢的特定形式的查询?
-
它是否是一个特定的数据库,现在比其他数据库消耗更多的资源?
-
在当前负载下,这是正常的吗?
当您需要时,提供的数据库监视信息非常宝贵。但是,当数据显示随时间变化的趋势和模式时,当出现问题时,可视化数据库的真实状态最有帮助。
如果您可以将这些静态的累积数据转换为时序数据,并定期存储指标的快照,那将更有价值。存储数据后,我们可以使用标准 SQL 来查询每个快照和指标的增量值,以查看每个数据库、用户和查询是如何按间隔执行的。这也使得确定问题何时开始以及哪个查询或数据库似乎贡献最大的问题变得更加容易。在这篇博客文章(我们之前关于这个主题的101的续集)中,我们将讨论使用 TimescaleDB 功能存储和分析快照数据的基本过程,以有效地存储,管理和查询指标数据。
关于这个主题的另一个看法,你可以观看我今年四月份时候在Citus Con的演讲。
虽然您可以在一些PostgreSQL扩展的帮助下自动存储快照数据,但只有 TimescaleDB 提供了您所需的一切,包括自动化作业调度,数据压缩,数据保留和连续聚合,以有效地管理整个解决方案。
1.PostgreSQL Database Monitoring 201:准备存储数据快照
在查询和存储正在进行的快照数据之前,我们需要准备一个架构,一个单独的数据库来保存我们将通过每个快照收集的所有信息。
我们选择对如何存储快照度量数据以及如何分离某些信息(如查询文本本身)发表自己的意见。使用我们的示例作为构建块来存储您认为在您的环境中最有用的信息。您可能不想保留一些度量数据,这是可以的。根据您的数据库监控需求进行调整。
创建指标数据库
回想一下,它跟踪PostgreSQL集群中每个数据库的统计信息。此外,具有适当权限的任何用户都可以在连接到任何数据库时查询所有数据。因此,虽然创建单独的数据库是可选步骤,但将此数据存储在单独的 TimescaleDB 数据库中可以更轻松地从正在进行的快照收集过程中筛选出查询。
我们还演示如何创建一个单独的架构,该架构调用来存储整个示例中使用的所有表和过程。这允许将此数据与您可能想要在此数据库中执行的任何其他操作完全分离。
psql=> CREATE DATABASE statements_monitor;
psql=> \c statements_monitor;
psql=> CREATE EXTENSION IF NOT EXISTS timescaledb;
psql=> CREATE SCHEMA IF NOT EXISTS statements_history;
创建 hypertables 以存储快照数据
无论是创建单独的数据库还是使用现有的 TimescaleDB 数据库,我们都需要创建表来存储快照信息。对于我们的示例,我们将创建三个表:
- 快照(hypertable):所有指标的集群范围的聚合快照,便于集群级监控
- 查询:按单独存储查询文本 queryid rolname datname
- statements (hypertable):每次拍摄快照时每个查询的统计信息按照 grouped by 和 queryid rolname datname
在以下 SQL 中,和表都将转换为 hypertable。由于这些表将随着时间的推移存储大量指标数据,因此使它们成为 hypertable可以解锁强大的功能,用于通过压缩和数据保留来管理数据,以及加快专注于特定时间段的查询。最后,请注意,根据添加到其中的数据的数量和频率,为每个表分配不同的表。
例如,该表将仅接收每个快照一行,这允许创建块的频率较低(每四周一次),而不会变得太大。相比之下,每次拍摄快照时,该表都可能收到数千行,因此更频繁地(每周)创建块使我们能够更频繁地压缩此数据,并提供对数据保留的更细粒度的控制。
集群的大小和活动,以及运行作业以拍摄数据快照的频率,将影响系统的正确性。有关块大小和最佳实践的更多信息,请参阅我们的文档。
/*
* The snapshots table holds the cluster-wide values
* each time an overall snapshot is taken. There is
* no database or user information stored. This allows
* you to create cluster dashboards for very fast, high-level
* information on the trending state of the cluster.
*/
CREATE TABLE IF NOT EXISTS statements_history.snapshots (
created timestamp with time zone NOT NULL,
calls bigint NOT NULL,
total_plan_time double precision NOT NULL,
total_exec_time double precision NOT NULL,
rows bigint NOT NULL,
shared_blks_hit bigint NOT NULL,
shared_blks_read bigint NOT NULL,
shared_blks_dirtied bigint NOT NULL,
shared_blks_written bigint NOT NULL,
local_blks_hit bigint NOT NULL,
local_blks_read bigint NOT NULL,
local_blks_dirtied bigint NOT NULL,
local_blks_written bigint NOT NULL,
temp_blks_read bigint NOT NULL,
temp_blks_written bigint NOT NULL,
blk_read_time double precision NOT NULL,
blk_write_time double precision NOT NULL,
wal_records bigint NOT NULL,
wal_fpi bigint NOT NULL,
wal_bytes numeric NOT NULL,
wal_position bigint NOT NULL,
stats_reset timestamp with time zone NOT NULL,
PRIMARY KEY (created)
);
/*
* Convert the snapshots table into a hypertable with a 4 week
* chunk_time_interval. TimescaleDB will create a new chunk
* every 4 weeks to store new data. By making this a hypertable we
* can take advantage of other TimescaleDB features like native
* compression, data retention, and continuous aggregates.
*/
SELECT * FROM create_hypertable(
'statements_history.snapshots',
'created',
chunk_time_interval => interval '4 weeks'
);
COMMENT ON TABLE statements_history.snapshots IS
$$This table contains a full aggregate of the pg_stat_statements view
at the time of the snapshot. This allows for very fast queries that require a very high level overview$$;
/*
* To reduce the storage requirement of saving query statistics
* at a consistent interval, we store the query text in a separate
* table and join it as necessary. The queryid is the identifier
* for each query across tables.
*/
CREATE TABLE IF NOT EXISTS statements_history.queries (
queryid bigint NOT NULL,
rolname text,
datname text,
query text,
PRIMARY KEY (queryid, datname, rolname)
);
COMMENT ON TABLE statements_history.queries IS
$$This table contains all query text, this allows us to not repeatably store the query text$$;
/*
* Finally, we store the individual statistics for each queryid
* each time we take a snapshot. This allows you to dig into a
* specific interval of time and see the snapshot-by-snapshot view
* of query performance and resource usage
*/
CREATE TABLE IF NOT EXISTS statements_history.statements (
created timestamp with time zone NOT NULL,
queryid bigint NOT NULL,
plans bigint NOT NULL,
total_plan_time double precision NOT NULL,
calls bigint NOT NULL,
total_exec_time double precision NOT NULL,
rows bigint NOT NULL,
shared_blks_hit bigint NOT NULL,
shared_blks_read bigint NOT NULL,
shared_blks_dirtied bigint NOT NULL,
shared_blks_written bigint NOT NULL,
local_blks_hit bigint NOT NULL,
local_blks_read bigint NOT NULL,
local_blks_dirtied bigint NOT NULL,
local_blks_written bigint NOT NULL,
temp_blks_read bigint NOT NULL,
temp_blks_written bigint NOT NULL,
blk_read_time double precision NOT NULL,
blk_write_time double precision NOT NULL,
wal_records bigint NOT NULL,
wal_fpi bigint NOT NULL,
wal_bytes numeric NOT NULL,
rolname text NOT NULL,
datname text NOT NULL,
PRIMARY KEY (created, queryid, rolname, datname),
FOREIGN KEY (queryid, datname, rolname) REFERENCES statements_history.queries (queryid, datname, rolname) ON DELETE CASCADE
);
/*
* Convert the statements table into a hypertable with a 1 week
* chunk_time_interval. TimescaleDB will create a new chunk
* every 1 weeks to store new data. Because this table will receive
* more data every time we take a snapshot, a shorter interval
* allows us to manage compression and retention to a shorter interval
* if needed. It also provides smaller overall chunks for querying
* when focusing on specific time ranges.
*/
SELECT * FROM create_hypertable(
'statements_history.statements',
'created',
create_default_indexes => false,
chunk_time_interval => interval '1 week'
);
创建快照存储过程
创建表以存储统计数据,我们需要创建一个存储过程,该过程将按计划运行以收集和存储数据。这是一个简单的过程,具有 TimescaleDB 用户定义的操作。
用户定义的操作提供了一种使用基础计划引擎来计划自定义存储过程的方法,TimescaleDB 将该引擎用于自动策略(如连续聚合刷新和数据保留)。尽管还有其他用于管理计划的PostgreSQL扩展,但默认情况下,此功能包含在 TimescaleDB 中。首先,创建存储过程以填充数据。在此示例中,我们使用多部分公用表表达式 (CTE) 来填充每个表,从视图的结果开始。
CREATE OR REPLACE PROCEDURE statements_history.create_snapshot(
job_id int,
config jsonb
)
LANGUAGE plpgsql AS
$function$
DECLARE
snapshot_time timestamp with time zone := now();
BEGIN
/*
* This first CTE queries pg_stat_statements and joins
* to the roles and database table for more detail that
* we will store later.
*/
WITH statements AS (
SELECT
*
FROM
pg_stat_statements(true)
JOIN
pg_roles ON (userid=pg_roles.oid)
JOIN
pg_database ON (dbid=pg_database.oid)
WHERE queryid IS NOT NULL
),
/*
* We then get the individual queries out of the result
* and store the text and queryid separately to avoid
* storing the same query text over and over.
*/
queries AS (
INSERT INTO
statements_history.queries (queryid, query, datname, rolname)
SELECT
queryid, query, datname, rolname
FROM
statements
ON CONFLICT
DO NOTHING
RETURNING
queryid
),
/*
* This query SUMs all data from all queries and databases
* to get high-level cluster statistics each time the snapshot
* is taken.
*/
snapshot AS (
INSERT INTO
statements_history.snapshots
SELECT
now(),
sum(calls),
sum(total_plan_time) AS total_plan_time,
sum(total_exec_time) AS total_exec_time,
sum(rows) AS rows,
sum(shared_blks_hit) AS shared_blks_hit,
sum(shared_blks_read) AS shared_blks_read,
sum(shared_blks_dirtied) AS shared_blks_dirtied,
sum(shared_blks_written) AS shared_blks_written,
sum(local_blks_hit) AS local_blks_hit,
sum(local_blks_read) AS local_blks_read,
sum(local_blks_dirtied) AS local_blks_dirtied,
sum(local_blks_written) AS local_blks_written,
sum(temp_blks_read) AS temp_blks_read,
sum(temp_blks_written) AS temp_blks_written,
sum(blk_read_time) AS blk_read_time,
sum(blk_write_time) AS blk_write_time,
sum(wal_records) AS wal_records,
sum(wal_fpi) AS wal_fpi,
sum(wal_bytes) AS wal_bytes,
pg_wal_lsn_diff(pg_current_wal_lsn(), '0/0'),
pg_postmaster_start_time()
FROM
statements
)
/*
* And finally, we store the individual pg_stat_statement
* aggregated results for each query, for each snapshot time.
*/
INSERT INTO
statements_history.statements
SELECT
snapshot_time,
queryid,
plans,
total_plan_time,
calls,
total_exec_time,
rows,
shared_blks_hit,
shared_blks_read,
shared_blks_dirtied,
shared_blks_written,
local_blks_hit,
local_blks_read,
local_blks_dirtied,
local_blks_written,
temp_blks_read,
temp_blks_written,
blk_read_time,
blk_write_time,
wal_records,
wal_fpi,
wal_bytes,
rolname,
datname
FROM
statements;
END;
$function$;
创建存储过程后,请将其安排为作为用户定义的操作持续运行。在以下示例中,我们计划每分钟收集一次快照数据,这可能太频繁了,无法满足您的需求。调整收集计划以满足您的数据捕获和监视需求。
/*
* Adjust the scheduled_interval based on how often
* a snapshot of the data should be captured
*/
SELECT add_job(
'statements_history.create_snapshot',
schedule_interval=>'1 minutes'::interval
);
最后,您可以通过查询作业信息视图来验证用户定义的操作作业是否正确运行。如果您将其设置为一分钟(如上所示),等待几分钟,然后确保为零
schedule_intervallast_run_statusSuccesstotal_failures
SELECT js.* FROM timescaledb_information.jobs j
INNER JOIN timescaledb_information.job_stats js ON j.job_id =js.job_id
WHERE j.proc_name='create_snapshot';
Name |Value |
----------------------+-----------------------------+
hypertable_schema | |
hypertable_name | |
job_id |1008 |
last_run_started_at |2022-04-13 17:43:15.053 -0400|
last_successful_finish|2022-04-13 17:43:15.068 -0400|
last_run_status |Success |
job_status |Scheduled |
last_run_duration |00:00:00.014755 |
next_start |2022-04-13 17:44:15.068 -0400|
total_runs |30186 |
total_successes |30167 |
total_failures |0 |
查询指标数据库已设置并准备好查询!让我们看几个查询示例来帮助您入门。
2.查询pg_stat_statements快照数据
我们选择创建两个统计信息表:一个用于聚合集群的快照统计信息(而不考虑特定查询),另一个用于存储每个快照的每个查询的统计信息。使用两个表中创建的列对数据进行时间戳。每个快照的变化率是一个快照到下一个快照的累积统计信息值的差异。
这是在 SQL 中使用 LAG 窗口函数完成的,该函数从按创建的列排序的前一行中减去每一行。
一段时间内的集群性能
第一个示例查询“快照”表,该表存储整个集群的所有统计信息的聚合总计。运行此查询将返回每个快照的总值,而不是总累积值。
/*
* This CTE queries the snapshot table (full cluster statistics)
* to get a high-level view of the cluster state.
*
* We query each row with a LAG of the previous row to retrieve
* the delta of each value to make it suitable for graphing.
*/
WITH deltas AS (
SELECT
created,
extract('epoch' from created - lag(d.created) OVER (w)) AS delta_seconds,
d.ROWS - lag(d.rows) OVER (w) AS delta_rows,
d.total_plan_time - lag(d.total_plan_time) OVER (w) AS delta_plan_time,
d.total_exec_time - lag(d.total_exec_time) OVER (w) AS delta_exec_time,
d.calls - lag(d.calls) OVER (w) AS delta_calls,
d.wal_bytes - lag(d.wal_bytes) OVER (w) AS delta_wal_bytes,
stats_reset
FROM
statements_history.snapshots AS d
WHERE
created > now() - INTERVAL '2 hours'
WINDOW
w AS (PARTITION BY stats_reset ORDER BY created ASC)
)
SELECT
created AS "time",
delta_rows,
delta_calls/delta_seconds AS calls,
delta_plan_time/delta_seconds/1000 AS plan_time,
delta_exec_time/delta_seconds/1000 AS exec_time,
delta_wal_bytes/delta_seconds AS wal_bytes
FROM
deltas
ORDER BY
created ASC;
time |delta_rows|calls |plan_time|exec_time |wal_bytes |
-----------------------------+----------+--------------------+---------+------------------+------------------+
2022-04-13 15:55:12.984 -0400| | | | | |
2022-04-13 15:56:13.000 -0400| 89| 0.01666222812679749| 0.0| 0.000066054620811| 576.3131464496716|
2022-04-13 15:57:13.016 -0400| 89|0.016662253391151797| 0.0|0.0000677694667946| 591.643293413018|
2022-04-13 15:58:13.031 -0400| 89|0.016662503817796187| 0.0|0.0000666146741069| 576.3226820499345|
2022-04-13 15:59:13.047 -0400| 89|0.016662103471929153| 0.0|0.0000717084114511| 591.6379700812604|
2022-04-13 16:00:13.069 -0400| 89| 0.01666062607900462| 0.0|0.0001640335102535|3393.3363560151874|
前 100 个最昂贵的查询
获取集群实例的概览对于了解整个系统随时间推移的状态非常有帮助。另一组有用的数据可供快速分析,它是使用群集中资源最多的查询的列表,逐个查询。您可以通过多种方式查询快照信息以获取这些详细信息,并且您对“资源密集型”的定义可能与我们显示的定义不同,但此示例提供了指定时间内每个查询的高级累积统计信息,按执行和计划时间的最高总和排序。
/*
* individual data for each query for a specified time range,
* which is particularly useful for zeroing in on a specific
* query in a tool like Grafana
*/
WITH snapshots AS (
SELECT
max,
-- We need at least 2 snapshots to calculate a delta. If the dashboard is currently showing
-- a period < 5 minutes, we only have 1 snapshot, and therefore no delta. In that CASE
-- we take the snapshot just before this window to still come up with useful deltas
CASE
WHEN max = min
THEN (SELECT max(created) FROM statements_history.snapshots WHERE created < min)
ELSE min
END AS min
FROM (
SELECT
max(created),
min(created)
FROM
statements_history.snapshots WHERE created > now() - '1 hour'::interval
-- Grafana-based filter
--statements_history.snapshots WHERE $__timeFilter(created)
GROUP by
stats_reset
ORDER by
max(created) DESC
LIMIT 1
) AS max(max, min)
), deltas AS (
SELECT
rolname,
datname,
queryid,
extract('epoch' from max(created) - min(created)) AS delta_seconds,
max(total_exec_time) - min(total_exec_time) AS delta_exec_time,
max(total_plan_time) - min(total_plan_time) AS delta_plan_time,
max(calls) - min(calls) AS delta_calls,
max(shared_blks_hit) - min(shared_blks_hit) AS delta_shared_blks_hit,
max(shared_blks_read) - min(shared_blks_read) AS delta_shared_blks_read
FROM
statements_history.statements
WHERE
-- granted, this looks odd, however it helps the DecompressChunk Node tremendously,
-- as without these distinct filters, it would aggregate first and then filter.
-- Now it filters while scanning, which has a huge knock-on effect on the upper
-- Nodes
(created >= (SELECT min FROM snapshots) AND created <= (SELECT max FROM snapshots))
GROUP BY
rolname,
datname,
queryid
)
SELECT
rolname,
datname,
queryid::text,
delta_exec_time/delta_seconds/1000 AS exec,
delta_plan_time/delta_seconds/1000 AS plan,
delta_calls/delta_seconds AS calls,
delta_shared_blks_hit/delta_seconds*8192 AS cache_hit,
delta_shared_blks_read/delta_seconds*8192 AS cache_miss,
query
FROM
deltas
JOIN
statements_history.queries USING (rolname,datname,queryid)
WHERE
delta_calls > 1
AND delta_exec_time > 1
AND query ~* $$.*$$
ORDER BY
delta_exec_time+delta_plan_time DESC
LIMIT 100;
rolname |datname|queryid |exec |plan|calls |cache_hit |cache_miss|query
---------+-------+--------------------+------------------+----+--------------------+------------------+----------+-----------
tsdbadmin|tsdb |731301775676660043 |0.0000934033977289| 0.0|0.016660922907623773| 228797.2725854585| 0.0|WITH statem...
tsdbadmin|tsdb |-686339673194700075 |0.0000570625206738| 0.0| 0.0005647770477161|116635.62329618855| 0.0|WITH snapsh...
tsdbadmin|tsdb |-5804362417446225640|0.0000008223159463| 0.0| 0.0005647770477161| 786.5311077312939| 0.0|-- NOTE Thi...
但是,您决定对此数据进行排序,您现在有一个快速结果集,其中包含查询文本和 .只需多花一点功夫,我们就可以更深入地了解特定查询在一段时间内的性能。
例如,在上一个查询的输出中,我们可以看到,在这段时间内,它的总体执行和规划时间最长。我们可以使用它来更深入地了解此特定查询的逐个快照性能。
/*
* When you want to dig into an individual query, this takes
* a similar approach to the "snapshot" query above, but for
* an individual query ID.
*/
WITH deltas AS (
SELECT
created,
st.calls - lag(st.calls) OVER (query_w) AS delta_calls,
st.plans - lag(st.plans) OVER (query_w) AS delta_plans,
st.rows - lag(st.rows) OVER (query_w) AS delta_rows,
st.shared_blks_hit - lag(st.shared_blks_hit) OVER (query_w) AS delta_shared_blks_hit,
st.shared_blks_read - lag(st.shared_blks_read) OVER (query_w) AS delta_shared_blks_read,
st.temp_blks_written - lag(st.temp_blks_written) OVER (query_w) AS delta_temp_blks_written,
st.total_exec_time - lag(st.total_exec_time) OVER (query_w) AS delta_total_exec_time,
st.total_plan_time - lag(st.total_plan_time) OVER (query_w) AS delta_total_plan_time,
st.wal_bytes - lag(st.wal_bytes) OVER (query_w) AS delta_wal_bytes,
extract('epoch' from st.created - lag(st.created) OVER (query_w)) AS delta_seconds
FROM
statements_history.statements AS st
join
statements_history.snapshots USING (created)
WHERE
-- Adjust filters to match your queryid and time range
created > now() - interval '25 minutes'
AND created < now() + interval '25 minutes'
AND queryid=731301775676660043
WINDOW
query_w AS (PARTITION BY datname, rolname, queryid, stats_reset ORDER BY created)
)
SELECT
created AS "time",
delta_calls/delta_seconds AS calls,
delta_plans/delta_seconds AS plans,
delta_total_exec_time/delta_seconds/1000 AS exec_time,
delta_total_plan_time/delta_seconds/1000 AS plan_time,
delta_rows/nullif(delta_calls, 0) AS rows_per_query,
delta_shared_blks_hit/delta_seconds*8192 AS cache_hit,
delta_shared_blks_read/delta_seconds*8192 AS cache_miss,
delta_temp_blks_written/delta_seconds*8192 AS temp_bytes,
delta_wal_bytes/delta_seconds AS wal_bytes,
delta_total_exec_time/nullif(delta_calls, 0) exec_time_per_query,
delta_total_plan_time/nullif(delta_plans, 0) AS plan_time_per_plan,
delta_shared_blks_hit/nullif(delta_calls, 0)*8192 AS cache_hit_per_query,
delta_shared_blks_read/nullif(delta_calls, 0)*8192 AS cache_miss_per_query,
delta_temp_blks_written/nullif(delta_calls, 0)*8192 AS temp_bytes_written_per_query,
delta_wal_bytes/nullif(delta_calls, 0) AS wal_bytes_per_query
FROM
deltas
WHERE
delta_calls > 0
ORDER BY
created ASC;
time |calls |plans|exec_time |plan_time|ro...
-----------------------------+--------------------+-----+------------------+---------+--
2022-04-14 14:33:39.831 -0400|0.016662115132216382| 0.0|0.0000735602224659| 0.0|
2022-04-14 14:34:39.847 -0400|0.016662248949061972| 0.0|0.0000731468396678| 0.0|
2022-04-14 14:35:39.863 -0400| 0.0166622286820572| 0.0|0.0000712116494436| 0.0|
2022-04-14 14:36:39.880 -0400|0.016662015187426844| 0.0|0.0000702374920336| 0.0|
3.压缩、连续聚合和数据保留
此自助式查询监视设置不需要 TimescaleDB。您可以使用其他扩展或工具来安排快照作业,并且常规的PostgreSQL表可能会存储您保留一段时间的数据而不会出现太大问题。尽管如此,所有这些都是经典的时间序列数据,跟踪PostgreSQL集群随时间推移的状态。
保留尽可能多的历史数据可为此数据库监视解决方案的有效性提供重要价值。TimescaleDB 提供了一些 vanilla PostgreSQL 所不具备的功能,可帮助您管理不断增长的时间序列数据,并提高查询和流程的效率。
对此数据的压缩非常有效,原因有二:
-
大多数数据存储为整数,使用我们的类型特定算法可以很好地压缩(96%以上)。
-
可以更频繁地压缩数据,因为我们从不更新或删除压缩数据。这意味着可以在磁盘利用率非常低的情况下存储数月或数年的数据,并且对特定数据列的查询通常比压缩数据快得多。
通过连续聚合您可以为经常运行的聚合查询维护一段时间内的更高级别汇总。假设您有显示所有这些数据的 10 分钟平均值的仪表板。在这种情况下,您可以编写一个连续聚合,以便在一段时间内为您预聚合该数据,而无需修改快照过程。这允许您在存储原始数据并发现新的查询机会后创建新的聚合。
最后,数据保留允许您在较旧的原始数据达到定义的期限后自动删除这些数据。如果在原始数据上定义了连续聚合,它将继续显示聚合数据,从而为在数据老化时保持所需的数据保真度级别提供完整的解决方案。
这些附加功能提供了一个完整的解决方案,用于长期存储有关集群的大量监视数据。有关详细信息,请参阅为每个功能提供的链接。
4.通过pg_stat_statements实现更好的自助查询监控
我们在这篇文章中讨论和展示的所有内容都只是一个开始。通过一些超表和查询,来自 的累积数据可以快速变为现实。一旦该过程到位,并且您更习惯于查询它,将其可视化将非常有用。
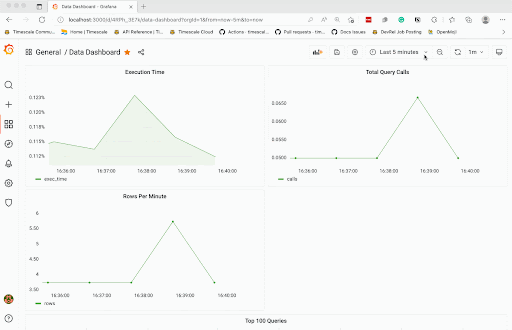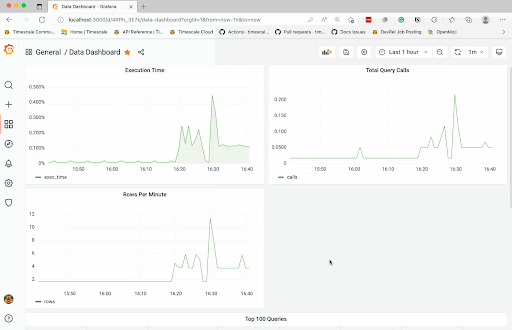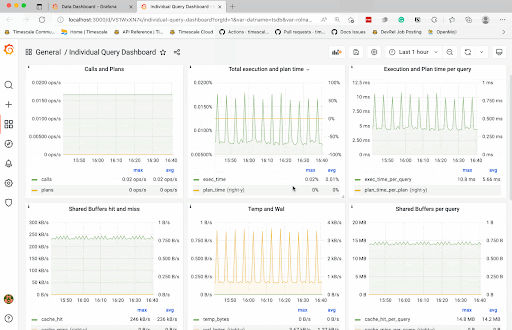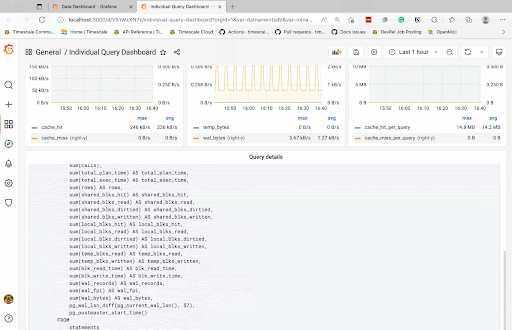
在即将推出的教程中,我们将端到端地介绍此过程,包括设置上面提到的每个附加功能以及使用 Grafana 绘制数据图。
试想一下:在几个小时内,您可以开始进行不断更新和交互式的自助查询监视。
pg_stat_statements在所有 Timescale 云服务中自动启用。如果您还不是用户,可以免费试用 Timescale Cloud(无需信用卡),以访问具有 TimescaleDB 顶级性能、解耦存储和计算、自动缩放、一键式数据库复制和分叉、VPC 对等互连以及对多节点服务的支持的现代云原生数据库平台。
原文标题:Point-in-Time PostgreSQL Database and Query Monitoring With pg_stat_statements
原文作者:Ryan Boozu
原文地址:https://www.timescale.com/blog/point-in-time/
