




Table of Contents
一. 数据源介绍
下载地址:
https://www.lendingclub.com/info/prospectus.action
LoanStats3a.csv
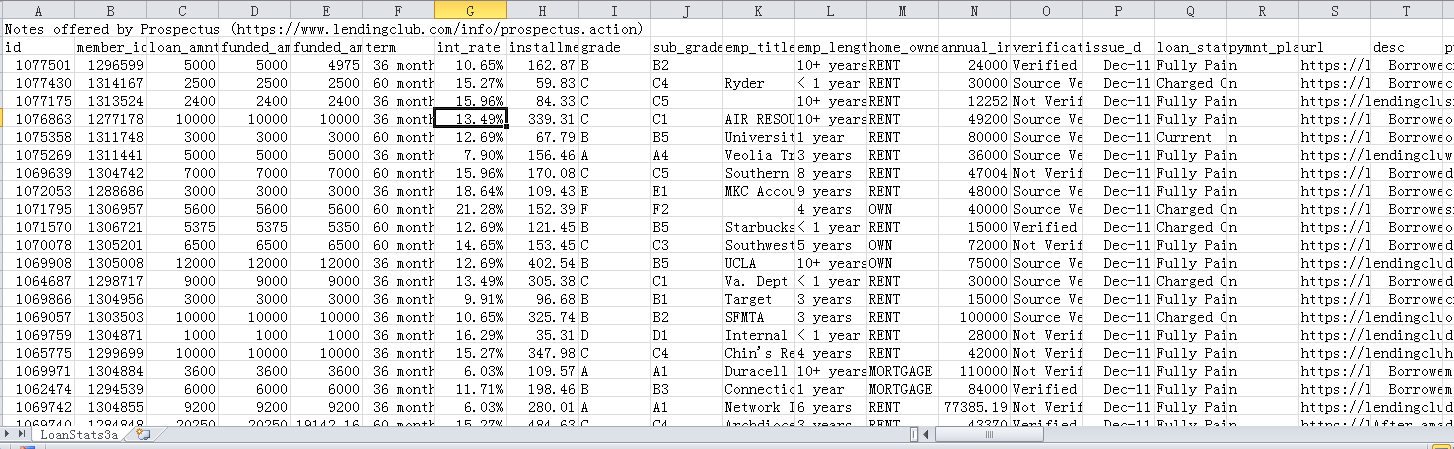
这是一个贷款的数据
二. 数据预处理
我们从上一步的数据中可以看到数据存在的一些问题:
- 首行是URL,第二行才开始是表格数据
- 存在很多的空列
- 有些id、member_id 这类流水id,有url、desc这些描述性字段 等一些对于分析意义不大的数据
- 有部分列只有唯一值,对于分析意义不大
2.1 删除空列
代码:
import pandas as pd
# 跳过首行读取数据
loans_2007 = pd.read_csv('E:/file/LoanStats3a.csv', skiprows=1)
# 删除一些空列及不需要的列
half_count = len(loans_2007) / 2
loans_2007 = loans_2007.dropna(thresh=half_count, axis=1)
loans_2007 = loans_2007.drop(['desc', 'url'],axis=1)
# 将处理完的数据写入到文件
loans_2007.to_csv('E:/file/loans_2007.csv', index=False)
2.2 删除不必要的列并对字符数据进行编码
代码:
import pandas as pd
loans_2007 = pd.read_csv("E:/file/loans_2007.csv")
loans_2007 = loans_2007.drop(["id", "member_id", "funded_amnt", "funded_amnt_inv", "grade", "sub_grade", "emp_title", "issue_d"], axis=1)
loans_2007 = loans_2007.drop(["zip_code", "out_prncp", "out_prncp_inv", "total_pymnt", "total_pymnt_inv", "total_rec_prncp"], axis=1)
loans_2007 = loans_2007.drop(["total_rec_int", "total_rec_late_fee", "recoveries", "collection_recovery_fee", "last_pymnt_d", "last_pymnt_amnt"], axis=1)
print(loans_2007['loan_status'].value_counts())
# 将字符类型转换为数值
loans_2007 = loans_2007[(loans_2007['loan_status'] == "Fully Paid") | (loans_2007['loan_status'] == "Charged Off")]
status_replace = {
"loan_status" : {
"Fully Paid": 1,
"Charged Off": 0,
}
}
loans_2007 = loans_2007.replace(status_replace)
#将只包含唯一值的列进行删除
orig_columns = loans_2007.columns
drop_columns = []
for col in orig_columns:
col_series = loans_2007[col].dropna().unique()
if len(col_series) == 1:
drop_columns.append(col)
loans_2007 = loans_2007.drop(drop_columns, axis=1)
print(drop_columns)
print(loans_2007.shape)
# 将处理完的数据写入到一个新文件
loans_2007.to_csv('E:/file/filtered_loans_2007.csv', index=False)
2.3 删除空值较多的列并对字符列进行编码
代码:
import pandas as pd
# 查看没一列 空值的个数,并将空值较多的列进行删除
loans = pd.read_csv('E:/file/filtered_loans_2007.csv')
null_counts = loans.isnull().sum()
print(null_counts)
loans = loans.drop("pub_rec_bankruptcies", axis=1)
loans = loans.dropna(axis=0)
# 查看列的数据类型,并将字符转为数值类型
object_columns_df = loans.select_dtypes(include=["object"])
print(object_columns_df.iloc[0])
cols = ['home_ownership', 'verification_status', 'emp_length', 'term', 'addr_state']
#for c in cols:
# print(loans[c].value_counts())
# 这两列意义类似,删除其中之一
print(loans["purpose"].value_counts())
print(loans["title"].value_counts())
mapping_dict = {
"emp_length": {
"10+ years": 10,
"9 years": 9,
"8 years": 8,
"7 years": 7,
"6 years": 6,
"5 years": 5,
"4 years": 4,
"3 years": 3,
"2 years": 2,
"1 year": 1,
"< 1 year": 0,
"n/a": 0
}
}
loans = loans.drop(["last_credit_pull_d", "earliest_cr_line", "addr_state", "title"], axis=1)
loans["int_rate"] = loans["int_rate"].str.rstrip("%").astype("float")
loans["revol_util"] = loans["revol_util"].str.rstrip("%").astype("float")
loans = loans.replace(mapping_dict)
# 进行独热编码
cat_columns = ["home_ownership", "verification_status", "emp_length", "purpose", "term"]
dummy_df = pd.get_dummies(loans[cat_columns])
loans = pd.concat([loans, dummy_df], axis=1)
loans = loans.drop(cat_columns, axis=1)
loans = loans.drop("pymnt_plan", axis=1)
# 将处理完成的数据写入到文件
loans.to_csv('E:/file/cleaned_loans2007.csv', index=False)
2.4 预处理完成的数据
代码:
import pandas as pd
# 读取数据源
loans = pd.read_csv("E:/file/cleaned_loans2007.csv")
print(loans.info())
测试记录:
如下可知,我们总共选择了37个特征,每个特征都是数值类型,且没有空值。
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 38428 entries, 0 to 38427
Data columns (total 37 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 loan_amnt 38428 non-null float64
1 int_rate 38428 non-null float64
2 installment 38428 non-null float64
3 annual_inc 38428 non-null float64
4 loan_status 38428 non-null int64
5 dti 38428 non-null float64
6 delinq_2yrs 38428 non-null float64
7 inq_last_6mths 38428 non-null float64
8 open_acc 38428 non-null float64
9 pub_rec 38428 non-null float64
10 revol_bal 38428 non-null float64
11 revol_util 38428 non-null float64
12 total_acc 38428 non-null float64
13 home_ownership_MORTGAGE 38428 non-null int64
14 home_ownership_NONE 38428 non-null int64
15 home_ownership_OTHER 38428 non-null int64
16 home_ownership_OWN 38428 non-null int64
17 home_ownership_RENT 38428 non-null int64
18 verification_status_Not Verified 38428 non-null int64
19 verification_status_Source Verified 38428 non-null int64
20 verification_status_Verified 38428 non-null int64
21 purpose_car 38428 non-null int64
22 purpose_credit_card 38428 non-null int64
23 purpose_debt_consolidation 38428 non-null int64
24 purpose_educational 38428 non-null int64
25 purpose_home_improvement 38428 non-null int64
26 purpose_house 38428 non-null int64
27 purpose_major_purchase 38428 non-null int64
28 purpose_medical 38428 non-null int64
29 purpose_moving 38428 non-null int64
30 purpose_other 38428 non-null int64
31 purpose_renewable_energy 38428 non-null int64
32 purpose_small_business 38428 non-null int64
33 purpose_vacation 38428 non-null int64
34 purpose_wedding 38428 non-null int64
35 term_ 36 months 38428 non-null int64
36 term_ 60 months 38428 non-null int64
dtypes: float64(12), int64(25)
memory usage: 10.8 MB
None
三. 使用逻辑回归模型进行分析
3.1 简单的逻辑回归模型
import pandas as pd
from sklearn.linear_model import LogisticRegression
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import cross_val_predict, KFold
# 读取数据源
loans = pd.read_csv("E:/file/cleaned_loans2007.csv")
#print(loans.info())
# 使用逻辑回归建模分析
lr = LogisticRegression()
cols = loans.columns
train_cols = cols.drop("loan_status")
features = loans[train_cols]
target = loans["loan_status"]
# 使用交叉验证
kf = KFold(n_splits=3, random_state=None)
predictions = cross_val_predict(lr, features, target, cv=kf)
predictions = pd.Series(predictions)
# False positives.
fp_filter = (predictions == 1) & (loans["loan_status"] == 0)
fp = len(predictions[fp_filter])
# True positives.
tp_filter = (predictions == 1) & (loans["loan_status"] == 1)
tp = len(predictions[tp_filter])
# False negatives.
fn_filter = (predictions == 0) & (loans["loan_status"] == 1)
fn = len(predictions[fn_filter])
# True negatives
tn_filter = (predictions == 0) & (loans["loan_status"] == 0)
tn = len(predictions[tn_filter])
# Rates
tpr = tp / float((tp + fn))
fpr = fp / float((fp + tn))
print(tpr)
print(fpr)
print(predictions[:20])
测试记录:
我们可以看到tpr和fpr都是很高的数值,但是我们想贷款利润最大化,就要求 tpr越大越好,fpr越小越好。
这样的结果是达不到我们的要求的,原来是因为样本分布不均匀的原因,正样本数远远大于负样本数。
0.9992428143077808
0.9983367214932545
0 1
1 1
2 1
3 1
4 1
5 1
6 1
7 1
8 1
9 1
10 1
11 1
12 1
13 1
14 1
15 1
16 1
17 1
18 1
19 1
dtype: int64
3.2 逻辑回归+改变样本权重
对比上一章节,我这边只修改了一行代码,就是训练模型时候的样本权重值。
代码:
import pandas as pd
from sklearn.linear_model import LogisticRegression
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import cross_val_predict, KFold
# 读取数据源
loans = pd.read_csv("E:/file/cleaned_loans2007.csv")
#print(loans.info())
# 使用逻辑回归建模分析,改变正负样本的权重项
lr = LogisticRegression(class_weight="balanced")
cols = loans.columns
train_cols = cols.drop("loan_status")
features = loans[train_cols]
target = loans["loan_status"]
# 使用交叉验证
kf = KFold(n_splits=3, random_state=None)
predictions = cross_val_predict(lr, features, target, cv=kf)
predictions = pd.Series(predictions)
# False positives.
fp_filter = (predictions == 1) & (loans["loan_status"] == 0)
fp = len(predictions[fp_filter])
# True positives.
tp_filter = (predictions == 1) & (loans["loan_status"] == 1)
tp = len(predictions[tp_filter])
# False negatives.
fn_filter = (predictions == 0) & (loans["loan_status"] == 1)
fn = len(predictions[fn_filter])
# True negatives
tn_filter = (predictions == 0) & (loans["loan_status"] == 0)
tn = len(predictions[tn_filter])
# Rates
tpr = tp / float((tp + fn))
fpr = fp / float((fp + tn))
print(tpr)
print(fpr)
print(predictions[:20])
测试记录:
tpr 0.5559,这个比较低了
fpr 0.37,1 - 0.37 = 0.63,模型的效果只能分辨出63%的负样本数据。
0.5559257352273071
0.37737941230826094
0 0
1 0
2 0
3 1
4 1
5 0
6 0
7 0
8 0
9 1
10 1
11 0
12 0
13 1
14 0
15 0
16 1
17 1
18 1
19 0
dtype: int64
四. 随机森林
4.1 初步的随机森林
代码:
import pandas as pd
from sklearn.linear_model import LogisticRegression
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import cross_val_predict, KFold
from sklearn.ensemble import RandomForestClassifier
# 读取数据源
loans = pd.read_csv("E:/file/cleaned_loans2007.csv")
#print(loans.info())
cols = loans.columns
train_cols = cols.drop("loan_status")
features = loans[train_cols]
target = loans["loan_status"]
# 使用随机森林进行建模
rf = RandomForestClassifier(n_estimators=10,class_weight="balanced", random_state=1)
#print help(RandomForestClassifier)
kf = KFold(n_splits=3, random_state=None)
predictions = cross_val_predict(rf, features, target, cv=kf)
predictions = pd.Series(predictions)
# False positives.
fp_filter = (predictions == 1) & (loans["loan_status"] == 0)
fp = len(predictions[fp_filter])
# True positives.
tp_filter = (predictions == 1) & (loans["loan_status"] == 1)
tp = len(predictions[tp_filter])
# False negatives.
fn_filter = (predictions == 0) & (loans["loan_status"] == 1)
fn = len(predictions[fn_filter])
# True negatives
tn_filter = (predictions == 0) & (loans["loan_status"] == 0)
tn = len(predictions[tn_filter])
# Rates
tpr = tp / float((tp + fn))
fpr = fp / float((fp + tn))
print(tpr)
print(fpr)
print(predictions[:20])
测试记录:
tpr 高,fpr也高,所以这个模型效果也不理想
0.9763152315473846
0.9406763999260765
0 1
1 0
2 1
3 1
4 1
5 1
6 1
7 1
8 1
9 1
10 1
11 1
12 1
13 1
14 1
15 1
16 1
17 1
18 1
19 1
dtype: int64
4.2 调整参数
我们使用for循环去遍历参数,查看最优的参数
代码:
import pandas as pd
from sklearn.linear_model import LogisticRegression
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import cross_val_predict, KFold
from sklearn.ensemble import RandomForestClassifier
# 读取数据源
loans = pd.read_csv("E:/file/cleaned_loans2007.csv")
#print(loans.info())
cols = loans.columns
train_cols = cols.drop("loan_status")
features = loans[train_cols]
target = loans["loan_status"]
rf_trees = [2,5,8,10,12,15]
rf_depthe = [3,4,5,6,7,8,9,10,11,12,13,14,15]
result = {}
results = []
results2 = []
for t in rf_trees:
for d in rf_depthe:
# 使用随机森林进行建模
rf = RandomForestClassifier(n_estimators=t, max_depth=d, class_weight="balanced", random_state=1)
#print help(RandomForestClassifier)
kf = KFold(n_splits=3, random_state=None)
predictions = cross_val_predict(rf, features, target, cv=kf)
predictions = pd.Series(predictions)
# False positives.
fp_filter = (predictions == 1) & (loans["loan_status"] == 0)
fp = len(predictions[fp_filter])
# True positives.
tp_filter = (predictions == 1) & (loans["loan_status"] == 1)
tp = len(predictions[tp_filter])
# False negatives.
fn_filter = (predictions == 0) & (loans["loan_status"] == 1)
fn = len(predictions[fn_filter])
# True negatives
tn_filter = (predictions == 0) & (loans["loan_status"] == 0)
tn = len(predictions[tn_filter])
# Rates
tpr = tp / float((tp + fn))
fpr = fp / float((fp + tn))
#print("trees:" + str(t) + " " + "depths:" + str(d))
#print('trp:'+ str(tpr))
#print('fpr:'+ str(fpr))
#print("##########################")
result['trees'] = t;
result['depths'] = d;
result['trp'] = tpr;
result['fpr'] = fpr;
# json字典在循环外 顾需要加上copy
results.append(result.copy())
for r in results:
print(r)
测试记录:
{'trees': 2, 'depths': 3, 'trp': 0.6363691431686707, 'fpr': 0.40713361670670856}
{'trees': 2, 'depths': 4, 'trp': 0.6348244843565436, 'fpr': 0.40177416374052854}
{'trees': 2, 'depths': 5, 'trp': 0.6153193809249781, 'fpr': 0.3962299020513768}
{'trees': 2, 'depths': 6, 'trp': 0.6316443044492231, 'fpr': 0.40620957309184996}
{'trees': 2, 'depths': 7, 'trp': 0.6363994305963595, 'fpr': 0.42247274071336166}
{'trees': 2, 'depths': 8, 'trp': 0.6567525820032105, 'fpr': 0.4514877102199224}
{'trees': 2, 'depths': 9, 'trp': 0.6668382954235696, 'fpr': 0.46331546849011274}
{'trees': 2, 'depths': 10, 'trp': 0.6982463579368204, 'fpr': 0.5139530585843651}
{'trees': 2, 'depths': 11, 'trp': 0.691552836417603, 'fpr': 0.5058214747736093}
{'trees': 2, 'depths': 12, 'trp': 0.742375140079353, 'fpr': 0.5989650711513583}
{'trees': 2, 'depths': 13, 'trp': 0.7715722203713239, 'fpr': 0.6409166512659398}
{'trees': 2, 'depths': 14, 'trp': 0.7682103158978708, 'fpr': 0.6521899833672149}
{'trees': 2, 'depths': 15, 'trp': 0.7799012629857346, 'fpr': 0.6686379597116984}
{'trees': 5, 'depths': 3, 'trp': 0.6375806402762213, 'fpr': 0.39807798928109406}
{'trees': 5, 'depths': 4, 'trp': 0.6708362358784868, 'fpr': 0.42912585474034376}
{'trees': 5, 'depths': 5, 'trp': 0.6424872035618014, 'fpr': 0.386065422287932}
{'trees': 5, 'depths': 6, 'trp': 0.6694733016324923, 'fpr': 0.4245056366660506}
{'trees': 5, 'depths': 7, 'trp': 0.6668382954235696, 'fpr': 0.42506006283496583}
{'trees': 5, 'depths': 8, 'trp': 0.6898567404670322, 'fpr': 0.4588800591387914}
{'trees': 5, 'depths': 9, 'trp': 0.7132386346427598, 'fpr': 0.4882646460912955}
{'trees': 5, 'depths': 10, 'trp': 0.7385892116182573, 'fpr': 0.5316946959896507}
{'trees': 5, 'depths': 11, 'trp': 0.7558227579731653, 'fpr': 0.5693956754758824}
{'trees': 5, 'depths': 12, 'trp': 0.7921070963443074, 'fpr': 0.6135649602661246}
{'trees': 5, 'depths': 13, 'trp': 0.8204258412333041, 'fpr': 0.6743670301238218}
{'trees': 5, 'depths': 14, 'trp': 0.8450495199442711, 'fpr': 0.7048604694141564}
{'trees': 5, 'depths': 15, 'trp': 0.8593148983856801, 'fpr': 0.7240805766032157}
{'trees': 8, 'depths': 3, 'trp': 0.6597510373443983, 'fpr': 0.41323230456477544}
{'trees': 8, 'depths': 4, 'trp': 0.6633249538116728, 'fpr': 0.41378673073369066}
{'trees': 8, 'depths': 5, 'trp': 0.6701093376139564, 'fpr': 0.4130474958418037}
{'trees': 8, 'depths': 6, 'trp': 0.6695035890601811, 'fpr': 0.4165588615782665}
{'trees': 8, 'depths': 7, 'trp': 0.667444043977345, 'fpr': 0.4204398447606727}
{'trees': 8, 'depths': 8, 'trp': 0.693248932368174, 'fpr': 0.4553686934023286}
{'trees': 8, 'depths': 9, 'trp': 0.7205379047157525, 'fpr': 0.49011273332101274}
{'trees': 8, 'depths': 10, 'trp': 0.7472514159372444, 'fpr': 0.5276289040842728}
{'trees': 8, 'depths': 11, 'trp': 0.770784747251416, 'fpr': 0.5716133801515432}
{'trees': 8, 'depths': 12, 'trp': 0.8038586182875488, 'fpr': 0.612640916651266}
{'trees': 8, 'depths': 13, 'trp': 0.840264106369446, 'fpr': 0.6978377379412308}
{'trees': 8, 'depths': 14, 'trp': 0.8618287548838477, 'fpr': 0.7238957678802439}
{'trees': 8, 'depths': 15, 'trp': 0.8847866250719326, 'fpr': 0.7567917205692108}
{'trees': 10, 'depths': 3, 'trp': 0.6630826543901627, 'fpr': 0.42080946220661614}
{'trees': 10, 'depths': 4, 'trp': 0.6703819244631554, 'fpr': 0.4178525226390686}
{'trees': 10, 'depths': 5, 'trp': 0.6711693975830633, 'fpr': 0.4126778783958603}
{'trees': 10, 'depths': 6, 'trp': 0.6844958657661205, 'fpr': 0.4317131768619479}
{'trees': 10, 'depths': 7, 'trp': 0.6763485477178424, 'fpr': 0.4245056366660506}
{'trees': 10, 'depths': 8, 'trp': 0.6989126813459733, 'fpr': 0.4500092404361486}
{'trees': 10, 'depths': 9, 'trp': 0.7281400490656329, 'fpr': 0.49454814267233416}
{'trees': 10, 'depths': 10, 'trp': 0.7572765545022261, 'fpr': 0.5348364442801701}
{'trees': 10, 'depths': 11, 'trp': 0.7821425326347033, 'fpr': 0.5806690075771577}
{'trees': 10, 'depths': 12, 'trp': 0.8144289305509284, 'fpr': 0.6204028830160784}
{'trees': 10, 'depths': 13, 'trp': 0.8475633764424387, 'fpr': 0.6995010164479764}
{'trees': 10, 'depths': 14, 'trp': 0.872156767725717, 'fpr': 0.7333210127518018}
{'trees': 10, 'depths': 15, 'trp': 0.8946300390707818, 'fpr': 0.766771391609684}
{'trees': 12, 'depths': 3, 'trp': 0.6893418541963231, 'fpr': 0.44428017002402515}
{'trees': 12, 'depths': 4, 'trp': 0.6845867280491867, 'fpr': 0.4278321936795417}
{'trees': 12, 'depths': 5, 'trp': 0.6869491474089106, 'fpr': 0.42857142857142855}
{'trees': 12, 'depths': 6, 'trp': 0.6898567404670322, 'fpr': 0.43522454259841065}
{'trees': 12, 'depths': 7, 'trp': 0.6869491474089106, 'fpr': 0.4320827943078913}
{'trees': 12, 'depths': 8, 'trp': 0.7059090771420783, 'fpr': 0.45721678063204585}
{'trees': 12, 'depths': 9, 'trp': 0.7362570796862222, 'fpr': 0.49768989096285343}
{'trees': 12, 'depths': 10, 'trp': 0.7641518005875761, 'fpr': 0.5427832193679542}
{'trees': 12, 'depths': 11, 'trp': 0.793470030590302, 'fpr': 0.5893550175568287}
{'trees': 12, 'depths': 12, 'trp': 0.8231819971529818, 'fpr': 0.6318610238403253}
{'trees': 12, 'depths': 13, 'trp': 0.8541357482509011, 'fpr': 0.7039364257992977}
{'trees': 12, 'depths': 14, 'trp': 0.8763970076021443, 'fpr': 0.7311033080761412}
{'trees': 12, 'depths': 15, 'trp': 0.9027773571190599, 'fpr': 0.777490297542044}
{'trees': 15, 'depths': 3, 'trp': 0.699215555622861, 'fpr': 0.457771206800961}
{'trees': 15, 'depths': 4, 'trp': 0.6887966804979253, 'fpr': 0.4387359083348734}
{'trees': 15, 'depths': 5, 'trp': 0.6972165853954023, 'fpr': 0.43688782110515617}
{'trees': 15, 'depths': 6, 'trp': 0.6941575551988369, 'fpr': 0.43836629088893}
{'trees': 15, 'depths': 7, 'trp': 0.6989126813459733, 'fpr': 0.4431713176861948}
{'trees': 15, 'depths': 8, 'trp': 0.7145409940333768, 'fpr': 0.4668268342265755}
{'trees': 15, 'depths': 9, 'trp': 0.7413150801102463, 'fpr': 0.5063759009425245}
{'trees': 15, 'depths': 10, 'trp': 0.7693612381500439, 'fpr': 0.5494363333949362}
{'trees': 15, 'depths': 11, 'trp': 0.7984977435866372, 'fpr': 0.5980410275364997}
{'trees': 15, 'depths': 12, 'trp': 0.8308447163582396, 'fpr': 0.6423951210497135}
{'trees': 15, 'depths': 13, 'trp': 0.8611018566193174, 'fpr': 0.709111070042506}
{'trees': 15, 'depths': 14, 'trp': 0.8829390919829179, 'fpr': 0.7397893180558123}
{'trees': 15, 'depths': 15, 'trp': 0.9112578368719144, 'fpr': 0.7952319349473295}
参考:
- https://study.163.com/course/introduction.htm?courseId=1003590004#/courseDetail?tab=1
「喜欢这篇文章,您的关注和赞赏是给作者最好的鼓励」
关注作者
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文章的来源(墨天轮),文章链接,文章作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
