




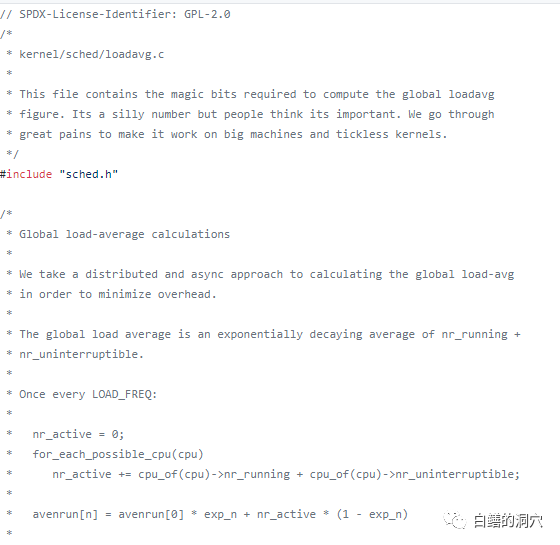

最初的目标是为网络设备的CPU负荷制定一个统一的度量指标。其指标的值就是正在运行的进程数+等待运行的进程数。后来这个指标被UNIX系统引入了,含义还是相同的。这个指标在LINUX上发生了很大变化的起因是因为1993年的一个LINUX开发者遇到的一个问题。当时一个客户提出他的系统CPU很空闲,但是大量的线程在等待IO,而这个等待会十分短暂,很快这些进程就需要大量使用CPU去处理IO了。如果这样的系统也被认为是低负载的系统,是不合理的,于是这个程序员把等待IO的线程也记录在负载中了。下面的这个邮件记录了这段历史。
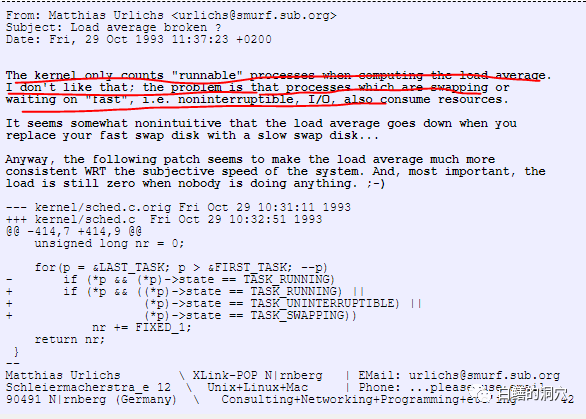
从上面的代码可以看出,当时计算Load是三种类型的,其中TASK_SWAPPING是记录正在换页的状态,这个状态在后来的LINUX版本中被去除了,只剩下了TASK_UNINTERRUPTIBLE,后来被改为nr_uniterruptible)。当时nr_uninterruptible状态的线程只有一种等待事件,就是IO,从此以后,LINUX的LOAD AVERAGE可以反映出CPU使用和IO负载两种负载情况,而不仅仅是CPU的负载,这是十分重要的,因为大多RDBMS系统表现出来的就是这样一种负载状况。如果用网络设备使用的load average定义来评估RDBMS应用的场景,产生的偏差是十分巨大的。随着数据库等重负载应用的高速发展,评价服务器负载不能仅仅看纯CPU的消耗,也要关注正在短暂等待IO,马上就会大量消耗CPU的线程,LINUX上对于LOAD average的这种重新定义是符合信息技术的发展潮流的。
不过让这位偶然修改了几行代码的程序员始料未及的是,随着计算机软硬件的发展,LINUX发展的太快了。随着LINUX的发展,TASK_UNINTERRUPTIBLE也就是nr_uninterruptible状态不仅仅是在等待IO,到了LINUX 1.x的时候,就有十几条等待路径会被标识为nr_uninterruptible。而到了最新的4.x内核,有400多条路径可以让线程处于nr_uninterruptible状态,线程等待系统锁资源也可能会处于nr_uninterruptible状态。
虽然LINUX内核发生了巨变,但是loadavg.c的核心算法并没有发生变化,所以说目前的loadavg已经发生了很大的变化。因为nr_uninterruptible状态的情况变得复杂,因此loadavg作为单一的体现系统负载的指标,可能有些时候无法真正体现出系统负载了。比如我们昨天提到的一种情况,NFS文件系统出现了问题,访问这个文件系统的所有的线程都会被标识为nr_uninterruptible状态,并且长久的挂死在系统中。这时候实际上系统的负载是十分低的,但是我们还是可能看到十分高的load average。这种情况下load average就出现了严重的偏差。
如果单一的使用loadavg来进行负载的分析会存在一定的偏差。不幸的是,现在好多负载均衡的策略都是基于loadavg的,比如oracle rac的Load balance就是根据不同实例的loadavg来确定新连接会话的位置的,K8S和云平台也会根据loadavg来调度POD和vm,其目的也是为了通过CPU与IO负载作为调度资源的最重要的依据。
如果loadavg有时候会出现不准确的情况,会如何影响这些使用loadavg作为资源调度基准的应用呢?实际上以前我们在Oracle RAC上就经常能看到多个RAC节点中,实际上CPU使用率都差不多,但是连接的会话数总是会出现极为不均匀的情况,这样就会导致业务高峰期,多个RAC节点之间的资源出现严重的不均衡。这种情况有很大一部分原因就出现在loadavg计算出现偏差的时候。
看样子loadavg有时候会不靠谱,但是我们还不得不使用它。既然了解了loadavg的原理,那么我们该如何更好的使用它呢?在运维自动化系统中,我们不能够单一的使用这个指标来判断系统的负载。如果我们需要分析CPU负载,我们可以单一的通过runable队列的深度来进行判断,再结合CPU的使用率来定位负载。对于IO,我们可以通过b队列的深度和WIO的比例来判断IO的负载。
如果我们发现了loadavg比较高,CPU使用率也比较高,r队列也比较大,那么我们就一定能够确定CPU已经出现了瓶颈,并已经影响了系统的性能吗?答案是不一定。因为哪怕r大于CPU的核数,也不一定说明CPU资源就一定影响了性能。不同的应用特点与不同性能指标的CPU下,这些都是变数。如果我们真的需要判断CPU调度是否已经成为了瓶颈(其实目前大多数情况下我们不需要这么做),那么/proc/schedstat,/proc/sched_debug等统计数据数据可以成为精准分析的重要依据。比如下面的awk命令就是分析sched_debug文件,取出等待时间最长的20个进程调度。从等待时间的长短就可以更为精细的分析CPU资源调度是否存在了瓶颈。在缺省情况下,kernel.sched_schedstats参数是0,我们是无法跟踪CPU调度等待的,如果要做下面的分析首先要设置该参数为1:

一定要记得分析完,要把这个参数恢复为0,否则会产生较大的系统开销。
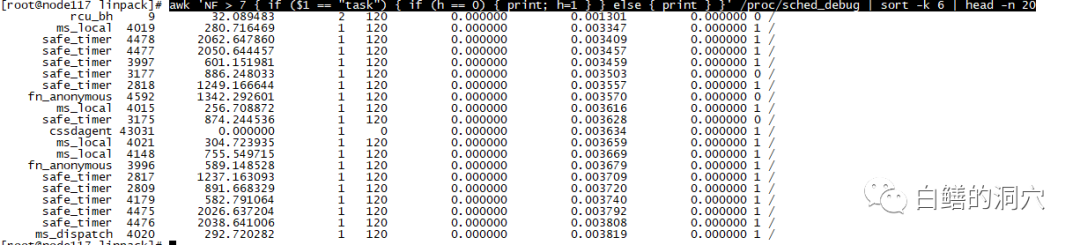
第六列就是wait-time,在一个空闲的系统中,所有的调度等待都是0。我们给系统用linpack加点压力后再来看这个数据。
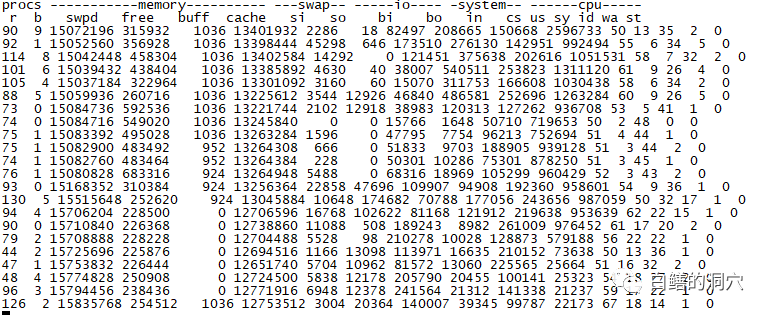
这时候r队列已经很高了,再看看结果:
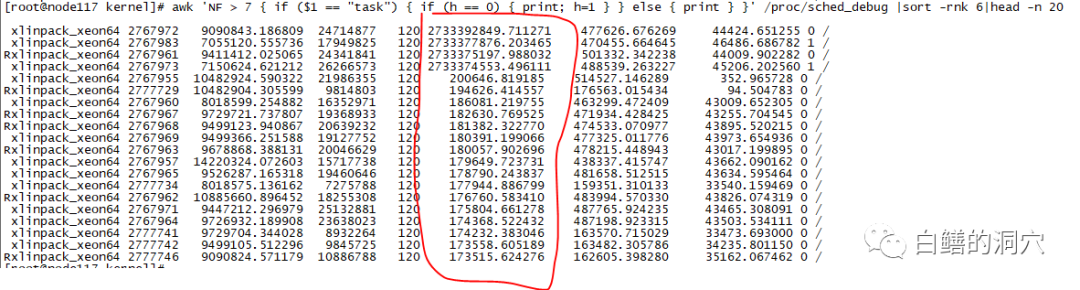
通过上面的方式进行分析,根据wait_time就可以了解CPU调度的等待时间,如果等待时间变长,那么CPU瓶颈可能真的成为影响系统性能的主要因素了,否则你就放宽心吧。
似乎今天老白讲的东西对于一个运维人员来说,已经太复杂了。绝大多数内容可能是屠龙技,平时都用不到。不过知识这东西,能够多了解一些总是好的,保不齐啥时候还真的就用到了呢。
