




以时间轴的方式对不同时期的有代表性的论文(从理论研究、原型系统、 生产系统三个维度分类)进行了梳理,带你简要回顾一下OCC在学术界及工业界的发展历程。
生产系统——在验证阶段使用Paxos提交协议发现冲突
Megastore: Providing Scalable, Highly Available Storage for Interactive Services CIDR 2011
concurrent6
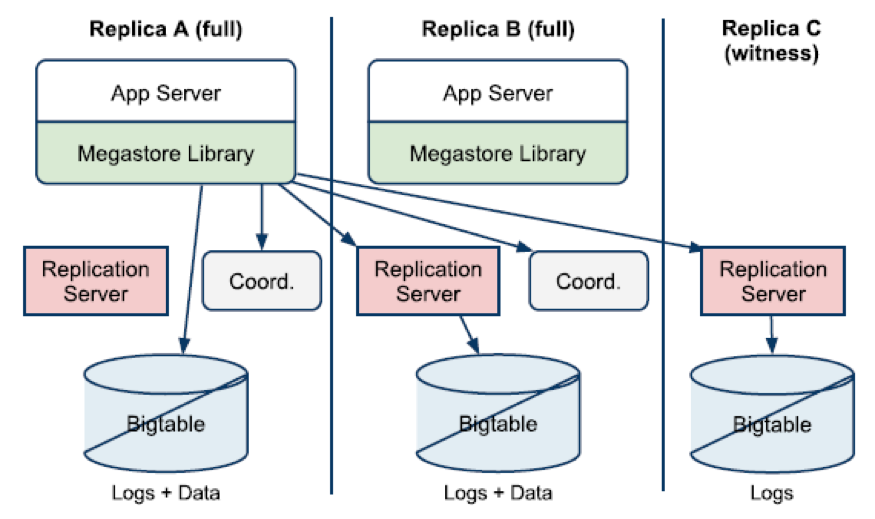
Megastore是少有的在内核层实现OCC的生产级分布式数据库系统,在Entity Group的数据分区级别使用MVOCC实现了串行化隔离级别的事务,同一分区一次只能执行一个事务,分布多副本间可以并发执行事务。一个OCC事务三个阶段的实现大致描述如下:
1. 读取阶段
① 在任意副本均可发起强一致读;数据更新缓存在应用的事务私有内存
② 从多数派副本中获取最新事务提交时间戳及事务日志的位置(可以通过查询本地coordinator中副本的数据状态做优化)
③ 选择一个合适的副本(综合考虑本地性、响应时间、事务提交时间等),使用Paxos协议同步事务日志并将其应用到本地Bigtable中
④ 若选择了本地副本,则异步更新coordinator中副本数据状态为有效
⑤ 根据获取的事务提交时间戳从本地Bigtable中读取数据
2. 验证阶段
① 从强一致读得到的事务日志中获取下一次写入事务日志的位置
② 选取一个比最新事务提交时间戳更大的值作为本次事务提交时间戳
③ 将事务私有内存中的更新打包到一个事务日志中
④ 发起一次完整的两阶段Paxos协议实例(可以优化为一阶段Paxos协议),一个事务日志位置只能由一个事务提交成功。如果成功,则将未成功接受当前事务日志的副本所对应的coordinator中的数据状态设置为失效,通知应用事务已提交;如果失败(prepare阶段发现提交的内容与达成一致的内容不匹配),则终止事务并重新执行
3. 写入阶段(异步执行)
将更新数据异步写入Bigtable,清理应用事务私有内存数据
由上述流程可以看出,Megastore将事务局限在一个EG且只能串行化执行,并发冲突的控制粒度在事务级别,导致事务吞吐率非常低。虽然论文[15]中提出了一种提高Megastore事务提交吞吐量的可能方案,但Google内部最终还是放弃了Megastore,转而使用了Spanner(使用MV2PL并发控制技术),因为Spanner通过2PL+2PC实现了跨分区的事务。
生产系统——MVCC+OCC在内存数据库中的落地
High-Performance Concurrency Control Mechanisms for Main-Memory Databases VLDB 2012
真正把OCC在生产系统中落地的是内存数据库Hekaton,论文使用全内存的无锁哈希表存储多版本数据,数据的访问全部通过索引查找实现,一个OCC事务的生命周期实现如下:
- 正常处理阶段(读取阶段)
① 获取事务开始时的当前时间作为读时间戳并赋予一个唯一的事务号,事务状态设置为active
② 在事务处理的过程中维护读集(指向读版本的指针)、写集(指向写版本的指针)、扫描集(重新执行扫描时需要的信息,如扫描条件)
③ 更新数据时(总在最新的版本上更新),版本可更新的判断:
a. 更新数据的end域无效或事务号所属事务已经中止
– 将原始版本的end域原子更新为当前事务号,防止其它事务的并发修改
– 链接新的数据版本并设置begin域为当前事务号
– 可能会出现更新begin域的事务处于preparing状态的数据版本,采取投机更新策略并记录提交依赖
b. 更新数据的end域事务号所属事务处于active或preparing状态
写写冲突,更新事务需要中止
④ 读取数据时,版本可见性的判断:
a. 读取数据的begin/end域都是有效的时间戳
如果读时间戳在begin/end之间,则可见;否则不可见
b. 读取数据的begin域是事务号
– 如果事务号所属的事务状态为active,仅对事务号所属事务可见
– 如果事务号所属的事务状态为preparing,读时间戳如果比事务提交时间戳大,则采取投机读策略并记录提交依赖(引入了级联中止问题)
– 如果事务号所属的事务状态为aborted,直接忽略
– 如果事务号所属的事务状态为commited,读时间戳如果比事务提交时间戳大,正常读取
c. 读取数据的end域是事务号
– 如果事务号所属的事务状态为active,仅对事务号所属事务不可见
– 如果事务号所属的事务状态为preparing,读时间戳如果比事务提交时间戳大,则采取投机忽略策略并记录提交依赖(引入了级联中止问题); 读时间戳如果比事务提交时间戳小,则- 可见
– 如果事务号所属的事务状态为aborted,可见
– 如果事务号所属的事务状态为commited,读时间戳如果比事务提交时间戳小,则可见 - 准备阶段(验证阶段)
① 获取当前时间戳作为提交时间戳,事务状态设置为preparing
② 读集有效性验证,检查读集中的版本是否依然可见;重新执行扫描集检查是否存在幻读
③ 等待提交依赖全部完成或当前事务是否已被其它事务设置为中止
④ 同步写redo日志
⑤ 将事务状态设置为commited - 后处理阶段(写入阶段)
① 如果提交,将新数据的begin域和旧数据的end域设置为提交时间戳
② 如果中止,将新数据的begin域设置为无效,尝试将旧数据的end域设置为无效(如果已被其它事务更新则忽略)
③ 处理提交依赖,如果提交,则减少依赖该事务的其它事务的提交依赖计数;如果中止,则通知依赖该事务的其它事务中止
④ 清理事务表
生产系统——应用层OCC在分布式环境的价值
F1: A Distributed SQL Database That Scales VLDB 2013
F1是Google内部研发的分布式关系数据库,存储层基于Spanner,自建SQL层,用于Google最重要的广告业务。F1在Spanner之上基于行级的修改时间戳列实现了乐观事务并将其设置为默认配置,论文提到使用乐观事务有如下优缺点:
• 优点
– 容忍客户端的不正确行为(如无意义的长事务或未正常结束的事务)
– 长事务/交互式事务友好(没有锁超时导致中止的问题/用户查询期间不持有锁)
– 服务端重试友好,对用户透明
– 事务更新状态保存在客户端,利于容灾及负载均衡
– 易于实现投机写(检查读数据的版本变更发现冲突)
• 缺点
– 幻读问题需要借助其它手段避免
– 高数据竞争场景下的低事务吞吐率
其中关于OCC优点的描述来自生产级分布式环境运维的最佳实践经验,虽然只是应用层的简单实现,但也从另一方面验证了OCC在现代分布式数据库环境中的技术价值。
以上为分布式技术专题之并发系列三:乐观并发控制之生产系统,「分布式技术专题」是由hubble数据库团队精心整编,专题会持续更新,欢迎大家保持关注。
