




如果我说有一个智能预测的模型,可以用于预测数据库的健康状态变化,达到95%以上的准确率,MSE小于5,你是不是觉得挺牛的。我们刚刚开始做这方面的工作的时候也是这么认为的。实际上随着智能预测工作的深入,我们越来越感到这项工作的复杂和我们对这件事的难度的估计不足。
我们是从2017年开始研究Oracle健康指标的智能预测问题的,通过历史数据做序列预测,从而能够在某些(部分,不是全部)数据库故障发生前提前预测到数据库健康状态的变化。
要做这个工作,最常规的方法是监督学习的方法,通过数据标注完成训练集,然后训练模型。在实际工作中我们发现这是一个几乎无法完成的任务,全量数据集通过专家标注的工作量是海量的。后来我们受周志华的一篇文章的启发,采用半监督学习的方法构建模型,用于预测生产环境中数据库健康状态的变化。
2017年下半年,我们和南京大学李文中老师的团队共同开始了这方面的研究工作,利用我们采集的用户生产环境的数据进行建模。几个月后就取得了十分重大的成果,预测模型针对系统运行状态按照A/B/C/D四种状态进行分类,经过500论的训练后,采用多层感知机MLP的算法就获得了接近90%的正确率。
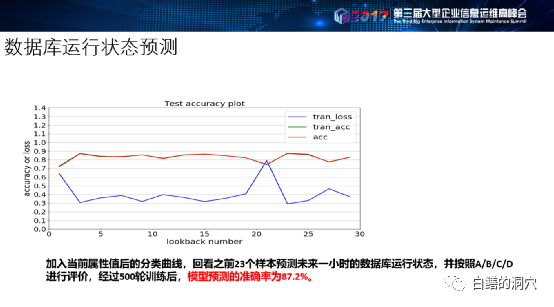
初步工作的结果是令人吃惊的,通过对第一批用户数据的处理,我们居然获得了MSE在2左右,R2 9.1+的结果。这种效果是我们刚刚开始做这项工作的时候想都不敢想的。
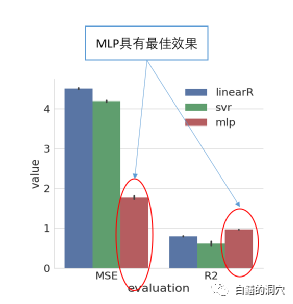
这个成果让我们受到了极大的鼓舞,在2018年初的第三届大型企业信息运维峰会上,我们十分高兴的和与会者分享了这一成果。从哈尔滨回来后,我们继续优化模型,有效性很快就超过了95%。于是我们就走出实验室,在D-SMART中开启了智能化预测的功能。
右侧的那个比较难看的人脑图标标识了右侧的四个指标是通过深度学习模型预测的,其中第一个点是当前值,后面三个点是预测值,每个点之间的间隔是3分钟。也就是说,我们的模型可以用来预测未来9分钟左右数据库的健康状态,而且准确率达到了95%+,是不是很牛X的事情。
事实上,我们很快就被打脸了,经过三个月的模型训练,2个月的实际运行后,从客户现场反馈回来的数据的MSE和我们在实验室的结果相差不大,有效率甚至更高于我们实验室的成果。不过和数据上的好看相反的是,客户对这个我们认为不错的结果并不买账。他们反馈回来一个十分重要的情况,那就是:“系统正常的时候,你们的预测总是准的,而系统不正常的时候,你们的预测基本上是不准的,我们不需要你们给我们预测正常情况,只需要你们给我们预测不正常的情况”。
刚开始我们还觉得不太服气,认为现场效果不够好是训练不足或者训练数据的代表性不好,有效率和MSE指标那么好,怎么能说模型不好呢,随着训练集的不断丰富,预测会越来越准确的。于是用户找出一个系统,用95分画了条线,然后计算MSE和R2,发现MSE和R2和我们的模型居然也差不了多少。
这下子点醒了我们,原来我们筛选算法好坏的时候是根据MSE和R2的,而实际上客户的数据库系统大多数情况下都是处于十分良好的运行状态的,出问题的时候极少,甚至不宕机,用户根本不清楚数据库出过问题。于是我们做健康状态预测仅仅是通过历史健康分去预测下几个点的健康分。根据所有的预测数据去计算MSE等指标,再根据这些指标再去调参和筛选算法。在这种情况下,一个过拟合的算法或者一个波动很小的算法很可能会获得比其他算法更好的MSE和R2。然而通过这样的方式筛选出来的算法并不一定是最有效的。
因为这个原因,为了避免智能模型预测带来的误解,我们在2019年的D-SMART 1.8以后的版本中关闭了智能预测这个功能,并且开始了新的算法研究工作。
基于这个认知,我们不再纠结MSE和R2,而是通过真正的效果去筛选算法。这种筛选工作需要专家大量的介入,算法工程师找到一些推荐的算法并进行调参优化后,由专家来评判算法和参数的好坏,而不是直接根据MSE和R2。实际上在这种比较复杂的工作场景中,AUTOML的效率大大的降低了。这时候幸亏D-SMART 1.9获得了不少用户的认可,帮助我们获得了大量的用户生产数据,同时D-SMART数据中心分析功能也可以帮助专家发现系统中存在的问题点,从而帮助我们提高标注数据的准确性。通过专家模型标注的数据更为准确,也使训练集的质量得到了极大的提升。经过一年多的工作,新的数据库健康状态预测智能模型逐渐成熟了。我们把这一代算法称为“健康预测2.0”。
新的模型在故障预测中的效率已经有了脱胎换骨的变化,下面我们来看几个例子。这几个例子是使用了我们实验室中的用户真实的数据,原始数据共有640个特征。去掉单一唯一的特征和零重要性的特征,最终选择的特征共有213个(2017年版本时候我们只选择了41个特征)。数据总样本量49175个,按照80%训练,20%测试划分,在划分训练集与测试集的时候,我们严格按照测试集中的数据绝对不和训练集重合的原则进行分组,也就是说测试的数据肯定是没有参与过训练的。
这个模型的测试mse很不好看,19.17865,比2018年的时候要差很多。不过样子难看没有关系,是不是管用才是关键。
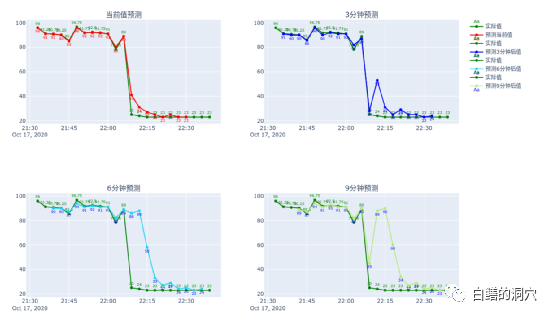
大家看上面这个例子,在一次数据库实例HANG 住,数据库无法提供任何服务,3分钟预测模型十分准确的提前3分钟发现了这个健康状态的突降。而6分钟预测与9分钟预测都出现了延迟。如果这是在生产环境上,运维人员将在数据库HANG 死前3分钟得到风险的预警,有可能在问题恶化前完成问题的处置。
再看下一个案例,这个例子更为复杂,系统从健康状态出现严重下降,然后在较为严重的亚健康状态运行了3个多小时,随后逐渐恢复正常。因为时间段是在半夜,所以用户对这个情况并无感知,不过有部分后台任务延迟到第二天业务高峰期才结束。
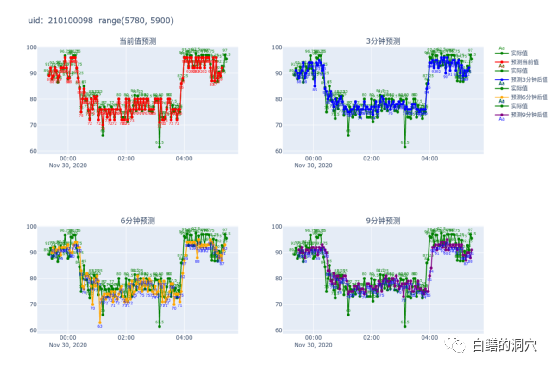
在这个案例里,3分钟预测在0:21分再次正确的预测到了这个健康状态的下降,比我们的专家模型提前了3分钟。从数据上看,健康状态预测模型预测的分值的准确度下降了,但是对于趋势的预测吻合度大大提高了。特别是在系统有问题的时候,对于健康状态突降趋势的预测准确度比以前的算法有了很大的提高。所以虽然MSE比以前差了很多,但是实际预测效果却好了很多。
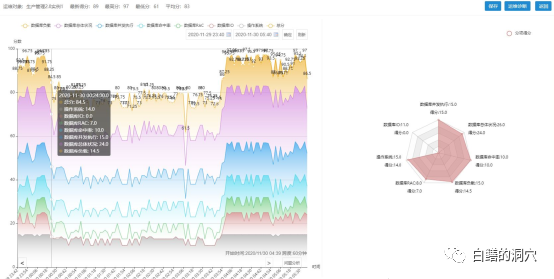
通过D-SMART的分析发现,在这个时间点上,系统的负载并不高,但是后端存储的IO性能出现了下降,引起了这个数据库实例的健康状态下降。随着时间的推移这个故障引起了数据库健康状态的不断下降。到凌晨3点多的时候,数据库健康达到了最低点。此时共享池的性能也下降了数十倍,RAC 消息发送延时增加了5倍以上。如果此时数据库负载较高,那么就可能会出大问题了。
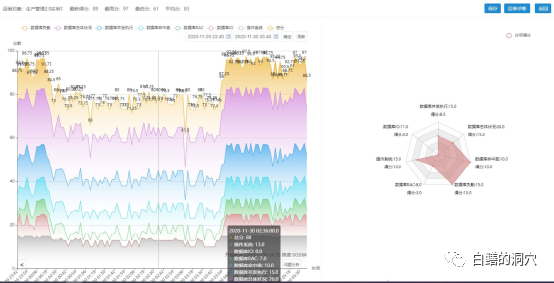
幸亏当时这个数据库实例上的负载很低,所以没有出现宕机等问题。到了三点半以后,随着后端存储负载的下降,数据库健康状态逐步恢复。
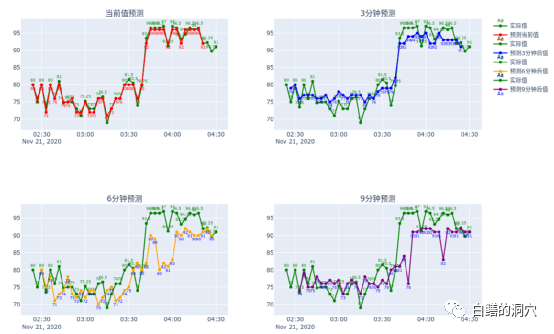
从上面的图上可以看到,智能模型也较为准确的提前3分钟预测到了数据库健康状态的由坏转好。
从2017年我们懵懵懂懂的进入这个领域后轻狂的大喊“SO EASY”,到2018年经历了巨大失败后的再出发,在Oracle数据库状态预测方面,我们目前还是仅仅走出了小小的一步。这一小步成果的取得是2年的汗水,其中有我们自己的努力,也有客户对我们的支持,还有南京大学、INTEL、腾讯等合作伙伴对我们的帮助。
从目前的实践上看,3分钟预测的效果还是令人满意的,而6分钟和9分钟预测的效果离实战需要还有很大的距离。特别是对于gray failure的预测,一度在运维自动化领域大家都认为gray failure是不可预测的。从目前我们的实践来看,一部分的gray failure是可预测的。
而对于Oracle数据库宕机的预测则更为复杂,很多宕机是因为BUG触发,甚至是某个核心进程被杀掉导致的,这种宕机可能之前并无任何预兆,数据库实例也是瞬间宕掉。不过对于因为某些系统内部的隐患导致的数据库HANG死或者宕机,智能预测模型还是可以发挥一定的作用的。
路漫漫其修远兮,吾将上下而求索。智能化预测的路太远,我们也才刚刚出发,通过智能模型的3分钟预警还无法让运维人员有足够的时间定位故障,消除故障隐患,恢复系统运行。不过对于某些行业关键应用来说,减少3分钟的故障时间已经价值巨大了。这项工作我们将会继续下去,在越来越多的用户加入到我们的工作中后,算法的优化也会提速。九分钟预测是我们的下一个目标,达到9分钟预测,我们就能够给运维人员充分的时间去做相关的处置。
