




Oracle 自动调优是在 10g 引入的一个新特性。它可以从多个方面对 SQL 语句进行分析,给出详细的优化建议。并且在 11g 当中,这些优化建议可以被自动实施。与其它第三方调优工具相比,由于自动调优是 Oracle 自己开发的工具,它可以借助服务端优化器运行在调优模式下对语句进行深入分析,从而获得效果更好的调优建议。但在另一方面,它也会增加服务器的负载。
我们可以通过调优接口包 DBMS_SQLTUNE 的方法,创建调优任务(create_tuning_task),对一条或者多条语句进行调优。
8.3.1 创建调优任务
根据调优目标语句的来源不同,DBMS_SQLTUNE 中存在多个创建调优任务接口。
• 直接输入一条 SQL 语句文本;
• 通过 SQL_ID 从缓存中查找一条语句;
• 通过 SQL_ID 从 AWR 的历史数据中查找一条语句;
• 从 SQL 语句集(SQLSET)中获取部分或全部语句;
• 从 SQL 性能分析器(SQL Performance Analyzer)任务中获取部分或全部语句;
创建调优任务后,会在相关数据字典当中存储该任务的所有数据,并且存在一个唯一的任务名称(可以通过接口指定、也可以由系统自动生成),例如目标语句、任务的参数设置等。只要这些 数据还存储在数据字典中,我们可以根据需要修改参数、多次执行该任务,获得不同调优结果。
除了 DBMS_SQLTUNE 提供的接口,我们还可以通过调用所有建议器的通用封装包
DBMS_ADVISOR 中的接口(CREATE_TASK)创建 SQL 调优建议器的任务。
8.3.2 SQL 调优建议器的参数
创建了 SQL 调优任务后,我们可以修改调优任务的参数改变调优任务执行过程中的行为。所有优化器参数及其初始值可以通过视图“dba_advisor_def_parameters”查看。SQL 调优建议器本身特有的参数包含以下参数:
表 8-1 调优建议器的参数
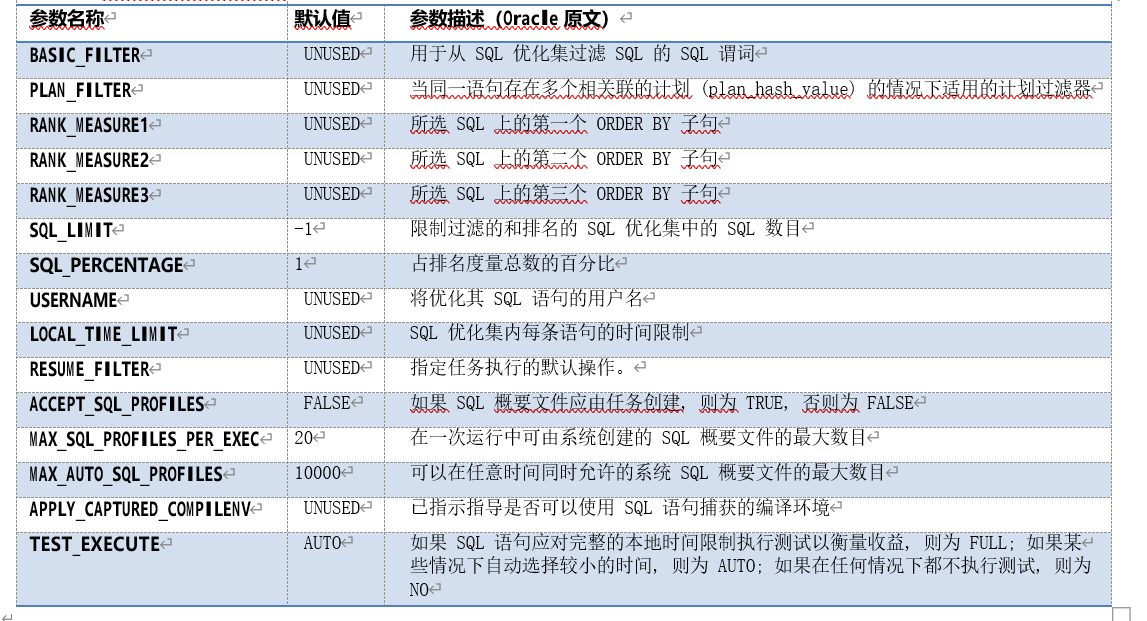
其中,
• BASIC_FILTER 和 RESUME_FILTER 为过滤谓词,即一个 WHERE 条件子句。它是调优任务执行(或者暂停任务继续)时,建议器进行选择符合条件的语句或执行计划进行分析;
• RANK_MEASUREn 为排序参数,即一个 ORDER BY 子句。当语句选择数量或者整体调优时间受限使,排在前面的语句会被优先分析;
• SQL_LIMIT 和 SQL_PERCENTAGE 限制了被分析的 SQL 数量;
• USERNAME 限制仅分析该用户所解析的语句;
• ACCEPT_SQL_PROFILES 决定了调优过程中,是否自动接收 SQL 调优配置;
• TEST_EXECUTE 决定 SQL 分析器(SQL Analyzer)是否执行语句以获取实际的性能改进数据;自动(AUTO)模式下,分析器会根据当前任务的剩余可用时间限制决定;
除了 SQL 调优建议器本身的参数外,还有一些参数是所有建议器共用的参数,参数列表如下:
表 8-2 建议器公共参数

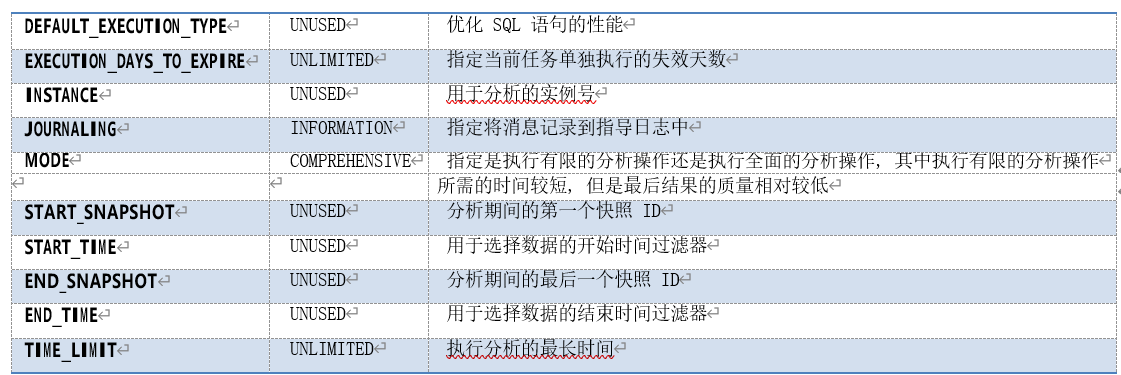
其中,
• DEFAULT_EXECUTION_TYPE:任务默认的执行类型,对于 SQL 调优建议器来说,其值仅有“TUNE SQL”;
• MODE 为优化模式,参数值可以为 LIMITED 和 COMPREHENSIVE:
o LIMITED:仅作统计数据分析、访问路径分析和 SQL 语句结构分析,并且不会产生
SQL 调优配置的辅助数据;
o COMPREHENSIVE:对语句做全面分析并根据需要产生 SQL 调优配置的辅助数据;
上面显示的都是参数的初始设置值,在创建优化任务时,会将这些默认值作为任务的初始参数值。建议器的参数初始值可以通过接口 DBMS_ADVISOR.SET_DEFAULT_TASK_PARAMETER 修改。任务创建后,我们可以通过视图“dba_advisor_parameters”查看其参数值,并且可以通过
DBMS_ADVISOR.SET_TASK_PARAMETER 修改任务的参数设置。
8.3.3 自动调优分析
通过接口(execute_tuning_task)可以启动已经创建的调优任务对目标语句进行调优。调优任务启动后,优化器就运行在调优模式下对语句进行分析、输出调优结果。当优化器运行在普通模式 下时,它的输出结果是找到的最优的执行计划。而当优化器运行在调优模式下时也称为自动调优优 化器(Automatic Tuning Optimizer),它还可以调用其他组件,例如 SQL 分析器(SQL Analyzer), 从多个方面对语句进行分析,找到语句的性能瓶颈,并输出优化语句性能的建议、具体措施以及其 它辅助数据。这些被分析的方面包括:
• 对象统计数据(Statistics);
• 访问路径(Access Path);
• SQL 结构重写(Restructure SQL);
• 并行执行(Parallel Execution);
• 备选执行计划(Alternative Plan);
• SQL 补丁(SQL Patch);
• SQL 配置(SQL Profile);
对象统计数据(Statistics)分析
对象统计数据分析是对目标语句中涉及的对象(表、索引)的统计数据进行分析,以确认是否存在未收集统计数据或者当前统计数据过于“陈旧”的对象。在分析过程中,分析器会再扫描对象
(根据其存储大小决定是否取样)读取和计算其当前的统计数据。如果对象不存在统计数据,或者 对象已有统计数据过于“陈旧”(与获取的实际数据比较相差较大),则会建议用户更新该对象统 计数据,并通过 SQL 分析器利用获取的统计数据对陈旧数据进行调整后重新生成执行计划。如果在这种情况下生成的执行计划优于当前执行计划,则会将这些统计数据作为 SQL 优化配置(SQL
Profile)的辅助数据存在数据字典中,并建议用户采用 SQL 优化配置。
对象是否存在统计数据,通过查询数据字典表可以判断。以下示例中,语句中存在未收集统计 数据的对象,调优建议器则会建议用户更新该对象的统计数据,并给出实际操作方法:



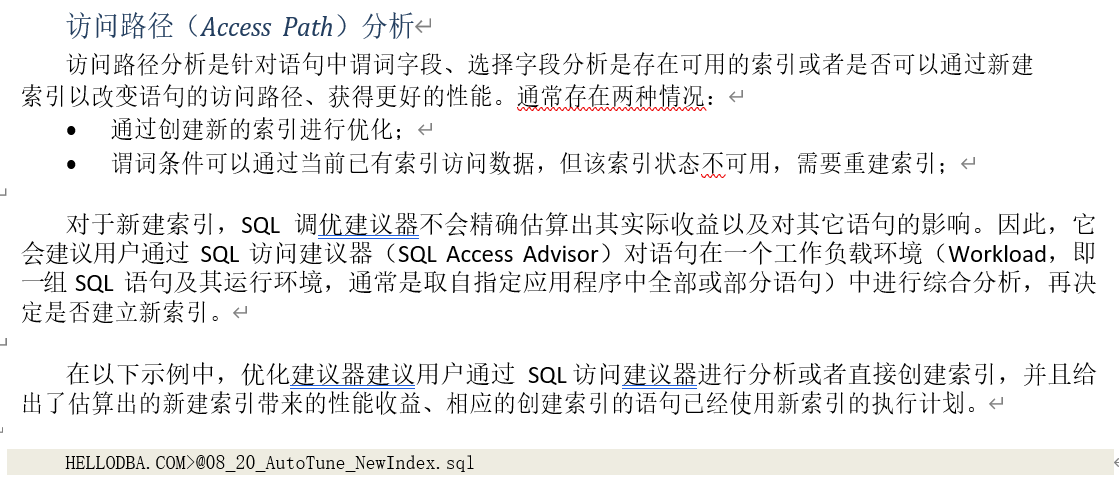


注意,对于建立在多个字段上的复合索引,调优建议器在给出创建索引的语句时,会将字段按照选择性高低排列,选择性最好的字段放在最前面。
当调优建议器找到可以改善语句的新索引时,如果当前存在被新索引的前缀字段覆盖的索引,也会建议删除该重复索引:
示例:
SQL 结构重写(Restructure SQL)分析
SQL 结构重写分析是从语句的语法、语义以及物理设计多个方面分析导致的性能问题,并给出具体建议重写语句,使优化器能生成更好的执行计划。通常,语句结构导致的性能问题有以下几种 情况:
• 执行计划中存在笛卡尔乘积关联(Cartesian Join),导致笛卡尔积操作有两个主要原因:
o 查询语句中某张表没有与其它表的关联条件————用户需要检查语句逻辑关系,为 该表加上关联条件或将该表从语句中剔除;
o ORDERED 提示导致优化器产生笛卡尔积操作————用户需要用其他方式,如使用
LEADING 提示,来消除 OREDED 提示带来的负面影响、并同时满足 ORDERED 提示所需要的效果;
• 子查询无法被反嵌套(Unnest),导致无法消除由于“NOT IN”子句带来的过滤(Filter) 操作————用户可以考虑用“NOT EXISTS”代替“NOT IN”,但是如果关联字段存在
NULL 值的话,需要有额外的条件来保证逻辑一致;
• 语句中存在联合(UNION)操作,从而导致代价高昂的消除重复值的操作————如果用户能确认结果集本身就不存在重复值、或者重复值是可被接受,则可以用“UNION ALL”代替“UNION”;
• 在谓词条件中,索引字段上存在表达式,导致执行计划无法使用该索引:表达式可能是用
户显式地写在语句中的;也可能是由于关系表达式左右数据类型不匹配所导致的隐式类型转换加上了类型转换函数————用户可以考虑重新关系表达式、消除索引字段上表达式或函数,使执行计划能使用索引访问数据;或者建立新的函数索引,但建议使用 SQL 访问建议器进行综合评估;
• 在谓词条件中,索引字段的关系表达式是一个不等于匹配的关系,导致执行计划无法采用 索引访问数据————用户可以考虑通过用等于匹配关系式改写语句以使执行计划能利用 索引,通常这种情况适用于唯一值数较少的位图索引字段;
此外,在语句中存在一些关键字、特殊函数或者关联关系会导致查询转换器(Query
Transformer)无法对语句进行视图合并(View Merge)。但移除关键字或者改写语句关联关系可能会导致语句发生逻辑变化,因此,调优建议器只会给相关提示、并不给出具体的解决建议。通常导 致查询转换器无法对语句进行视图合并的原因有:
• 优化程序不能合并包含 “ORDER BY” 子句的视图, 除非此语句为 “DELETE” 或 “UPDATE”, 并且父查询为此语句中的顶级查询。
• 优化程序不能合并包含 “ROWNUM” 伪列的视图。
• 优化程序不能合并包含设置运算符的视图。
• 优化程序不能合并包含窗口函数的视图。
• 优化程序不能合并包含 “SPREADSHEET” 子句的视图。
• 优化程序不能合并包含嵌套的聚集函数的视图。
• 优化程序不能合并包含不带 “GROUP BY” 子句的聚集函数的视图。
• 优化程序不能合并包含分组函数的视图。
• 优化程序不能合并包含带 “ROLLUP”, “CUBE” 或 “GROUPING SETS” 选项的 “GROUP BY” 子句的视图。
• 优化程序不能合并包含 “START WITH” 子句的视图。
• 优化程序不能合并包含 NO_MERGE 提示的视图。
• 优化程序不能合并包含 “CURSOR” 表达式的视图。
• 优化程序不能合并包含 “WITH” 子句的视图。
• 优化程序不能合并带包含外部联接中所涉及的嵌套表列的谓词的视图。
• 如果复杂视图的父查询包含 “START WITH” 子句, 优化程序不能合并此复杂视图。
• 如果复杂视图的父查询为 “SELECT FOR UPDATE”, 优化程序不能合并此复杂视图。
• 仅当外部联接右侧的视图包含带单个 “WHERE” 子句的单个表时才能合并。
• 如果复杂视图的父查询包含对 “ROWNUM” 伪列的引用, 优化程序不能合并此复杂视图。
• 如果复杂视图的父查询包含 “GROUP BY CUBE” 子句, 优化程序不能合并此复杂视图。
• 如果复杂视图的父查询包含 “GROUPING SETS” 子句, 优化程序不能合并此复杂视图。
• 如果复杂视图的父查询的 “SELECT” 列表包含 “SEQUENCE” 列, 优化程序不能合并此复杂视图。
• 优化程序不能合并包含组外部联接的视图。
• 优化程序不能合并包括组外部联接中涉及的视图。
以下示例中,调优建议器会建议我们使用“NOT EXISTS”代替“NOT IN”:
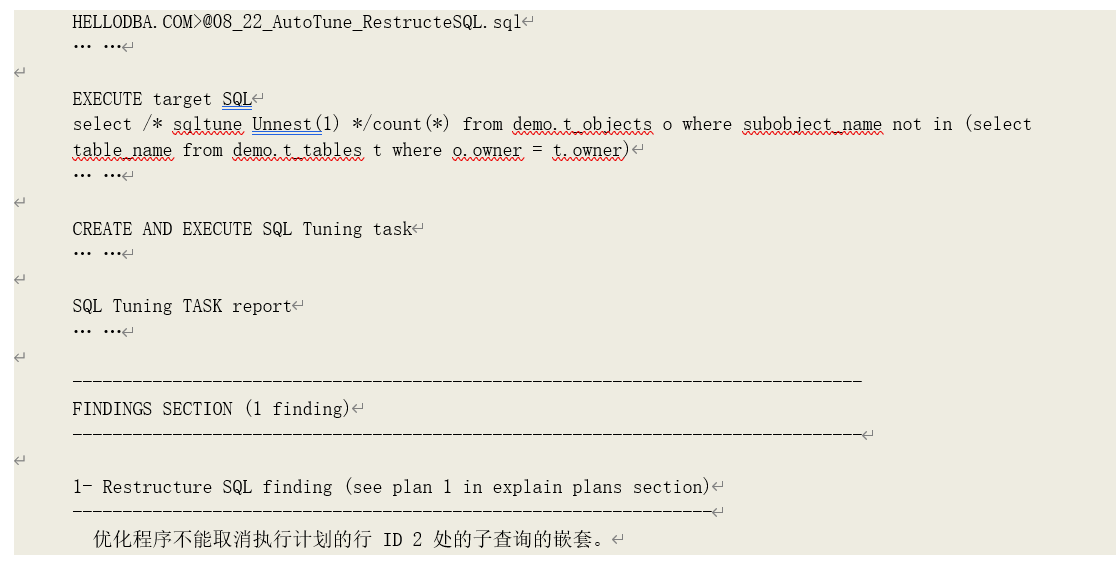


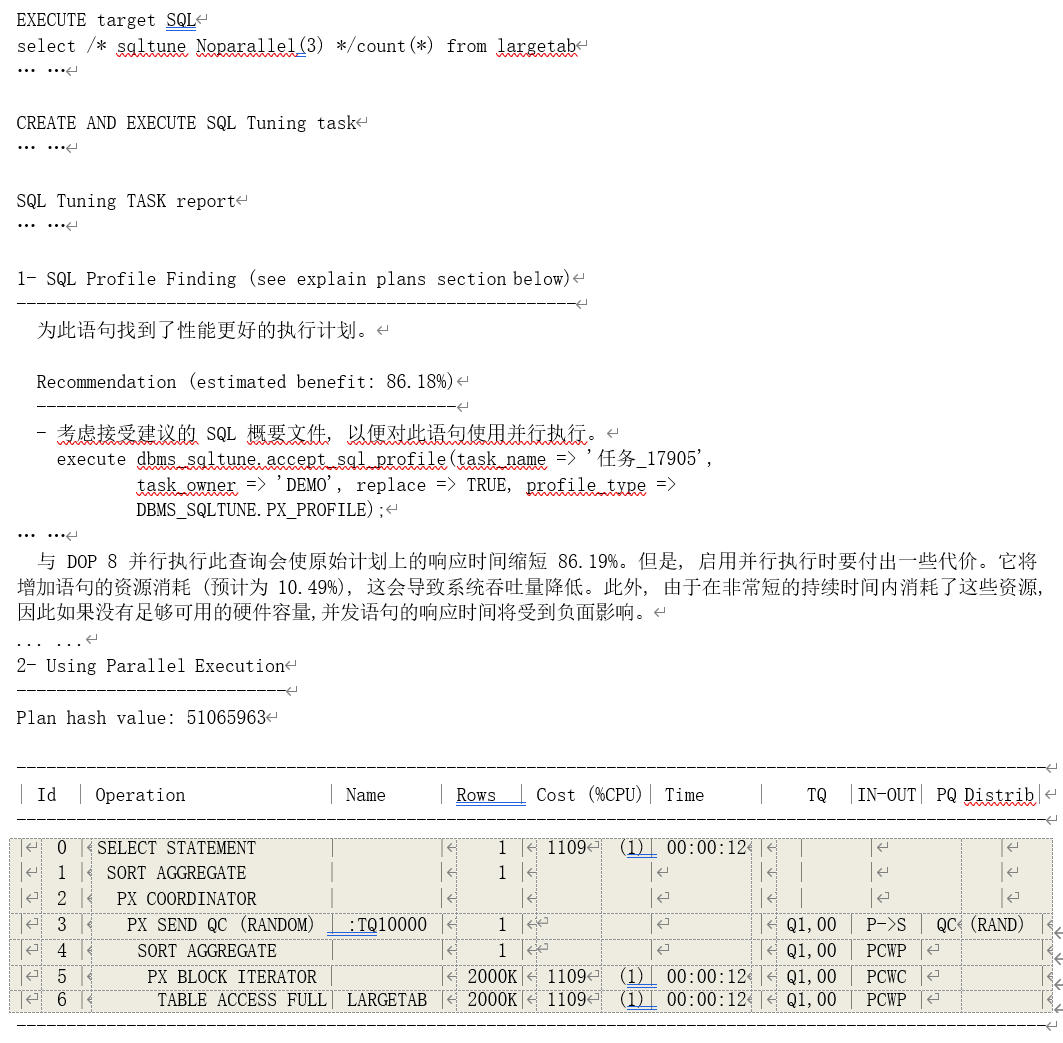


SQL 优化配置(SQL Profile)分析
SQL 优化配置分析实际上是一个综合分析,SQL 配置则包含多种用于帮助优化器生成性能最优的执行计划的辅助数据,这些数据可能会来自于之前几个方面分析过程中产生的辅助数据。从我们 前面的例子也可以看到,多个分析结果中都会建议用户采纳 SQL 调优建议器在分析过程中生成的
SQL 配置数据作为语句的优化配置。此外,在分析过程中,SQL 分析器还会尝试修改优化器特性参数(OPTIMIZER_FEATURES_ENABLE)改变 SQL 优化器选择执行计划的行为,从而找到更好的执行计划。
提示:参数 OPTIMIZER_FEATURES_ENABLE 是一个综合设置但是,它会导致优化器在生成执行计划时仅考虑该参数所指示的版本中的特性。
以下示例则是调优建议器通过修改优化器特性参数找到的代价更小的执行计划:


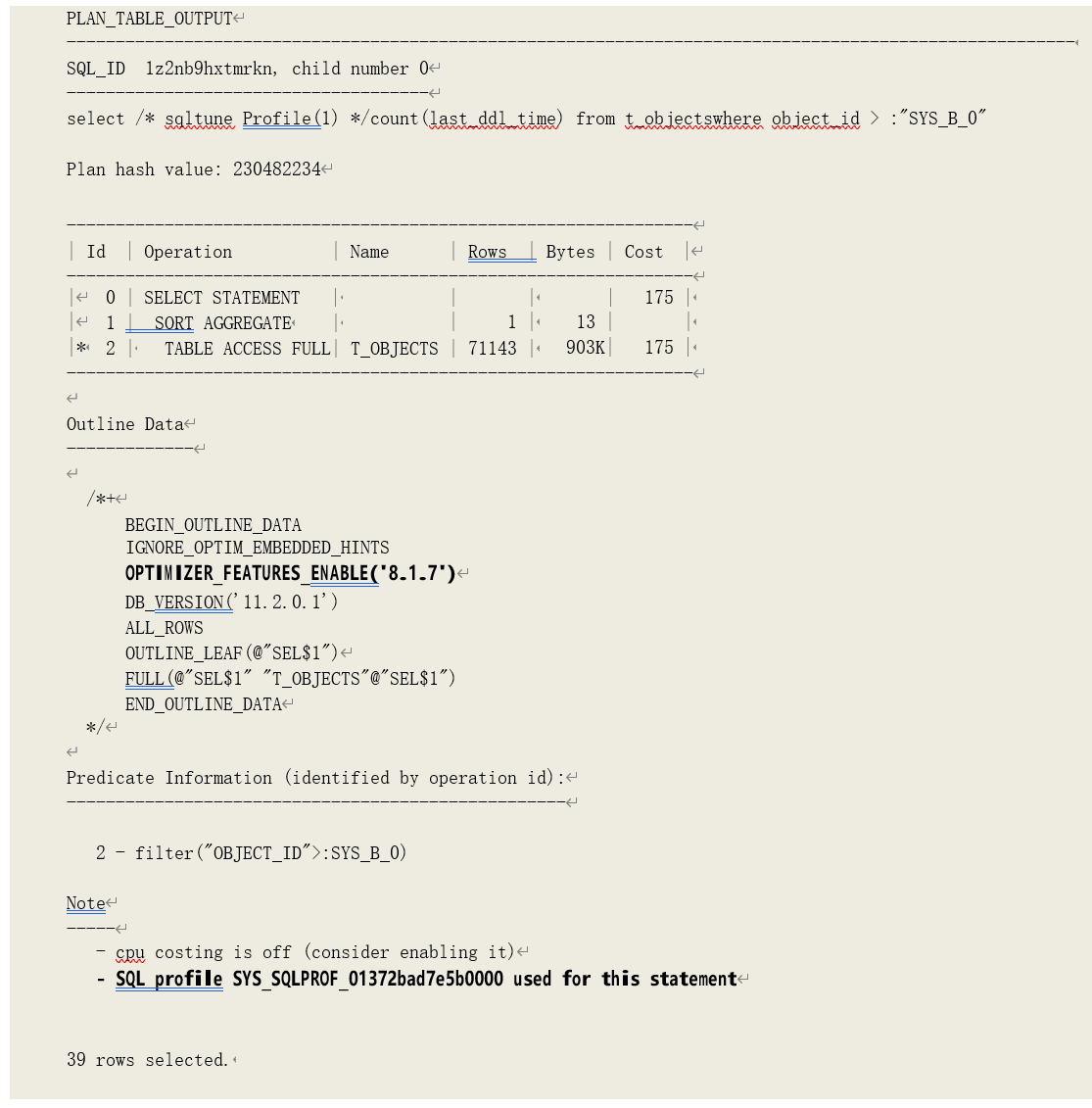
提示:SQL 优化配置与 SQL 执行计划管理共用了一套数据字典,即 SMB。并且,SQL 优化配置与
SQL 执行计划管理并不存在冲突,而是一个相辅相成的关系。当 SQL 优化配置与执行计划基线数据同时存在时,优化器会使用 SQL 优化配置找到最佳的基线执行计划。此外,当我们按照调优建议器的优化建议接受一个 SQL 优化配置时,如果该语句存在执行计划基线,那么 Oracle 在创建优化配置的同时也会将新的执行计划加入基线当中。
SQL 优化配置创建后,可以通过接口 DBMS_SQLTUNE.ALTER_SQL_PROFILE 修改其属性,包括:
• STATUS:状态是否可用(ENABLE/DISABLE);
• NAME:SQL 优化配置的名称————接受优化配置时,Oracle 会为其创建一个系统生成的名称;
• DESCRIPTION:SQL 优化配置的描述;
• CATEGORY:SQL 优化配置所属的分类;
还可以通过接口 DBMS_SQLTUNE.DROP_SQL_PROFILE 删除不需要的 SQL 优化配置。
